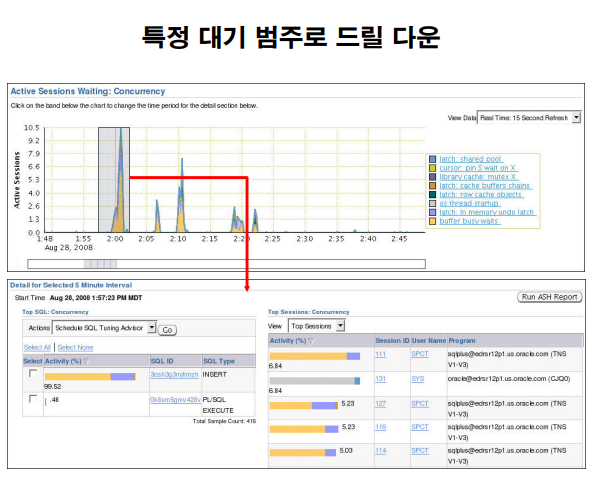
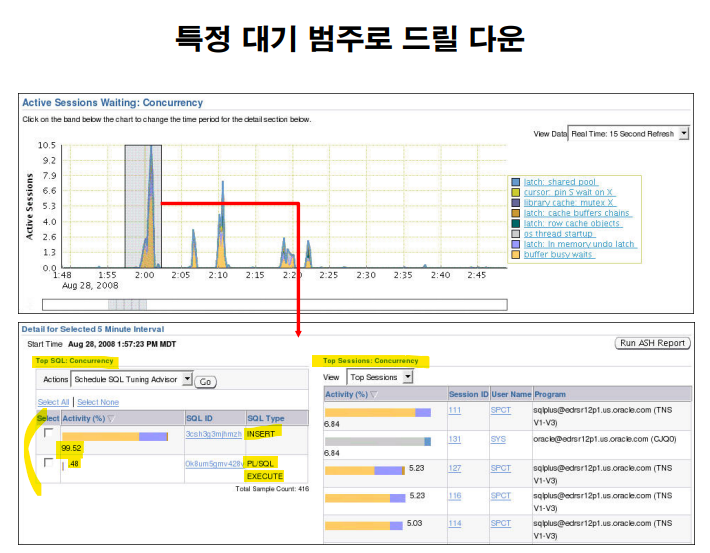
문제 파악이 가능함
문제 해결 - sql 튜닝으로 대부분 가능
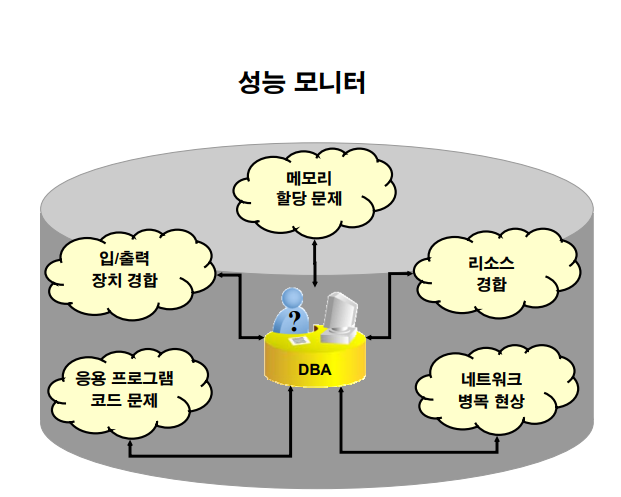
DBA 가 일상적으로 반드시 해야하는 일이 2가지인데 하나는 문제파악이고
다른 하나가 문제해결 입니다.
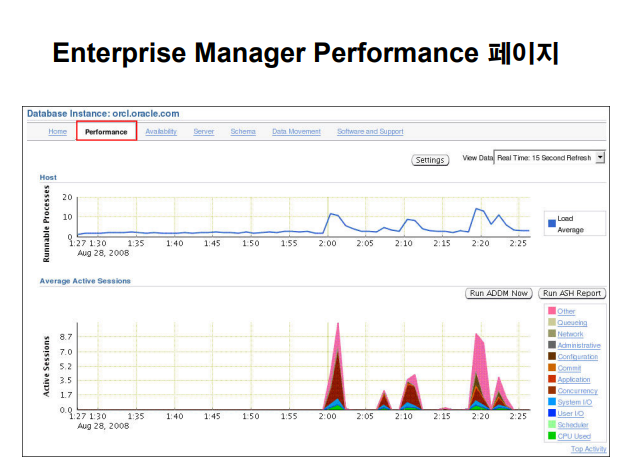
문제 파악을 빠르게 하려면 EM 의 성능 모니터 탭을 이용하면 아주 빠르게 문제를 파악할 수 있습니다.
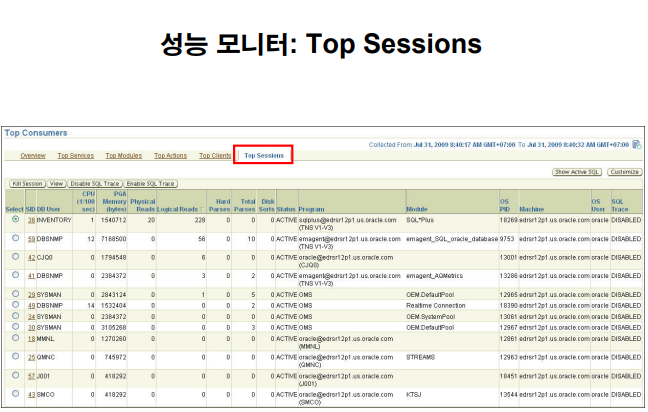
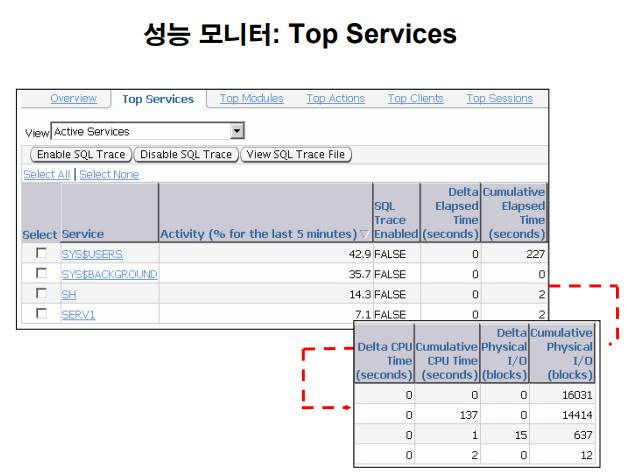
성능 모니터 : Top Services
특정 서비스에 대한 모음
서비스는 같은 서비스를 이용하는 세션들의 모음으로 세션보다는 큰 개념이다.
예) 배달의 민족
주문 서비스 scott 으로 4세션 접속 / 배달 서비스 scott 으로 4세션 접속
주문 서비스가 느린지 배달 서비스가 느린지를 한번에 확인 할 수 있음.
세션(session) : 오라클에 접속한 하나의 유져
서비스(service) : 여러개의 세션들의 집합
■ 실습
#1. em 을 켜려면 리눅스 서버로 직접 oracle 로 로그인 해야합니다.
#2. orcl db 를 선택합니다.
#3. orcl db 가 open 되어있는지 확인합니다.
#4. 리스너가 orcl 서비스를 인식하고 있는지 확인합니다.
#5. em 을 시작시킵니다.
#6. em url 로 em 홈페이지에 접속을 합니다.
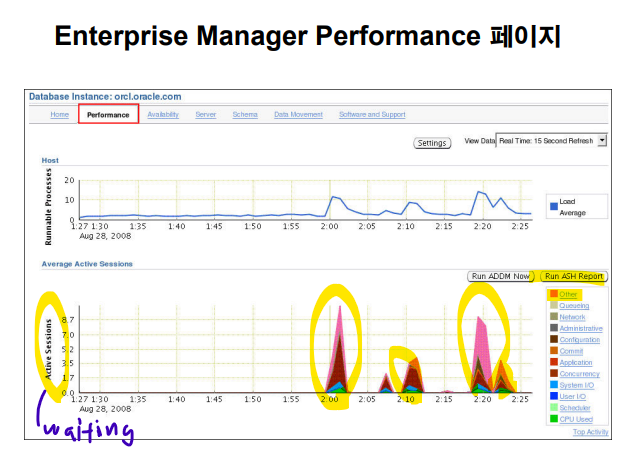
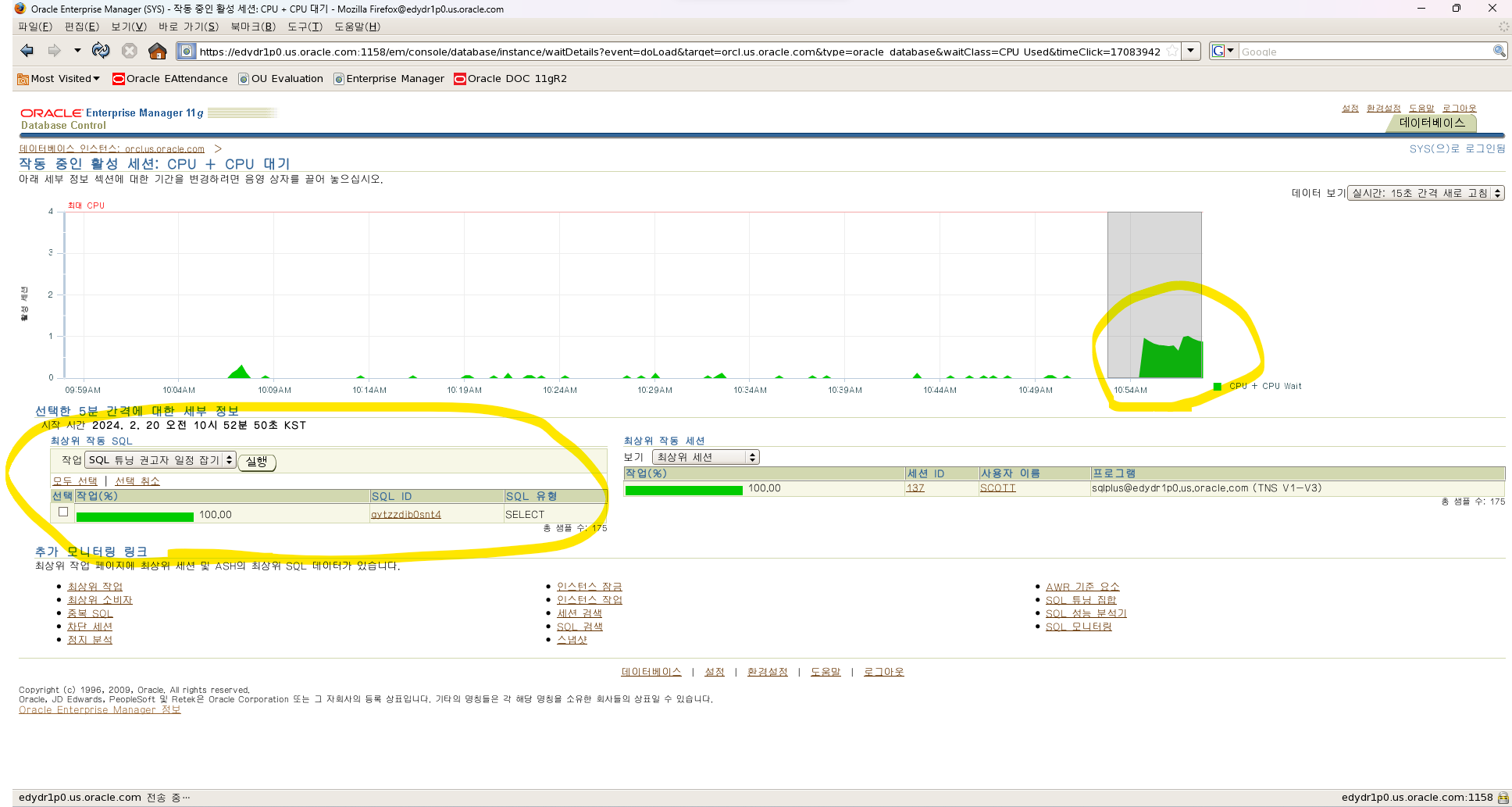
#7. 성능 텝을 눌러서 책에 나온데로 클릭을 해봅니다.
#8. 악성 sql을 scott 에서 수행합니다.
#9. 성능 텝에서 해당 session 과 악성 sql을 찾습니다.
https://edydr1p0.us.oracle.com:1158/em/console/aboutApplication
문제1. 아래의 악성 SQL 을 scott 유저에서 수행하고 em 에서 빠르게 db에 문제를 일으키는 세션과 악성 sql 을 알아내시오 !
▣ 예제 102. 오라클 메모리 사이즈 관리는 자동으로 되고 있어요

AMM (자동 메모리 관리)
낮 시간 : sga > pga
밤 시간 : sga < pga
pga : 정렬작업, hash join
자동 공유 메모리 관리
하나의 초기화 파라미터 : memory_target
평상시에는 자동으로 메모리 사이즈가 조정되게 하고 특별한 때에 수동으로 메모리사이즈를 설정하면 됩니다.
특별한 때 : 데이터 이행, 여러개의 테이블 생성 작업
메모리 사이즈를 자동 조절하게 하는 딱 하나의 파라미터는 memory_target
면접 때 대답을 잘해야지
키워드를 암기하고 있어야지
- db buffer cache -- > data file 로 부터 읽어들인 data 블럭의 복사본이 올라오는 곳
- redo log buffer -- > db 에 가한 변경 사항을 기록하는 곳
- shared pool --- > 파싱된 데이터를 올려서 파싱을 최소화 하기 위한 메모리 영역
- large pool ---> 병렬 쿼리문과 rman 백업/복구 시 사용하는 메모리 영역
- java pool ---> 자바 코드가 컴파일 되는 메모리영역 (dbca, netca 등을 실행할 때)
- stream pool --- > 데이터 이행할 때 사용하는 메모리 영역
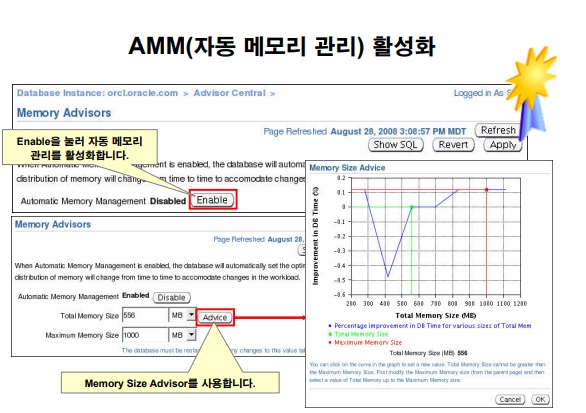
AMM(자동 메모리 관리) 활성화
데이터베이스를 구성할 때 AMM(자동 메모리 관리) 기능을 활성화하지 않은 경우 다음
단계를 수행하여 활성화할 수 있습니다.
1. Database Home 페이지에서 Server 탭을 누릅니다.
2. Database Configuration 영역에서 Memory Advisors를 누릅니다.
Memory Advisors 페이지가 나타납니다.
3. Automatic Memory Management에 대해 Enable을 누릅니다.
Enable Automatic Memory Management 페이지가 나타납니다.
4. Automatic Memory Management에 대해 Total Memory Size와 Maximum Memory Size
값을 설정합니다.
주: Maximum Memory Size를 변경하는 경우에는 데이터베이스 Instance를
재시작해야 합니다.
5. OK를 누릅니다.
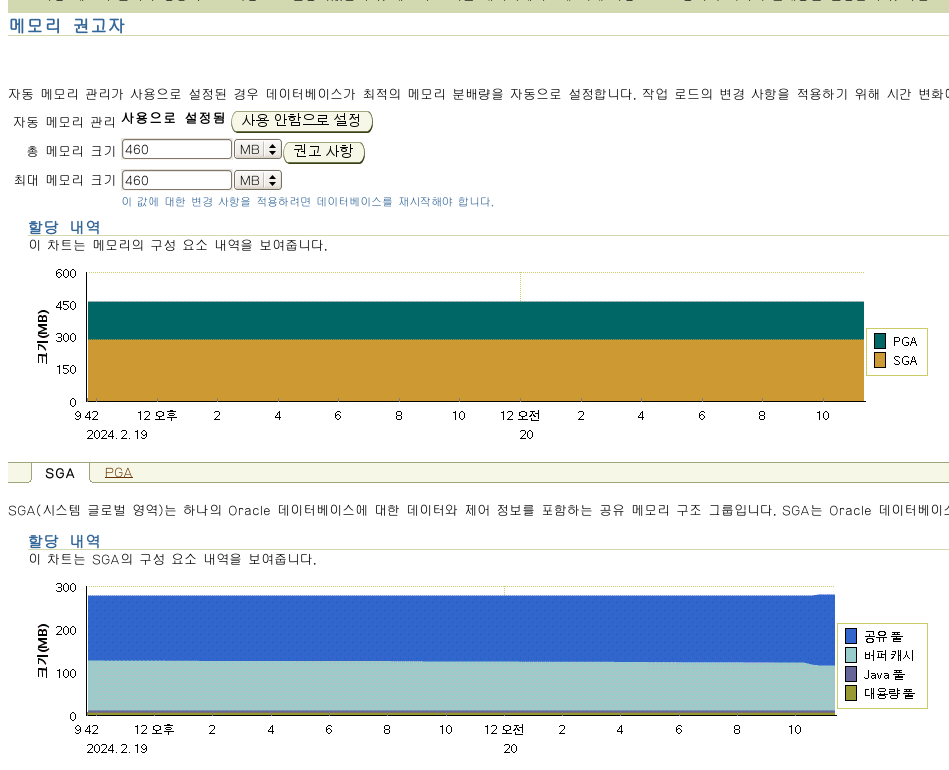
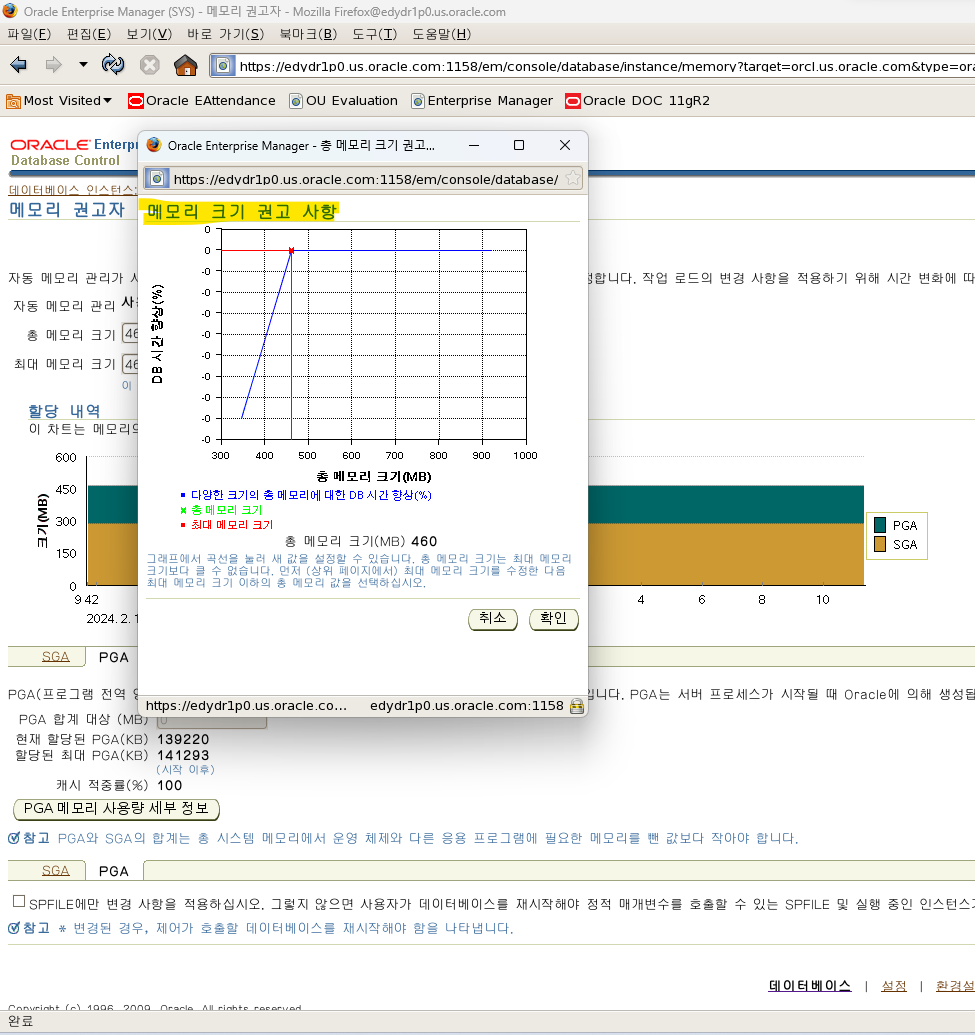
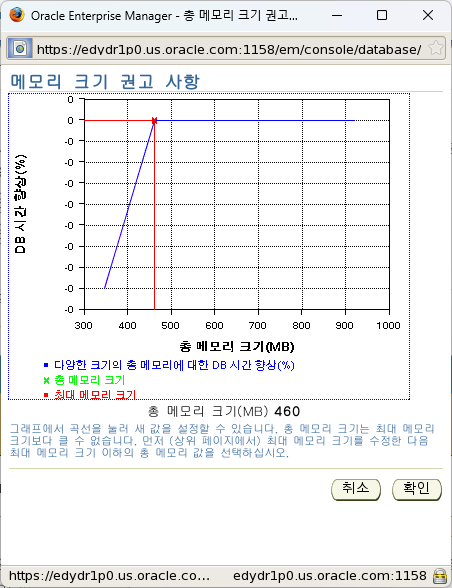
메모리 권고사항
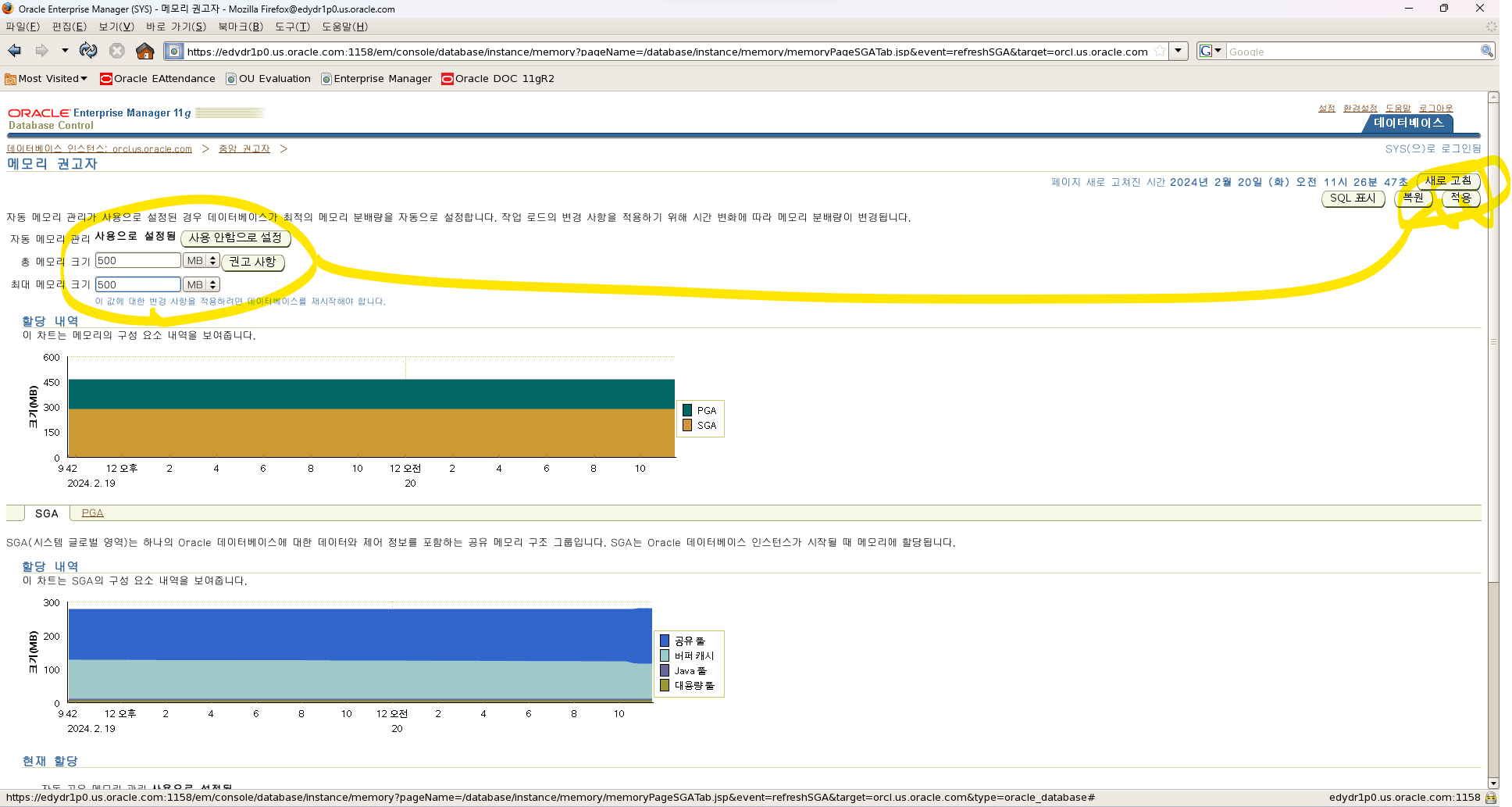
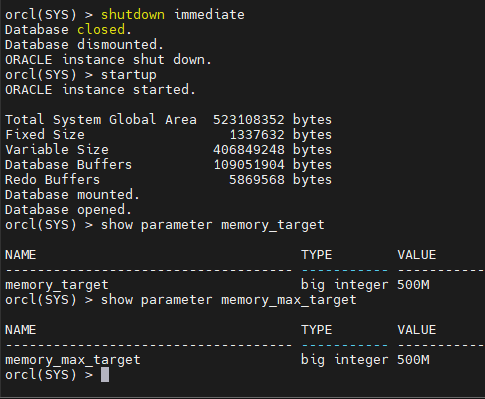
문제 1. 수동으로 memory_target 사이즈를 500 메가로 늘리시오
orcl(SYS) > show parameter memory_target
orcl(SYS) > show parameter memory_max_target
orcl(SYS) > alter system set memory_max_target=500m scope=spfile;
System altered.

orcl(SYS) > alter system set memory_target=500m scope=spfile;
System altered.
orcl(SYS) > shutdown immediate
orcl(SYS) > show parameter memory_target
▣ 103. 다이나믹 퍼포먼스 뷰를 잘 활용할 수 있어야 해요
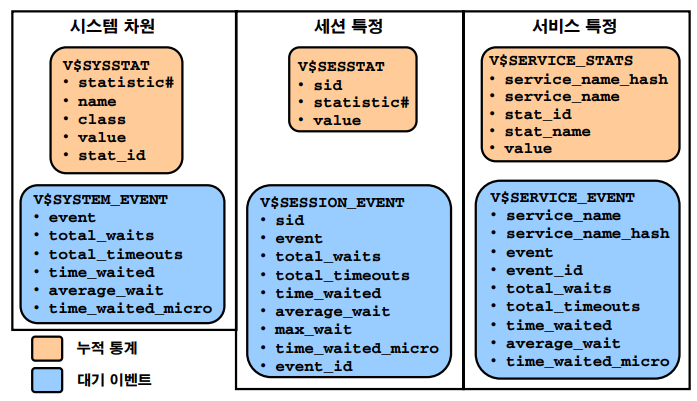
v$ 로 시작함
대기 이벤트 : 오라클이 느린 이유를 알 수 있음
누적 통계 : 메모리에서 그동안 읽은 블럭의 개수
v$ 로 시작하는 다이나믹 퍼포먼스 뷰에는 오라클의 성능을 진단하기 위한 데이터가 들어있습니다.
이게 두가지로 나뉩니다
- 누적 통계지표 : db가 startup 된 이후 부터 누적되어온 db 성능 통계지표
예 : vsesstat, v$service_stats
- 대기 이벤트 : db가 느린 이유에 대한 이벤트 이름
예 : vsession_event, v$service_event
■ 실습
- 오라클 인스턴스 메모리에서 읽어들인 블럭의 개수
select name, value
from v$sysstat
where name like '%logical%';
NAME VALUE
session logical reads 229914
악성 sql 이 수행되면 갑자기 이 값이 올라갑니다.
- 현재 발생하고 있는 대기 이벤트 정보를 확인합니다.
select event
from v$session_wait
order by event;
db file scattered read ---> 누군가 full table scan 하면서 대기하고 있다는 것입니다.
■ 실습 : em 말고 리눅스 명령어와 sql 을 이용해서 악성 sql 을 한번에 찾는 방법
#1. scott 유져로 접속해서 악성 sql 을 수행합니다.
select count(*)
from emp, emp, emp, emp, emp, emp, emp, emp, emp;
#2. 리눅스에서 현재 cpu 를 많이 사용하고 있는 프로세서 번호를 알아냅니다.
top | head -8 | tail -1
[orcl:~]$ top | head -8 | tail -1
22263 oracle 25 0 653m 25m 22m R 93.3 0.7 0:27.13 oracle
[orcl:~]$ top | head -8 | tail -1 | awk '{print $1}'
22263
#3. 위에서 출력되고 있는 프로세서 번호를 변소에 담고 echo 로 출력하시오
vi cpu_top_sql.sh
#4. 위의 스크립트를 이용해서 완성한 cpu 를 과도하게 사용하는 프로세서의 SQL을
출력하는 쉘 스크립트를 작성하고 수행하시오 (점심시간 문제)
pid=top | head -8 | tail -1 | awk '{print $1}'
echo $pid
output=$(sqlplus -s sys/oracle_4U as sysdba <<EOF
Select a.sql_text txt
from v$sqlarea a, v$session b, v$process c
where c.spid = '$pid'
and c.addr = b.paddr
and b.sql_address = a.address
and b.sql_hash_value = a.hash_value;
EOF
)
echo $output
쉘 스크립트 안에 $ 를 쓰려면 \ 를 써줘야 함 ( | ) < 이거
▣ 예제104. 부적절한 인덱스와 프로시져를 찾아서 사용 가능하게끔 구성해야 해요.
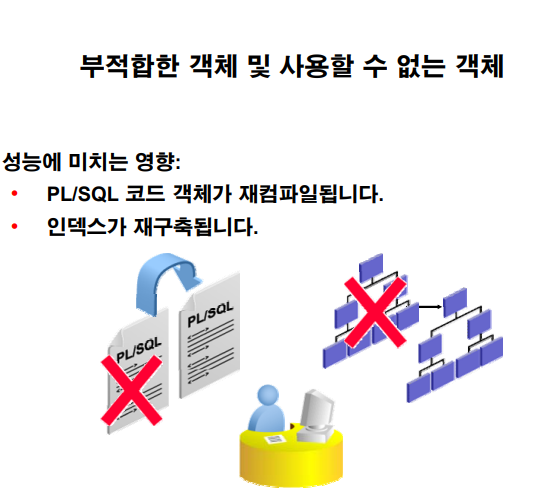
부적합한 객체 및 사용할 수 없는 객체
부적합한 PL/SQL 객체 및 사용할 수 없는 인덱스는 성능에 영향을 줍니다.
부적합한 PL/SQL 객체는 재컴파일해야 사용할 수 있습니다.
그러므로 PL/SQL 패키지, 프로시저 또는 함수에 액세스하려고 시도하는 첫번째 작업에 컴파일 시간이 추가됩니다
PL/SQL이 제대로 재컴파일되지 않으면 작업이 실패하고 오류가 발생합니다.
사용할 수 없는 인덱스는 옵티마이저에서 무시됩니다.
SQL 문의 적절한 성능이 사용할 수 없는 것으로 표시된 인덱스에 따라 달라지는 경우 인덱스를 재구축할 때까지는 성능이 개선되지 않습니다.
설명 1. 잘 실행되던 프로시져가 invalid 되는 경우
답 : 프로시져 내의 테이블이 drop 되거나 컬럼이 추가 삭제 되는 경우
해결 방법 : 다시 프로시져를 compile 한다.
- 잘 실행되던 인덱스가 invalid 되는 경우
해결 방법 : 인덱스를 rebuild 해야 합니다.
■ 실습 1 : invalid 된 인덱스를 rebuild 하기
#1. scott 유져에서 demobld 스크립트를 다시 수행합니다.
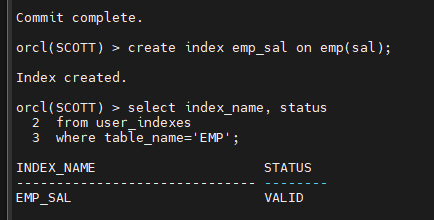
#2. emp 테이블 sal 에 인덱스를 생성합니다.
orcl(SCOTT) > create index emp_sal on emp(sal);
Index created.
orcl(SCOTT) > select index_name, status
2 from user_indexes
3 where table_name='EMP';
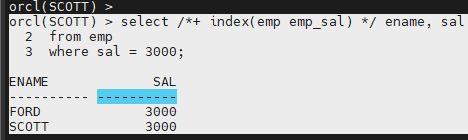
orcl(SCOTT) > select /+ index(emp emp_sal) / ename, sal
2 from emp
3 where sal = 3000;
.
#3. emp 테이블을 다른 테이블 스페이스로 이동
왜 move시키는가 ? db org 작업 때문입니다
select table_name, tablespace_name
from user_tables
where table_name='EMP';
orcl(SCOTT) > select tablespace_name from dba_tablespaces;
orcl(SCOTT) > alter table emp move tablespace example;
Table altered.
orcl(SCOTT) > select table_name, tablespace_name
2 from user_tables where table_name='EMP';
#4. emp_sal 인덱스의 상태를 확인
orcl(SCOTT) > select index_name, status
2 from user_indexes
3 where table_name='EMP';
#5. emp_sal 인덱스의 상태를
orcl(SCOTT) > select /+ index(emp emp_sal) / ename, sal
2 from emp
3 where sal = 3000;

#5. emp_sal 인덱스의 상태를 정상으로 회복시킵니다
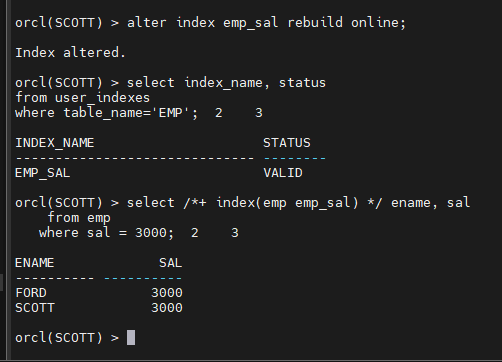
alter index emp_sal rebuild online;
select index_name, status
from user_indexes
where table_name='EMP';
select /+ index(emp emp_sal) / ename, sal
from emp
where sal = 3000;
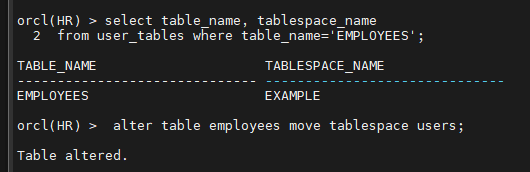
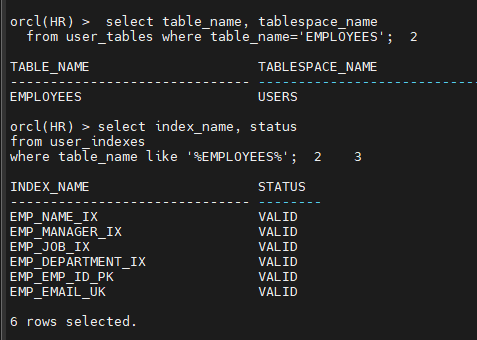
문제1. hr 계정으로 접속해서 hr 계정의 employees 테이블이 어느 테이블 스페이스에 있는지 확인하시오
connect hr/tiger
select table_name, tablespace_name
from user_tables where table_name='EMPLOYEES';
문제2.
alter table employees move tablespace users;
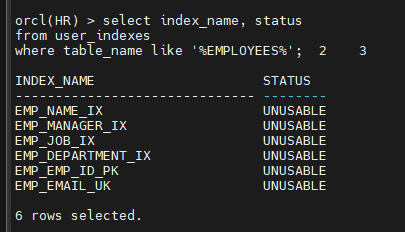
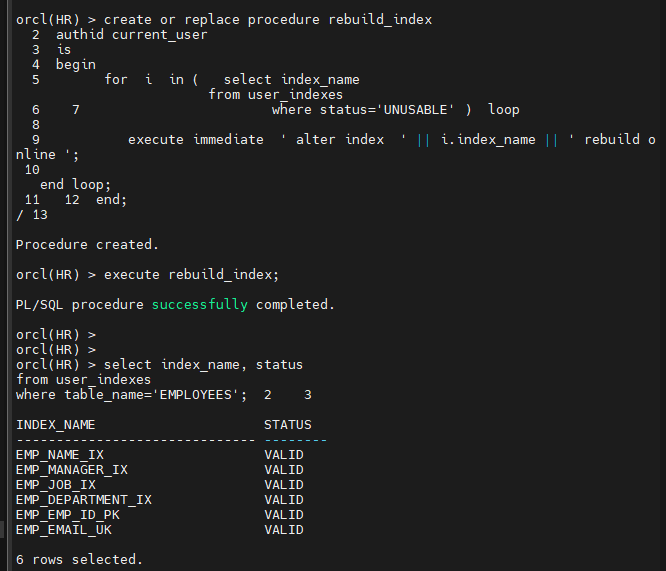
문제3. employees 테이블과 관련된 인덱스들의 상태를 확인하고 전부 valid 상태로 복구 시키시오
select index_name, status
from user_indexes
where table_name like '%EMPLOYEES%';
select ' alter index ' || index_name || ' rebuild online; '
from user_indexes
where table_name = 'EMPLOYEES' and status='UNUSABLE';
select table_name, tablespace_name
from user_tables where table_name='EMPLOYEES';

문제4. 다시 employees 테이블을 example 테이블 스페이스로 move 시키세요
alter table employees move tablespace example;
select index_name, status
from user_indexes
where table_name='EMPLOYEES';
문제5. unusable 된 인덱스들을 모두 valid 시키는 프로시져를 생성하고 실행하시오
create or replace procedure rebuild_index
authid current_user
is
begin
for i in ( select index_name
from user_indexes
where status='UNUSABLE' ) loop
execute immediate ' alter index ' || i.index_name || ' rebuild online ';
end loop;
end;
/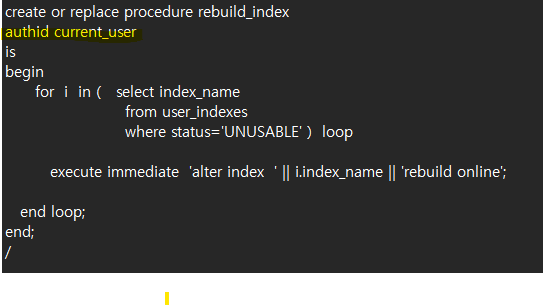
authid current_user : 권한을 위해 넣어야 함.
exec rebuild_index;
■ 실습1. INVALID 된 프로시져를 다시 컴파일 하기
#1. 프로시져를 생성합니다.
connect scott/tiger
create or replace procedure pro1
is
v_sal emp.sal%type;
begin
select sal into v_sal
from emp
where ename='SCOTT';
end;
/
#2. 프로시져와 관련된 테이블을 DROP 합니다
orcl(SCOTT) > drop table emp;
Table dropped.
#3. drop 된 테이블을 flashback 으로 복구합니다.
orcl(SCOTT) > flashback table emp to before drop;
Flashback complete.
#4. 프로시져의 상태를 확인합니다.
select object_name, status
from user_objects
where object_name='PRO1';
OBJECT_NAME STATUS
PRO1 INVALID
#5. 프로시져를 컴파일 합니다
alter procedure pro1 compile;
OBJECT_NAME STATUS
PRO1 VALID

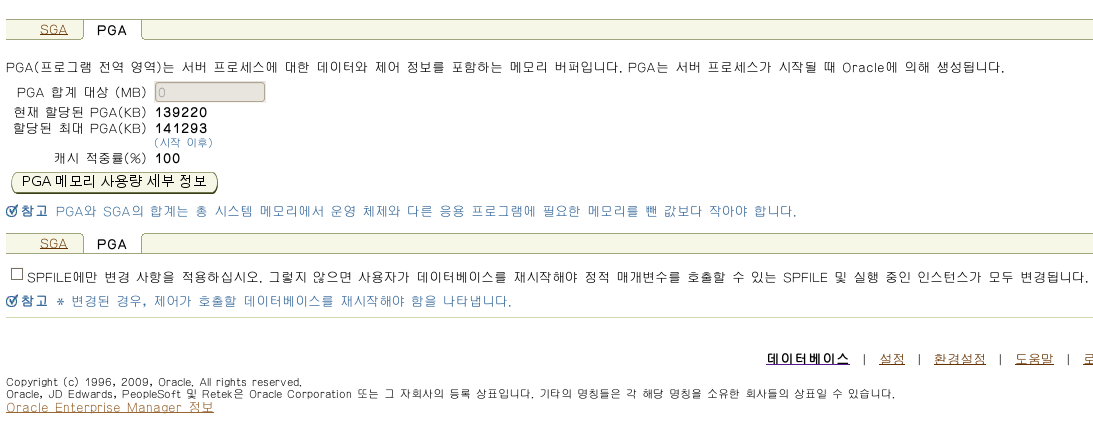
PGA


▣ 예제 105. 데이터를 이행하는 3가지 방법을 알아야해요
-
Direct load insert : 서브 쿼리를 사용한 insert 문
-
SQL*loader : csv 나 text 파일을 데이터 베이스에 이행 (데이터 양이 많아지면 사용한다)
-
export / import : 테이블 또는 테이블 스페이스를 통채로 이행
↓
export pump/import pump
위의 3가지 중 가장 많이 사용하는 데이터 이행방법은 1번과 3번 입니다.

서브쿼리를 사용한 insert 로 이행하는 경우 ?
11g 의 테이블과 21c 의 테이블의 구조가 서로 다르거나 데이터를 암호화 해서 이해을 해야한다.
리뉴얼
export / import 하는 경우 ?
그냥 통채로 전 부 데이터를 넘겨도 되는 경우
▣ 예제 106. 서브쿼리를 사용한 insert 문의 속도를 높이는 방법을 알아야해요
Direct load insert : high water mark 위에 데이터를 입력
high water mark 란 ? 포맷된 디스크와 포맷되지 않은 디스크의 경계선이다.
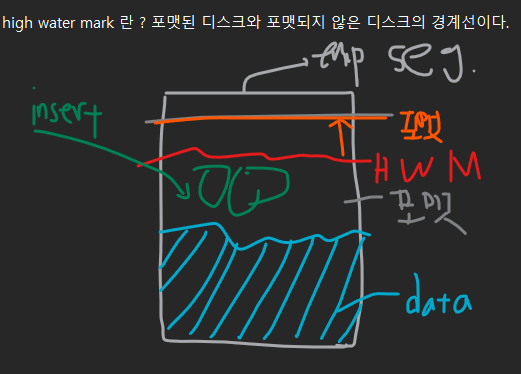
다음과 같이 emp 테이블에 insert 를 하면 전부 HWM 아래에 입력 됩니다.
insert into emp(empno, ename, sal)
values(1111,'aaa',3000);
insert into emp
select *
from emp2;
HWM 위에 데이터를 입력하는 것은 다음과 같이 하면 됩니다.
insert /*+ append */ into emp
select *
from emp2;왜 HWM 위에 데이터를 넣는가 ? : insert 속도가 빠름.
■ 실습1. 서브쿼리를 사용한 데이터 이행
#1. emp_new 라는 테이블을 생성합니다.
create table emp_new
as select * from emp where 1=2;
(구조만 만들었음)
#2. emp_new 테이블에 emp 테이블의 데이터를 입력합니다.
hwm 아래쪽에 넣는다
insert into emp_new
select * from emp;
#3. emp_new 테이블의 데이터를 전부 지웁니다.
delete from emp_new;
commit;
#4. emp_new 테이블 emp 테이블의 데이터를 입력하는데 HWM 위로 입력합니다.
insert /+ append / into emp_new
select * from emp;
HWM 위로 입력 했는지 아는 법
select 했는데 에러가 나면 위로 들어간것 !!
orcl(SCOTT) > select count() from emp_new;
select count() from emp_new
*
ERROR at line 1:
ORA-12838: cannot read/modify an object after modifying it in parallel
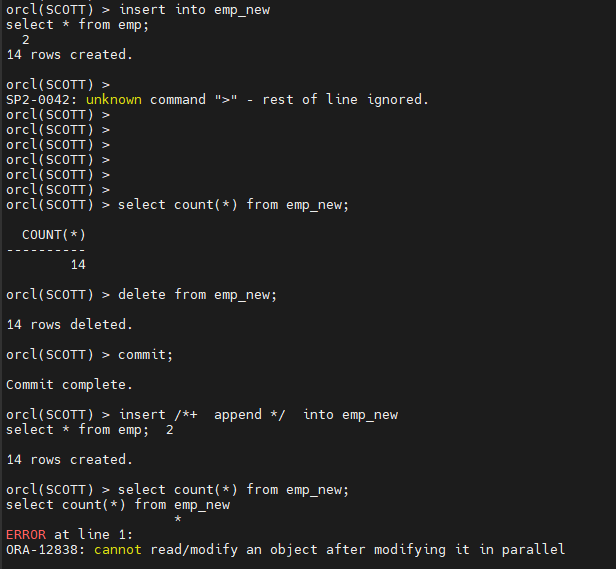
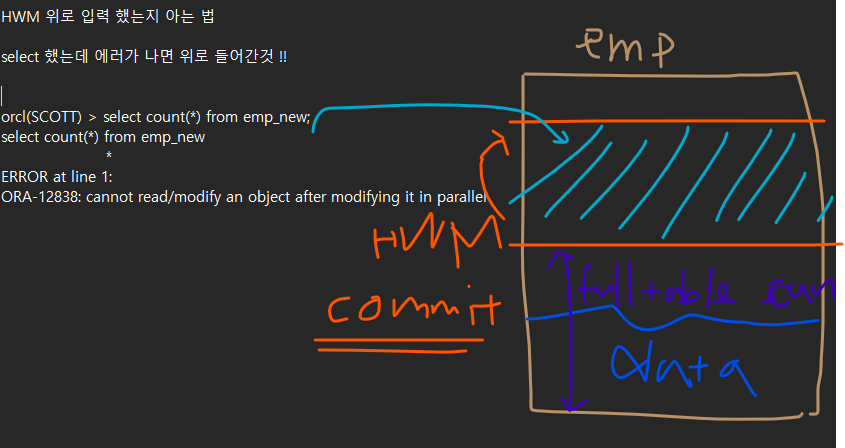
commit 를 해줘야 한다.
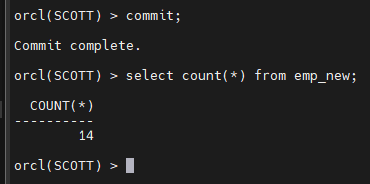
commit 을 해야 HWM 가 위로 올라가면서 데이터를 select 할 수 있습니다.
high water mark 위로 데이터를 insert 해야하는 때
= > 대량의 데이터를 이행해야할 때 속도를 빠르게 하기 위해서
문제1. orcl 에 있는 데이터를 PROD 로 이행하기 위해서 orcl 쪽에 PROD 쪽 테이블을 엑세스 할 수 있는 DB링크를 생성하시오
#1. 리스너의 상태를 확인해서 orcl 과 prod 의 서비스 상태 확인
lsnrctl status
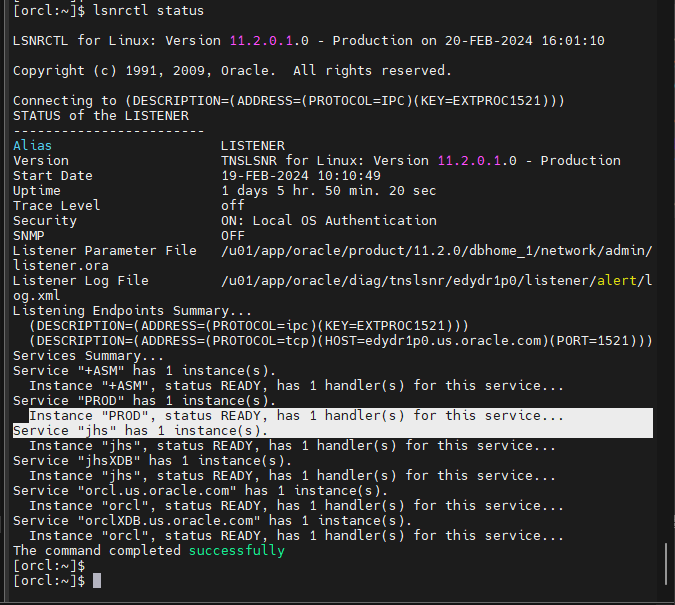
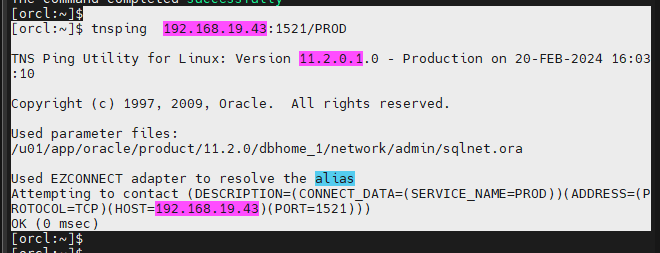
[orcl:~]$ tnsping 192.168.19.43:1521/PROD
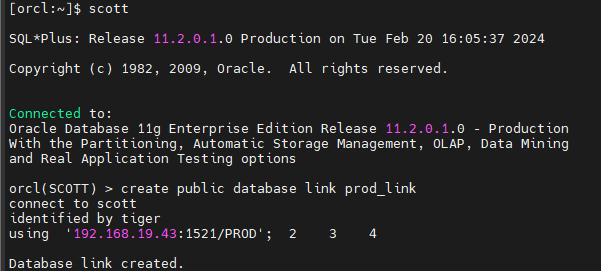
#2. orcl 쪽 scott 유져에서 prod 쪽에 대한 db 링크를 생성합니다.
create public database link prod_link
connect to scott
identified by tiger
using '192.168.19.43:1521/PROD';
Database link created.
orcl(SCOTT) > select * from emp@prod_link;
※ 이수자평가할때 편안하게 하려면 푸티창을 두개를 열고 한 쪽은 프로드로 들어가고 다른 한 쪽은 orcl 열고
둘 다 scott
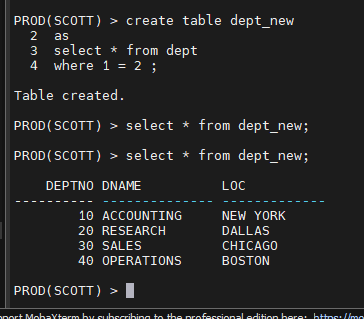
문제2. prod 쪽에 dept_new 라는 테이블을 dept 테이블의 구조로만 생성하시오
PROD(SCOTT) > create table dept_new
2 as
3 select * from dept
4 where 1 = 2 ;
Table created.
문제3. orcl 쪽의 dept 테이블의 데이터를 prod dept_new 테이블에 이행 하시오
HWM 마크 위로 입력되게 하시오
이행해
orcl(SCOTT) > insert /+ append / into dept_new@prod_link select * from dept;
4 rows created.
orcl(SCOTT) > commit;
Commit complete.

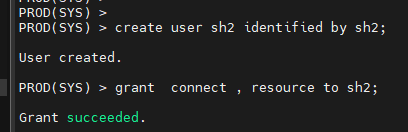
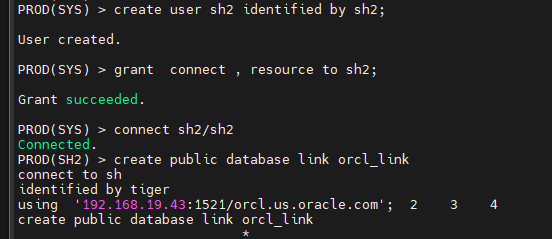
문제4. prod 쪽에 sh2라는 유져를 패스워드를 sh2로 해서 생성하고 기본적인 권한을 주시오
create user sh2 identified by sh2
grant connect , resource to sh2;
문제5. prod 쪽에 sh2 유져로 접속해서 orcl 쪽의 sh 계정의 데이터를 엑세스 할 수 있게 db 링크를 생성하시오 !
PROD(SYS) > grant create database link to sh2;
create public database link orcl_link
connect to sh
identified by tiger
using '192.168.19.43:1521/orcl.us.oracle.com';
PROD(SH2) > select count(*) form sales@orcl_link;
문제6. prod 쪽의 sh2 에서 sales_new 라는 테이블을 생성하는데 orcl 쪽의 sh 계정의 sales 테이블의 구조로만 생성하시오
PROD(SH2) > create table sales_new
as
select * from sales@orcl_link
where 1 = 2;
문제7. prod 쪽의 sh2 계정의 sales_new 에 데이터를 입력하는데
orcl 쪽의 sh 계정의 sales 테이블의 데이터를 불러와서
hwm 위로 입력하시오!
set timing on
insert /+ append / into sales_new
select * from sales@orcl_link;
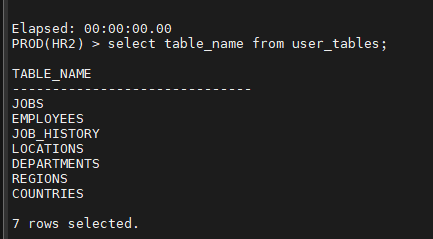
오늘의 마지막 문제. prod 쪽에 hr2 계정을 생성하고 orcl 쪽의 hr 계정의 모든 테이블을 prod 쪽에 hr2 계정에 데이터 이행하시오
테이블명은 똑같이 하세요 !
create user hr2 identified by hr2
grant connect , resource to hr2;
grant create public database link to hr2;
create public database link orcl_link2
connect to hr
identified by tiger
using '192.168.19.43:1521/orcl.us.oracle.com';
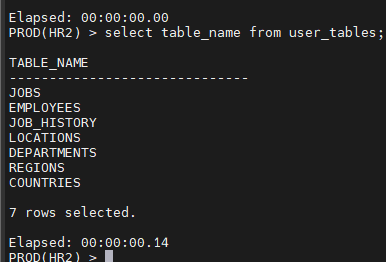
orcl(HR) > select table_name from user_tables;
create table COUNTRIES
as
select * from COUNTRIES@orcl_link2
where 1 = 2;
create table REGIONS
as
select * from REGIONS@orcl_link2
where 1 = 2;
create table DEPARTMENTS
as
select * from DEPARTMENTS@orcl_link2
where 1 = 2;
create table LOCATIONS
as
select * from LOCATIONS@orcl_link2
where 1 = 2;
create table JOB_HISTORY
as
select * from JOB_HISTORY@orcl_link2
where 1 = 2;
create table EMPLOYEES
as
select * from EMPLOYEES@orcl_link2
where 1 = 2;
create table JOBS
as
select * from JOBS@orcl_link2
where 1 = 2;
insert /*+ append */ into COUNTRIES
select * from COUNTRIES@orcl_link2;
insert /*+ append */ into REGIONS
select * from REGIONS@orcl_link2;
insert /*+ append */ into DEPARTMENTS
select * from DEPARTMENTS@orcl_link2;
insert /*+ append */ into LOCATIONS
select * from LOCATIONS@orcl_link2;
insert /*+ append */ into JOB_HISTORY
select * from JOB_HISTORY@orcl_link2;
insert /*+ append */ into EMPLOYEES
select * from EMPLOYEES@orcl_link2;
insert /*+ append */ into JOBS
select * from JOBS@orcl_link2;