
■ RAC 수업 복습
- RAC 개념
- RAC 관리
- RAC 백업과 복구
- RAC 튜닝
▣ 예제51. US enqueue
US enqueue 란 ?
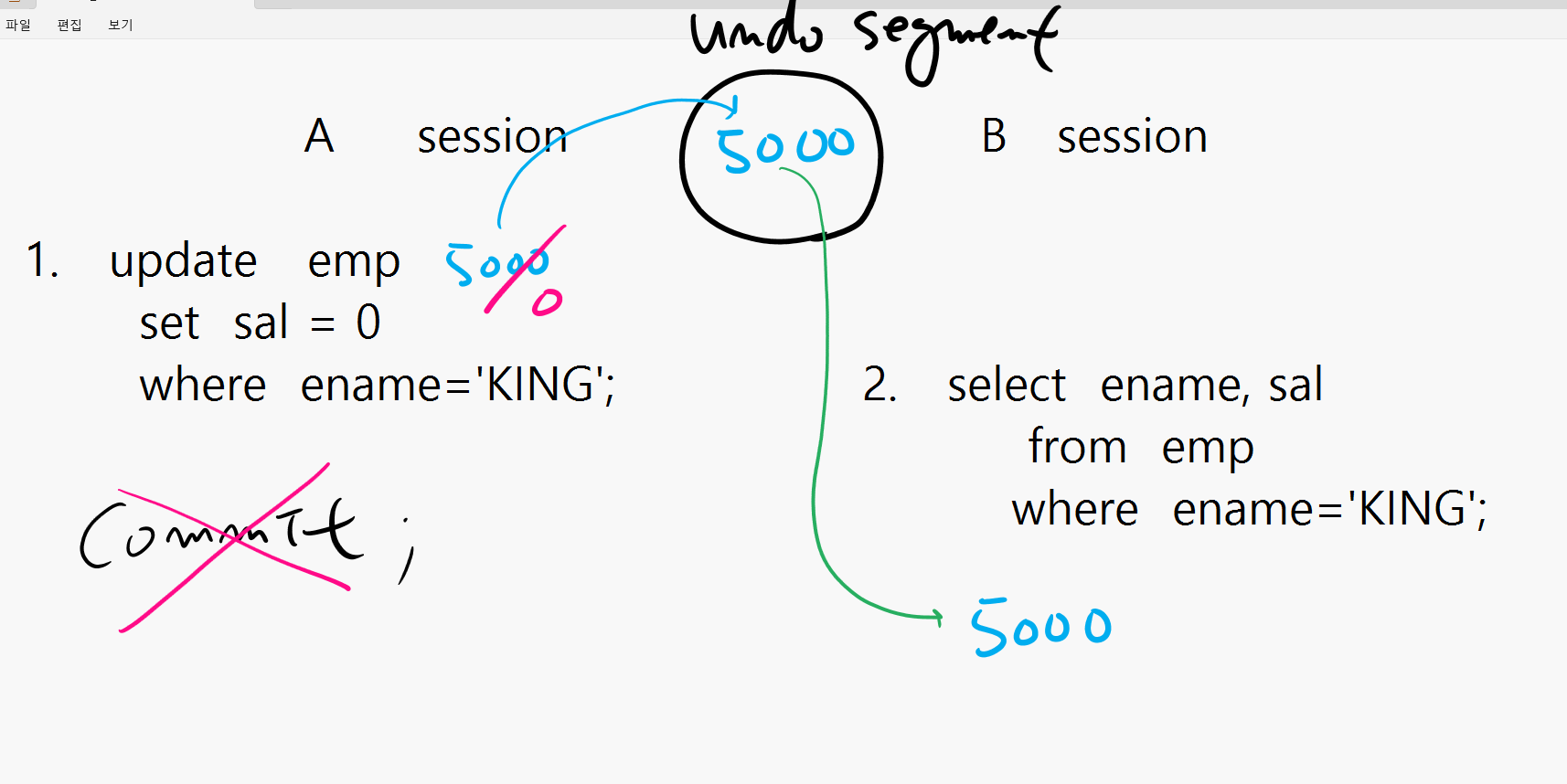
Undo Segment enqueue 라는 뜻입니다.
Undo Segment 를 여러 세션들이 동시에 할당받아서
사용하려고 할 때 경합이 발생하게 되는데 그 때
undo segment 를 보호하기 위해서 사용하는 락입니다.
- undo segment 의 역할 ? rollback 할 데이터를 저장하는 공간
읽기 일관성을 보장하기 위한 공간
- undo segment 가 현재 몇개가 떠 있는지 확인하시오 !
select *
from v$rollname;
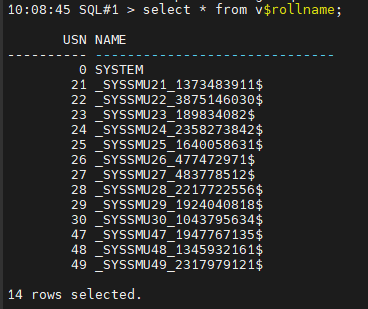
지금은 19개만 나오지만 DML 작업이 활발히 발생하면 이 갯수가 자동으로
늘어납니다. 무한히 늘어날 수 는 없고 undo tablespace 의 사이즈에 따라
허용하는 한도 내에서 늘어날 수 있으므로 지금 활성화된 undo segment 들을 여러 세션들이 공유해서 사용하는것입니다.
하나의 undo segment 를 여러개의 trasaction 이 같이 사용할 수 있는것입니다.
그래서 그 transaction 은 끝날때까지(commit할때) 그 undo segment 만 해야합니다.
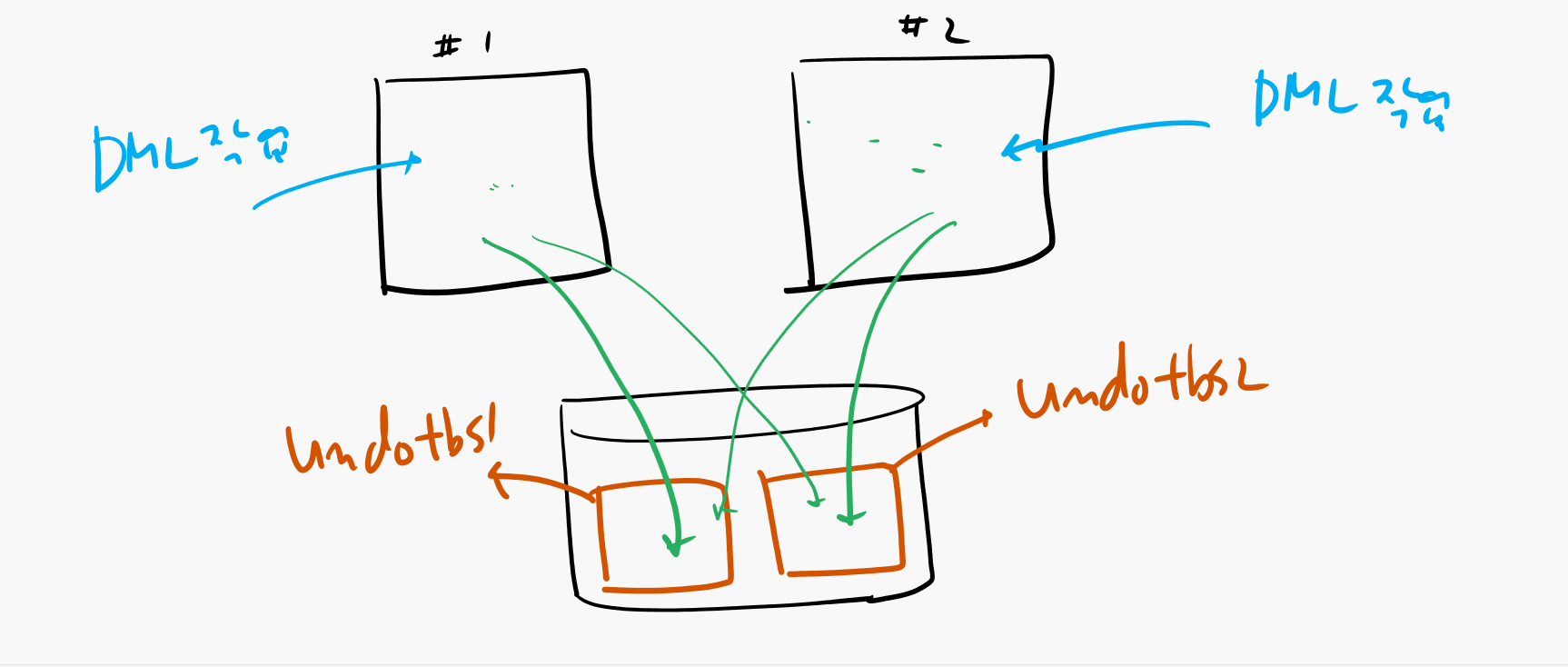
동시에 여러 transactoin 들이 하나의 undo segment 에 경합을 벌이지 않게
하기 위해서 us enqueue 로 undo segment 를 보호하는것입니다.
us enqueue 를 잡은 세션만 undo segment 를 사용할 수 있게 합니다.
그런데 rac 환경에서 us enqueue 가 더 잘 발생합니다.
왜 더 많이 발생하냐면 인스턴스가 1개가 아니라 여러개이기 때문에
더 많은 세션이 오라클에 접속해서 transaction 을 발생 시킬 수 있기
때문입니다.
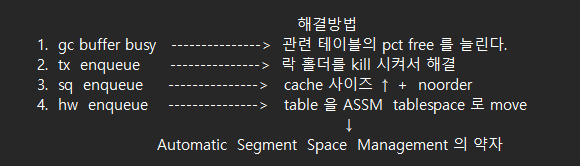
해결방법
1. us enqueue 의 홀더 세션을 kill 시켜서 락을 해제합니다.
2. undo_management 가 auto 로 되어있는지 확인
3. undo_retention 의 시간을 적절하게 조정
4. undo_tablespace 의 크기를 좀더 늘려줌
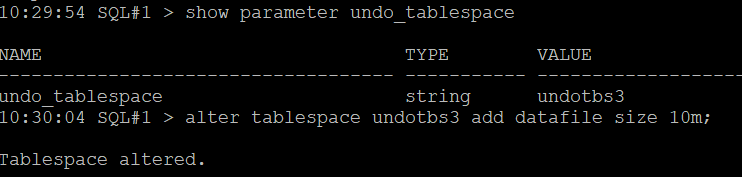
문제5. 2번 인스턴스의 default undo tablespace 가 뭔지 확인하고
사이즈를 10m 더 늘리시오 !
alter tablespace undotbs3 add datafile size 10m;
▣ 예제52. shared pool 관련한 latch 를 알아야 해요
오라클 메모리 성능에 이슈 2가지 ?
1. enqueue 2. latch

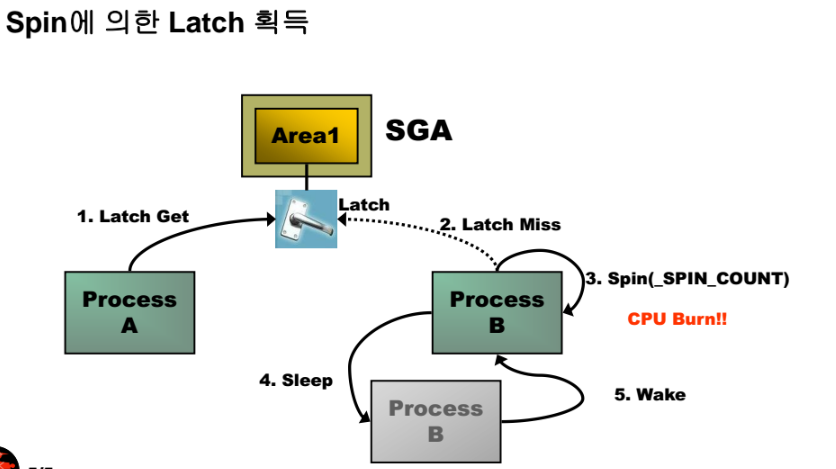
latch 를 획득해야지만 SGA 영역 메모리를 사용할 수 있게 되는것입니다.
면접질문: latch 가 뭔지 설명해주기겠어요?
답변 :
오라클 메모리를 보호하가 위한 락의 종류중에 하나이고 가벼운 lock 입니다
오라클 메모리를 사용하려면 반드시 latch 를 획득해야하고 latch 를 획득하지
못하면 대기 리스트에 들어가서 대기하게 됩니다.
latch 를 획득해야 하는 경우
-
shared pool 의 경우 : SQL 을 파싱 하려고
-
db buffer cache 의 경우 : datafile 에서 data 블럭을 메모리에 올리려고
-
불필요한 파싱을 최소하는 방법 이론 설명
select ename, sal
from emp
where ename='SCOTT';
- Parsing ---> 문법검사, 의미검사
- execute ---> 데이터 찾는 과정
- fetch ---> 데이터 전달
하드 파싱 : 다시 파싱하는거
■ 실습 " 불필요한 파싱을 최소하는 방법 " : 하드 파싱
#1. 스냅샷
SQL> @snap
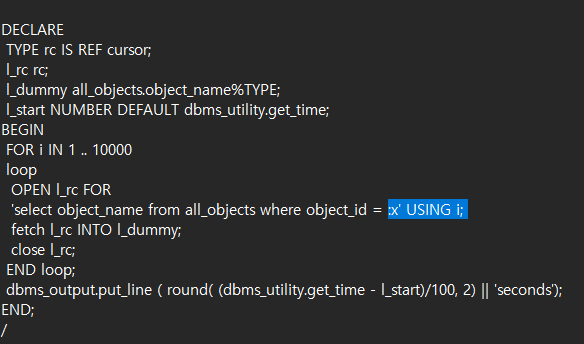
#2. 하드 파싱을 일으키는 부하를 일으킨다
SQL> DECLARE
TYPE rc IS REF cursor;
l_rc rc;
l_dummy all_objects.object_name%TYPE;
l_start NUMBER DEFAULT dbms_utility.get_time;
BEGIN
FOR i IN 1 .. 10000
loop
OPEN l_rc FOR
'select object_name from all_objects where object_id = ' || i;
fetch l_rc INTO l_dummy;
close l_rc;
END loop;
dbms_output.put_line ( round( (dbms_utility.get_time - l_start)/100, 2) || 'seconds');
END;
/또 다른 터미널 창을 열어서 top 도 수행하고 다음과 같이 대기 이벤트도 조회합니다.
$ top
cpu 를 과도하게 사용하는 프로세서가 하나 있습니다.
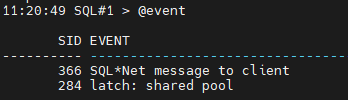
SQL#1> @event
SQL#1> @event
SQL#1> select sql_text
from v$sql
where sql_text like 'select object_name%';
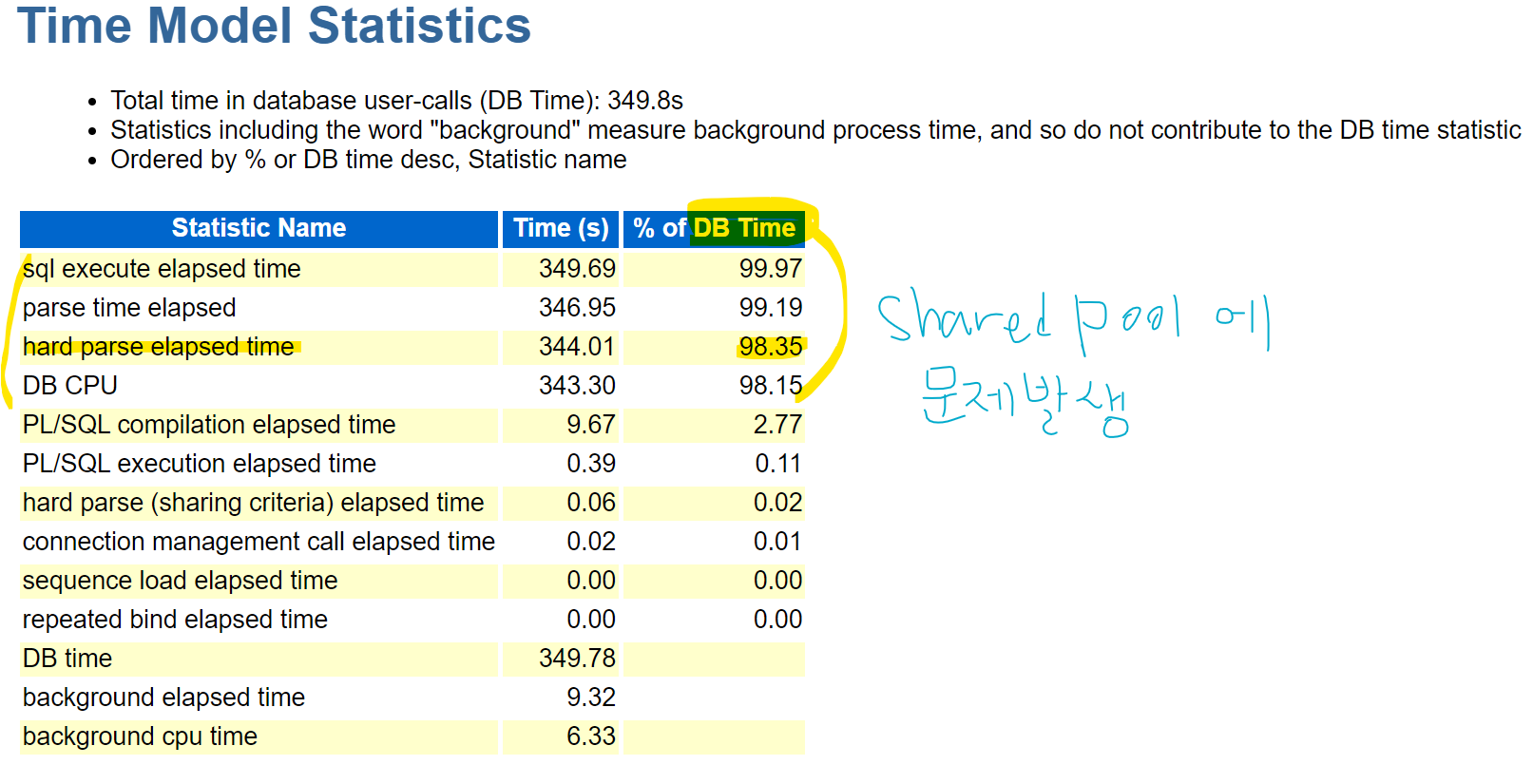
설명: 공유 풀안에 공유 되지 않은 sql이 가득차 있습니다.
공유가 안되었다는것은 다시 파싱했다는 뜻입니다.
파싱을 하기 위해서 cpu 를 많이 소모했다는것입니다.
cpu 를 100% 가까이 사용하는 세션이 서버에 있으면 엄청 느려집니다.
그 원인을 찾아서 해결해야합니다.
#4. awr report 생성
SQL#1> @?/rdbms/admin/awrrpt.sql

#5. addm report 생성
SQL#1> @?/rdbms/admin/addmrpt.sql
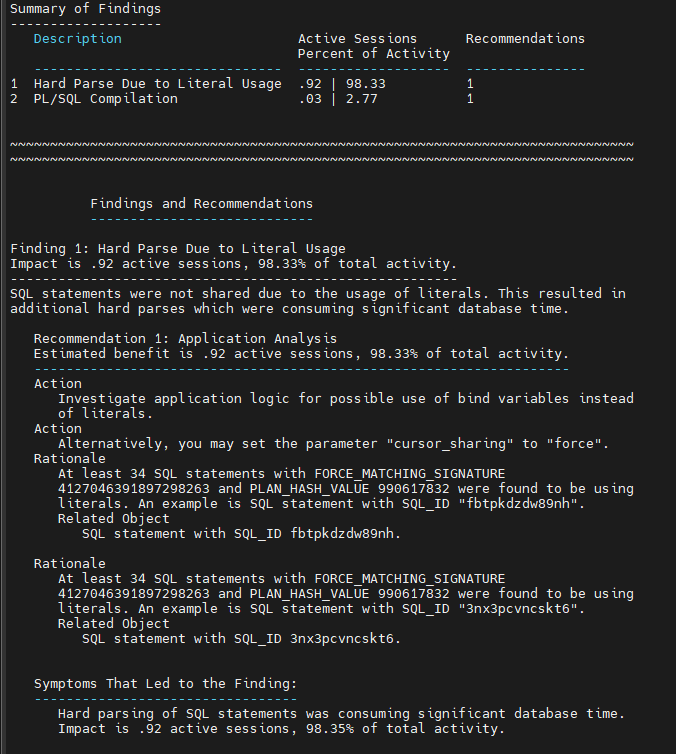

해결방법
1. 바인드 변수 사용
2. 파라미터 변경
ADDM 레포트에 추천 해결방법은 SQL이 공유가 될 수 있도록
Literal SQL 을 Bind variable 로 변경하라는 것입니다.
- Literal SQL 의 예:
select empno, ename, sal from emp where empno = 7788;
select empno, ename, sal from emp where empno = 7902;
select empno, ename, sal from emp where empno = 7566;
뒤에 사원번호만 틀려도 오라클은 다른 SQL로 인식해서 다시 파싱합니다.
그래서 튜닝방법이 바인드 변수로 변경해줘야합니다.
#6. 스냅샷
@snap
#7. 공유가 되는 튜닝된 부하를 일으킨다
#8. 스냅샷
@snap
#9. awr 비교 레포트 생성
SQL#1> @?/rdbms/admin/awrddrpt.sql
4개의 스냅샷 번호를 넣을 예정
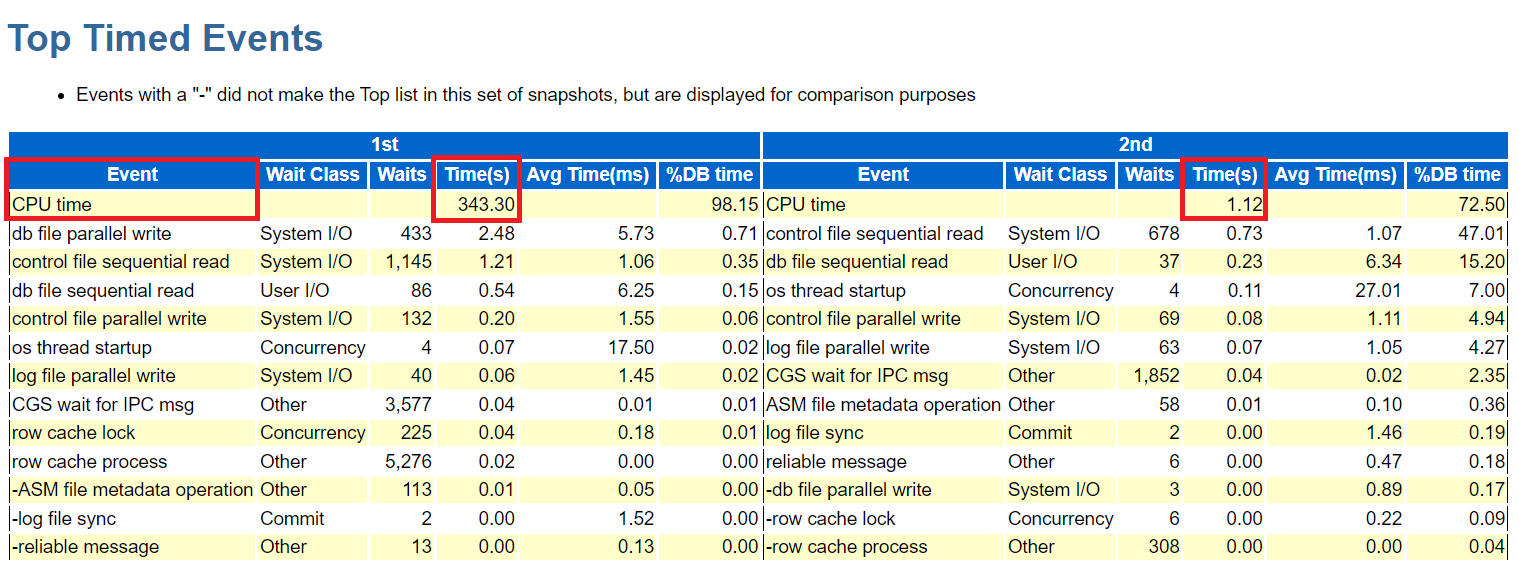
awr 비교 레포트를 보니 CPU time 이 튜닝 전과 후로 차이나게 줄어들었다
ADDM 레포트가 권장하는 해결방법 2가지
- PL/SQL 로직에서 literSQL 을 bind 변수로 변경
- cursor_sharing 을 force 로 변경하면 알아서 모든 literal SQL을 오라클이 bind 변수로 자동으로 변경해줍니다.
점심시간 문제 다음의 literl SQL 을 scott 유져에서 수행하고 공유풀에 올라가있는지 확인 하시오.
select empno, ename, sal from emp where empno = 7788;
select empno, ename, sal from emp where empno = 7902;
select sql_text
from v$sql
where sql_text like 'select empno%';▣ 예제53. 하드 파싱을 줄이기 위한 해결방법을 알아야해요.
하드 파싱이 shared pool latch 경합의 원인이 되고 있습니다.
하드 파싱(hard parsing) 을 줄이기 위한 방법 2가지 ?
-
literal SQL 을 바인드 변수로 변경합니다.
-
cursor_sharing 파라미터는 force 로 지정하면 자동으로 전부 litersql 이 바인드 변수로 변경됩니다.
■ 실습
#1. scott 유져에서 아래의 2개의 SQL 을 실행하고 공유풀에 존재하는지 확인합니다.
SQL#1> connect scott/tiger
SQL#1> select empno, ename, sal from emp where empno = 7788;
SQL#1> select empno, ename, sal from emp where empno = 7902;
SQL#1> select sql_text from v$sql where sql_text like '%select empno%';
설명 : 위의 2개의 sql이 공유가 안되어서 둘다 보입니다. 만약 공유가 되어지면 1개만 보입니다.
#2. cursor_sharing 을 force 로 변경합니다.
SQL#1> show parameter cursor_sharing
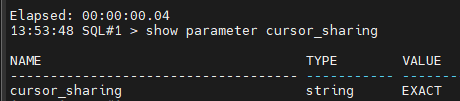
VALUE 설명
- EXACT : 리터럴 SQL 을 그냥 그대로 리터럴 SQL 로 사용하겠다.
- FORCE : 리터럴 SQL 을 바인드 변수로 변경하겠다.
- similar : 데이터의 선택도에 따라 리터럴 SQL 을 바인드 변수로 변경할 수도 있고 변경안할 수도 있다. (권장하지 않음)
SQL#1> alter system set cursor_sharing=force scope=both sid='*';
#3. 양쪽 인스턴스를 둘다 내렸다 올립니다.
#4. 다시 아래의 2개의 SQL 을 실행합니다.
SQL#1 > show parameter cursor_sharing
cursor_sharing string FORCE

SQL#1> connect scott/tiger
SQL#1> select empno, ename, sal from emp where empno = 7788;
SQL#1> select empno, ename, sal from emp where empno = 7902;
#5. 공유풀에 2개의 SQL이 어떻게 되어 들어있는지 확인합니다.
SQL#1 > select sql_text from v$sql where sql_text like '%select empno%';

오라클이 알아서 바인드 변수로 변경함.
#6. 리터럴 SQL 을 10000번 수행해서 하드 파싱을 유발하는 PL/SQL 코드를 수행하시오.
하드 파싱 유발 pl/sql
SQL> DECLARE
TYPE rc IS REF cursor;
l_rc rc;
l_dummy all_objects.object_name%TYPE;
l_start NUMBER DEFAULT dbms_utility.get_time;
BEGIN
FOR i IN 1 .. 10000
loop
OPEN l_rc FOR
'select object_name from all_objects where object_id = ' || i;
fetch l_rc INTO l_dummy;
close l_rc;
END loop;
dbms_output.put_line ( round( (dbms_utility.get_time - l_start)/100, 2) || 'seconds');
END;
/SQL#1 > select sql_text from v$sql where sql_text like '%select object_name%';
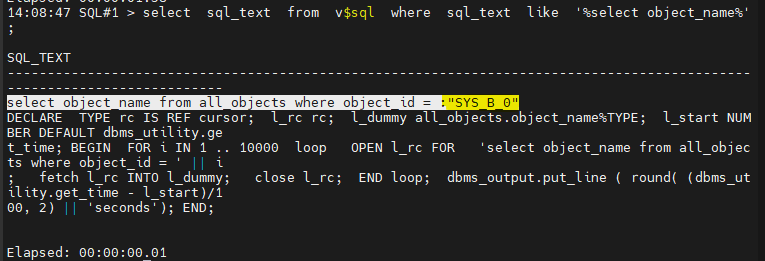
바인드 변수를 사용하여 소프트 파싱 함.
cursor_sharing=force 일 때 부작용도 있다
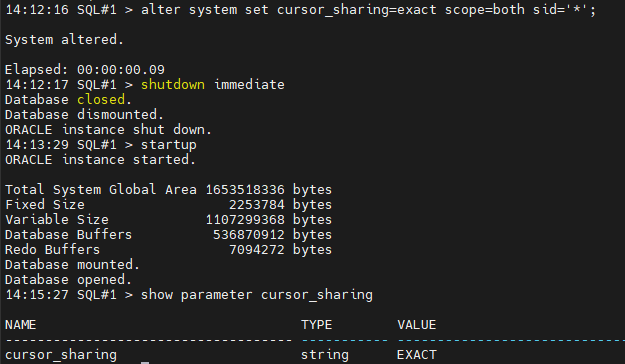
문제1. 다시 cursor_sharing 을 exact로 변경하시오
SQL#1> alter system set cursor_sharing=exact scope=both sid='*';
SQL#1> shutdown immediate
SQL#2> shutdown immediate
SQL#1> startup
SQL#2> startup
SQL#1> show parameter cursor_sharing
▣ 예제 54. cursor_sharing 파라미터를 force 로 지정하기 전에 확인 해야할 내용
- emp99 테이블을 총 10000건의 데이터가 있고 ename 에 인덱스가 있는 상황입니다.
- 10000 건중에 ename 이 scott1은 1건이 있고 scott99 는 9999건이 있습니다.
select count(*) from emp99 where ename='scott1';
한 건 있으니 index scan
select count(*) from emp99 where ename='scott99';
9999건 있으니 full table scan

scott1 이 검색 될 때는 index range scan 이라는 실행계획이 바람직 하며 scott99 가 검색 될 때는 full table scan 이 바람직 하다.
만약 다음과 같이 바인드 변수로 변경이 된다면 실행 계획은 딱 한개의 실행계획으로 고정 되어 버린다.
위의 SQL을 파싱할 때 만들었던 실행계획 1개로 계속해서 유지가 된다.
만약 index range scan 이라는 실행계획으로 유지된다면 scott1 을 검색할때는 속도가 빠르지만 scott99 가 검색될때는 속도가 느려진다.
반대로 full table scan 이라는 실행 계획으로 유지된다면 scott1 을 검색할때 속도가 느려진다.
바인드 변수로 자동으로 변경이 되면 위와같은 SQL 은 문제를 일으킨다
위와 같은 경우에 오라클에서 권장하는 해결 방법이 있다.
SQL#1> alter system set cursor_sharing=force scope=both sid='*';
SQL#1> shutdown immediate
SQL#2> shutdown immediate
SQL#1> startup
SQL#2> startup
SQL#1> show parameter cursor_sharing
cursor_sharing 이 force 라는 애기는 리터럴 SQL을 바인드 변수로 자동으로 변경하겠다
는것입니다.
그런데 특별하게 emp99 와 같은 테이블에 대해서는 바인드 변수로 변경하지 말라고
하는 힌트가 있습니다. 그게 바로 /+ cursor_sharing_exact / 입니다.
■ 실습
#1. cursor_sharing 파라미터 값을 확인합니다.
SQL#1> show parameter cursor_sharing
#2. 아래의 SQL을 실행합니다.
SQL#1> connect scott/tiger
SQL#1> select ename, sal from emp where empno = 7788;
#3. 2번에서 수행한 SQL을 공유풀에서 검색합니다.
SQL#1> select sql_text from v$sql where sql_text like '%select ename%';
select ename, sal from emp where empno = :"SYS_B_0"

#4. cursor_sharing_exact 힌트를 사용해서 SQL을 실행합니다.
SQL#1> select /+ cursor_sharing_exact / ename, sal from emp where empno = 7902;
설명 : 위의 힌트를 쓴 sql 은 바인드 변수로 변환하지 않습니다. 그냥 리터럴 SQL 로 수행합니다.
#5. 4번에서 수행한 SQL을 공유풀에서 검색합니다.
SQL#1 > select sql_text from v$sql where sql_text like '%cursor_sharing_exact%';

=> 오라클이 바인드 변수로 변경하지 않았고 리터럴 SQL 그대로 보인다.
▣ 예제 55. RAC 환경 튜닝 팁 1. 사용하지 않는 인덱스를 정리한다.
인덱스 불필요하게 많으면 테이블에 데이터 입력할 때 속도가 느려집니다.
왜 사용하지 않은 인덱스가 많이 생겼는가 ?
답변: 개발할 때 개발자들이 DBA 에게 인덱스 생성 요청을 많이 합니다.
생성 요청마다 그대로 인덱스를 생성하게 되면 불필요하게 인덱스가
많아집니다. DBA 가 잘 선별해서 필요한 인덱스를 생성해줘야합니다.
DBA 가 많이 선별해서 인덱스를 생성했는데도 불구하고 사용하지 않은
인덱스들이 생깁니다. 이럴때 다음과 같이 정리하면 됩니다.
■ 실습
#1.scott 유져로 접속해서 demobld.sql 스크립트를 수행합니다.
SQL#1> connect scott/tiger
SQL#1> @demobld.sql
#2. 사원 테이블에 월급에 인덱스를 생성합니다.
SQL#1> create index emp_sal on emp(sal);
#3. 인덱스를 모니터링하게 합니다.
SQL#1> alter index emp_sal monitoring usage;
SQL#1> select index_name, used from v$object_usage;
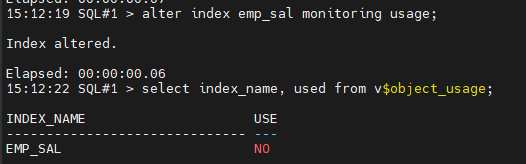
#4. 사원 테이블의 월급을 조회해서 emp_sal 인덱스를 사용합니다.
SQL#1> select /+ index(emp emp_sal) / ename, sal
from emp
where sal = 3000;
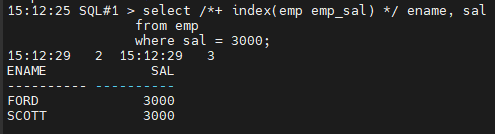
#5. 인덱스를 사용했는지 확인합니다.
SQL#1> select index_name, used from v$object_usage;

※ dba 들이 꼭 물어보는 질문 : 인덱스 모니터링이 db 에 부하를 주지 않나요 ?
답변 : 부하를 주지 않으니 걱정하지 말고 모니터링 사용 하세요
#6. emp_sal 인덱스의 모니터링을 끄시오
SQL#1> alter index emp_sal nomonitoring usage;
SQL#1> select index_name, used from v$object_usage;
설명 : 1~2 달 모니터링을 했는데 한번도 사용하지 않은 인덱스가 있다면 drop 한다.
문제1. 사원 테이블에 job 에 인덱스를 생성하고 인덱스 사용 여부를 확인하기 위해 모니터링을 거시오
emp_job 을 사용 후 사용했는지 확인 하시오
SQL#1> create index emp_job on emp(job);
SQL#1> alter index emp_job monitoring usage;
select /*+ index(emp emp_job) */ ename, job
from emp
where job = 'SALESMAN';
SQL#1> select index_name, used from v$object_usage;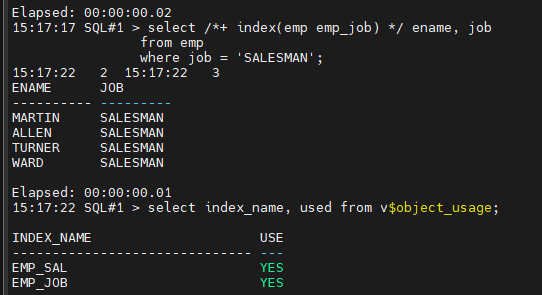
▣ 예제55. RAC 환경 튜닝 팁 2. 파티션 테이블 사용
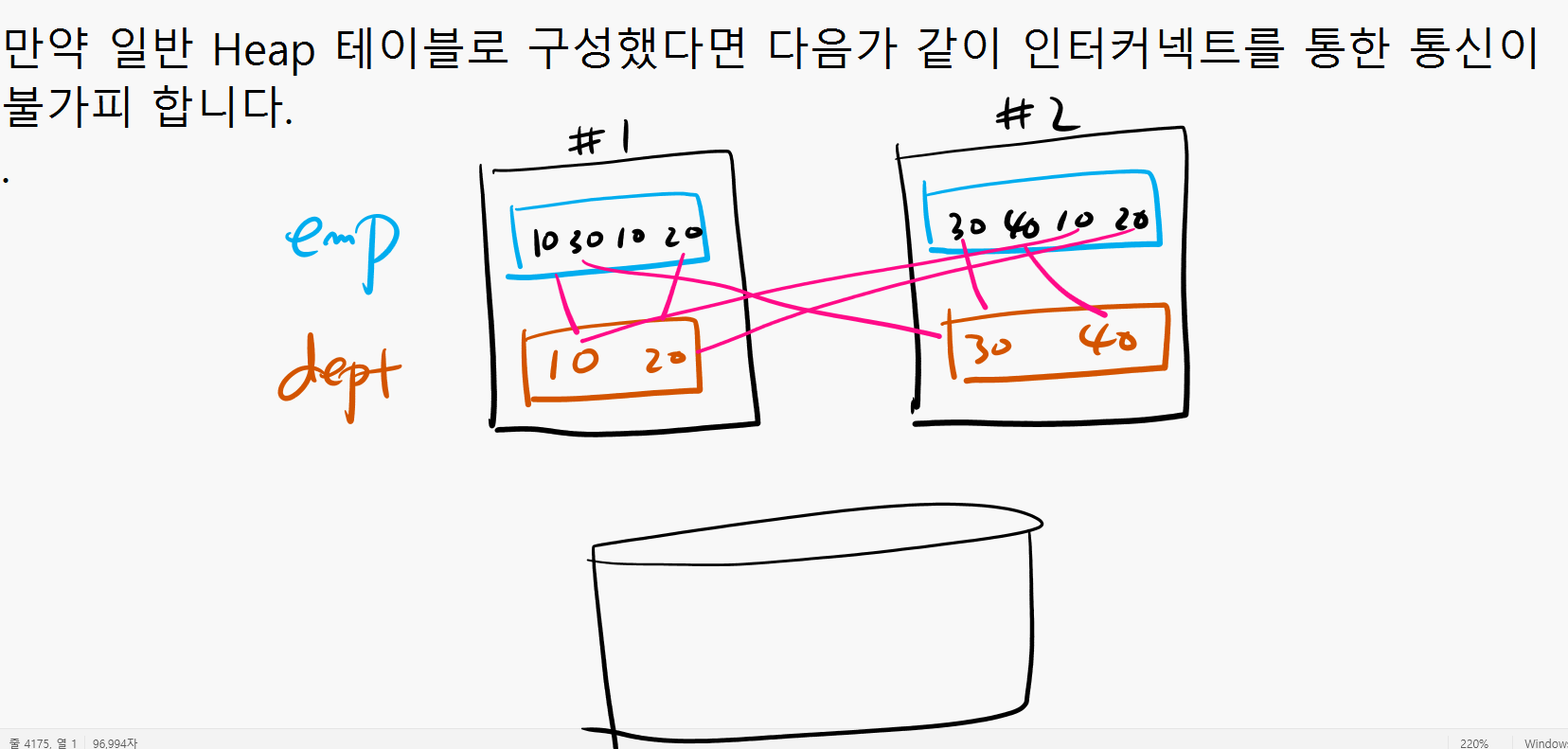
RAC 환경에서 파티션 테이블을 사용하게 되면 파티션 와이즈 조인을 할 수 있습니다.
파티션 와이즈 조인이란 ? 파티션끼리 조인하는것
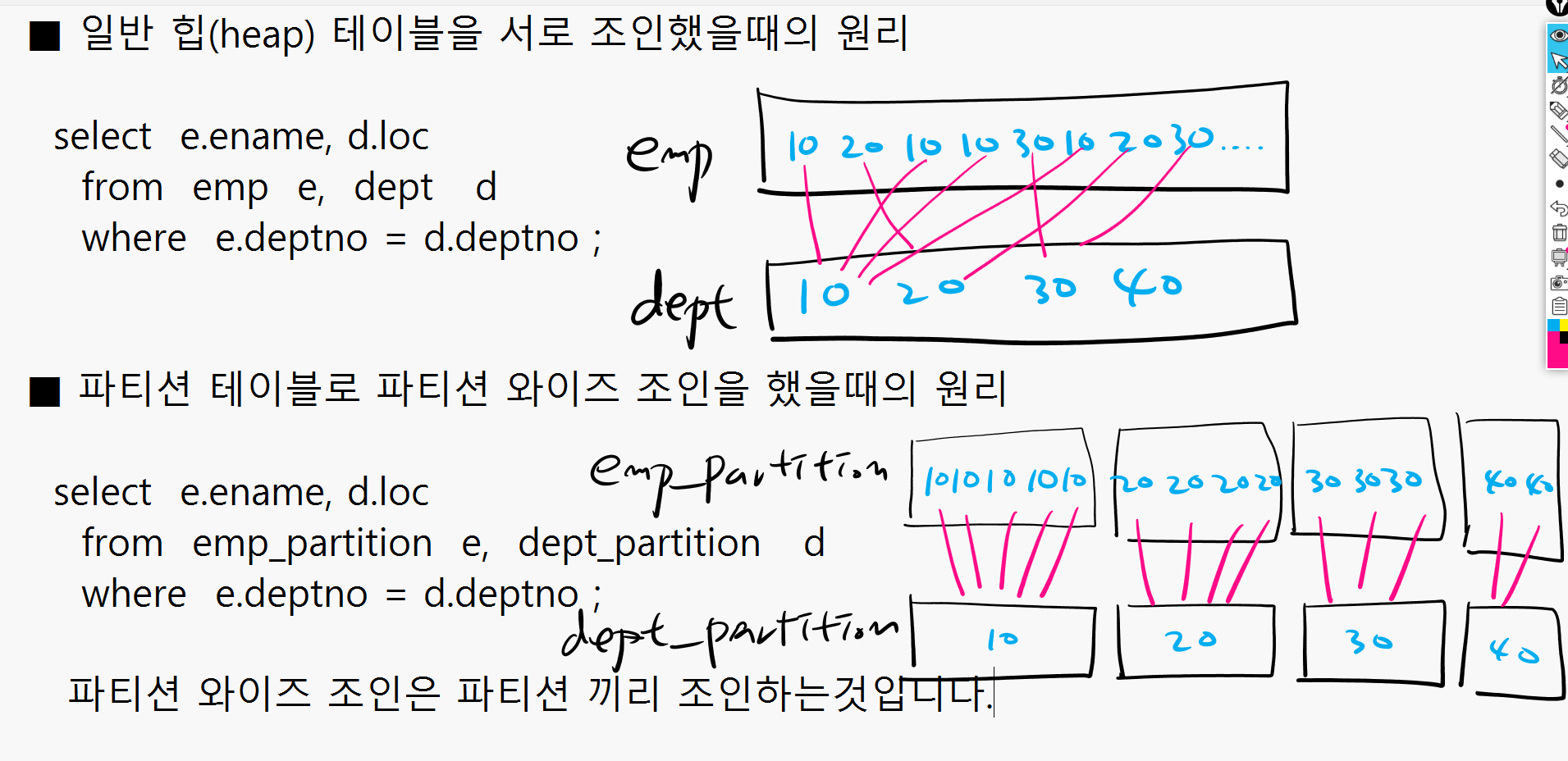
파티션끼리 조인하므로 인터 커넥트를 통해서 통신하는 양을 줄일 수 있다.
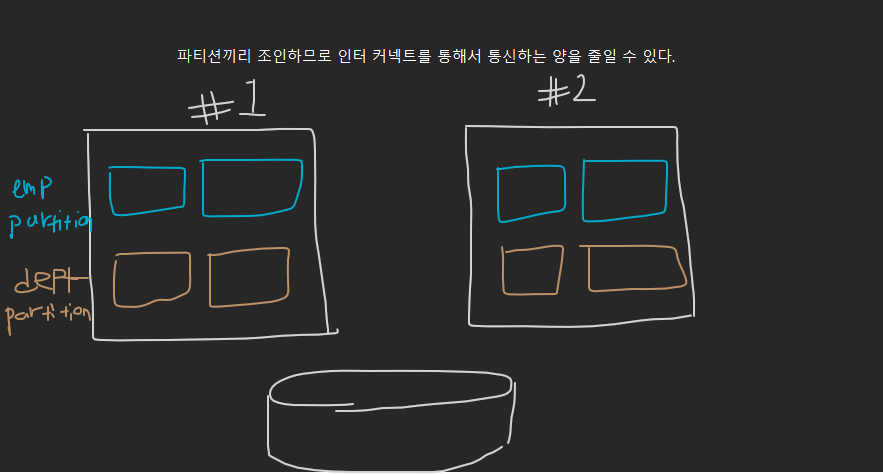
만약 일반 Heap 테이블로 구성했다면 다음과 같이 인터커넥트를 통한 통신이 불가피 하다
■ 실습
#1. emp 테이블을 부서번호를 기준으로 파티션 테이블로 구성합니다.
create table emp_partition
( empno number(4,0) ,
ename varchar2(10),
job varchar2(9),
mgr number(4,0),
hiredate date,
sal number(7,2),
comm number(7,2),
deptno number(2,0)
)
partition by range(deptno)
(partition p_deptno_10 values less than(20),
partition p_deptno_20 values less than(30),
partition p_deptno_30 values less than(40),
partition p_max values less than(maxvalue) );
insert into emp_partition
select * from emp;
select * from emp_partition;
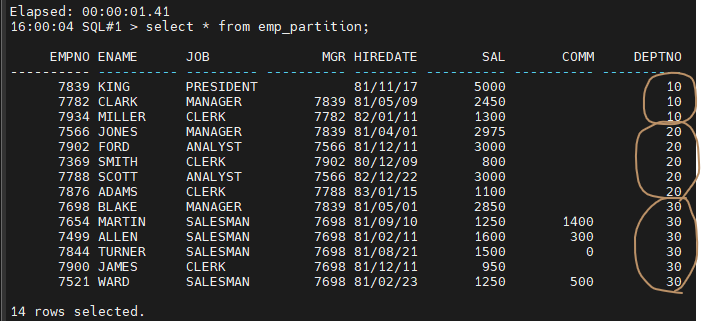
파티션 나눠져 있음.
#2. dept 테이블을 부서번호를 기준으로 파티션 테이블로 구성합니다.
create table dept_partition
( deptno number(10),
dname varchar2(14),
loc varchar2(13)
)
partition by range(deptno)
(partition p_deptno_10 values less than(20),
partition p_deptno_20 values less than(30),
partition p_deptno_30 values less than(40),
partition p_max values less than(maxvalue) );
insert into dept_partition
select * from dept;select * from dept_partition;#3. emp 와 dept 테이블을 파티션 와이즈 조인 합니다.
exec dbms_stats.gather_table_stats('scott','emp_partition');
exec dbms_stats.gather_table_stats('scott','dept_partition');
#4. emp 와 dept 테이블을 파티션 와이즈 조인 합니다
explain plan for
select e.ename, d.loc
from emp_partition e, dept_partition d
where e.deptno = d.deptno ;
select * from table(dbms_xplan.display);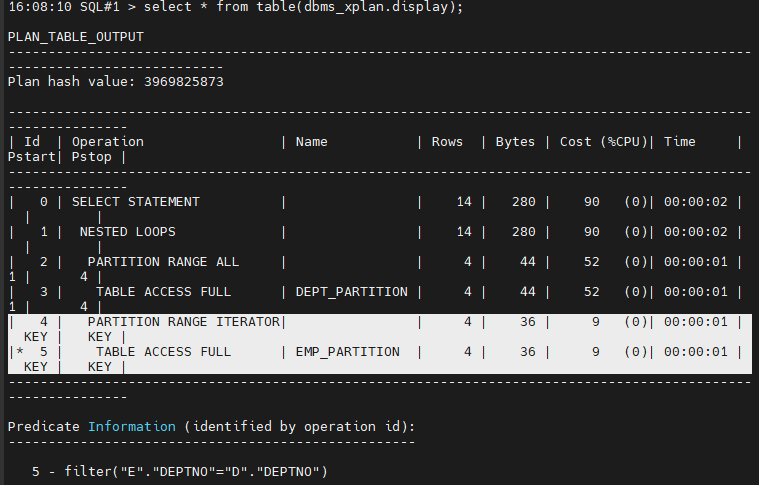
설명: 실행계획을 보면 파티션 와이즈 조인을 했습니다.
실행계획에 key 가 출력되는데 key 기반으로 필요한 파티션에 대해서만 접급해서 파티션 와이즈 조인을 했습니다.
▣ 예제56. RAC 환경 튜닝팁3.
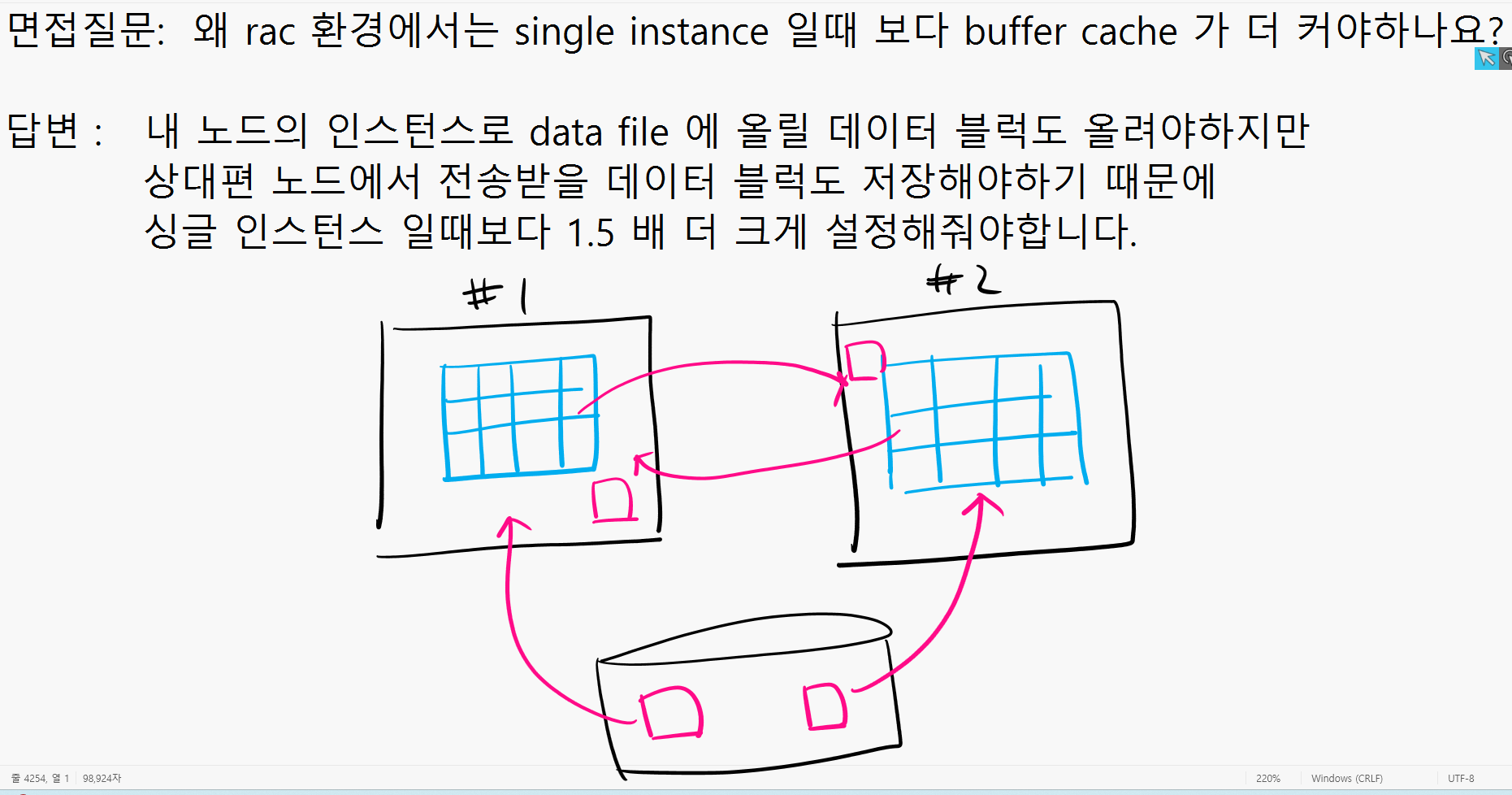
rac 환경에서는 single instance 보다 buffer cache 를 더 크게 설정해야합니다.
면접질문: 왜 rac 환경에서는 single instance 일때 보다 buffer cache 가 더 커야하나요?
답변 : 내 노드의 인스턴스로 data file 에 올릴 데이터 블럭도 올려야하지만 상대편 노드에서 전송받을 데이터 블럭도 저장해야하기 때문에 싱글 인스턴스 일때보다 1.5 배 더 크게 설정해줘야합니다.
■ 실습
#1. 1번 노드와 2번 노드에 현재 buffer cache 의 크기를 확인하시오 !

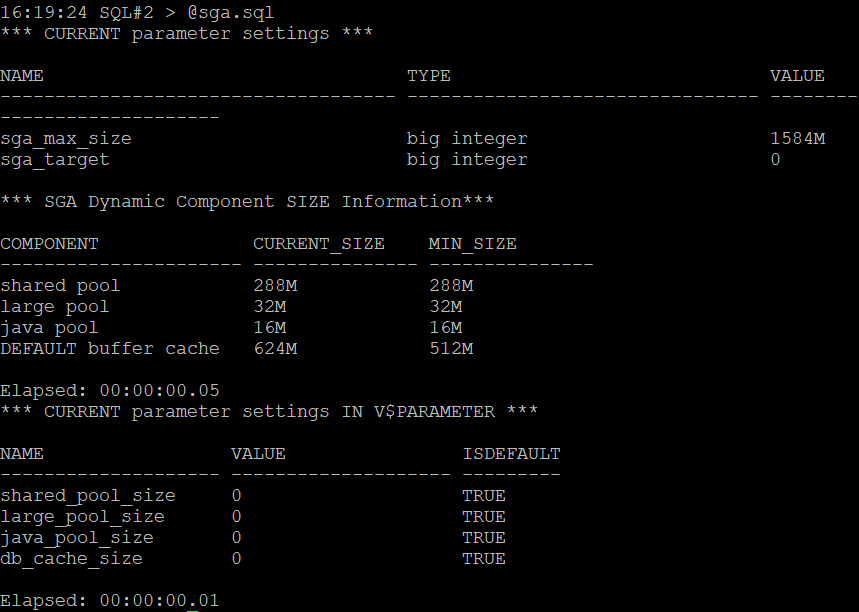
#2. db buffer cache 사이즈를 700m 늘리시오 !
SQL#1 > alter system set db_cache_size = 700m scope=spfile sid='*';
SQL#1 > shutdown immediate
SQL#1 > startup
SQL#1 > @sga
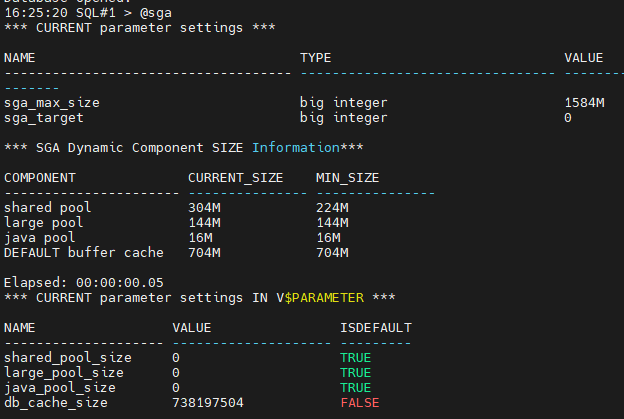
#3. 2번 인스턴스는 그냥 내렸다 올립니다.
SQL#2 > shutdown immediate
SQL#2 > startup
SQL#2 > @sga

마지막 문제 다시 양쪽 노드에 buffer cache size 를 600m 로 변경 하시오 !
변경 된 화면 캡쳐 해서 올리고 검사 받기 !
SQL#1 > alter system set db_cache_size = 600m scope=spfile sid='*';
SQL#1 > shutdown immediate
SQL#1 > startup
SQL#1 > @sga
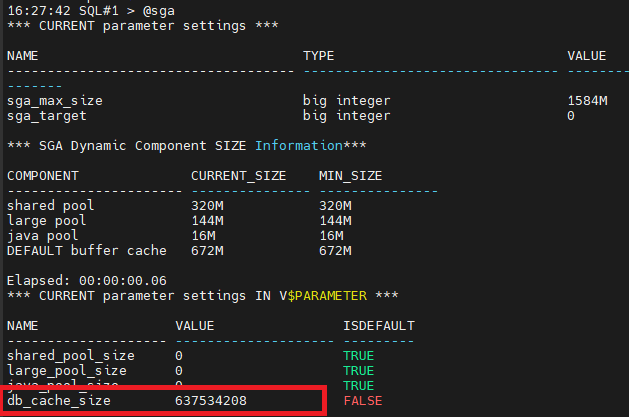
#3. 2번 인스턴스는 그냥 내렸다 올립니다.
SQL#2 > shutdown immediate
SQL#2 > startup
SQL#2 > @sga
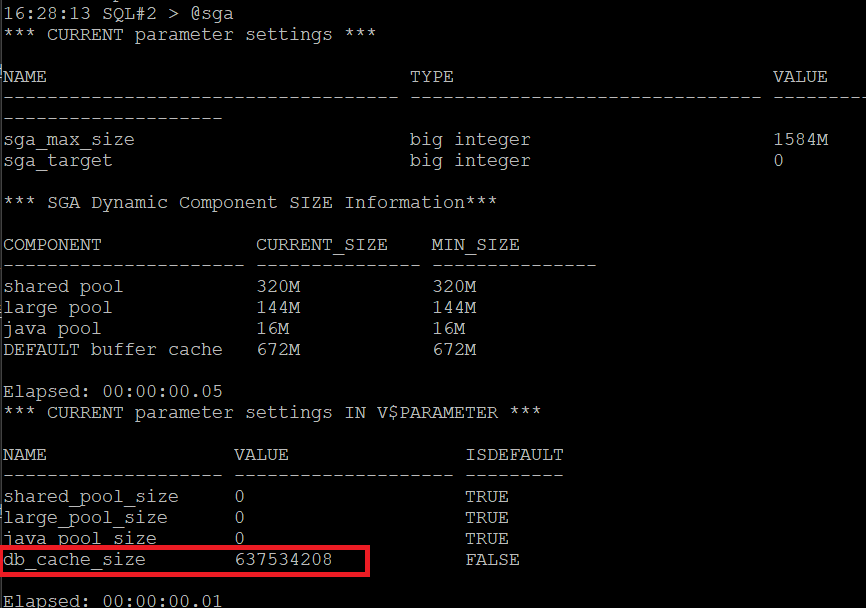
변경되면 디폴트가 아니어서 false 가 됨.
