■ RAC DB 서버 튜닝
SQL 튜닝으로만으로 해결될 수 없는 요소들을 튜닝 !
튜닝의 우선순위 ! 1. SQL 튜닝
2. RAC 서버 튜닝(파라미터 튜닝)
면접질문: db 튜닝을 어떻게 했나요?
답변: 1순위로 SQL 튜닝을 했고 SQL튜닝만으로는 해결되지 않는 부분은
파라미터 튜닝을 했습니다.

- latch : 1. shared pool latch 경합
scott99 는 9999 개 scott1 은 1건이 있는 컬럼의 경우 바인드 변수로 자동 변환
그렇게 되면 문제점 : 실행계획 고정
select empno, ename from emp99 where ename='scott1';
select empno, ename from emp99 where ename='scott99';
select 문의 처리과정 ?
parsing
옵티마이져에 의해서 실행계획이 생성
execute
fetch 아래의 select 문의 처리 과정 ?
select empno, ename from emp99 where ename= :v_empno;-
parsing ------------> 실행계획 생성
-
binding
-
execute
-
fetch
해결방법
-
cursor_sharing = force 로 두고
-
emp99 같은 극단적인 데이터 분포를 갖는 테이블을 쿼리하는 select 문에서 오라클 힌트 cursor_sharing_exact 를 사용합니다.
select /+ cursor_sharing_exact / ename, sal
from emp99
where ename= :v_ename;
-
▣ 예제58. buffer cache latch 경합을 줄이기 위한 튜닝
- buffer cache latch 경합은 왜 발생하는가 ?
데이터를 검색하는 select 문을 수행하면 서버 프로세서는 먼저 그 데이터를
메모리에서 찾고 없으면 data file 에서 찾아서 메모리에 올려둡니다.
메모리에 올려두는 이유는 다음번에 또 이 데이터를 검색하려하면 바로
메모리에서 바로 가져다 줄려고 메모리에 올려놓습니다.
이 메모리가 바로 db buffer cache 입니다.
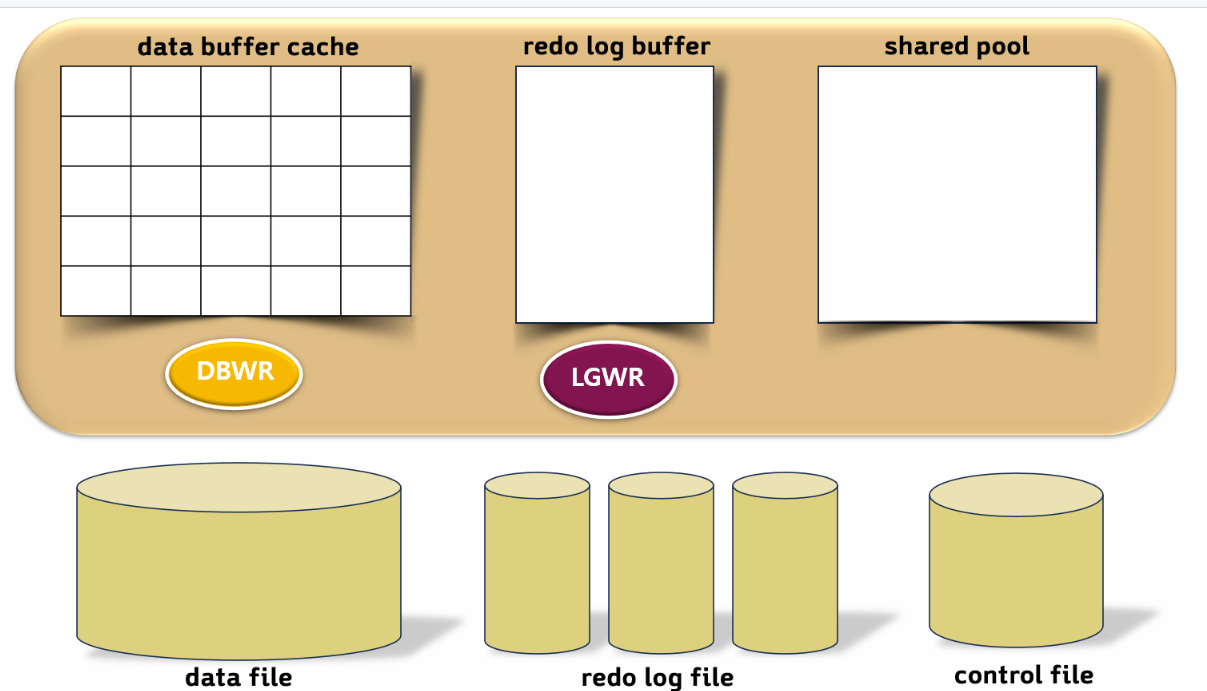
select 문의 처리 과정
parsing : 문법 검사 후 실행 계획을 만든다
execute : 데이터 찾기
fetch
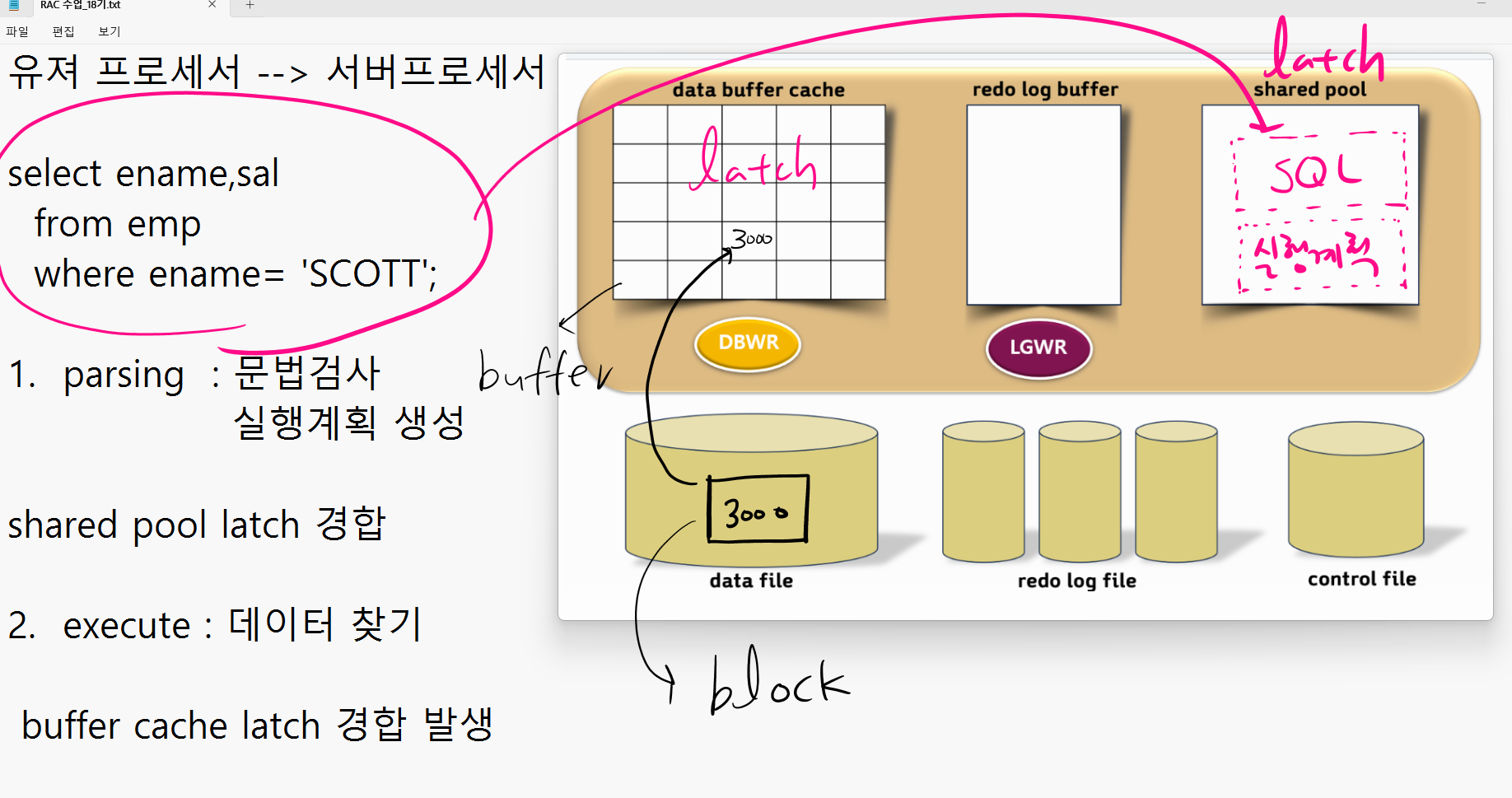
parsing 할 때
select 문 을 shared pool 에 올린다 latch 를 잡아야 공간을 확보하고 올릴 수 있다.
shared pool에 실행 계획도 같이 올린다.
shared pool latch 경합 발생
execute 할 때
datafile 에서 데이터를 찾음 데이터는 block
db buffer cache 는 버퍼로 구성
서브 프로세서가 블락을 버퍼로 올리는데 latch 를 잡아야
db buffer cache latch 경합 발생
설명: execute 단계에서 scott 의 데이터를 찾는데 메모리에 없으면 data file 에서 찾아서 메모리에 올립니다. 이때 buffer cache latch를 확보해야 올릴 수 있습니다.
그런데 동시에 buffer cache 를 사용하려는 세션들이 많게 되면 latch 경합이 발생하게 됩니다. 이 latch 의 갯수가 정해져 있기 때문입니다.
■ 실습1
#1. owi 유져로 접속합니다.
SQL#1> connect owi/owi
#2. 사진을 찍습니다.
SQL#1> exec dbms_workload_repository.create_snapshot;
#3. buffer cache latch 경합을 일으킵니다.
SQL#1> @exec
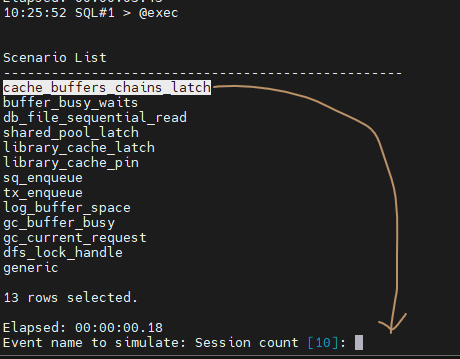
대기 이벤트 확인
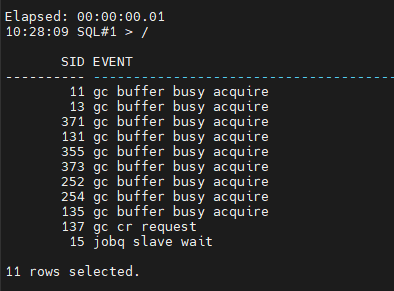
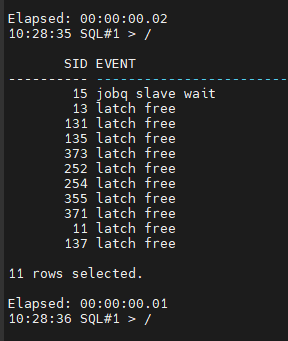
#4. 사진을 찍습니다.
#5. awr report 를 생성합니다.
SQL#1> @?/rdbms/admin/awrrpt.sql
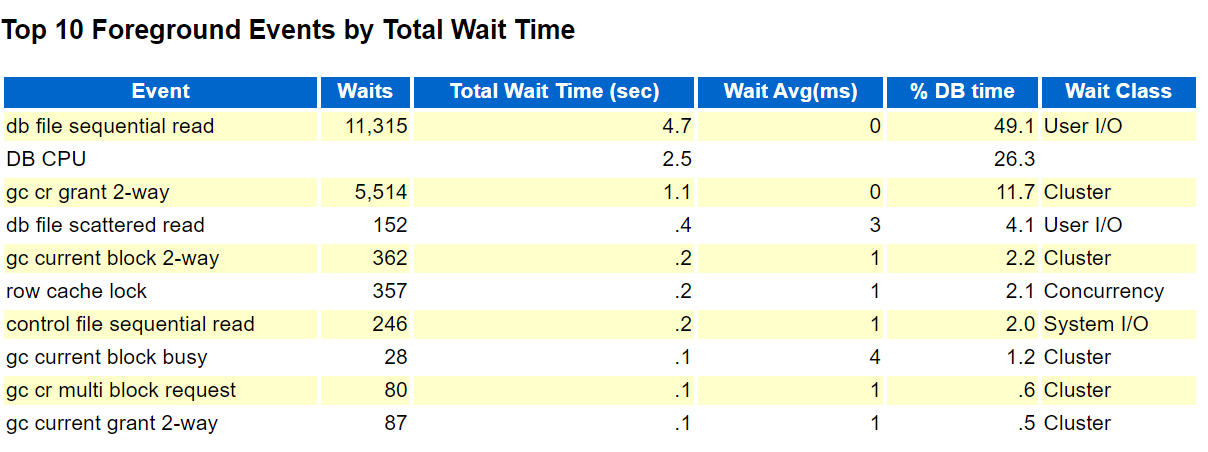
설명: latch free 대기 이벤트가 나오고 있습니다. 이 대기 이벤트는 buffer cache 쪽에 관련한 대기 이벤트입니다. 이 경우의 해결방법은 latch free 경합을 일으키는 SQL 을 찾아서 튜닝하는 방법으로 해결을 하면 됩니다.
#6. addm report 를 생성합니다.

셀파 소프트 , 엑셈 제품을 사용하면 찾을 수 있고 또는 oracle EM 을 통해서도 찾을 수 있습니다.
찾았으면 SQL 튜닝을 하면 해결 됩니다.
■ 실습2. db_block_lru_latches 파라미터 조정하기
#1. 현재 db_block_lru_latches
SQL#1> @hidden
Enter value for param_name: latch
_db_block_lru_latches 32
#2. 양쪽 인스턴스의 db_block_lru_latchs 파라미터의 갯수를 늘립니다.
SQL#1> alter system set "_db_block_lru_latches"=40 scope=spfile sid='*';
#3. 양쪽 인스턴스를 내렸다 올립니다.
SQL#1> shutdown immediate
SQL#1> startup
SQL#2> shutdown immediate
SQL#3> startup
#4. 잘 변경되었는지 확인합니다.
SQL#1>@hidden
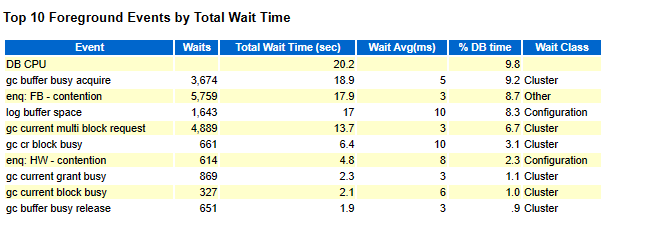
▣ 예제59. 리두 로그 버퍼 캐쉬 영역에 대한 대기 이벤트

설명: log buffer space 대기 이벤트는 서버 프로세서가 리두 로그 버퍼에 데이터를
쓰기 위해 대기해야할 때 발생합니다. 주로 리두 로그 버퍼가 충분히 빠르게
디스크로 기록되지 않아서 발생합니다.
왜 LGWR 가 빨리빨리 내려쓰지 못할까 ? 그 원인을 알아야합니다.
해결방법
- 리두 로그 파일이 있는 하드웨어 구성이 RAID 0+1 이어야하는데 RAID5 로 되어있어서
입니다. 그래서 RAID 구성을 확인해봐야합니다.
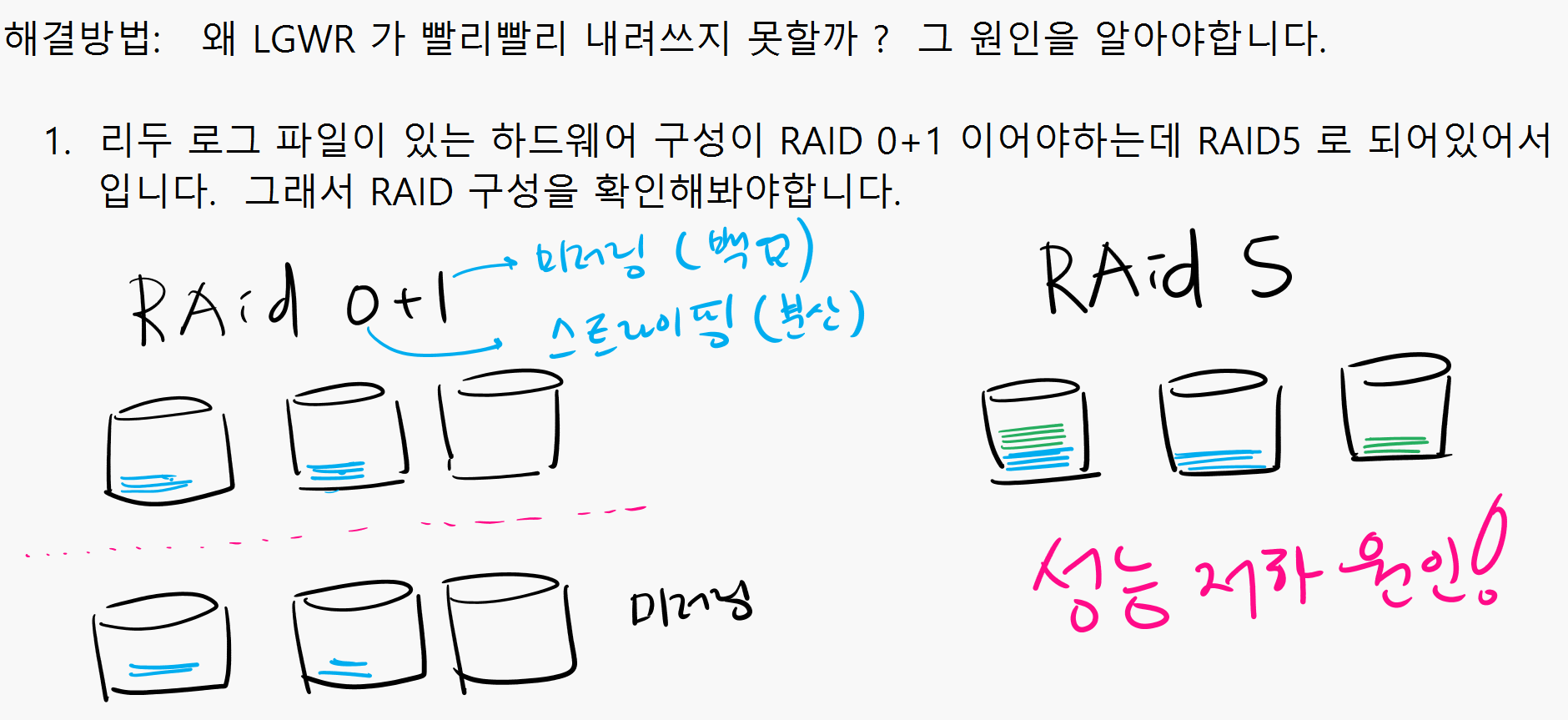
설명: 오라클의 주요 파일들중에 redo log file 이 write 가 가장 활발하게 일어나는 파일
입니다. 그러므로 redo log file 이 있는 하드웨어 raid 구성은 반드시 raid5 가
아니라 raid 0+1 로 구성해야합니다. raid 5 면 write 가 느려집니다.
- LGWR 가 내려쓰려고 하는데 아직 리두 로그 파일이 ACTIVE 상태면 INACTIVE 가 될 때까지 기다려줘야합니다. 그래서 리두 로그 파일의 갯수를 늘려서 해결합니다.
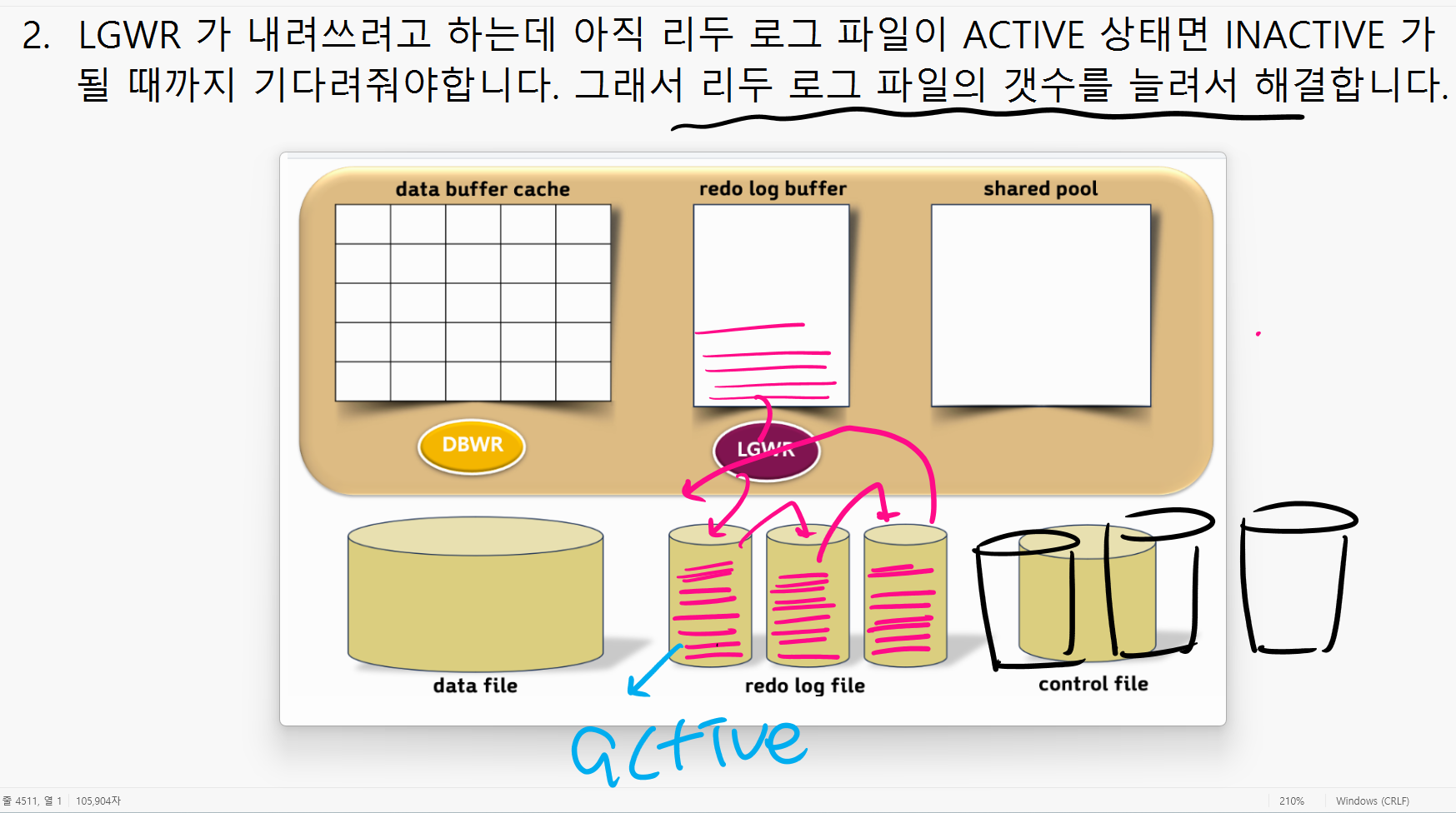
- Log buffer 사이즈 늘리기 (일시적인 방법)
■ 실습
#1. owi 유져로 접속합니다.
SQL#1> connect owi/owi
#2. 사진을 찍습니다.
SQL#1> exec dbms_workload_repository.create_snapshot;
#3. 대기 이벤트 모니터링 할 별도의 터미널 창 준비
#4. log buffer space 대기 이벤트를 일으킵니다.
SQL#1> @exec
이벤트 모니터링
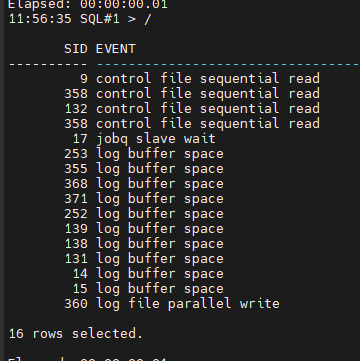
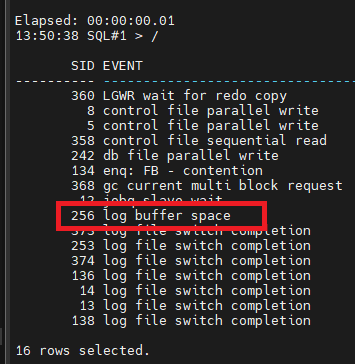
#5. 사진을 찍습니다.
SQL#1> exec dbms_workload_repository.create_snapshot;
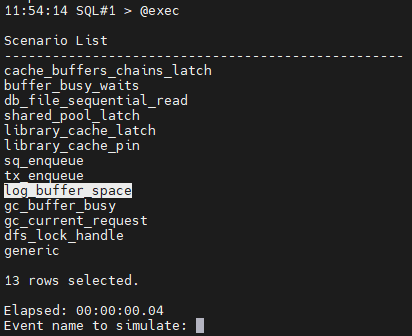
#6. awr report 를 생성합니다.
SQL#1> @?/rdbms/admin/awrrpt.sql
#7. addm report 를 생성합니다.
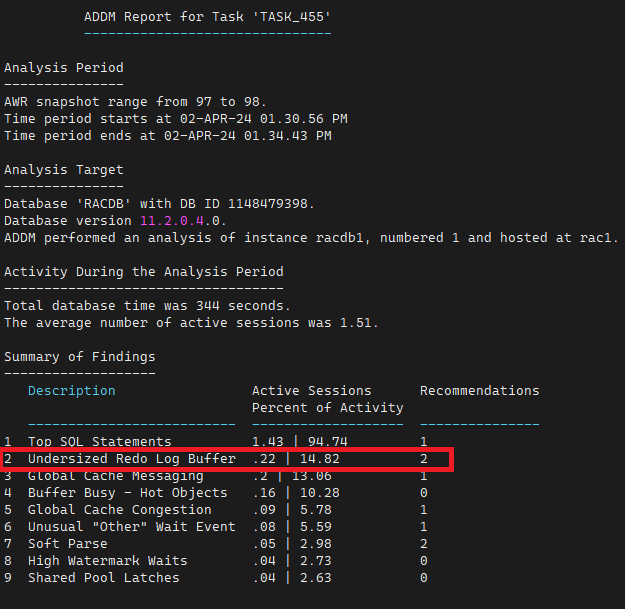
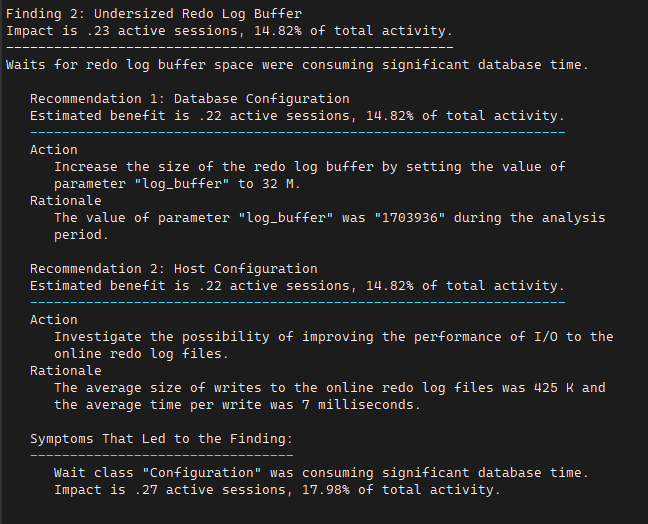
SQL#1> @?/rdbms/admin/addmrpt.sql
-
log buffer space 대기 이벤트의 해결방법 ?
- redo log file 의 디스크의 RAID 구성을 RAID 0+1 구성
- 리두로그 그룹의 갯수를 더 늘림
- redo log buffer 의 크기를 늘림
문제2. 리두 로그 그룹의 갯수를 인스턴스 마다 1개씩 더 늘리시오 !
SQL#1 > select group#, status, sequence#, thread# from v$log;
GROUP# STATUS SEQUENCE# THREAD#
---------- ---------------- ---------- ----------
1 INACTIVE 49 1
2 CURRENT 50 1
3 INACTIVE 45 2
4 INACTIVE 46 2
6 INACTIVE 47 1
7 INACTIVE 47 2
8 INACTIVE 48 1
9 CURRENT 48 2SQL#1 > alter database add logfile thread 1 group 8;
SQL#2 > alter database add logfile thread 2 group 9;
SQL#1 > alter system switch logfile;
SQL#2 > alter system switch logfile;
SQL#1 > @logfile위와 같이 튜닝하고 다시 부하를 준 다음에 비교 레포트를 뜨게 되면
다음과 같이 출력이 된다.
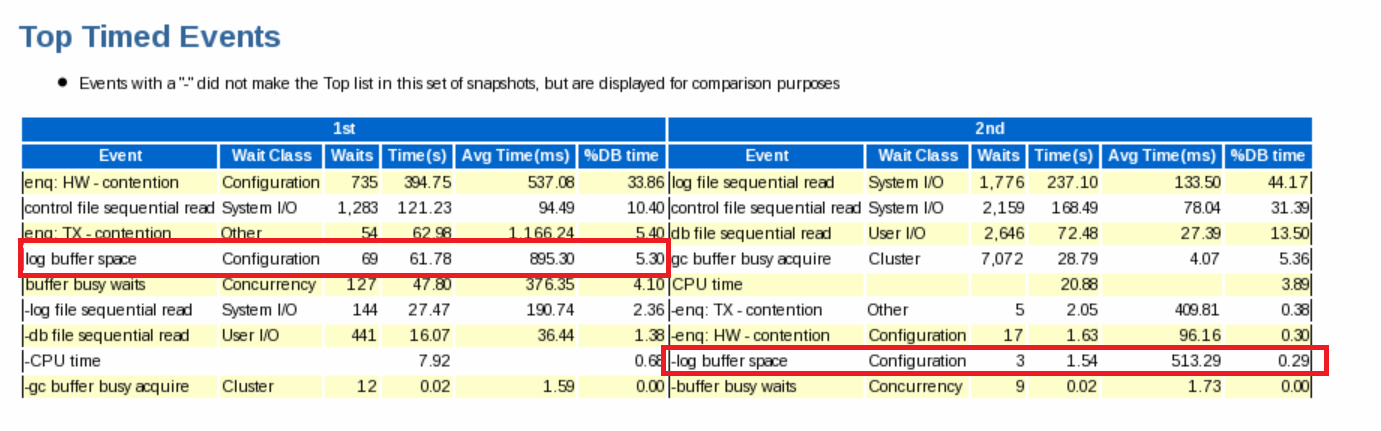
▣ 예제 60. 바쁜 업무시간에 DDL 명령어 사용 금지
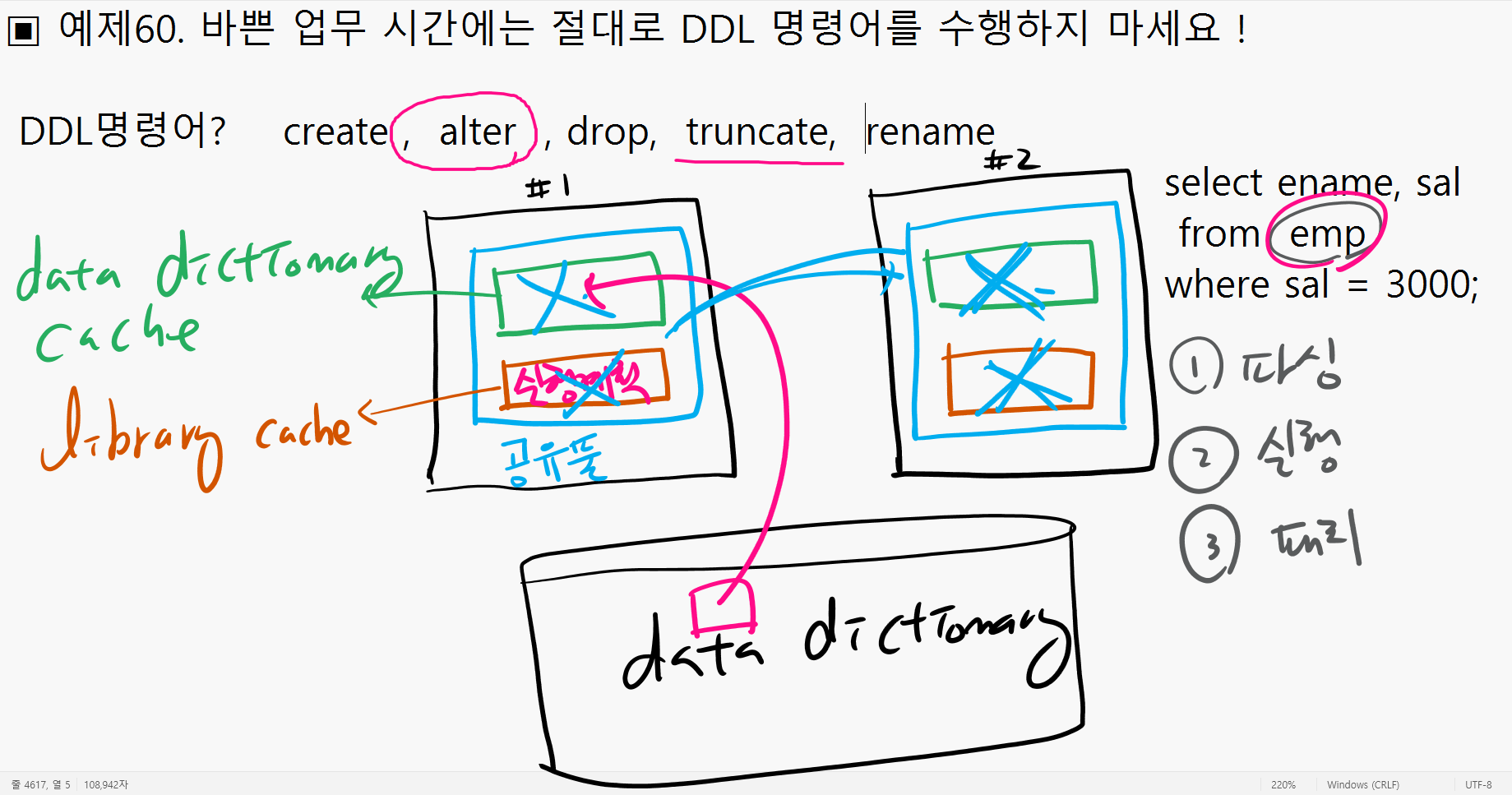
데이터 딕셔너리는 시스템 테이블 스페이스에 있음 데이터 파일 안에 있다
설명: 바쁜 업무시간에 DDL 문을 실행하게 되면 DDL명령어와 관련된 테이블에 대한 파싱정보가 공유풀에서 사라지게 됩니다. 그러면 다시 파싱을 해야하므로 관련된 테이블을 SELECT 하는 모든 쿼리문이 다같이 느려지게 됩니다. 그래서 컬럼 추가와 같은 DDL 명령어는 업무시간 피해서 수행해야합니다.
관련된 대기 이벤트는 Library cache 에 대한 대기 이벤트 인데
library cache pin 과 library cache lock 대기 이벤트 입니다.
■ 실습
#0. owi 유져로 접속합니다.
#1. 사진을 찍습니다.
#2. 별도의 터미널 창을 열어서 대기 이벤트를 모니터링 합니다.
#3. library cache 에 관한 대기 이벤트를 일으킵니다.
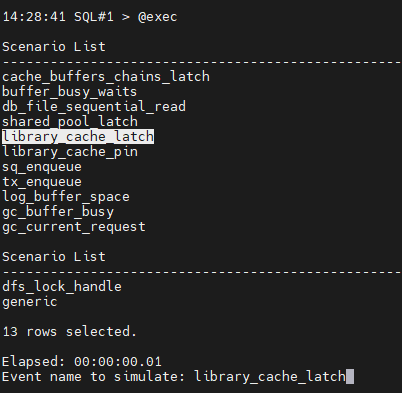
두번째 터미널 창
@event
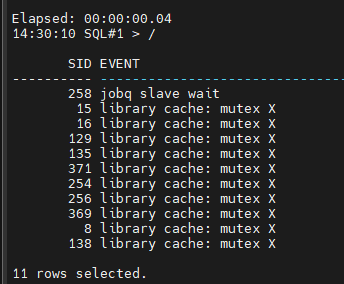
#4. 사진을 찍습니다.
@snap
#5. awr report 를 생성합니다.
SQL#1 > @?/rdbms/admin/awrrpt.sql
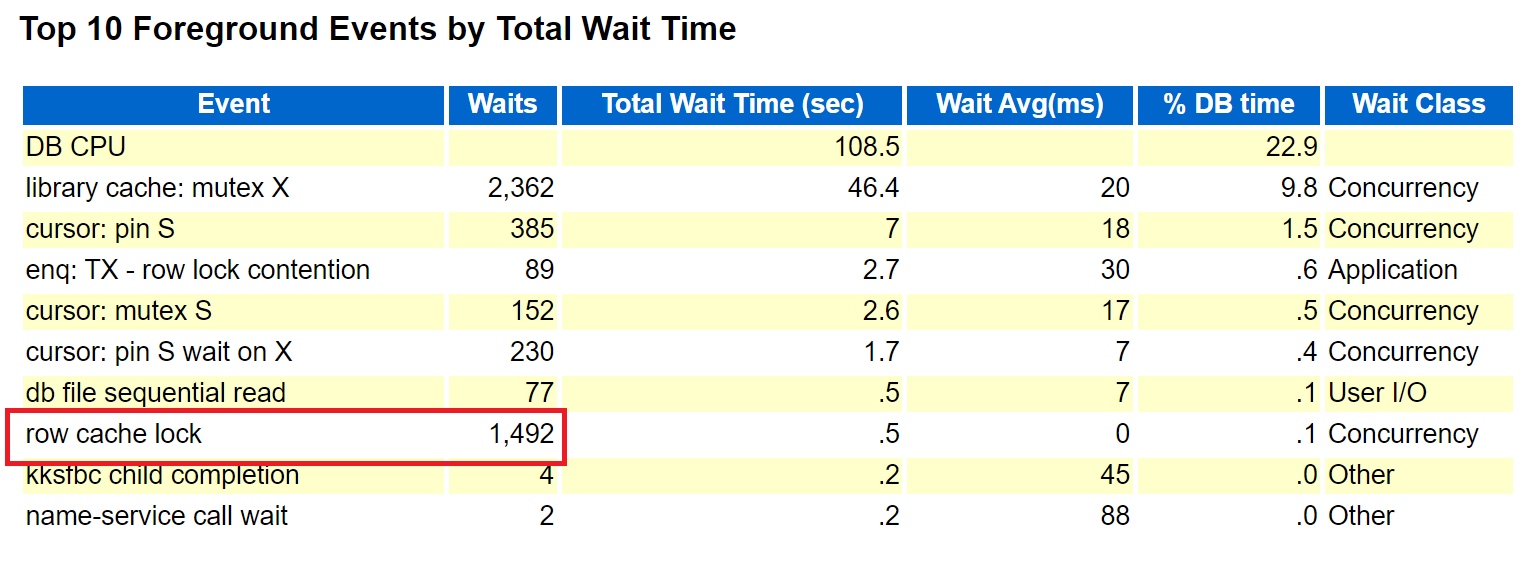
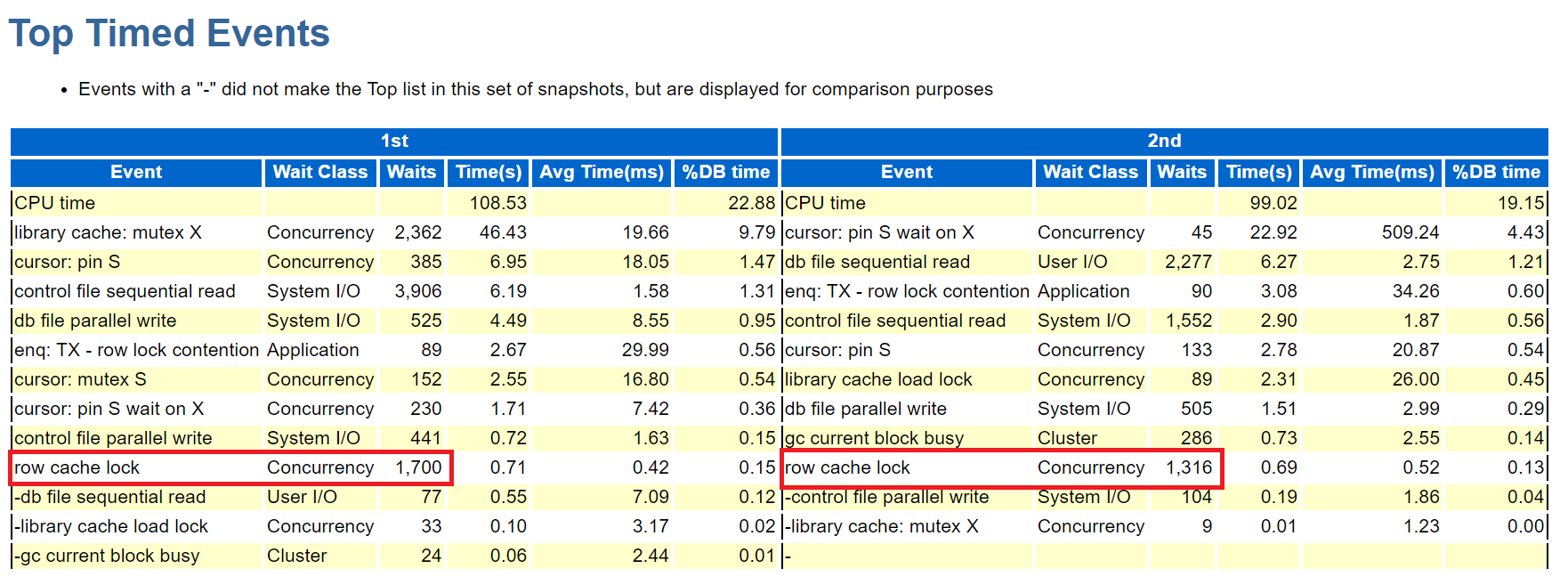
row cache lock 대기 이벤트가 library cache 에 관련된 대기 이벤트이다.
#6. addm report 를 생성합니다.
SQL#1 > @?/rdbms/admin/addmrpt.sql
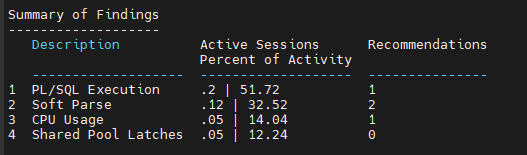
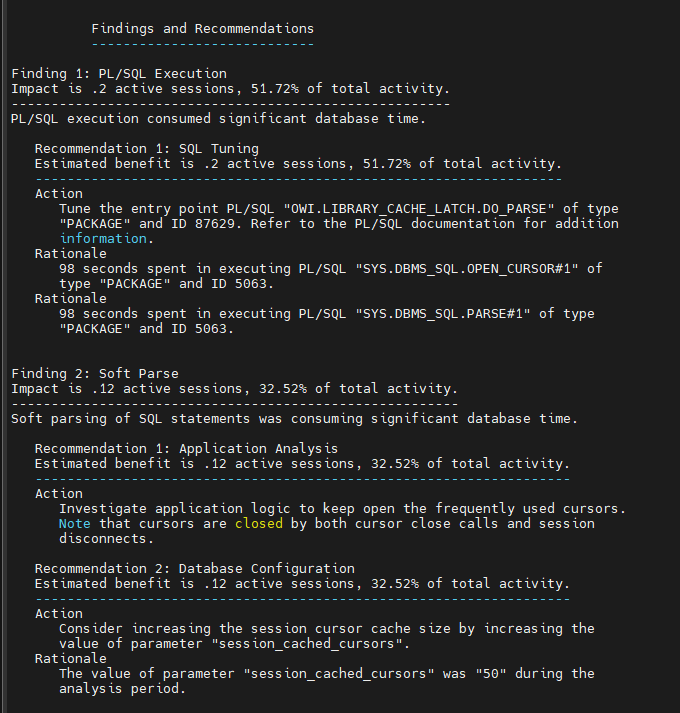
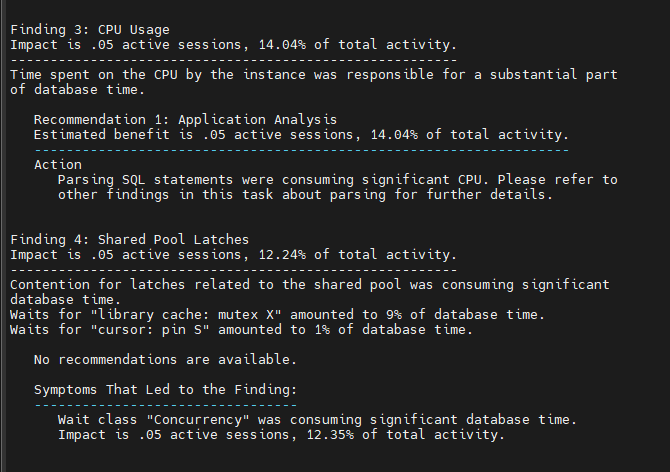
문제2. shared pool size 를 기존의 1.2 배로 늘리시오
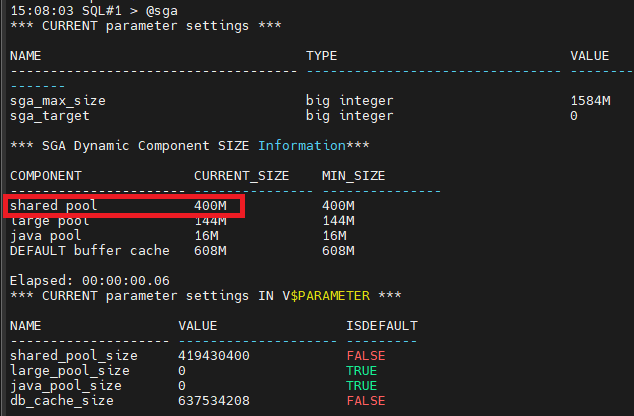
SQL#1 > show parameter shared_pool_size
shared_pool_size 0
0이면 오라클이 알아서 shared pool 사이즈를 조절한다는 뜻
@sga
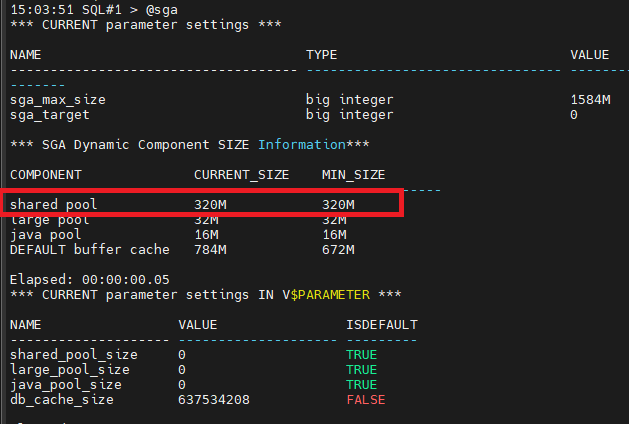
사이즈 키우기
SQL#1 > alter system set shared_pool_size=400m scope=spfile sid='*';
SQL#1> shutdown immediate
SQL#2> shutdown immediate
SQL#1> startup
SQL#2> startup
@sga
@snap 11분
@exec
- 이번엔 핀으로
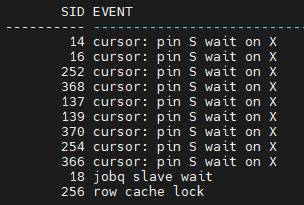
@snap
비교레포트
SQL#1> @?/rdbms/admin/awrddrpt.sql
▣ 예제61. RAC 환경에서 truncate 스크립트 수행할 때 양쪽 노드에서 각각 하지마세요
데이터 이행을 하다보면 여러개의 테이블을 한번에 truncate 를 해야할 일이
있습니다.
SQL#1> connect scott/tiger
SQL#1> select 'truncate table ' || table_name ||';'
from user_tables;

설명: truncate table 스크립트가 300줄 나오면 150개는 1번 노드에서 수행하고
또 나머지 150개는 2번 노드에서 수행하게 되면 둘중 어느 하나의 작업은
lock 에 걸리듯이 멈춰버리게 됩니다.
truncate 할 때 서로 인터커넥트를 통해서 어디까지 메모리에서 데이터
지웠는지 서로 통신을 해야하기 때문입니다.
해결방법: 한쪽 노드에서만 truncate table 전체 스크립트를 수행합니다.
제 7장.

▣ 예제62. RAC 환경에서의 서비스 활용
서비스란
같은 작업을 하는 세션들의 모임
RAC 환경에서 서비스가 필요한 이유 :
RAC 의 단점을 극복하기 위해서 필요
- RAC 의 장점과 단점
- RAC 의 장점 : 1. 고가용성 2. 확장성
- RAC 의 단점 : 인터커넥트 부하로 인해서 성능이 떨어지는 단점
단점을 극복하기 위해 나온 기능이 "서비스" 입니다.
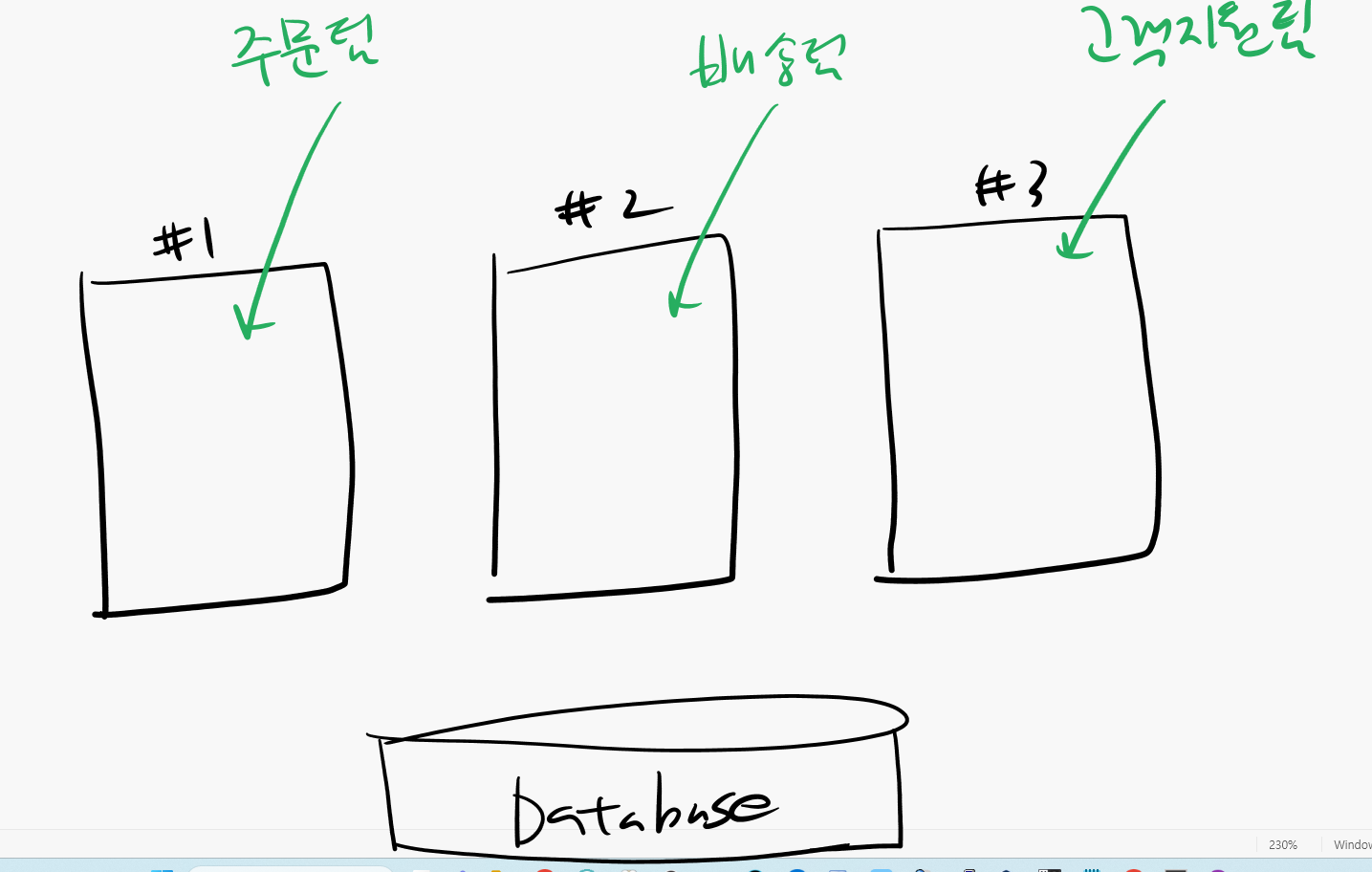
설명: 주문팀은 3개의 노드중에 1번 노드로 접속하게 하고
배송팀은 3개의 노드중에 2번 노드로 접속하게 하고
고객지원팀은 3개의 노드중에 3번 노드로 접속하게 하면
인터커넥트를 통한 데이터 전송을 최소화 할 수 있습니다.
이걸 가능하게 해주는 기술이 바로 "서비스" 입니다.
그런데 우리가 sqldeveloper 로 rac 에 접속을 하게 되면 어느 노드로 접속하지
알 수 없습니다. 랜덤이니까요. 그런데 "서비스" 를 이용하게 되면
어느 노드로 접속하게 될지 결정할 수 있습니다.
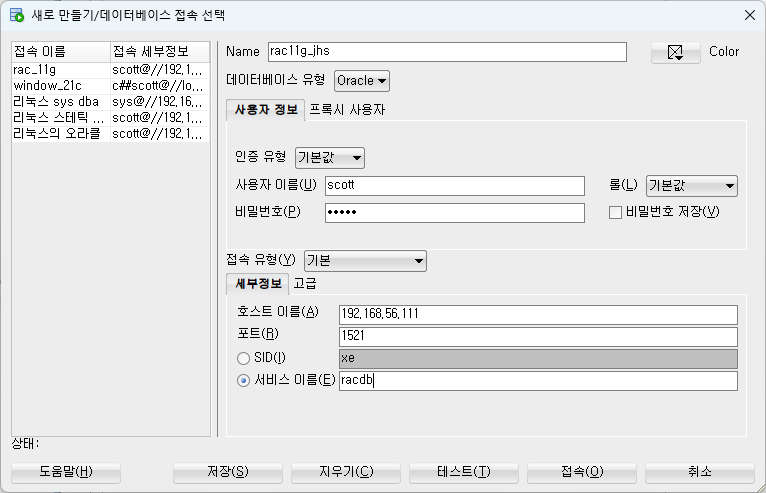
■ 실습1. sqldeveloper 로 rac db 에 접속하기
만들기 누르고 속성 누르기
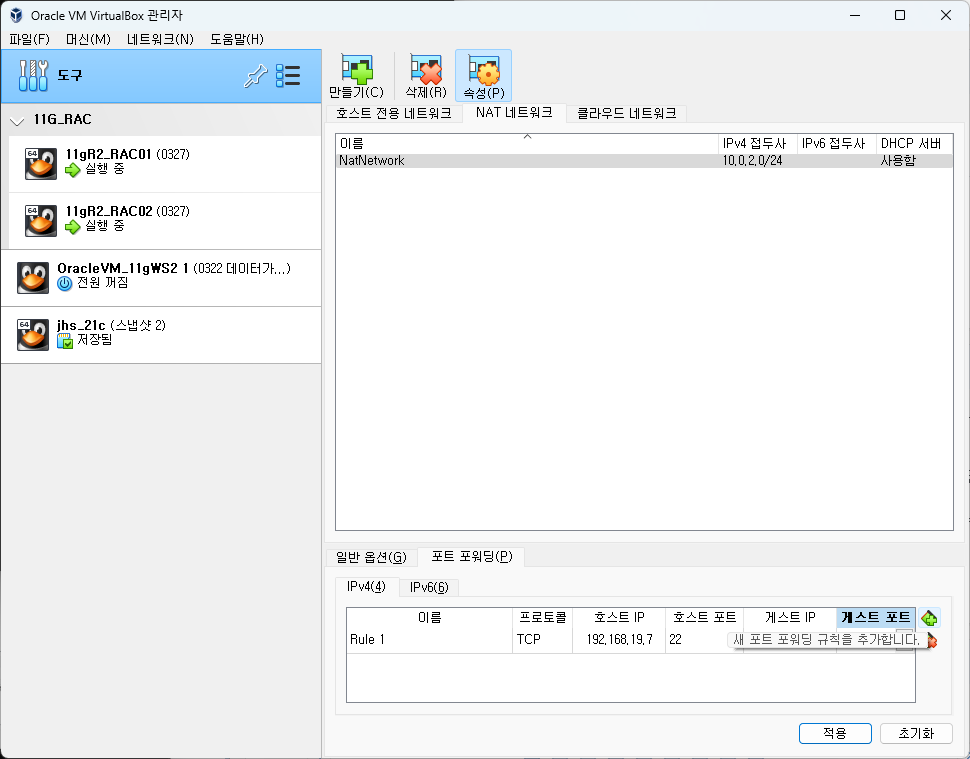
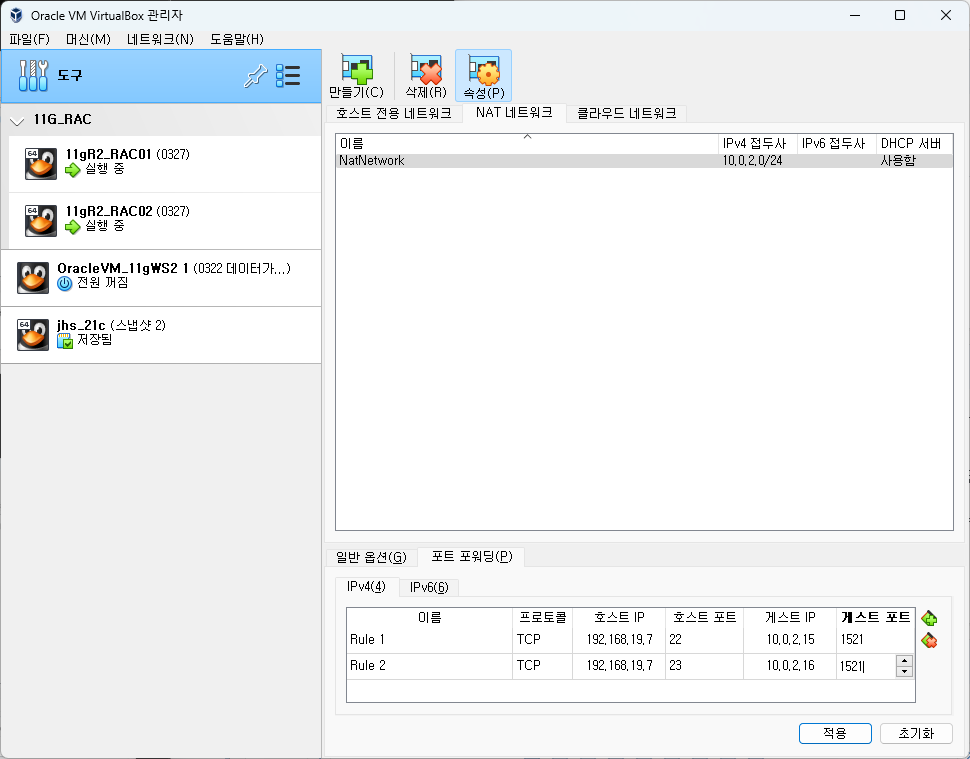
두개를 넣고 적용
D:\oracle2\dbhomeXE\network\admin\sample
안에
tnsname.ora