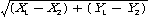
K-NN 알고리즘
지도 학습의 한 종류로 거리 기반 분류 분석 모델
데이터를 가장 가까운 유사 속성에 따라 분류하여 라벨링
K-NN 알고리즘은 '유클리디안 거리' 계산법을 사용한다.
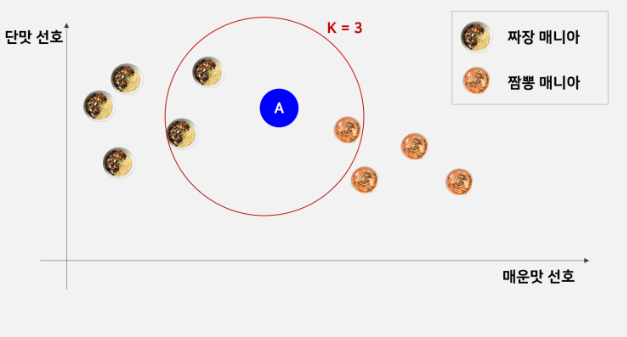
K=3 이라고 가정하면 A와 가장 가까운 거리에 있는 3개의 데이터를 찾는다.
다음과 같이 짜장 2개와 짬뽕 1개가 선택이 되면 짜장을 선호하는 데이터로 분류하게 된다.
- 단 K의 개수는 홀수로 하는 것이 좋다. (동점 상황 예방)
지도 학습의 한 종류로 거리 기반 분류 분석 모델
데이터를 가장 가까운 유사 속성에 따라 분류하여 라벨링
K-NN 알고리즘은 '유클리디안 거리' 계산법을 사용한다.
K=3 이라고 가정하면 A와 가장 가까운 거리에 있는 3개의 데이터를 찾는다.
다음과 같이 짜장 2개와 짬뽕 1개가 선택이 되면 짜장을 선호하는 데이터로 분류하게 된다.
