Flynn's Taxonomy on Parallel Computer
이는 2개의 independent dimension으로 나뉜다.
- Instruction stream
- Data stream
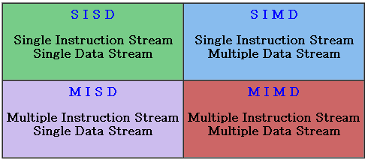
가로축이Data stream, 세로축이Instruction stream
SISD (Single Instruction, Single Data)

- Serial computer (parallel 아님)
- 대부분의 computer가 이런 형태
SIMD (Single Instruction, Multiple Data)
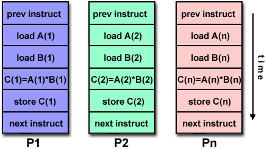
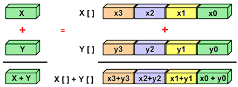
- 모든 processing unit들이 clock cycle마다 같은 instruction을 수행함
- grapthics/image processing 같이 규칙성을 특징으로 하는 문제에 적합함
MISD (Multiple Instruction, Single Data)

- 각 processing unit은 instruction stream을 통해 data에 대해 독립적으로 작동함
- 이런 종류의 parallel computer는 거의 존재 X
MIMD (Multiple Instruction, Multiple Data)
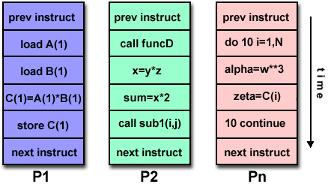
- 모든 processor는 다른 instructruction stream을 실행
- 모든 processor는 다른 data stream에 대해 작업
- 대부분의 Parallel computer
- 대부분 현대의 supercomputer의 종류
Parallel Program을 만드는 방법
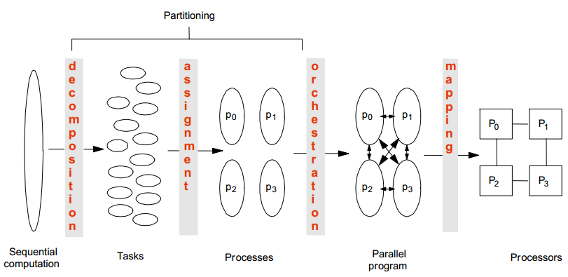
1. Decomposition
2. Assignment
3. Orchestration/Mapping
Decomposition
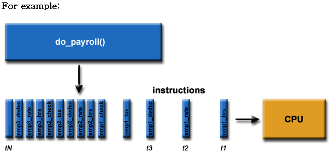
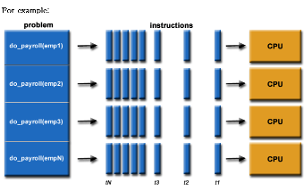
- computation을 task로 분할해 process간 나눔
- concurrency를 식별하고, 이를 활용할 level을 결정
- 위 사진에서 do_payroll()을 4 chunks로 쪼갬
Domain Decomposition

- proplem과 관련된 data가 decompose됨
- 각각 parallel task는 data의 일부에 대해 작업
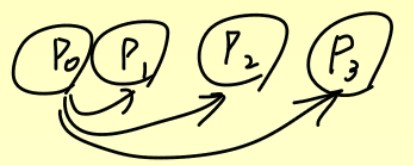
Block Decomposition- 전체 데이터를 연속된 block으로 나누어 각 processor에 할당
- Data가 [0, 1, 2, ..., 15]가 있을 때, 4개의 processor가 있으면
P0: [0, 1, 2, 3] P1: [4, 5, 6, 7] P2: [8, 9, 10, 11] P3: [12, 13, 14, 15] - 장점으로 연속된 data가 한 processor에 몰려있어 캐시 효율이 좋음
- load balance 문제가 생김 (data가 균일하지 않음)
Cyclic Decomposition- Data를 고르게 분산시키기 위해 round-robin 방식으로 할당
P0: [0, 4, 8, 12] P1: [1, 5, 9, 13] P2: [2, 6, 10, 14] P3: [3, 7, 11, 15]- 장점으로 task가 불균형하게 분포되어 있을 때 균등하게 분산 가능
- 서로 다른 processor간 통신량이 많아질 수 있음
Functional Decomposition
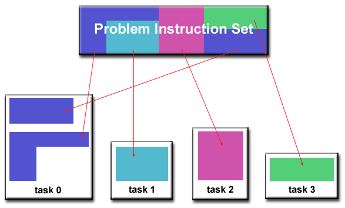
- data보다 수행해야 할 computation에 초점을 맞춤
- 수행해야 하는 작업에 따라 세분화
- 각 작업은 전체 작업의 일부를 수행
Example
1. 이미지 읽기
2. 필터 적용
3. 엣지 검출
4. 결과 저장
위와 같은 단계가 있을 때
P0: 이미지 읽기
P1: 필터 적용
P2: 엣지 검출
P3: 결과 저장
위와 같이 각 processor가 특정 기능만 반복하도록 수행
- 각 기능에 최적화된 리소스나 알고리즘 사용 가능
- 특정 기능에 bottleneck이 생기면 전체 성능이 저하됨 -> load balancing이 어려움
Assignment
- task를 thread에 할당
- Goal
- Balanced workload
- Reduced communication costs
- 할당 기준
- 작업의 크기 (Workload)
- processor의 수
- Communication overhead
Orchestration
- 여러개의 작업, 서비스, 컴포넌트들을 자동으로 관리, 조정, 통제
- memory에서 data structure를 구성하고 작업을 시간별로 예약
- Goal
- Processor가 보는 communication 및 synchronization 비용 절감
- data 참조 위치 예약
- 데이터를 잘 배치해서 Locality를 향상 (memory에서 연속적으로 접근할 수 있도록!)
Mapping
- thread들을 execution unit (CPU cores)에게 mapping
- Mapping 결정 과정
- 관련된 thread들을 같은 processor에 위치
- locality, data sharing ⬆️
- communication/synchronization 비용 ⬇️
Parallel Program의 성능
성능에 미치는 요소는 뭐가 있을까?
- Decomposition
- algorithm의 병렬의 처리 범위 (Coverage)
- Assignment
- processor간의 partitioning의 세분성(Granularity)
- Orchestration/Mapping
- computation과 communication의 위치(Locality)
Coverage (AmdahI's Law)
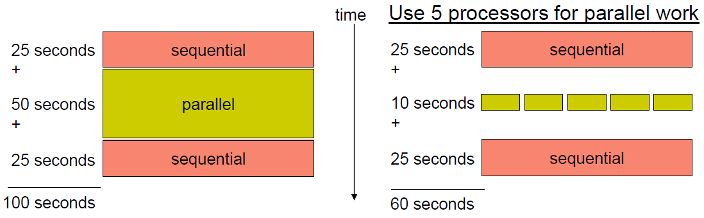
- potential program 속도 향상은 병렬화 할 수 있는 code의 비율로 정의됨
- code에서 병렬처리 할 수 있는 부분이 많으면, 속도 향상 가능성도 높아짐
- 위 그림을 보면 parallel 가능한 부분이 5배가 됐는데 성능은 5배가 안됨 -> 과연 이게 좋은것인가?
- processor를 사용 중인데 왜 speedup은 5배가 아닌가 -> 좋은건 아님
p = 병렬처리 할 수 있는 작업의 분수
n = processor의 개수
가 되고, 는 sequential 작업을 완료하는데 걸리는 시간, 는 parallel 작업을 완료하는데 걸리는 시간이다.
즉, speedup은 processor가 무한대로 갈 때 가 되는 경향이 있다.
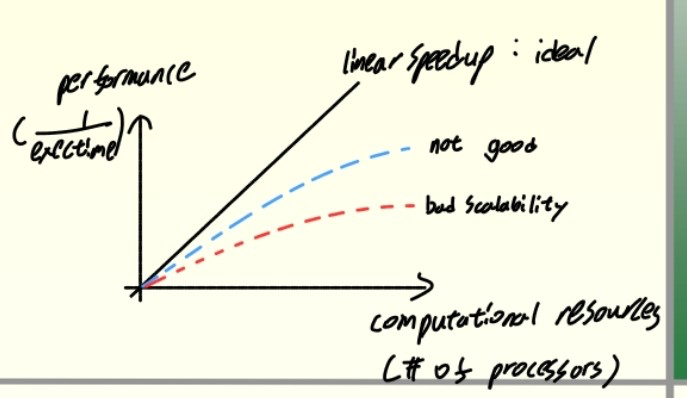
Performance Scalability
- Scalability
- resource가 추가될 때 load가 증가할 때 총 throughput을 증가시키는 system 기능
Granularity
Granularity는 computation과 communication의 비율을 나타내는 척도
- 병렬 프로그램에서 하나의 작업 단위가 얼마나 작거나 큰지 나타내는 정도
Grain = unit of work (the size of work unit) - Coarse
- communication event간에 많은 계산 작업이 수행된다.
- 큰 단위 작업으로 나눔
- Fine
- communication event간에 상대적으로 적은 양의 계산 작업이 수행된다.
- 작고 짧은 작업들을 많이 나눔
Computation 단계는 동기화로 인해 communication과 분리됨
- Granularity
- system이 작은 부분으로 세분화되는 정도
- Coarse-grained system
- fine-grained system보다 더 적은 수의 더 큰 component로 구성
- 큰 subcomponents
- Coarse-grain Parallelism
- computation/communication 이 높음
- communication event들 사이에 많은 computational 작업이 있음
- load balancing 감소
- 낮은 communication overhead
- Fine-grained systems
- 더 큰 component를 구성하는 작은 component와 관련
- Fine-grain Parallelism
- computation/communication 이 낮음
- communication event들 사이에 적은 computational 작업이 있음
- load balancing 증가
- 높은 communication overhead
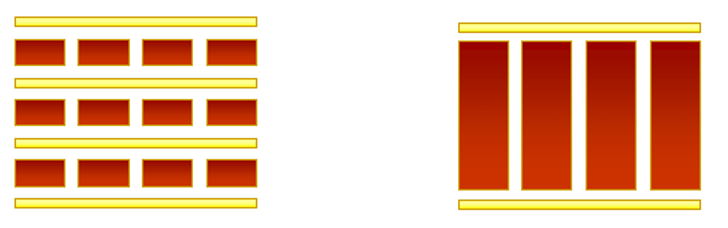
왼쪽이 Fine-grain Parallelism, 오른쪽이 Coarse-grain Parallelism
- 가장 효율적인 granularity는 algorithm과 hardware에 따라 달라짐
- 대부분 communication과 synchronization과 관련된 overhead는 실행속도에 비해 높기 때문에 coarse granularity를 가지는게 유리함
- Fine-grain parallelism은 load imbalance로 인해 overhead를 줄이는데 도움이 될 수 있음
Load Balancing

- 작업 간 거의 동일한 양의 작업을 분배해 모든 작업이 busy 상태가 되도록 유지
- task idle time을 최소화 하는 것이 목표
- 문제점
- 전체 작업은 가능한 빨리 완료해야 함
- worker가 비싸기 때문에 바쁘게 유지해야 함
- work가 공정하게 분배되어야 함. (모든 worker가 거의 동일한 양의 작업이 할당 되어야 함)
- 서로 다른 작업 사이에는 우선순위 제약이 있음. (ex. 벽 -> 지붕)
Static load balancing

- 프로그래머가 priori하게 결정을 내리고 각 processing core에 고정된 양의 작업을 할당
- 낮은 runtime overhead
- homogeneous multicore에 적합
- 모든 core가 동일
- 각 core는 동일한 양의 작업을 수행
- heterogeneous multicoere에는 적합하지 않음
- 일부 core가 다른 core보다 빠를 수 있음
- 작업 분배가 고르지 않음
Dynamic Load Balancing
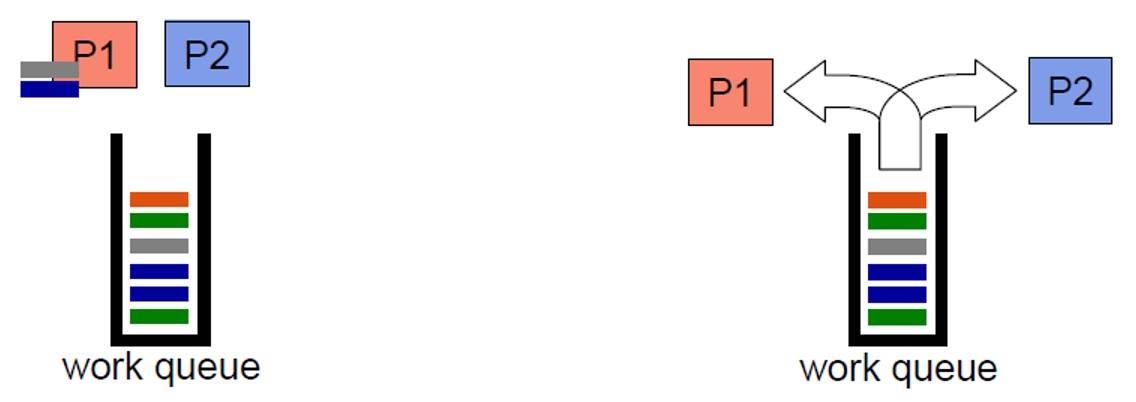
- 한 core가 할당된 작업을 완료하면 work queue 또는 작업량이 가장 많은 core에서 작업을 수행
- runtime에 partitioning을 조정해 load balance 조정
- 높은 runtime overhead
- heterogeneous multicore에 이상적
- 작업이 고르지 않고 예측할 수 없음
Communication
- message passing을 통해 프로그래머는 computation을 이해하고, 그에 따라 communication을 조정해야 함
- Point to Point
- Broadcast (one-to-all) and Reduce (all-to-one)
- All to All (각각의 processor가 다른 processor에게 data를 보냄)
- Scatter (one-to-several) and Gather (several-to-one)
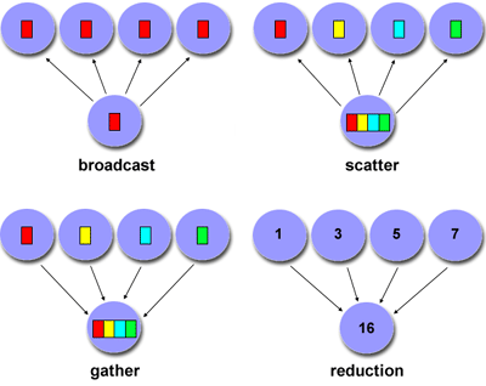
Communication의 고려 요소
- communication 비용
- task간 communication은 overhead를 수반
- task간 synchronization이 필요한 경우가 많기 때문에 작업을 수행하는 대신 'waiting'에 시간을 소비
LatencyvsBandwidth- Latency
- A에서 B로 minimal (0 byte) message를 보내는데 걸리는 시간
- Bandwidth
- 단위시간당 communication 할 수 있는 data의 양
- 작은 message를 계속 보내면 (latency > communication overhead)
- 작은 message를 큰 message로 package하는 것이 더 효율적인 경우가 많음
- Latency
synchronousvsasynchronous- synchronous : data를 공유하는 작업 간에 "handshaking"이 필요
- Asynchronous : 서로 독립적으로 data를 전송
- Scope of communication
- Point-to-Point
- collective
MPI (Message Passing Library)
- MPI
- parallel computers, clusters, heterogeneous networks, multicore에 필요
- 다양한 communication mode를 통해 정밀한 buffer 관리 가능
- 확장 가능한 global communication을 위한 확장된 작업
Point-to-Point
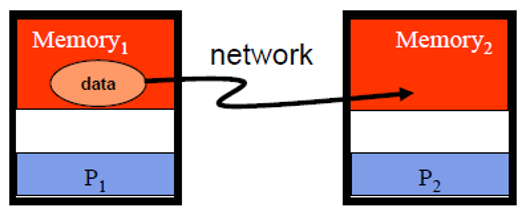
- 2개의 processor 사이에 기본적인 communication 방식
Originating processor가destination processor로 "sends"Destination processor가 message를 "receives"
- message에 포함되어 있는 것
- data, ...
- message 길이
- destination address
- Synchronous vs Asynchronous Message
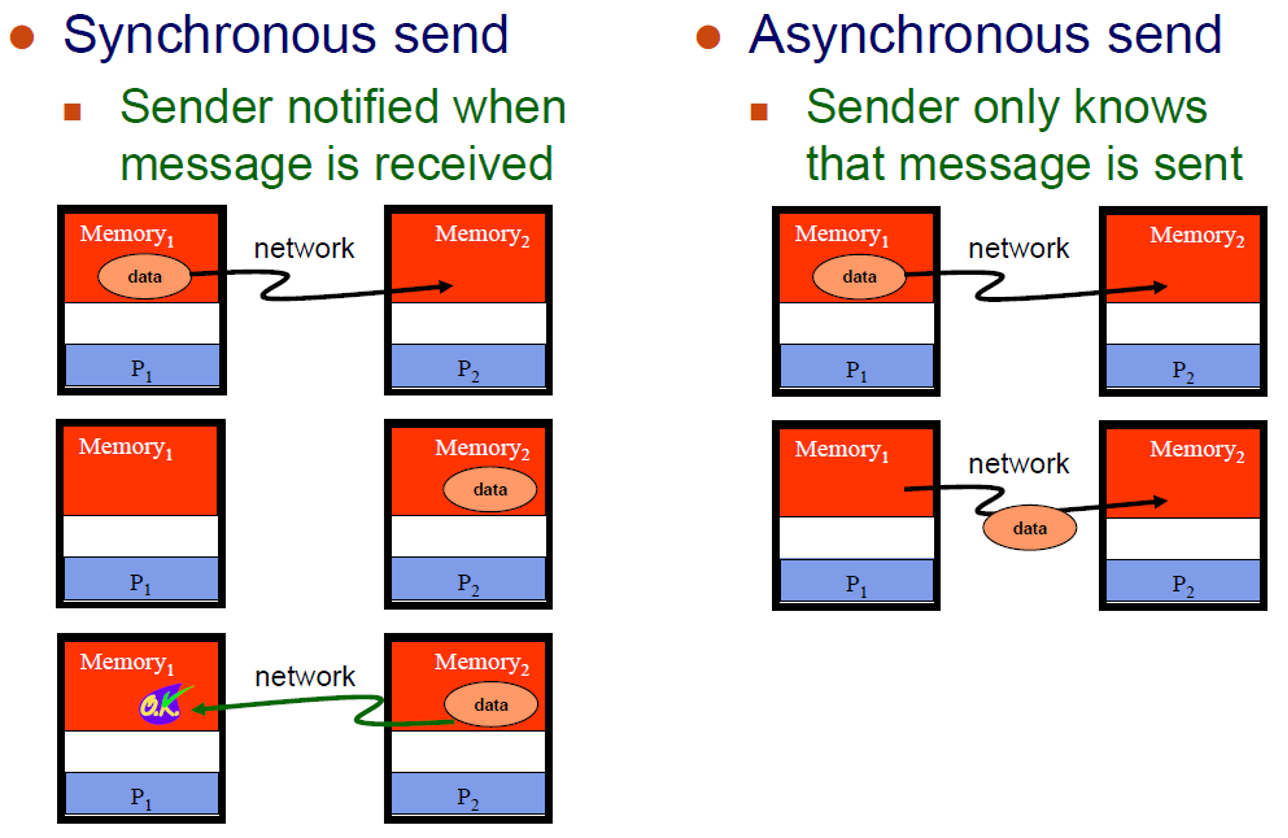
- Blocking vs. Non-Blocking Message
- Blocking message
- Sender는 message가 전송될 때까지 기다림 : buffer가 비어있음
- receiver는 message를 받을 때까지 기다림 : buffer가 차있음
- deaklock의 가능성 존재
- Non-blocking
- message가 전송되지 않아도 processing은 계속됨
- idle time과 deadlock을 피할 수 있음
- message가 전송되지 않아도 processing은 계속됨
- Blocking message
Broadcast
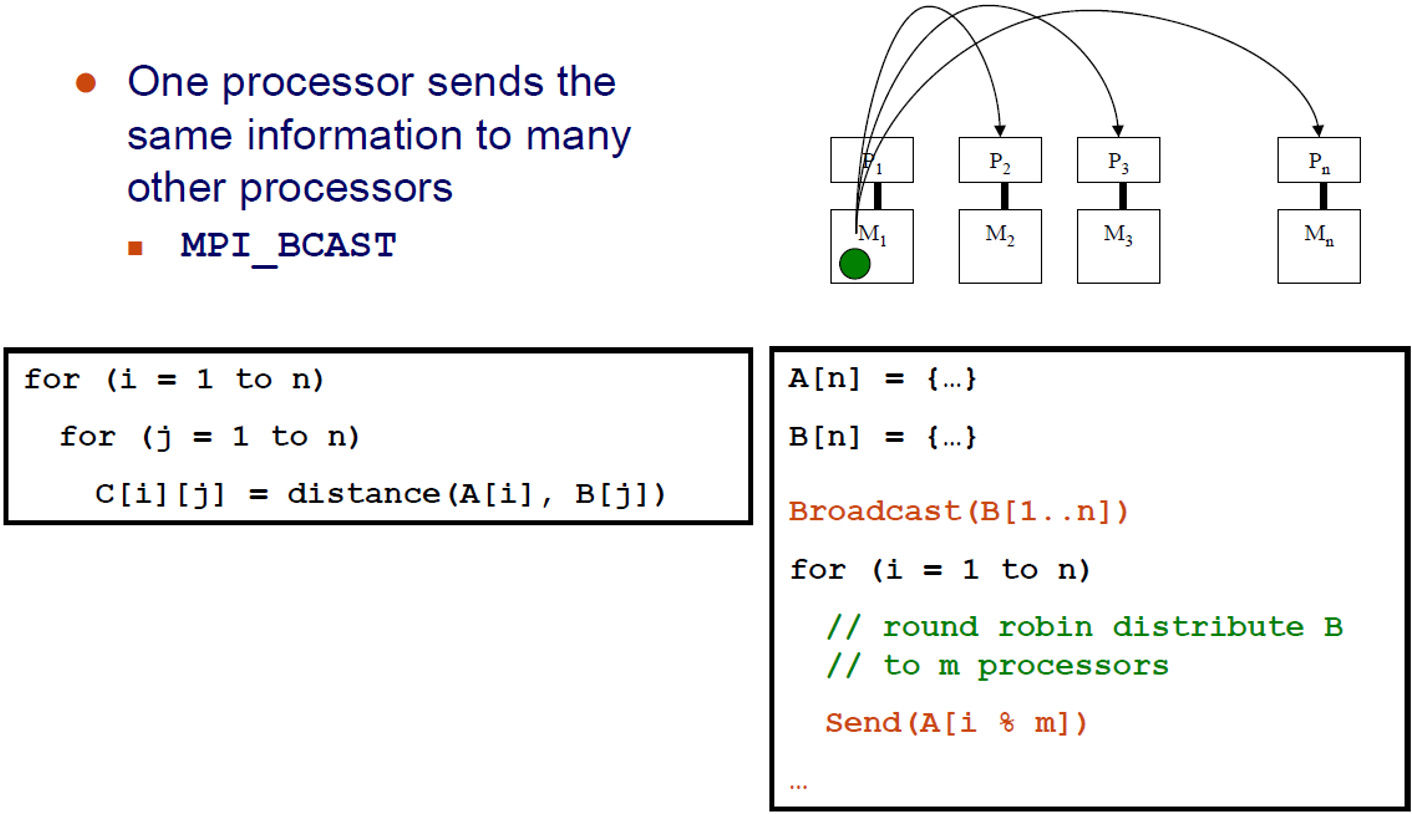
하나의 processor는 같은 정보를 많은 다른 processor로 보냄
MPI_BCAST
Reduction
- 모든 processor는 value로 시작하며, 모든 processor에 저장된 value의 합계를 알아야 함.
- reduction은 모든 processor의 data를 결합해 단일 process로 반환해야 함
MPI_REDUCE- 수집된 data에 모든 관련된 연산을 적용 가능
- ADD, OR, AND, MAX, MIN, etc.
- 각 processor가 값을 제공하기 전에는 어떤 processor도 reduction을 완료할 수 없음
- Broadcast, Reduction은 프로그래밍의 복잡성을 줄일 수 있다.
(MPI) Integration를 계산 방법
static long num_steps = 100000;
void main(int argc, char* argv[]) {
int i_start, i_end, i, myid, numprocs;
double pi, mypi, x, step, sum = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_BCAST(&num_steps, 1, MPI_INT, 0, MPI_COMM_WORLD);
i_start = my_id * (num_steps/numprocs)
i_end = i_start + (num_steps/numprocs)
step = 1.0 / (double) num_steps;
for (i = i_start; i < i_end; i++) {
x = (i + 0.5) * step
sum = sum + 4.0 / (1.0 + x*x);
}
mypi = step * sum;
MPI_REDUCE(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
printf("Pi = %f\n", pi);
MPI_Finalize();
}를 계산하는데 사용
- 정적분을 직사각형 방식으로 근사
- 작업을 여러 process가 나누어 병렬로 계산
- MPI를 통해 결과를 나중에 모아 최종 값 출력
myid: 현재 process ID
numprocs: 전체 process 수
sum, mypi: 각 process의 부분합
num_step의 값을 모든 process에 broadcast
Synchronization
올바른 runtime 순서를 얻고 예기치 않은 상태를 피하기 위해 simultaneous event를 조정해야 함
- Barrier
- 모든 thread/process는 barrier에서 멈춰야 하고, 다른 모든 thread/process가 이 barrier에 도달할 때까지 진행할 수 없음
- Lock/semaphore
- first task가 lock을 획득.
- 다른 task는 lock를 소유한 task가 lock을 해제할 때까지 기다려야 함.
Locality
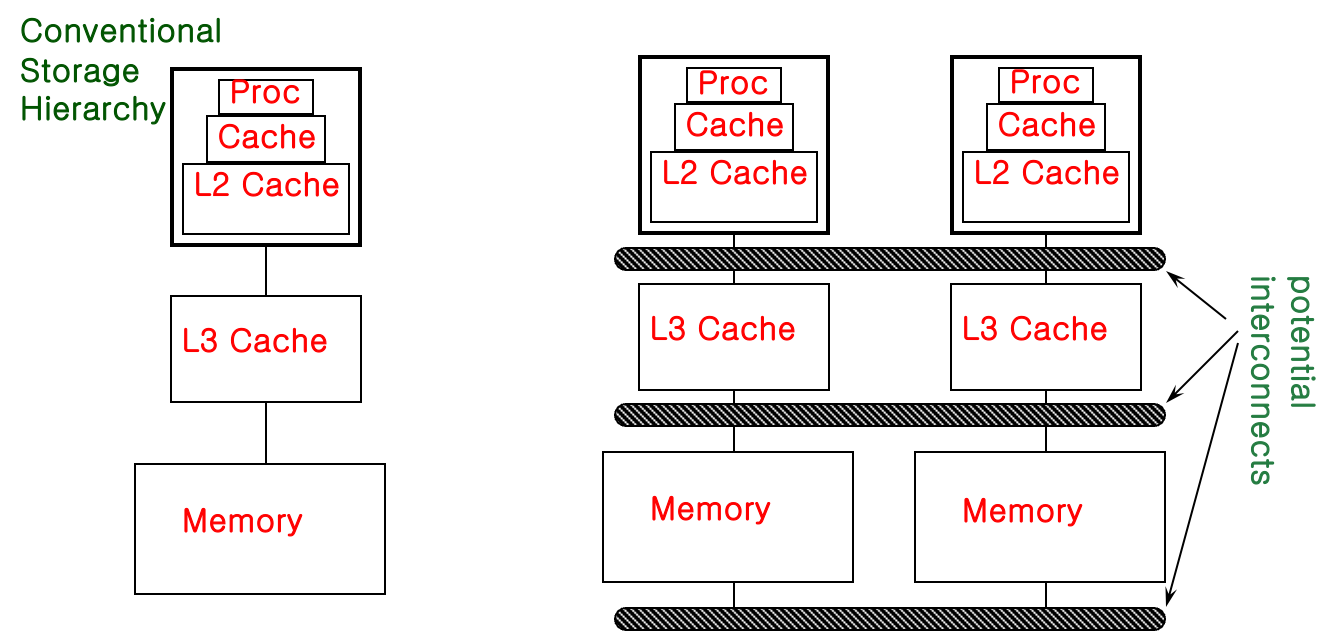
- 큰 memory는 느리고 작은 memory는 빠름
- communication이라고 부르는 remote data에 대한 접근이 느림
- spatial, temporal locality를 활용
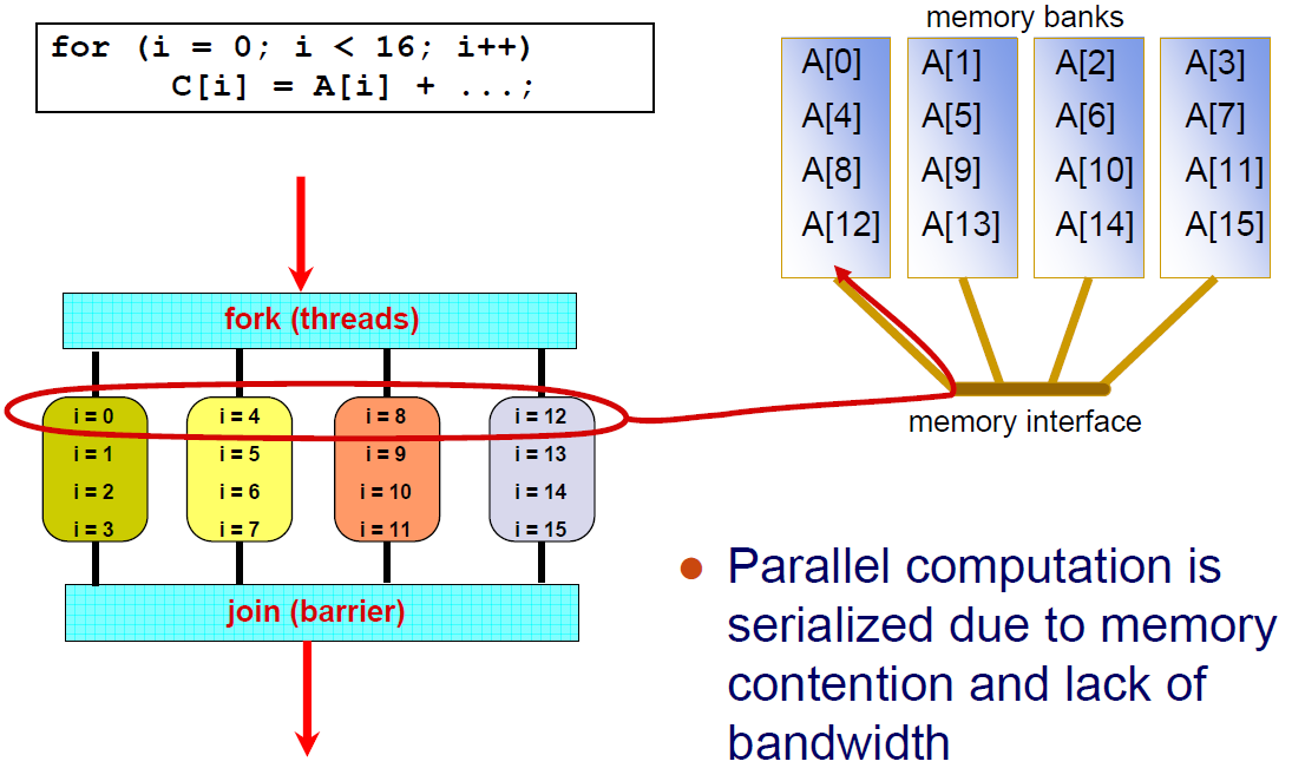
위와 같은 상황은 memory 경합 및 bandwidth 부족으로 parallel computation이 serialized 됨.
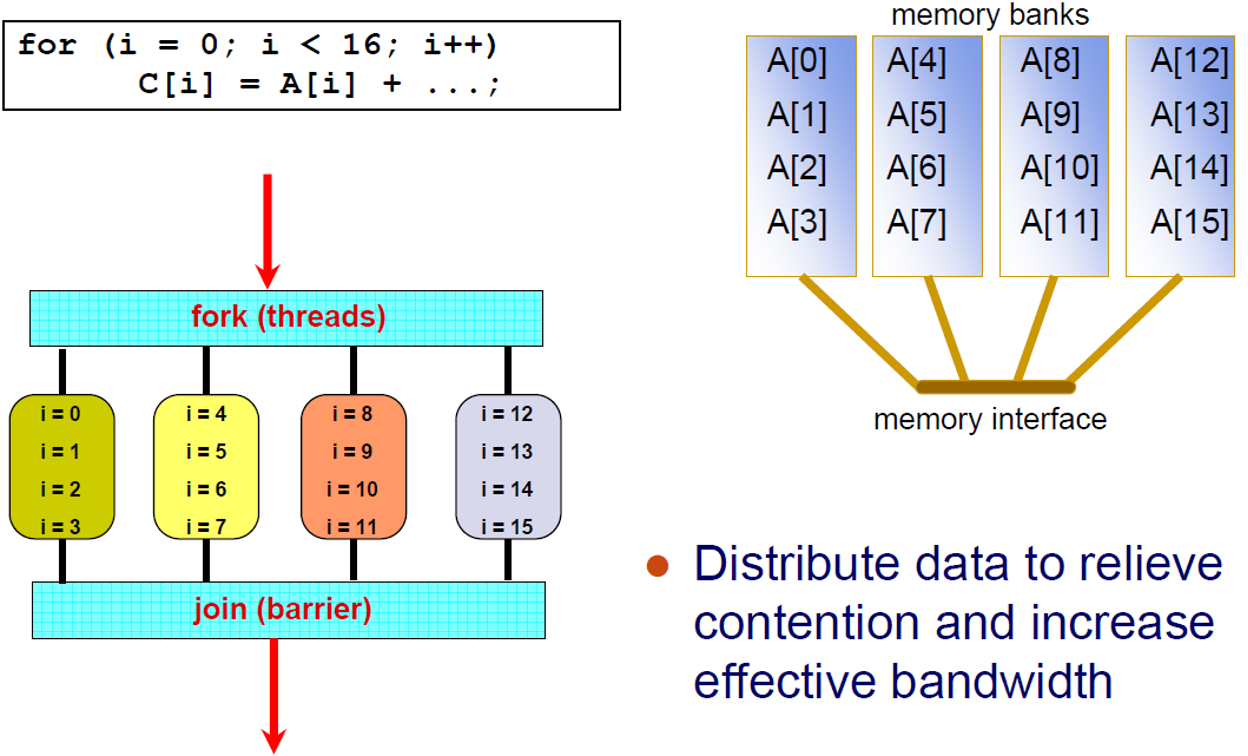
위 그림은 data를 분산하여 contention을 완화하고 effective bandwidth를 늘림
Shared Memory Architecture에서의 Memory Access Latency
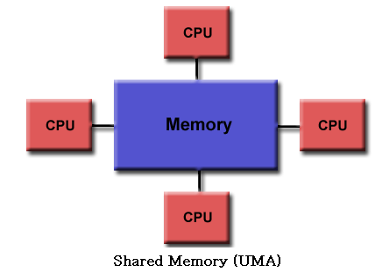
- Uniform Memory Access (UMA)
- 중앙에 위치한 memory
- 모든 processor가 동일한 거리에 있음 (Access 시간이 비슷)
- 주로 small scale system에 쓰임

- Non-Uniform Access (NUMA)
- 물리적으로 분할되어 있지만 모두가 access 가능함
- processor는 동일한 address space를 가짐
- data의 배치가 performance에 영향을 미침
- CC-NUMA (Cache-Coherent NUMA) : 일관성
- 주로 large scale system에 쓰임
Cache Coherence
- 여러 local cache에 저장되는 공유 리소스 data의 균일성 유지
- 문제점
- processor가 local cache에서 공유 변수를 수정하면 processor마다 변수의 값이 달라질 수 있음
- 변수의 복사본이 여러 cache에 존재할 수 있음
- 한 processor의 write가 다른 processor에서는 표시되지 않을 수 있음
- cache에서 오래된 값에 계속 access할 수 있음
- visibility나 cache coherence을 보장하기 위한 조치를 취해야 함
- processor가 local cache에서 공유 변수를 수정하면 processor마다 변수의 값이 달라질 수 있음
- Snooping cache coherence
- 모든 data 요청을 모든 processor로 전송
- small system에 적합
- Directory-based cache coherence
- directory에서 공유되는 내용을 추적함
- point-to-point 요청을 processor로 전송
Shared Memory Architecture
- 모든 processor가 모든 memory를 global address space로 access 할 수 있도록 함 (UMA, NUMA)
- 장점
- global address는 memory에 대한 사용자 친화적인 programming 관점을 제공함
- memory가 CPU에 근접해 있기 때문에 작업 간 data 공유가 빠르고 균일함
- 단점
- memory와 CPU간의 확장성이 부족함
- 비쌈: processor 수가 계속 증가함에 따라 shard memory machine을 설계하고 제작하는 것이 점점 더 어려워지고 비용이 많이 듦
Distributed Memory Architecture
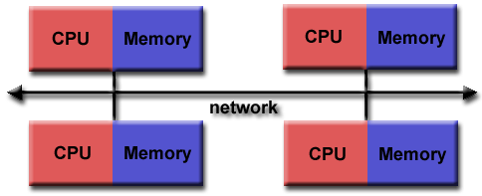
- 특징
- private(local) memory를 가지고 있음
- 독립적임
- processor간 memory 연결을 하려면 communication network가 필요함
- 장점
- scalable (processors, memory)
- Cost effective
- 단점
- data communication에 대한 programmer의 책임
- global memroy에 대한 access가 없음
- memory access 시간이 균일하지 않음
Hybrid Architecture
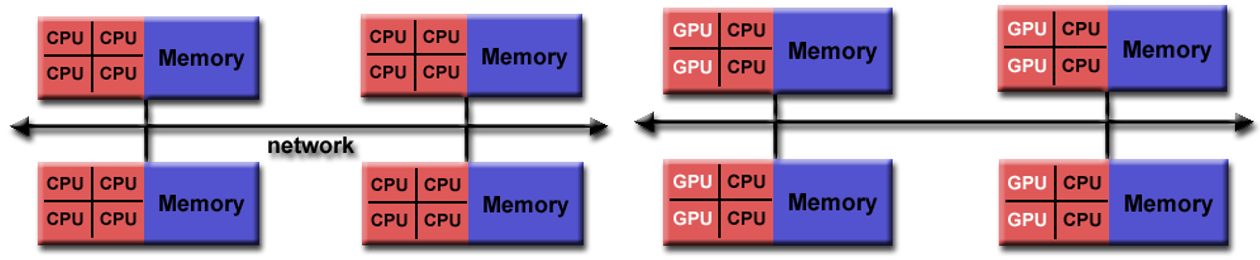
- 장점 / 단점
- Shared/Distributed architecture의 조합
- Scalable
- programmer의 복잡성 증가
Parallel Program의 예시
Ray Tracing
- 이미지 평면의 모든 pixel을 통해 ray을 쏨
- ray의 경로에 따라 물체에 부딪히면서 튕겨나가고 새로운 ray를 생성
- 결과는 해당 Pixel의 color와 opacity(투명도)
- ray 간의 parallelism
