2021
Abstract
이 논문은 self-supervised learning 기법이 ViT에 효과적으로 적용되고 다음과 같은 결과를 제시했다.
- self-supervised learning된 ViT는 image의 semantic segmentation에 대한 명확한 정보를 포함한다.
- 이러한 특징은 k-NN classifier에서도 우수한 성능을 보이고, 작은 ViT 모델로 ImageNet에서 78.3% top-1 accuracy를 달성했다.
또한 DINO와 ViT의 시너지를 실험을 통해 ViT-Base 모델로 ImageNet에서 80.1% accuracy를 달성했다.
Introduction
ViT는 convnets와 유사한 성능을 보이지만 계산 비용이 크고, 많은 학습 data가 필요하고, 독특한 특징을 갖지 못한다는 한계가 있다.
여기서 Transformer가 vision 분야에서 제한된 성과를 보이는게 supervision 기반 pretraining 때문인지 탐구
➡️ 이후 작성
이미지에서 supervision 방식은 이미지의 풍부한 정보를 사전에 정의된 몇 천개의 category 중 하나로 단순화한다는 한계가 있음.
연구의 주요 특징은 다음과 같다.
- self-supervised learning된 ViT는 장면의 layout과 object의 경계를 명확하게 나타내며 마지막 블록의 self-attention 모듈에서 확인이 가능하다.
- k-NN classifier에서도 우수한 성능을 보이고 finetuning이나 data augmentation 없이 ImageNet에서 78.3% top-1 accuracy를 달성했다.
DINO는 label 없이 수행되는 knowledge distillation 방식으로 momentum encoder로 구축된 teacher network의 출력을 직접 예측하는 방식으로 동작한다. 이는 centering과 sharpening 만으로도 학습 collapse를 방지할 수 있다.
centering
DINO에서 teacher network는 student network에서 나온 feature를 받아 target을 생성한다. 이때 teacher의 출력이 특정 값으로 수렴하는 학습 collapse가 발생할 수 있다. 이를 방지하기 위해 centering을 적용한다.
구현은 Teacher의 softmax 출력을 평균으로 조정하는 방식을 사용한다.
- : teacher network의 output
- : centering parameter
- : temperature scaling factor
이때 는 moving average로 업데이트를 한다.
moving average는 다음과 같다.
- : decay factor
- : mini-batch에 대한 평균
sharpening
DINO에서는 Teacher와 Student network의 출력을 맞추는 방식으로 학습이 이루어 지지만 teacher의 출력이 지나치게 분산되어 있으면 학습이 제대로 이루어 지지 않아 teacher의 확률 분포를 더욱 확실하게 강조한다.
이는 Teacher의 출력에 낮은 temperature 값을 사용해 softmax 확률을 더욱 뾰족하게 만든다.
학습 collapse
network가 모든 input에 대해 동일한 output을 내는 상태로 수렴하는 현상
또한 DINO는 convnets와 ViT 모두에서 적용이 가능하다.
DINO와 ViT의 시너지를 검증한 결과 ImageNet Linear Evaluation benchmark에서 80.1% top-1 accuracy를 달성해 기존 self-supervised learning 성능을 뛰어넘었다.
Related work
Self-Supervised Learning
self-supervised learning은 별도의 label 없이 data 자체를 활용해 학습하는 방식
discriminative approach- Instance Classification
- 각 이미지를 서로 다른 class로 간주하고 data augmentation을 적용해 model이 이를 구별하도록 학습하지만, data가 많아질수록 모든 이미지를 분류하는 것이 비효율적이다.
- Noise Contrastive Estimator (NCE)
- instance를 직접 분류하는 대신, 서로 다른 instance를 비교하는 방식. 하지만 동시에 많은 이미지의 특징을 비교해야 하므로 큰 batch size나 memory bank가 필요함
- Clustering
- 자동으로 instance를 그룹화해 scale 문제를 해결
- Instance Classification
Non-Discriminative approach- 최근 연구에서는 개별 이미지를 구별하는 방식이 아닌 유사한 embedding을 학습하는 방식이 등장
- BYOL
- Momentum Encoder를 사용해 특징을 매칭하는 metric learning 기반 접근법
- Momentum Encoder 없이도 동작하지만 성능의 저하가 발생한다.
이 논문에서는 BYOL에서 영감을 받아 similarity matching loss를 활용해 student과 teacher network의 아키텍처를 동일하게 유지한다.
Self-Training and Knowledge Distillation
Self-Training은 소량의 초기 label을 활용해 더 큰 규모의 unlabelled data에 대해 예측을 확장하는 방식
Hard Label Assignment- 모델이 예측한 값을 고정된 label로 간주해 훈련
Soft Label Assignment- 모델이 예측한 확률 값을 활용해 훈련
Knowledge Distillation
- 일반적으로 student model이 teacher의 output을 모방하도록 학습하는 방식
- knowledge distillation이 self-training pipeline에서 soft label을 unlabelled data에 확장하는데 사용할 수 있음을 보여준다.
- 기존 연구는 고정된 teacher network를 활용했지만 DINO는 학습과정에서 동적으로 teacher를 업데이트 하는 방식을 채택했다.
teacher를 student의 평균을 이용해 업데이트 한다.
Approach
SSL with Knowledge Distillation
DINO의 구조는 다음과 같다.
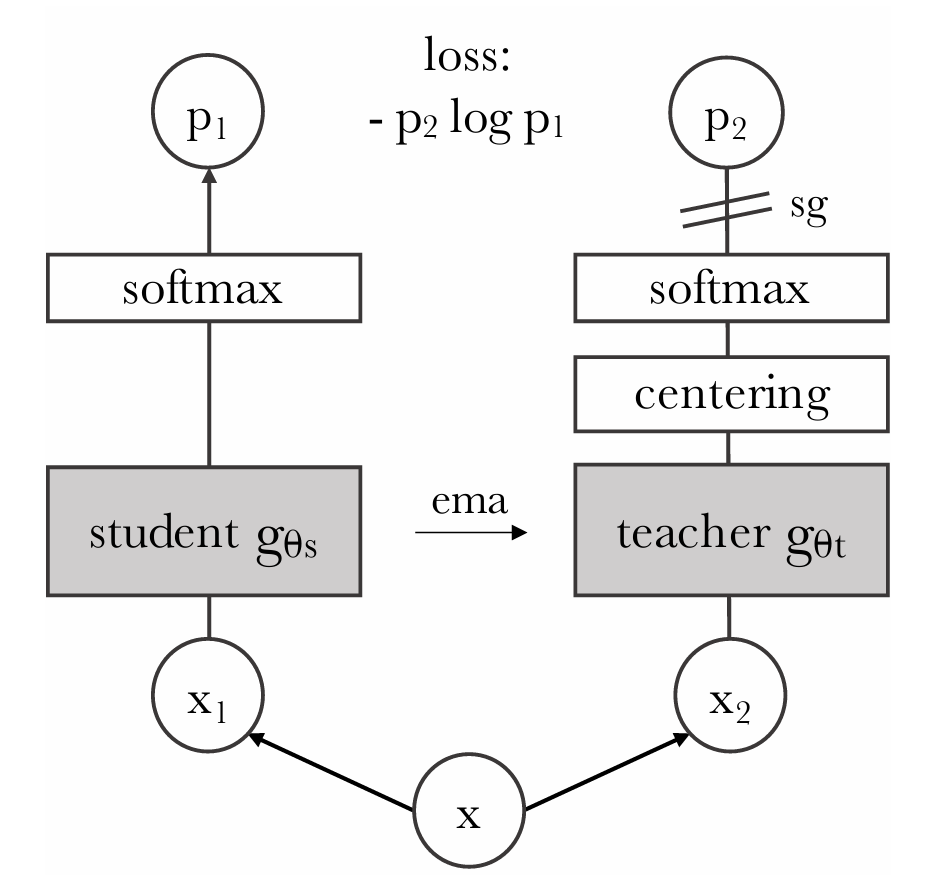
주어진 이미지 에 대해 teacher network와 student network는 각각 K차원의 확률 분포 를 출력하고, softmax 함수에 의해 정규화 된다.
이때 주어진 teacher network를 기준으로 student network가 학습하도록 하기 위해 다음과 같은 cross-entrophy loss를 최소화한다.
이때 는 이다.
입력 이미지는 다양한 방식으로 crop하여 여러개의 view를 생성한다. 이때 2 개의 global view와 여러 개의 local view를 포함하는데, global view만 teacher network를 통과하도록 한다. 이를 통해 local-to-global 관계를 학습한다.
teacher network에 global view를 넣어 나온 embedding과 student network에 local view를 넣어 나온 embedding을 비교해 학습
이때 최종적으로 최소화해야 하는 loss function은 다음과 같다.
이때 일반적으로 의 global view 2개와 의 여러 local view를 사용한다.
Teacher Network
기존 knowledge distillation과 다르게 사전에 정의된 teacher network 없이 student network의 과거 상태를 기반으로 teacher network를 생성한다.
teacher netowrk의 가중치는 EMA를 사용한 momentum encoder 방식이 효과적이었다. 이는 다음과 같이 정의된다.
이때 훈련 중 는 0.996~1로 변화하는 cosine schedule를 따른다고 한다.
Network architecture
network 는 backbone 와 projection head 로 구성된다.
- backbone
- ViT
- ResNet
- Projection head
- 3개의 층으로 이루어진 MLP
- hidden dimension : 2048
이때 DINO는 CNN과 달리 Batch Normalization을 사용하지 않는다.
Avoiding collapse
self-supervised learning에서는 상수 출력을 내놓는 collapse 현상을 방지해야 한다.
DINO는 momentum teacher network의 output를 centering하고 sharpening 하는 방식으로 collapse를 방지한다.
- : 갱신율
- : batch size
