2021 CVPR
Abstract
이미지 수준의 contrastive representation learning은 transfer learning으로서 매우 효과적이다. 하지만 특정한 downstream task에 초점을 맞출 때 부족할 수 있다. 이 논문에서는 다음과 같은 목표를 가진다.
- object-level representation
selective search bounding box를 object proposal로 사용한다. - pretraining network architecture
FPN과 같은 detection pipeline에서 사용하는 모듈을 포함 - object detection properties
object 수준의 translation invariance와 scale invariance를 반영한다.
Introduction
기존 downstream task는 대규모로 라벨링된 dataset에서 학습된 사전 학습 가중치를 초기화에 사용함. 즉, supervised ImageNet pretraining이 널리 사용되어 왔다.
최근에 self-supervised pretraining으로 label data에 대한 의존도를 줄인다. 하지만 이는 전체적인 representation에 overfitting이 되어 object detection이나 semantic segmentation과 같은 dense prediction에 최적화 되어 있지 않다고 한다.
이를 해결하기 위해 object level self-supervised pretraining 프레임 워크인 Selective Object Contrastive learning (SoCo)를 제안했다. 이는 selective search를 통해 object proposal를 제안한다. 이를 통해 기존에 전체 이미지를 하나의 instance로 취급한 것과 달리 각 object proposal를 개별적인 instance로 간주한다.
즉, object instance의 scale과 location을 변화시킨 object 수준의 view를 구성하고 contrastive learning을 통해 augmented views 간의 유사성을 maximize한다.
Related Work
unsupervised-learning에서 auto-encoder와 Deep Boltzmann Manchine
➡️이미지의 pixel를 복원하면서 representation계층을 학습
unsupervised learning은 종종 초기화 하는 방법으로 사용한다.
최근에 self-supervised learning이 발전하면서 pretraining과 finetuning을 서로 다른 데이터셋에서 수행하는 transfer learning으로 문제를 정의
ImageNet classifier에서 선형 평가의 결과는 크게 향상되었지만, dense prediction task의 transfer는 제한이 있다. 이를 image-level representation을 pixel-level, region-level representation으로 전환한다.
- VADer, PixPro, DenseCL
- 서로 다른 view에서 동일한 물리적 위치의 point를 매칭
- InsLoc
- 합성된 image에서 region-level 특징을 매칭하는 방식
- DetCon
- MCG기반 하향식 분할 정보를 활용해 segment 내부의 픽셀 transfer 학습
- UP-DETR
- pre-task로 random query patch detection을 제안해 DETR의 pre-training을 수행
- Self-EMD
- ImageNet 이미지 없이 object detection을 위한 표현 학습
Method
이 논문은 동일한 object에 대해 다양한 augmentation에 대해 object-level feature의 유사성을 maximize하는 새로운 contrastive learning을 제안했다.
이 논문은 Mask R-CNN을 활용한 transfer learning을 사용한다고 한다. 또 확장성을 확인하기 위해 R50-C4 구조에도 적용해본다.
Overview
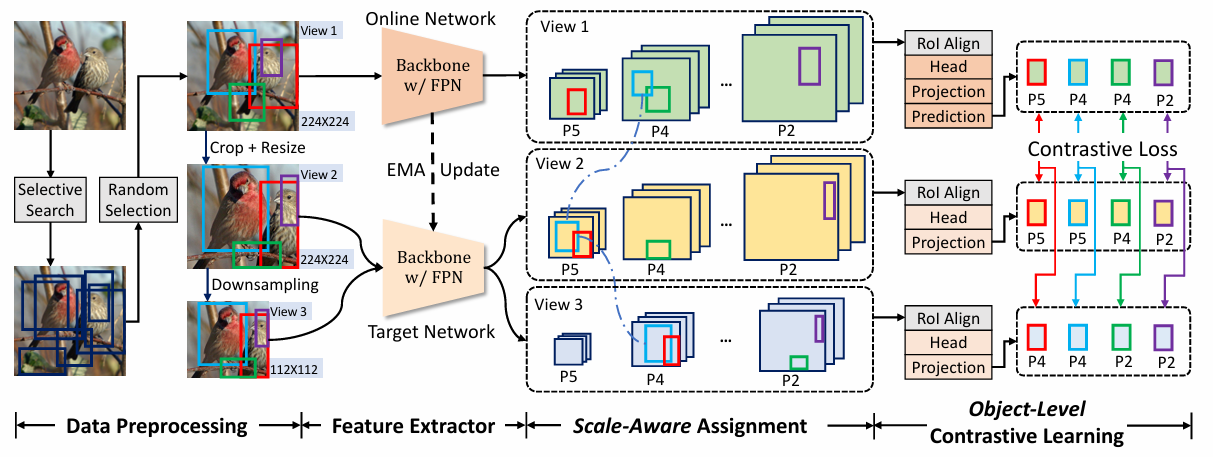
기존 self-supervised contrastive learning은 주로 backbone만을 pretraining하던 것과 달리 SoCo는 FPN과 Mask R-CNN의 head를 포함해 detection network의 모든 모듈을 pretraining 한다.
또한 object-level representation을 학습해 translation과 scale에 불변성을 가진다. 즉, 다양한 크기와 위치에서 여러개의 augmentation view를 생성하고, feature pyramid의 각 level에 적절한 scale를 할당하는 전략을 사용한다.
Data Preprocessing
Object Proposal Generation
Select Search 알고리즘은 color의 유사도, texture의 유사도, region의 사이즈, regeion간의 적합성을 고려해 원본 이미지에서 object proposal를 생성한다.
- object proposal :
이때 과 는 다음 조건을 만족해야 한다.
object proposal은 입력 이미지 당 K개의 랜덤 선택된다.
View Construction
SoCo에서는 3개의 view()를 생성한다.
- : 원본 이미지를 로 resizing
- : 에서 [0.5, 1.0] 범위의 random crop을 수행한 후 다시 로 resizing. 이때 밖에 위치한 object proposal은 제거된다.
- : 를 로 downsampling하여 생성
이를 통해 동일한 object proposal은 서로 다른 view에서 다양한 크기와 위치를 가진다. 이를 통해 model이 translation-invariance 및 scale-invariance을 학습할 수 있다.
Box Jitter
object proposal의 크기와 위치 변화를 더욱 다양하게 하기 위해 box jitter를 적용했다. 이는 주어진 region proposal인 에 대해 랜덤으로 변형된 bounding box인 를 생성한다.
여기서 은 -10%~10% 범위의 random 값이라고 한다. 이러한 box jitter는 각 object proposal에 대해 50%의 확률로 적용된다고 한다.
Object-Level Contrastive Learning
SoCo의 목표는 pretraining을 object detection에 적용하는 것이다.
Aligning Pretraining Architecture to Object Detection
Mask R-CNN의 FPN을 포함한 backbone network인 를 image-level feature extractor로 사용한다. 이때 FPN의 출력은 가 되고 는 해상도가 너무 낮아 사용되지 않는다. 각 pyramid의 stride는 이다. 구조적 alignment를 강화하기 위해 pretraining 과정에 R-CNN의 head인 를 추가하였다. 이때, 특정 이미지 view 에서 bounding box 의 object-level feature representation 는 다음과 같이 정의했다.
SoCo는 online network와 target network 2개의 network를 학습한다. 이때 target network의 가중치인 는 online network의 가중치인 의 EMA (Exponential Moving Average)로 업데이트를 한다.
각 object proposal set 의 표현은 다음과 같이 정의된다.
- online network를 사용해 에서 object feature 추출
- target network를 사용해 에서 object feature 추출이때, online network에서는 projector , predictor 를 추가해 latent embedding을 생성한다. 이는 각각 2층의 MLP로 구성된다. target network에는 projector만 추가하였다. (trivial solution을 방지하기 위해)
이때 각 object proposal ()에 대해 contrastive loss는 다음과 같이 계산한다.전체 loss는 각 object proposal K에 대해 평균을 취한 값이 된다.이때 Loss을 대칭화 시키기 위해 와 를 각각 online network와 target network에 입력해 를 다시 계산한다.
최종 Loss는 다음과 같다.
Scale-Aware Assignment
각 FPN에서 할당된 ground-truth box의 크기는 다음과 같다.
- : 픽셀
- : 픽셀
- : 픽셀
- : 픽셀
이와 유사하게 object proposal의 크기는 각 FPN level에 따라 다음과 같이 정의된다.
이때 최대 크기가 인 이유는 모든 view가 224보다 작기 때문이다.
이를 통해 서로 다른 크기의 동일 object가 일관된 표현을 학습할 수 있다.
Introducing Properties of Detection to Pretraining
이는 translation invariance와 scale invariance가 중요한 속성으로 간주되기 때문에 이를 학습하기 위해 다음과 같은 과정을 수행한다.
- 는 의 random crop
- bounding box의 이동을 유발하여 과 간 contrastive learning을 수행해 location-invariant를 학습한다.
- 는 의 downsampling
- object의 크기를 축소해 과 간 contrastive learning을 수행해 scale-invariant를 학습한다.
Extending to Other Object Detectors
SoCo는 Mask R-CNN + FPN 뿐 아니라 Mask R-CNN + C4에 적용할 경우
- 모든 object proposal에 대해 C4에서 RoIAlign을 수행
- R-CNN head를 5번째 ResNet block으로 교체
- 를 제거하고 만 사용
위 과정을 걸처 다양한 detector model과 호환이 가능하다.
Conclusion
SoCo는 기존 image-level contrastive learning이 전체 이미지를 하나의 instance로 간주하던 것과 달리 SoCo는 Selective Search를 통해 생성된 object proposal을 개별 instance로 간주하여 학습한다.
