ECCV 2022
Abstract
기존 Object Detection은 제한된 category의 object만 detection 할 수 있었다. 쵠근엔 open vocabulary 및 zero-shot detection 기법이 학습되지 않은 category를 탐지할 수 있다. 하지만 여전히 학습 가능한 category 수가 제한적이다. 이를 해결하기 위해 대규모 image-caption data에서 다양한 object에 대한 pseudo bounding-box annotation을 자동으로 생성하는 방법을 제안했다. 성과는 다음과 같다.
- COCO의 새로운 category : 8% AP 향상
- PASCAL VOC : 6.3% AP 향상
- Objects365 : 2.3% AP 향상
- LVIS : 2.8% AP 향상
Introduction
기존 새로운 category의 object를 detection 하려면 추가적인 bounding box annotation 작업이 필요하다. 이를 해결하기 위해 Zero-Shot object detection과 Open Vocabulary object detection 기법이 연구되고 있다.
- Zero-Shot Object Detection
기본 category와 새로운 category 간의 관계를 활용해 새로운 object category에 대한 일반화 능력을 향상시킨다.기존 단점
여전히 대규모의 수작업 annotation data를 요구한다는 한계가 있다. 즉, 기본 category의 annotation의 data가 필요함
- Open Vocabulary Object Detection
image caption data를 활용해 시로운 object detection 성능을 향상시킨다.기존 단점
훈련 가능한 기본 category의 수가 적어 여전히 다양한 새로운 object의 일반화가 어렵다.
이를 해결하기 위해 기존 자원을 활용해 object에 대해 bounding box annotation을 자동으로 생성할 수 있을지에 대한 연구를 수행하였다. 이를 통해 open-vocabulary object detection을 향상 시킬 수 있을까라는 질문을 던진다.
이는 대규모 image-captioning data를 활용해 object에 대해 pseudo bounding box annoatition을 생성하는 새로운 open-vocabulary object detection을 제안했다.
- Vision-Language model을 활용한 pseudo bounding box 생성
- pretraining된 vision-language model과 image-captioning data를 활용해 특정 object가 언급된 이미지 영역의 Grad-CAM을 계산
- 이를 bounding box로 변환해 object detection model 학습에 활용
- 완전 자동화된 annotation 생성
- 수작업 없이 자동으로 bounding box 생성 가능
- SOTA(Open Vocabulary) 모델 대비 성능 향상
- COCO dataset의 새로운 object detection 성능에서 기존 방법 대비 8% mAP 향상
Related Work
Object detection
Weakly supervised object detectors는 annotation 작업의 부담을 줄이기 위해 image-level label를 이용해 학습한다. 이는 고정된 category set 내에서만 작동되고 새로운 category를 detection 하려면, 해당 object의 data를 수집하고, 수동으로 annotation을 달아 다시 학습해야 한다.
Open vocabulary and zero-shot object detection
Open vocabulary와 zero-shot object detection은 기본 object class에 대한 annotation을 사용해 학습하고, 새로운 object의 class로 일반화를 수행한다.
OREO는 contrastive clustering과 energe-based unknown identification을 기반으로 unknown object를 점진적으로 학습한다. 이때 zero-shot의 성능을 향상시키기 위해 open vocabulary object detection에서는 pre-trained vision-language model의 image encoder를 detector 초기화에 활용해 성능을 향상시켰다
ViLD는 대규모 vision-language model(CLIP)에 knowledge distillation을 수행해 우수한 zero-shot 성능을 달성했다.
하지만 이들은 bounding box annotation이 있는 제한된 base category만 학습할 수 있고, inference에서 novel category가 base category와 다르면 일반화가 어렵다.
이 논문에서는 large-scale image-caption pair에서 pseudo box label를 생성하고 이를 detector 학습에 활용한다.
Vision-language pre-training models
대규모 image-cpation pair를 이용해 학습되고, zero-shot image classification과 같은 Image-only task에서도 성공적인 성과를 보인다.
Our Approach
이 framework는 pseudo bounding-box label generator와 open vocabulary object detector 2 가지 구성 요소로 이루어져 있다.
- pseudo label-generator
pre-trained vision-language model을 활용해 다양한 object에 대해 bounding box label을 자동으로 생성한다. 이후, 생성된 pseudo label를 이용해 detector를 직접 학습한다. - open vocabulary object detection
human-annotated bounding box가 있는 base object category가 제공될 경우, 학습된 detector를 해당 데이터로 fine-tuning을 한다.
Generating Pseudo Box Labels
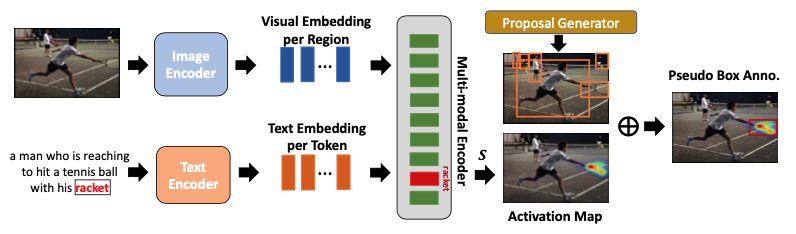
input은 image-caption pair이고, image encoder와 text encoder를 사용해 image와 해당 caption의 visual embedding과 text embedding을 추출한다. 이후, cross-attention을 통해 image와 text 간의 interaction을 수행해 multi-modal feature를 얻는다.
이를 통해 pseudo label를 생성한다. pre-trained vision-language model에서 이미지의 특정 영역과 caption 내 단어 간 암묵적인 alignment을 활용해, 관심 object에 대한 pseudo bounding-box annotation을 생성한다.
! Vision-Language Model
- Input: image 와 해당 caption
- 이때, 는 caption의 단어 수이고, 이때, [CLS]와 [SEP] token도 포함된다.
- Image encoder: image의 feature을 추출해 로 표현됨
- 이때, 는 image의 region representation의 개수이다.
- Text encoder: text를 표현하여
- Multi-modal encoder: 개의 연속된 cross-attention layer를 사용해 image와 text 정보를 융합한다.
각 cross-attention layer에서 caption의 특정 단어 가 image의 region들과 어떻게 상호작용하는지 아래를 보고 알 수 있다.
즉, 다음과 같다.
- : 번째 cross-attention layer에서의 visual attention score
- : 이전 번째 layer에서 얻은 hidden representation
- : text encoder에서 나온 초기 representation
이를 통해 특정 단어 가 이미지의 어떤 영역과 관련이 있는지 측정하고, 해당 영역의 가중 평균을 계산한다.
Grad-CAM을 활용해 최종 multi-modal encoder의 출력 를 기반으로 attention score의 gradient를 계산한다.
activation map 는 다음과 같이 계산된다.
여러 개의 attention head가 있을 경우, 모든 head에서 얻은 activation map 를 평균 내어 최종 activation map으로 사용한다.
위를 통해 caption에서 특정 object의 activation map을 얻은 후, 활성화 된 영역을 포함하는 bounding box를 생성해 해당 category의 pseudo label로 사용한다.
- Proposal Generator (예, Selective Search, EdgeBoxes)를 이용해 bounding box 후부 집합인 생성
최종 bounding box 는 activation map과 가장 많이 겹치는 proposal을 선택하여 결정한다.
- : bounding box 내에서의 activation map 합
- : bounding box의 면적
Open Vocabulary Object Detection with Pseudo Labels
일반적인 open vocabulary detection system은 다음과 같다.
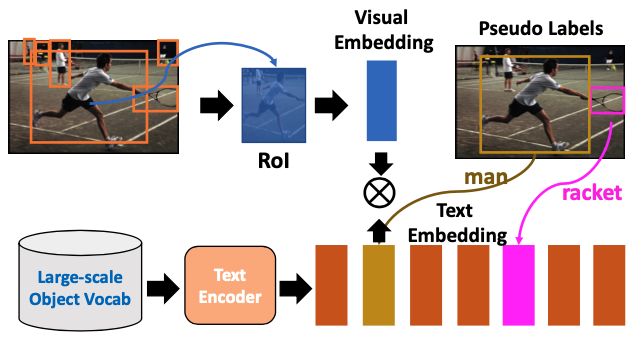
input image에서 feature extractor를 이용해 feature map을 추출한 후, 이를 기반으로 object proposal이 생성된다. 이후, RoI pooling/ RoI align을 거쳐 full connected layer를 통과해, region-based visual embedding, 을 얻는다. 이때, 은 region의 개수이다.
pre-trained 된 text encoder를 사용해 object vocabulary에서 object 후보들의 text embedding, 을 획득하고, 이때, 는 훈련된 object vocabulary의 크기를 의미하고, 는 background를 나타낸다. 이를 통해 동일한 object의 visual embedding과 text embedding을 가깝게 하고, 서로 다른 object의 embedding은 멀어지도록 한다. 이를 통해 와 가 매칭될 확률을 다음과 같이 계산된다.
이를 통해 positive pair의 매칭을 강화하고 negative pair의 매칭을 억제한다.
inference 시에 관심 있는 object class 집합이 주어질 때, region proposal은 vocabulary 내 모든 object 이름들과 비교해 해당 region의 visual embedding과 거리가 가장 작은 text embedding을 가지는 object class에 매칭된다.
Experiments
Datasets and Object Vocabulary for Training
Training Datasets.
이 mothod는 COCO caption, Visual-Genome, SBU Caption을 포함한 기존 image-caption dataset을 결합해 다양한 object의 pseudo bounding-box annotation을 생성했다.
Object Vocabulary
위에서 언급한 dataset으로 object category에 대한 pseudo label을 생성할 때, 기본 object vocabulary는 COCO, PASCAL VOC, Objects365, LVIS의 모든 object 이름을 합쳐 구성되고, 총 1,582개의 category를 포함한다.
