ICLR 2022
Abstract
text input으로 설명된 object를 detection 하는 open-vocabulary object detection을 발전 시키는 것을 목표로 한다. 기존 object detection dataset에서 class의 수를 확장하는 것은 비용이 매우 많이 든다.
이를 해결하기 위해 ViLD(Vision and Language Knowledge Distillation)라는 훈련 방법을 제안했다. 이는 pre-trained 된 open-vocabulary image classification model(teacher)로부터 two-stage detector(student)로 지식을 증류하는 방식이다.
- teacher model을 사용해 object proposal의 image 영역과 category text를 encoding 한다
- 이후, student detector를 훈련해 detection 된 box의 region embedding이 teacher가 추론한 text와 image embedding과 정렬되도록 한다.
LVIS dataset에서 희귀한 category를 novel category로 설정해 benchmarking을 수행했고, ResNet-50 backbone을 사용한 ViLD는 16.1 mask AP를 기록하여 supervised 방식보다 3.8 높았다.
이는 finetuning 없이도 다른 dataset으로 직접 transfer이 가능하고 다음과 같은 성능을 기록한다.
- PASCAL VOC: 72.2 AP
- COCO: 36.6 AP
- Objects365: 11.8 AP
Introduction
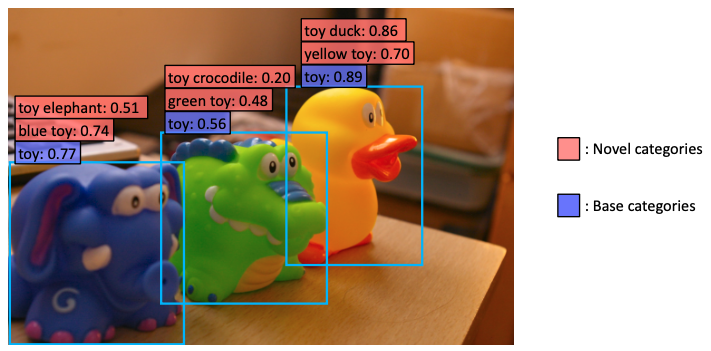
위 그림을 볼 때 기존 category (ex. toy)를 제외한 새로운 category (ex. toy elephant)를 detection 하는 방법을 구상한다.
기존 object detection은 일반적으로 detection dataset에 포함된 category만 탐지하도록 학습한다. 최근에 방대한 vocabulary를 포함하는 새로운 object detection dataset을 구축하고 있으며, 예를 들어 LVIS가 있다. 이는 1,203개의 category를 포함하고 있지만, 모든 category에 대해 충분한 학습 데이터를 확보하기 쉽지 않다.
사전 학습된 text encoder는 arbitrary text category에 대해 zero-shot transfer가 핵심이다. image-level representation 학습에는 성공적이었지만, object-level representation을 활용한 open-vocabulary detection은 여전히 어려운 문제이므로, pre-trained된 open-vocabulary classification model의 지식을 활용해 open-vocabulary detection을 가능하게 한다.
이 논문은 R-CNN의 기법을 사용해
- generalized object proposal
- open-vocabulary image classification
위 방법을 통해 해결한다. 먼저, base category를 이용해 region proposal model을 학습하고, 이후, pre-trained된 open-vocabulary image classification model을 사용해 cropped object proposal을 분류하지만 이는 기존 supervised 방식보다 더 높은 성능을 보였지만, inference 속도가 매우 느리다는 단점이 있다.
이를 해결하기 위해 open-vocabulary detector를 학습하는 ViLD (Vision and Language knowledge Distillation)을 제안했다. 구성 요소는 다음과 같다.
- text embedding을 활용한
ViLD-text- pre-trained 된 text encoder을 사용해 category 이름을 text embedding으로 변환한 후, 이를 detectionehls region을 분류하는데 사용
- image embedding을 활용한
ViLD-image
