
1. Text Classification using Keras
① 훈련 데이터에 대한 이해
여기서 진행되는 텍스트 분류 실습은 지도 학습(Supervised Learning)에 속한다. 지도 학습의 훈련 데이터는 레이블이라는 이름의 미리 정답이 적혀있는 데이터로 구성되어 있다.
예를 들어, 스팸 메일 분류기의 훈련 데이터의 경우, 메일의 내용과 해당 메일의 스팸 메일 여부가 적혀 있는 레이블로 구성되어 있다. 아래와 같은 형식의 메일 샘플이 약 20,000 개 있다고 가정하겠다.
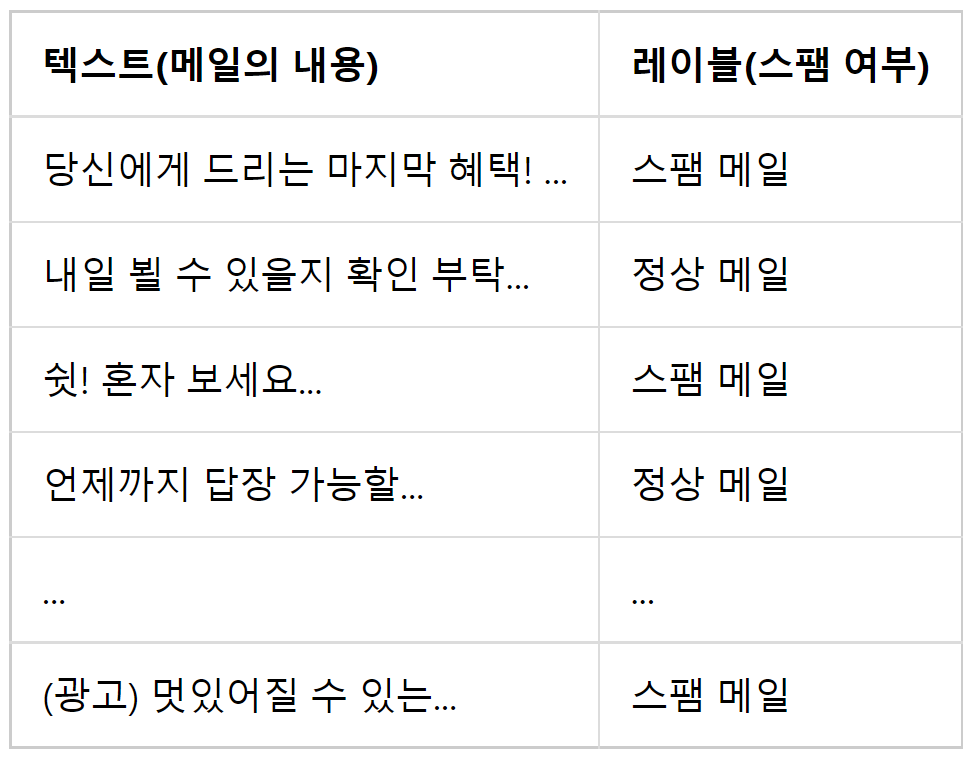
데이터에 문제가 없고, 모델도 잘 설계되어 있다면, 학습된 모델은 훈련 데이터에 존재하지 않았던 어떤 메일 텍스트가 주어지더라도 정확한 레이블을 예측할 수 있다.

② 훈련 데이터와 테스트 데이터
사실 20,000 개의 메일 샘플을 모두 훈련에 쓰는 것보다는, 테스트 용으로 일부 남겨놓는 것이 권장된다. 예를 들어 20,000 개의 샘플 중 18,000 개의 샘플은 훈련용으로 사용하고, 나머지 샘플은 테스트용으로 보류한 채 훈련 과정에서는 사용하지 않을 수 있다.
그 후 훈련이 끝나면, 테스트용 샘플로 모델에게 레이블은 보여주지 않고, 모델에게 레이블을 맞춰보라고 하여 정확도(accuracy)를 계산할 수 있다.
③ 단어에 대한 정수 부여
Keras의 Embedding()은 단어 각각에 대해 정수로 변환된 입력에 대해서 임베딩을 수행한다.
단어 각각에 정수를 부여하는 방법으로는, 단어를 빈도 순으로 정렬하고 빈도 순위에 따라 순차적으로 정수를 부여하는 것이 있다. 이 방식을 쓰면, 상위 몇 개의 빈도만 살리고, 희귀한 단어를 쉽게 걸러낼 수 있다.
④ RNN으로 분류하기
model.add(SimpleRNN(hidden_units, input_shape=(timesteps, input_dim)))hidden_units: RNN의 출력의 크기(=은닉 상태의 크기)timesteps: 시점의 수(=각 문서에서의 단어 수)input_dim: 입력의 크기(=임베딩 벡터의 차원)
⑤ RNN의 다 대 일(many-to-one) 문제
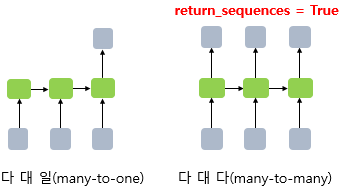
텍스트 분류는 RNN의 다 대 일 문제에 속한다. 즉, 텍스트 분류는 모든 시점(time step)에 대해서 입력을 받지만 최종 시점의 RNN 셀만이 은닉 상태를 출력하고, 이것이 출력층으로 가서 활성화 함수를 통해 정답을 고르는 문제가 된다. 한편, 선택지 개수에 따라 다음과 같이 나누어진다.
ⓐ 이진 분류(Binary Classification) 문제
- 두 개의 선택지 중에서 정답 고르기
- 활성화 함수: Sigmoid 함수
- 손실 함수:
binary_crossentropy
ⓑ 다중 클래스 분류(Multi-Class Classification) 문제
- 세 개 이상의 선택지 중에서 정답 고르기
- 활성화 함수: Softmax 함수
- 손실 함수:
categorical_crossentropy - 클래스가 개라면 Dense Layer의 크기는 (= 출력층 뉴런의 수는 개)
2. 스팸 메일 분류하기
https://drive.google.com/file/d/1W0nhdu4UTZU5eQH4SLZtVIOYCumlfOMw/view?usp=sharing
3. 로이터 뉴스 분류하기
https://drive.google.com/file/d/1owQmbTwe5RdswTcTac1D7SyFkXHc1qoA/view?usp=sharing
4. Bidirectional LSTM
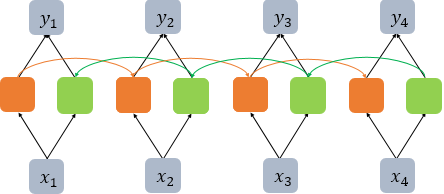
BiLSTM은 두 개의 독립적인 LSTM 아키텍처를 함께 사용하는 구조이다. 위 그림에서 주황색 LSTM 셀은 순차적으로 입력을 받는다. 추가로 뒤의 문맥까지 고려하기 위해, 초록색 셀처럼 오른쪽에서 반대로 읽는 역방향의 LSTM 셀도 함께 사용한다. 이 두 가지 정보를 출력층에서 예측 시에 모두 사용한다.
위 그림은 다 대 다(many-to-many) 문제를 푸는 경우의 Bi-LSTM을 보여주는 반면, 다 대 일(many-to-one) 문제인 텍스트 분류에 사용한다고 하면 의문점이 하나 생긴다.
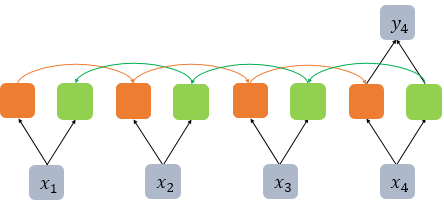
일반적으로 순방향 LSTM은 마지막 시점의 은닉 상태를 출력층으로 보내서 텍스트 분류를 수행한다.
그렇다고 역방향 LSTM도 순방향과 같은 시점의 은닉 상태를 사용한다면, 이것이 유용한 정보를 가지고 있다고 기대하기는 어렵다.
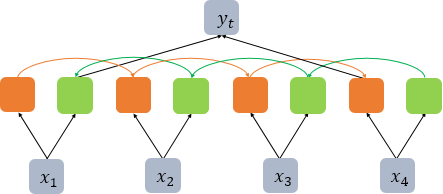
그래서 Keras에서는 Bi-LSTM을 사용하면서 return_sequences=False를 택할 경우에 위의 그림처럼 동작한다. 순방향 LSTM의 경우, 마지막 시점의 은닉 상태를 반환하고, 역방향 LSTM의 경우, 첫 번째 시점의 은닉 상태를 반환한다.
<참고 문헌>
유원준/안상준, 딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21694
박호현 교수님, 인공지능, 중앙대학교 전자전기공학부, 2024
