
1. Tokenization(토큰화)
가. 정의
토큰화란 주어진 corpus(코퍼스) 에서 token(토큰) 이라는 단위로 나누는 작업이다. 이때 코퍼스란 자연어 연구를 위해 특정 목적을 가지고 언어의 표본을 추출한 집합이다. 또한, 토큰의 단위는 상황에 따라 의미를 가질 수 있는 단위로 정의된다.
나. Word Tokenization(단어 토큰화)
토큰의 기준을 단어로 하는 토큰화를 단어 토큰화라고 한다. 이때 여기서 단어는 단어뿐만 아니라 단어구 또는 의미를 가지는 문자열로도 간주된다.
예를 들어, 입력값에서 구두점(마침표, 쉼표, 물음표, 세미콜론, 느낌표)과 같은 문자는 제외하는 토큰화를 한다고 하겠다.
입력: There is no remedy for love but to love more.
출력: "There", "is", "no", "remedy", "for", "love", "but", "to", "love", "more"
단어 토큰화 관련 패키지로는 다음과 같은 것이 있다.
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPuncTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
from nltk.tokenize import TreebankWordTokenizer다. Sentence Tokenization(문장 토큰화)
코퍼스 내에서 문장 단위로 구분하는 작업을 문장 토큰화라고 한다. 문장 분류(sentence segmentation)라고도 한다.
이를 구현한 예시는 다음과 같다.
라. 한국어 문장 토큰화
영어에 비해 한국어는 띄어쓰기만으로 토큰화를 하기에는 어려움이 있다. 한국어에서 띄어쓰기 단위가 되는 것을 어절이라고 하는데, 이를 기준으로 토큰화하는 것은 한국어 Natural Language Processing(NLP)에서는 지양되고 있다. 이유는 다음과 같다.
1) 한국어는 영어와 달리 교착어이다.
- 교착어란 조사, 어미 등을 붙여서 말을 만드는 언어이다.
- 형태소란 뜻을 가지는, 가장 작은 말의 단위이다.
- 자립 형태소: 접사, 어미, 조사와 무관하게 자립하여 사용될 수 있는 형태소. 그 자체로 단어가 된다. 그 예로 체언(명사, 대명사, 수사), 수식언(관형사, 부사), 감탄사가 있다.
- 의존 형태소: 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간을 가리킨다.
- 예시: 철수가 책을 읽었다.
→ 자립 형태소: 철수, 책
→ 의존 형태소: -가, -을, 읽-, -었-, 다
2) 한국어는 영어보다 띄어쓰기가 잘 지켜지지 않는다.
- 한국어는 띄어쓰기가 잘 지켜지지 않아도 글을 쉽게 이해할 수 있는 언어이다.
다음을 사용하면 한국어 문장 토큰화가 가능하다.
import kss마. Part-of-speech tagging(품사 태깅)
단어가 표기는 같더라도 품사에 따라 그 뜻이 달라지기도 한다. 예를 들어, 영어 단어 'fly'는 동사로 쓰이면 '날다'이지만, 명사로 쓰이면 '파리'이다. 또한, 한국어 단어 '못'은 명사로 쓰이면 '망치를 사용해서 목재 따위를 고정하는 물건'이지만, 부사로 쓰이면 동작 동사를 할 수 없다는 의미로 쓰인다.
단어 토큰화 과정에서 각 단어가 어떤 품사로 사용되었는 지를 구분하기도 하는데, 이 작업을 품사 태깅이라고 한다. 이를 NLTK와 KoNLPy을 이용하여 실습해보겠다.
<python 코드>
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "I am actively looking for Ph.D students. and you are a Ph.D student."
tokenized_sentence = word_tokenize(text)
print('단어 토큰화: ' , tokenized_sentence)
print('품사 태깅: ', pos_tag(tokenized_sentence))<출력 결과>

한국어 NLP을 위해서 KoNLPy라는 패키지를 사용할 수 있는데, 이를 통해 Okt(Open Korea text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)라는 형태소 분석기를 사용할 수 있다. 각 형태소 분석기는 성능과 결과가 다르기 때문에, 상황에 따라 가장 적절한 분석기를 사용하면 된다. 예를 들어, 속도가 중요한 경우에는 메캅을 사용하면 된다.
<python 코드>
pip install konlpy
from konlpy.tag import Okt
okt = Okt()
print('OKT 형태소 분석:', okt.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('OKT 품사 태깅:', okt.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('OKT 명사 추출:', okt.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))<출력 결과>

<python 코드>
from konlpy.tag import Kkma
kkma = Kkma()
print('꼬꼬마 형태소 분석 :',kkma.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('꼬꼬마 품사 태깅 :',kkma.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('꼬꼬마 명사 추출 :',kkma.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요")) <출력 결과>

2. Cleaning(정제) & Normalization(정규화)
가. 정의
정제란
가지고 있는 코퍼스로부터 noise data(노이즈 데이터)를 제거하는 것이다. 노이즈 데이터는 자연어가 아니면서 아무 의미도 갖지 않는 글자들(특수 문자 등)을 의미하기도 하지만, 분석 목적에 부합하지 않는 불필요 단어를 가리키기도 한다. 이를 제거하는 방법으로는 Stopword(불용어) 제거와 등장 빈도가 적은 단어, 길이가 짧은 단어를 제거하는 방법 등이 있다.
정규화란
표현 방법이 다른 단어를 통합시켜 같은 단어로 만드는 것이다. 방법으로는 규칙에 기반한 표기가 다른 단어의 통합(USA와 US), 대소문자 통합, Stemming(어간 추출) 및 Lemmatization(표제어 추출)이 있다.
나. 정규화 - 표제어 추출
표제어 추출로 단어들이 다른 형태를 가져도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단한다. 예를 들어, 'is, am, are'은 서로 다른 모습이지만, 그 뿌리 단어는 'be'이다. 여기서 이 단어들의 표제어를 'be'라고 할 수 있다.
표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 먼저 하는 것이다. 형태학이란 형태소로부터 단어를 만들어간다는 뜻의 학문인데, 형태소의 종류로는 어간과 접사가 있다. 형태학적 파싱은 이 두 요소를 분리하는 작업이다. 어간 추출에 대한 코드는 후술한다.
<python 코드>
import nltk
nltk.download('wordnet')
nltk.download('punkt')
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print('표제어 추출 전 :',words)
print('표제어 추출 후 :',[lemmatizer.lemmatize(word) for word in words])<출력 결과>

위 코드에서 WordNetLemmatizer는, 단어의 품사가 동사임을 입력할 수도 있다.
<python 코드>
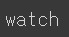
print(lemmatizer.lemmatize('dies', 'v'))
print(lemmatizer.lemmatize('watched', 'v'))
print(lemmatizer.lemmatize('has', 'v'))<출력 결과>


다. 정규화 - 어간 추출
어간을 추출하는 작업을 어간 추출이라고 한다. 이는 앞서 언급된 형태학적 분석을 단순화한 버전으로 볼 수 있다. 또한, 정해진 규칙에만 의해 단어의 어미를 자르는 어림 짐작의 작업으로도 볼 수 있다. 그런데 해당 작업은 그리 섬세하지 않기 때문에, 추출 후 결과로 나오는 단어가 사전에 부재할 수도 있다.
<python 코드>
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
stemmer = PorterStemmer()
sentence = "This was not the map we found in Billy Bones's chest, but an accurate copy, complete in all things--names and heights and soundings--with the single exception of the red crosses and the written notes."
tokenized_sentence = word_tokenize(sentence)
print('어간 추출 전 :', tokenized_sentence)
print('어간 추출 후 :',[stemmer.stem(word) for word in tokenized_sentence])<출력 결과>

<python 코드: PorterStemmer Vs. LancasterStemmer>
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
porter_stemmer = PorterStemmer()
lancaster_stemmer = LancasterStemmer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print('어간 추출 전 :', words)
print('포터 스테머의 어간 추출 후:',[porter_stemmer.stem(w) for w in words])
print('랭커스터 스테머의 어간 추출 후:',[lancaster_stemmer.stem(w) for w in words])<출력 결과>

라. 정제 - 불용어
I, my, me, over, 조사, 접미사 등의 단어는 문장에서는 자주 나타나지만, 실제 의미를 분석하는 데는 거의 쓸모가 없는 경우가 있다. 이러한 단어를 불용어라고 하며, NLTK에서는 이미 100 여개 이상의 영단어를 불용어로 패키지 내에서 미리 정의하고 있다. 이를 확인하면 다음과 같다.
<python 코드: 불용어 확인>
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stop_words_list = stopwords.words('english')
print('불용어 개수 :', len(stop_words_list))
print('불용어 10개 출력 :',stop_words_list[:10])<출력 결과>

불용어를 제거하는 코드는 다음과 같다.
<python 코드: 불용어 제거>
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example = "Family is not an important thing. It's everything."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example)
result = []
for word in word_tokens:
if word not in stop_words:
result.append(word)
print('불용어 제거 전 :',word_tokens)
print('불용어 제거 후 :',result)<출력 결과>

한국어 NLP에서 불용어를 제거하는 방식은 다음과 같다.
<python 코드: 한국어 불용어 제거>
from konlpy.tag import Okt
okt = Okt()
example = "고기를 아무렇게나 구우려고 하면 안 돼. 고기라고 다 같은 게 아니거든. 예컨대 삼겹살을 구울 때는 중요한 게 있지."
stop_words = "를 아무렇게나 구 우려 고 안 돼 같은 게 구울 때 는"
stop_words = set(stop_words.split(' '))
word_tokens = okt.morphs(example)
result = [word for word in word_tokens if not word in stop_words]
print('불용어 제거 전 :',word_tokens)
print('불용어 제거 후 :',result)<출력 결과>

3. 정규 표현식(Regular Expression)
가. Why Regular Expression?
Example
주민등록번호를 포함하고 있는 텍스트가 있다. 이 텍스트에 포함된 모든 주민등록번호의 뒷자리를 /* 문자로 변경하라.
<python 코드 1>
data = """
park 800905-1049118
kim 700905-1059119
"""
result = []
for line in data.split("\n"):
word_result = []
for word in line.split(" "):
if len(word) == 14 and word[:6].isdigit() and word[7:].isdigit():
word = word[:6] + "-" + "*******"
word_result.append(word)
result.append(" ".join(word_result))
print("\n". join(result))<출력 결과>
park 800905-*******
kim 700905-*******
<python 코드 2>
import re
data = """
park 800905-1049118
kim 700905-1059119
"""
pat = re.compile("(\d{6})[-]\d{7}")
print(pat.sub("\g<1>-*******", data))<출력 결과>
park 800905-*******
kim 700905-*******
<python 코드 1> 은 조건문과 인덱스 기반으로 처리하며, 정규표현식을 사용하지 않고 절차적으로 처리한다. 반면, <python 코드 2> 은 정규표현식을 사용하여 더욱 유연하고 간결하게 주민등록번호를 처리한다. 정규표현식은 패턴이 확실한 경우, 더 간결하고 확장 가능성이 높은 방법이다.
나. 정규표현식 특수문자(메타문자)
| 특수 문자 | 설 명 |
|---|---|
| . | 임의의 문자 하나 |
| ? | 앞의 문자가 존재할 수도 있고, 존재하지 않을 수도 있음(문자가 0개 또는 1걔) |
| * | 앞의 문자가 무한대로 존재할 수도 있고, 존재하지 않을 수도 있음(문자가 0개 이상) |
| + | 앞의 문자가 최소 한 개 이상 존재(문자가 1개 이상) |
| ^ | 뒤의 문자열로 문자열이 시작됨 |
| $ | 앞의 문자열로 문자열이 끝남 |
| {m} | m 회만큼 반복 |
| {m, n} | m 이상 n 이하만큼 반복. 여기서 m 또는 n 생략 가능. 생략된 m은 0과 동일하며, 생략된 n은 무한대 의미 |
| [] | 대괄호 안의 문자들 중 한 개의 문자와 매치 |
| [^문자] | 해당 문자를 제외한 문자와 매치 |
| | | A|B와 같이 쓰이며, A 또는 B의 의미를 가짐 |
| \b | 단어 구분자(word boundary). 보통 단어는 whitespace로 구분됨 |
| \B | \b 메타문자와 반대의 경우. 즉, whitespace로 구분된 단어가 아닌 경우에만 매치 |
| ( ) | Grouping |
<| 메타문자 사용 예시>
p = re.compile('Crow | Servo')
m = p.match('CrowHello')
print(m)<re.Match object; span=(0, 4), match='Crow'>
<^ 메타문자(문자열의 맨 처음과 일치) 사용 예시>
print(re.search('^Life', 'Life is too short'))<re.Match object; span=(0, 4), match='Life'>
print(re.search('^Life', 'My Life'))None
※ \A의 경우
\A은 문자열의 처음과 매치된다는 것을 의미한다. ^ 메타 문자와 동일한 의미이지만, re.MULTILINE 옵션을 사용할 경우에는 다르게 해석된다. re.MULTILINE 옵션을 사용할 경우, ^ 은 각 줄의 문자열의 처음과 매치되지만, \A은 줄과 상관없이 전체 문자열의 처음하고만 매치된다.
<$ 메타문자(^와 반대. 문자열의 끝과 매치) 사용 예시>
print(re.search('short$', 'Life is too short'))<re.Match object; span=(12, 17), match='short'>
print(re.search('short$', 'Life is too short, you need python'))None
※ \Z의 경우
\Z은 문자열의 끝과 매치된다는 것을 의미한다. 이것도 \A와 동일하게 re.MULTILINE 옵션을 사용할 경우, $ 메타문자와는 달리 전체 문자열의 끝과 매치된다.
※ \b의 경우
p = re.compile(r'\bclass\b')
print(p.search('no class at all'))<re.Match object; span=(3, 8), match='class'>
<() 메타문자 사용 예시 1>
p = re.compile('(ABC)+')
m = p.search('ABCABCABC OK?')
print(m)<re.Match object; span=(0, 9), match='ABCABCABC'>
print(m.group())ABCABCABC
<() 메타문자 사용 예시 2>

p = re.compile((r"(\w+)\s+(\d+[-]\d+[-]\d+)")
m = p.search("park 010-1234-1234")
print(m.group(1)) # park
print(m.group(2)) # 010-1234-1234※ grouping된 문자열 재참조하기
p = re.compile(r'(\b\w+)\s+\1')
p.search('Paris in the the spring').group()'the the'
정규식 (\b\w+)\s+\1 은 (그룹) + " " + (그룹) 과 동일한 단어와 매치됨을 의미한다. 이렇게 정규식을 만들게 되면 2개의 동일한 단어를 연속적으로 사용해야만 매치된다.
※ grouping된 문자열에 이름 붙이기
p = re.compile(r"(?P<name>\w+)\s+((\d+)[-]\d+[-]\d+)")
m = p.search("park 010-1234-1234")
print(m.group("name"))park
그룹 이름을 사용하면 정규식 내에서 재참조하는 것도 가능하다.
p = re.compile(r'(?P<word>\b\w+)\s+(?P=word)')
p.search('Paris in the the spring').group()'the the'
<전방 탐색(lookahead) 예시>
p = re.compile(".+:")
m = p.search("http://google.com")
print(m.group())http:
※ http:라는 검색 결과에서 :을 제외하고 출력하려면 어떻게 하는가?
- 긍정형 전방 탐색((?=...)): ...에 해당하는 정규식과 매치되어야 하며, 조건이 통과되어도 문자열이 소비되지 않음
p = re.compile(".+(?=:)")
m = p.search("http://google.com")
print(m.group())http
- 부정형 전방 탐색((?!...)): ...에 해당하는 정규식과 매치되지 않아야 하며, 조건이 통과되어도 문자열이 소비되지 않음
.*[.].*$위는 '파일_이름 +.+ 확장자'를 나타내는 정규식이다. 이 정규식은 foo.bar, autoexec.bat, sendmail.cf 같은 형식의 파일과 매치될 것이다.
위 정규식에 '확장자가 bat인 파일은 제외해야 한다'라는 조건을 추가해보겠다.
.*[.](?!bat$).*$bat 파일 외에 exe 파일도 제외하는 조건을 추가해보겠다.
.*[.](?!bat$|exe?).*$<후방 탐색(lookbehind) 예시>
다. 정규표현식 문자 규칙
| 문자 규칙 | 설 명 |
|---|---|
| \d | 모든 숫자를 의미. [0-9]와 의미 동일 |
| \D | 숫자를 제외한 모든 문자를 의미. [^0-9]와 의미 동일 |
| \s | 공백을 의미. [\t\n\r\f\v]와 의미 동일 |
| \S | 공백을 제외한 문자를 의미. [^ \t\n\r\f\v]와 의미 동일 |
| \w | 문자 또는 숫자를 의미. [a-zA-Z0-9]와 의미 동일 |
| \W | 문자 또는 숫자가 아닌 문자를 의미. [^ a-zA-Z0-9]와 의미 동일 |
라. 정규표현식 모듈 함수
| 모듈 함수 | 설 명 |
|---|---|
| re.compile() | 정규표현식을 컴파일하는 함수. 즉, python에게 전해주는 역할을 함. 찾고자 하는 패턴이 빈번할 경우, 미리 컴파일해놓고 사용하면 속도와 편의성 측면에서 유리 |
| re.search() | 문자열 전체에 대해 정규표현식과 매치되는지 검색 |
| re.match() | 문자열의 처음이 정규표현식과 매치되는지 검색 |
| re.split() | 정규표현식을 기준으로 문자열을 분리하여 리스트로 리턴 |
| re.findall() | 문자열에서 정규표현식과 매치되는 모든 경우의 문자열을 찾아서 리스트로 리턴. 만약 매치되는 문자열이 없으면 빈 리스트가 리턴 |
| re.finditer() | 문자열에서 정규표현식과 매치되는 모든 경우의 문자열에 대한 iterator 객체 리턴 |
| re.sub() | 문자열에서 정규표현식과 일치하는 부분에 대해서 다른 문자열로 대체 |
컴파일 옵션
- DOTALL(S): .이 줄바꿈 문자를 포함하여 모든 문자와 매치할 수 있도록 함
- IGNORECASE(I): 대소문자에 관계없이 매치할 수 있도록 함
- MULTILINE(M): 여러 줄과 매치할 수 있도록 함(^, $ 메타문자의 사용과 관련 有)
- VERBOSE(X): verbose 모드를 사용할 수 있도록 함(정규식을 보기 편하게 만들 수 있고, 주석 등을 사용할 수 있게 됨)
마. 정규표현식을 이용한 토큰화
<python 코드>
from nltk.tokenize import RegexpTokenizer
text = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop"
tokenizer1 = RegexpTokenizer("[\w]+")
tokenizer2 = RegexpTokenizer("\s+", gaps=True)
print(tokenizer1.tokenize(text))
print(tokenizer2.tokenize(text))<출력 결과>
['Don', 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'Mr', 'Jone', 's', 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']["Don't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name,', 'Mr.', "Jone's", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
※ tokenizer2에서 만약 gaps=True라는 부분을 미 기재하면 토큰화의 결과로 공백만 나옴
바. 텍스트 전처리에서 정규표현식 사용 예시
예) 길이가 짧은 단어 삭제
<python 코드>
import re
text = "I was wondering if anyone out there could enlighten me on this car."
# 길이가 1~2인 단어들을 정규 표현식을 이용하여 삭제
shortword = re.compile(r'\W*\b\w{1,2}\b')
print(shortword.sub('', text))<출력 결과>
was wondering anyone out there could enlighten this car.
4. 정수 인코딩(Integer Encoding)
가. Integer Encoding?
NLP에서 텍스트를 숫자로 바꾸는 여러 가지 방법 중 하나로 각 단어를 고유한 정수에 mapping시키는 전처리 작업이다.
나. Dictionary 이용
① 문장 토큰화
from nltk.tokenize import sent_tokenize② 단어 토큰화
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords③ 각 단어에 대한 빈도수 계산
Dictionary을 이용하여 표현 → {단어 : 빈도수}
④ 빈도수가 높은 순서대로 정렬
빈도수 상위 n개의 단어만 채택
⑤ 정수 인코딩
- 정렬된 빈도수에 따라 정수 인덱스 부여(1부터 시작)
예시) word_to_index = {'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5}
- 마지막 인덱스로 OOV(Out-Of-Vocabulary) 할당
예시) word_to_index['OOV'] = len(word_to_index) + 1
다. Counter 이용
① 문장 토큰화
② 단어 토큰화
③ 각 단어에 대한 빈도수 계산
from collections import Counter예시)
vocab = Counter(all_words_list)Counter({'barber': 8, 'secret': 6, 'huge': 5, 'kept': 4, 'person': 3, 'word': 2, 'keeping': 2, 'good': 1, 'knew': 1, 'driving': 1, 'crazy': 1, 'went': 1, 'mountain': 1})
④ 빈도수가 높은 순서대로 정렬
- 빈도수 상위 n개의 단어만 채택
vocab_size = 5
vocab = vocab.most_common(vocab_size)⑤ 정수 인코딩
라. Tensorflow / Keras
① 문장 토큰화
② 단어 토큰화
preprocessed_sentences = [['barber', 'person'], ['barber', 'good', 'person’], … ]
③ 각 단어에 대한 빈도수 계산
④ 빈도수가 높은 순서대로 정렬
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
# fit_on_texts() 안에 코퍼스를 입력으로 하면 빈도수를 기준으로 단어 집합 생성
tokenizer.fit_on_texts(preprocessed_sentences)
print(tokenizer.word_index)
print(tokenizer.word_counts){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7, 'good': 8, 'knew': 9, 'driving': 10, 'crazy': 11, 'went': 12, 'mountain': 13}
OrderedDict([('barber', 8), ('person', 3), ('good', 1), ('huge', 5), … ])
⑤ 정수 인코딩
print(tokenizer.texts_to_sequences(preprocessed_sentences))[[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], … ]
마. Tensorflow / Keras - 상위 n개, OOV 토큰
① 문장 토큰화
② 단어 토큰화
preprocessed_sentences = [['barber', 'person'], ['barber', 'good', 'person’], … ]
③ 각 단어에 대한 빈도수 계산
④ 빈도수가 높은 순서대로 정렬 - 상위 n개, oov_token
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words = vocab_size + 2, oov_token = 'OOV')
# 'num_words = vocab_size + 2'는 Padding과 OOV을 포함
tokenizer.fit_on_texts(preprocessed_sentences)
print('단어 OOV의 인덱스: {}'.format(tokenizer.word_index['OOV']))단어 OOV의 인덱스: 1
(#0: Padding, 1: OOV, 2~n+1: 상위 n개 단어)
⑤ 정수 인코딩
print(tokenizer.texts_to_sequences(preprocessed_sentences))[[2, 6], [2, 1, 6], [2, 4, 6], [1, 3], [3, 5, 4, 3], [4, 3], [2, 5, 1], … ]
5. 패딩(Padding)
가. Padding?
병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업
나. Using Numpy
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(preprocessed_sentences)
encoded = tokenizer.texts_to_sequences(preprocessed_sentences)
max_len = max(len(item) for item in encoded)
for sentence in encoded:
while len(sentence) < max_len:
sentence.append(0)
padded_np = np.array(encoded)
padded_np
다. Using Tensorflow/Keras
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(preprocessed_sentences)
encoded = tokenizer.texts_to_sequences(preprocessed_sentences)
from tensorflow.keras.preprocessing.sequence import pad_sequences
padded = pad_sequences(encoded)
padded
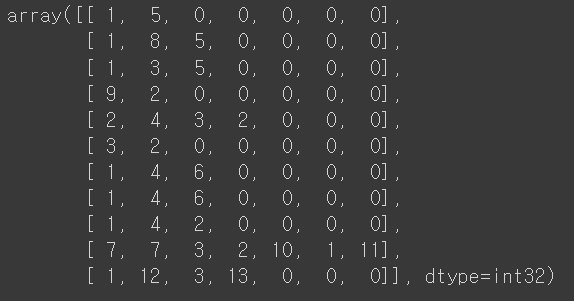
padded = pad_sequences(encoded, padding='post')
padded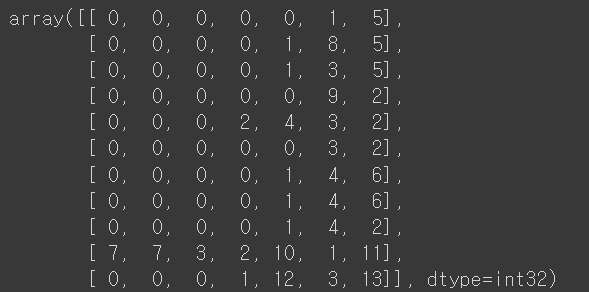
6. One-Hot Encoding
가. One-Hot Encoding?
단어 집합의 크기를 벡터의 차원으로 하고, 표현하고자 하는 단어의 인덱스에 1의 값을 부여하며, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식(One-Hot vector)
나. Raw Coding
① 정수 인코딩
word_to_index = {word: index for index, word in enumerate(tokens)}
print('단어 집합:', word_to_index)단어 집합: {'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5}
② One-hot encoding
def one_hot_encoding(word, word_to_index):
one_hot_vector = [0]*(len(word_to_index))
index = word_to_index[word]
one_hot_vector[index] = 1
return one_hot_vector
one_hot_encoding("자연어", word_to_index)[0, 0, 1, 0, 0, 0]
다. Using Tensorflow/Keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
# 1. 정수 인코딩
text = "나랑 점심 먹으러 갈래 점심 메뉴는 햄버거 갈래 햄버거 최고야"
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text]) # text가 []로 감싸 있음에 유의
print('단어 집합 :', tokenizer.word_index)
# 2. one-hot encoding
sub_text = "점심 먹으러 갈래 메뉴는 햄버거 최고야"
encoded = tokenizer.texts_to_sequences([sub_text])[0]
print(encoded)
one_hot = to_categorical(encoded)
print(one_hot)
라. One-hot Encoding의 한계
① 단어 집합의 크기가 곧 벡터 차원의 수
- 단어가 1,000 개인 corpus을 가지고 one-hot vector을 만들면 모든 단어 각각은 모두 1,000 개의 차원을 가진 vector가 된다.
- 모든 단어 각각은 하나의 값만 1을 가지고, 나머지 999 개의 값은 0을 가지는 벡터이다.
- 저장 공간 측면에서 매우 비효율적인 방법이다.
② 단어의 유사도를 표현하지 못함
- 대안으로 워드 임베딩이 제안된다. 워드 임베딩은 단어를 저차원 벡터로 변환하면서, 단어의 의미적 유사성을 반영한다.
7. 데이터 분리(Splitting Data)
<예 시>: 다음에 대해 X와 y로 분리해보자.
<훈련 데이터>
- X_train: 문제지 데이터
- y_train: 문제지에 대한 정답 데이터
<테스트 데이터>
- X_test: 시험지 데이터
- y_test: 시험지에 대한 정답 데이터
가. zip 함수로 분리
X, y = zip(['a', 1], ['b', 2], ['c', 3])
print('X 데이터 :', X)
print('y 데이터 :', y)
sequences = [['a', 1], ['b', 2], ['c', 3]]
X, y = zip(*sequences)
print('X 데이터 :', X)
print('y 데이터 :', y)
※ sequences 앞에 붙은 *은 무엇인가?
sequences 는 리스트 안에 3 개의 리스트가 들어있는 하나의 리스트이다. zip 함수는 개별적인 리스트를 각각의 인자로 받아야 하기 때문에, *을 사용해서 리스트를 unpacking한다. 이는 리스트의 각 원소를 개별 인자로 변환하는 역할을 한다.
따라서 *sequences 은 ['a', 1], ['b', 2], ['c', 3] 을 각각의 인자로 zip 함수로 전달하게 된다.
나. Dataframe으로 분리

import pandas as pd
values = [['당신에게 드리는 마지막 혜택!', 1], ['내일 뵐 수 있을지 확인 부탁드...', 0], ['도연씨. 잘 지내시죠? 오랜만입...', 0], ['(광고) AI로 주가를 예측할 수 있다!', 1]]
columns = ['메일 본문', '스팸 메일 유무’]
df = pd.DataFrame(values, columns=columns)
X = df['메일 본문']
y = df['스팸 메일 유무’]
print('X 데이터 :',X.to_list())
print('y 데이터 :', y.to_list())
다. Numpy로 분리
import numpy as np
np_array = np.arange(0, 16).reshape((4, 4))
print('전체 데이터 :')
print(np_array)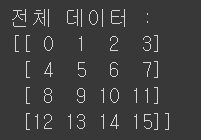
X = np_array[:, :3]
y = np_array[:,3]
print('X 데이터 :')
print(X)
print('y 데이터 :', y)
라. 사이킷 런으로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1234)
print('X 훈련 데이터 :')
print(X_train)
print('X 테스트 데이터 :')
print(X_test)
print('y 훈련 데이터 :')
print(y_train)
print('y 테스트 데이터 :')
print(y_test)
<참고 문헌>
유원준/안상준, 딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21694
박호현 교수님, 인공지능, 중앙대학교 전자전기공학부, 2024
