1.1 Introduction
1.1.1 고성능 컴퓨팅(HPC, High-Performance Computing)
- 일반적으로 복잡한 작업을 높은 처리량과 효율로 처리하기 위해 여러 프로세서나 컴퓨터를 사용하는 것
- 컴퓨터 구조뿐만 아니라 HW 시스템, SW 툴, 프로그래밍 플랫폼, 병렬 프로그래밍 패러다임(parallel programming paradigm)을 포함하는 요소의 집합으로도 여겨짐
- 신기술 등이 보편화되면서 HPC 환경은 항상 바뀌고 있고, 그에 따라 그 정의도 항상 변화
- GPU-CPU heterogeneous 구조의 등장으로 HPC가 비약적으로 발전, 이는 병렬 프로그래밍의 패러다임 전환으로 이어짐
1.2 Parallel Computing
1.2.1 parallel computing의 목적
- 계산 속도 향상
1.2.2 parallel computing의 정의
1. pure calculation perspective
- large problem을 소분화하고, 그것들을 동시에 해결하는 방식으로 많은 계산을 동시에 수행한다.
2. programmer's perspective
- 여러 computing resources가 있을 때, 병렬 컴퓨팅은 그것들(cores 또는 computers)을 동시에 사용하여 계산을 동시에 수행
- large problem이 소분화되고, 그것들을 각 computing resources가 동시에 해결하는 것이다.
3. HW/SW이 연관된 채로 구성
- computer architecture(하드웨어 측면)
: parallelism 지원에 중점 - parallel programming(소프트웨어 측면)
: computer architecture의 완전한 활용으로 smaller problems을 동시에 해결하는 것에 중점 - intertwining
SW가 parallelism을 이루어내기 위해서는, HW가 여러 프로세스 또는 스레드의 동시 실행을 지원하는 플랫폼을 제공해야 한다.
1.2.3 Harvard Architecture
대부분의 현대 프로세서는 Harvard Architecture 을 기반으로 하며, 이 구조는 다음 세 가지 요소로 구성된다.
1. Memory(instruction memory and data memory)
2. Central processing unit(control unit and arithmetic logic unit)
3. Input/Output interfaces
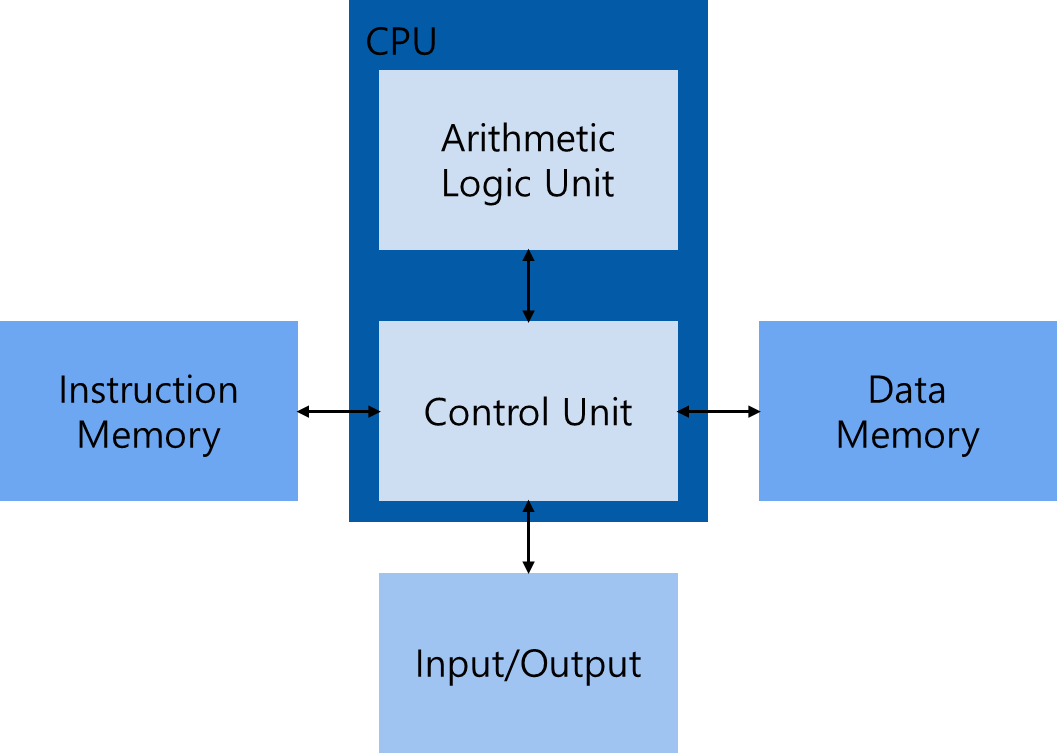
1. CPU
- HPC의 핵심요소이며, 보통 코어(core)라고 불림
- 초창기 컴퓨터에는, 칩에 단 하나의 코어만 존재했으며, 이를 uniprocessor라 함
- 오늘날에는, 다수의 코어를 하나의 프로세서로 통합하여 multi-core로 변화하여, architecture 수준에서 parallelism을 지원
- 프로그래밍은 어떤 작업을 가용 코어에 대응시켜 parallelism을 구현하도록 하는 과정
2. for algorithm
- 순차 알고리즘(sequential algorithm) 구현 시, computer architecture의 세부 사항을 몰라도 알맞은 프로그램 설계 가능
- multi-core machine을 위한 알고리즘 구현 시, computer architecture의 세부 사항을 아는 것이 필수적. 그래야 효율적인 parallel programming 설계 가능
1.3 Sequential and Parallel Programming
1.3.1 Sequential & Parallel Programming의 정의
컴퓨터 프로그램으로 어떤 작업을 할 때, 그것을 여러 개의 작업으로 소분화하면 용이하다. 다음 그림과 같은 방식으로 특정 작업을 수행할 때, 다음 방식의 프로그램을 순차 프로그램(sequential program)이라 한다.
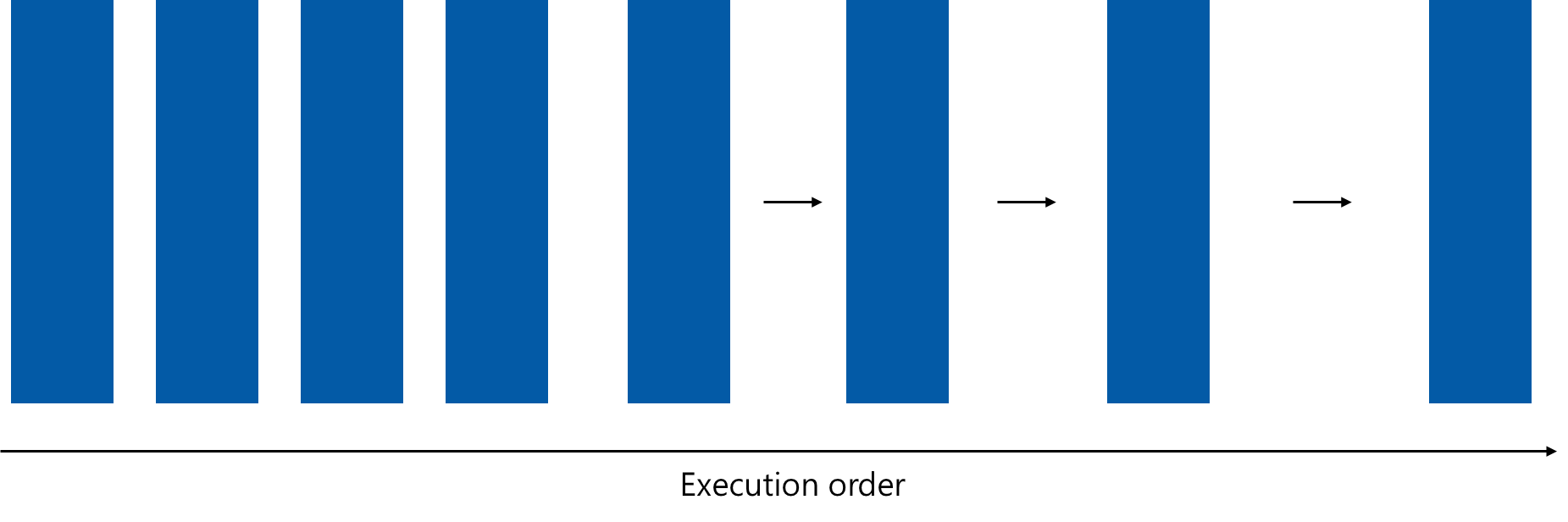
어떤 작업 A에 대해, a, b, c, ...와 같이 여러 개로 소분화했다고 할 때, a 작업과 b 작업 간 관계를 분류하는 방법에는 두 가지가 있다.
1. 작업 간 우선순위가 존재하여 순차적으로 계산이 필요한 경우
2. 그러한 제한이 존재하지 않아 동시에 계산이 가능한 경우
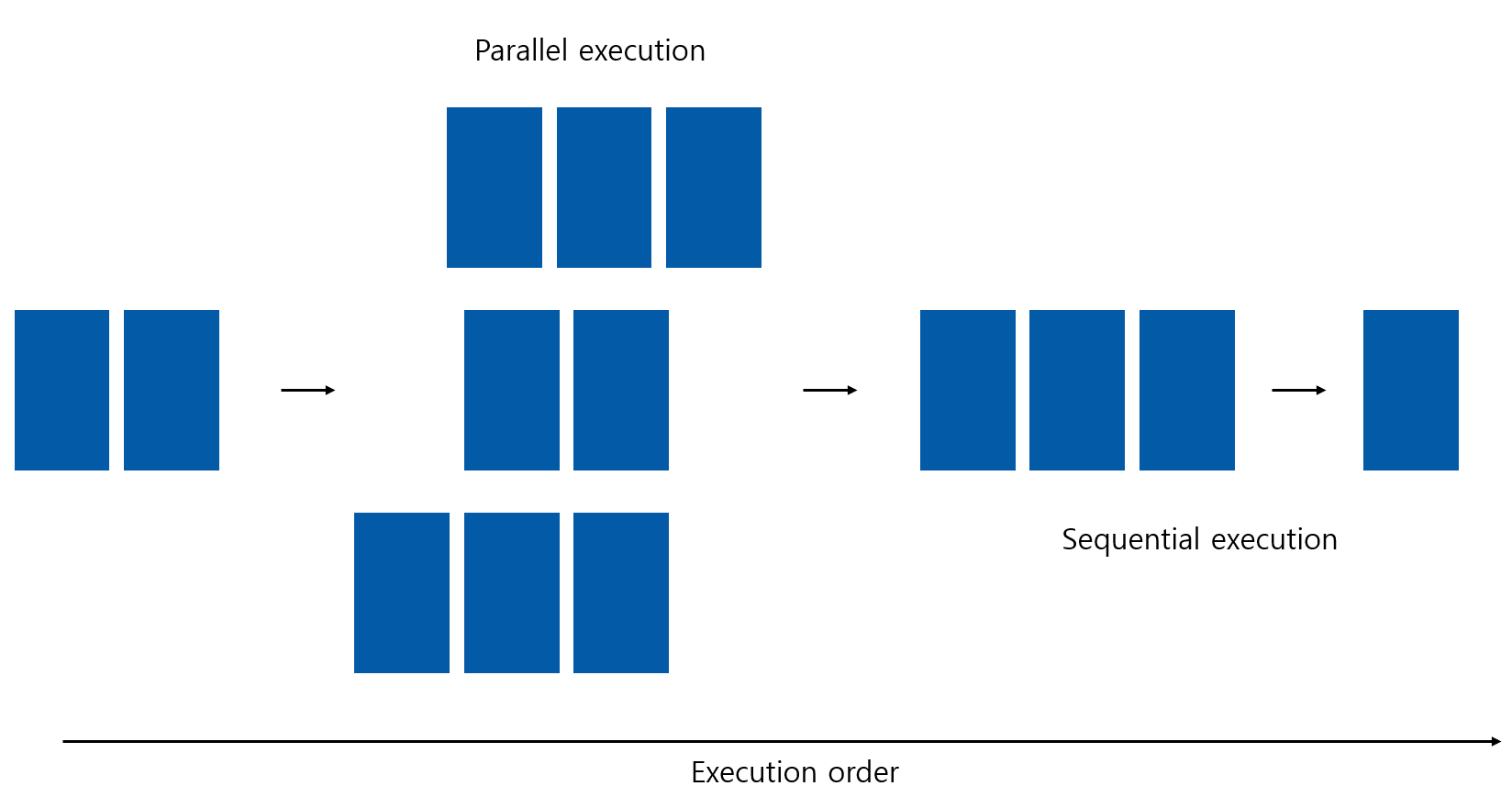
동시에 수행되는 작업을 포함하는 어떠한 프로그램이든 parallel program으로 불린다. 다음 그림처럼 parallel program에는 순차적인 부분이 포함될 수도 있다.
1.3.2 programmer's perspective
- 프로그램 = instruction + data
- large program을 여러 개로 소분화 했을 때, 각각을 작업(task)라 함.
- task에서 instruction이 input을 받아들이고, 이에 function을 적용하고, output 생성
- data dependency: 어떤 instruction이 선행 instruction이 생성한 data을 input으로 받을 때 발생. parallelism의 주요 방해 요소 중 하나이므로, 이를 분석하는 것은 애플리케이션 속도를 높이기 위해 필수적. 대부분, dependent tasks의 independent chain은 parallelism을 용이하게 함.
→ dependent : 어떤 task가 선행 task의 output을 input으로 받을 때
→ independent :그렇지 않을 때
1.4 Parallelism
1.4.1 parallelism 유형
1. Task Parallelism
- independent 그리고 주로 parallel하게 수행될 수 있는 많은 tasks 또는 functions이 있을 때 발생
- 여러 cores에 tasks 또는 functions을 분산하는 데 중점
2. Data Parallelism
- 동시에 수행될 수 있는 데이터 항목이 많을 때 발생
- 여러 cores에 data을 분산하는 데 중점
1.4.2 Why CUDA Programming?
- CUDA 프로그래밍은 data-parallel computation으로 표현할 수 있는 작업을 수행하는데 특화
- 큰 data sets을 처리하는 많은 애플리케이션이 data-parallel model로 연산 속도 향상 가능
- data-parallel 처리 방식은 data 요소를 parallel 스레드에 mapping
data-parallel program을 설계하는 첫 번째 순서는 스레드에 data을 분할하여, 각 스레드가 데이터의 일부분을 처리하도록 하는 것이다. 일반적으로 분할 방식에는 block partitioning과 cyclic partitioning이 있다.
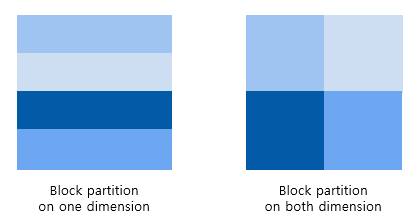
1. block partitioning
- 많은 연속적인 데이터 요소가 함께 묶임
- 각 묶음(chunk)은 임의의 순서로 single thread에 할당되며, threads는 일반적으로 한 번에 한 개의 chunk만을 처리
- 1D data partitioning: 각 thread는 one data block을 취함

- 2D data partitioning: 좌측부터 y dimension을 따른 partitioning, x, y dimension을 따른 partitioning
2. cyclic partitioning
- 더 적은 수의 데이터 요소가 함께 묶임
- 인접한 threads는 인접한 chunks을 받고, 각 thread는 한 개 이상의 chunk 처리 가능
- thread가 처리할 어떤 chunk을 선택하는 것은, thread 수만큼의 chunks을 건너뛴다는 것까지 의미
- 1D data partitioning: 각 thread는 two data blocks을 취함.

- 2D data partitioning: x dimension을 따른 partitioning

3. 정리
보통, data는 1차원적으로 저장된다. 심지어 논리적으로 다차원 데이터 뷰를 사용할 때조차, 물리적으로는 1차원 저장소에 mapping된다. data를 threads 간에 분배하는 방법을 결정짓는 것은, 그 data가 물리적으로 어떻게 저장되는지와 각 thread의 실행 순서와 밀접한 관련이 있다. 이에 따라 threads를 조직하는 방식은 프로그램 성능에 중요한 영향을 미친다.
1.5 Computer Architecture
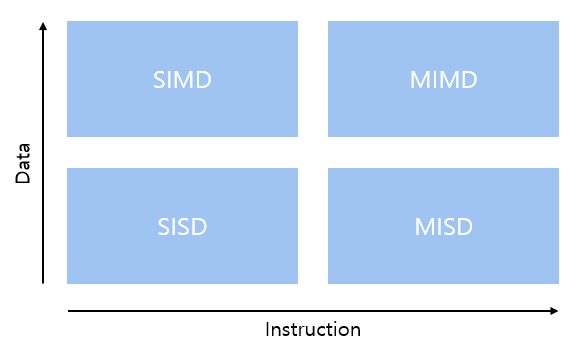
1.5.1 Flynn's Taxonomy
- Single Instruction Single Data(SISD)
- Single Instruction Multiple Data(SIMD)
- Multiple Instruction Single Data(MISD)
- Multiple Instruction Multiple Data(MIMD)
1. Single Instruction Single Data(SISD)
- 전통적인 컴퓨터 방식으로, 직렬 아키텍쳐
- core 유일
- 언제나 유일한 instruction stream만 실행되며, 한 data stream에서 operations이 수행됨
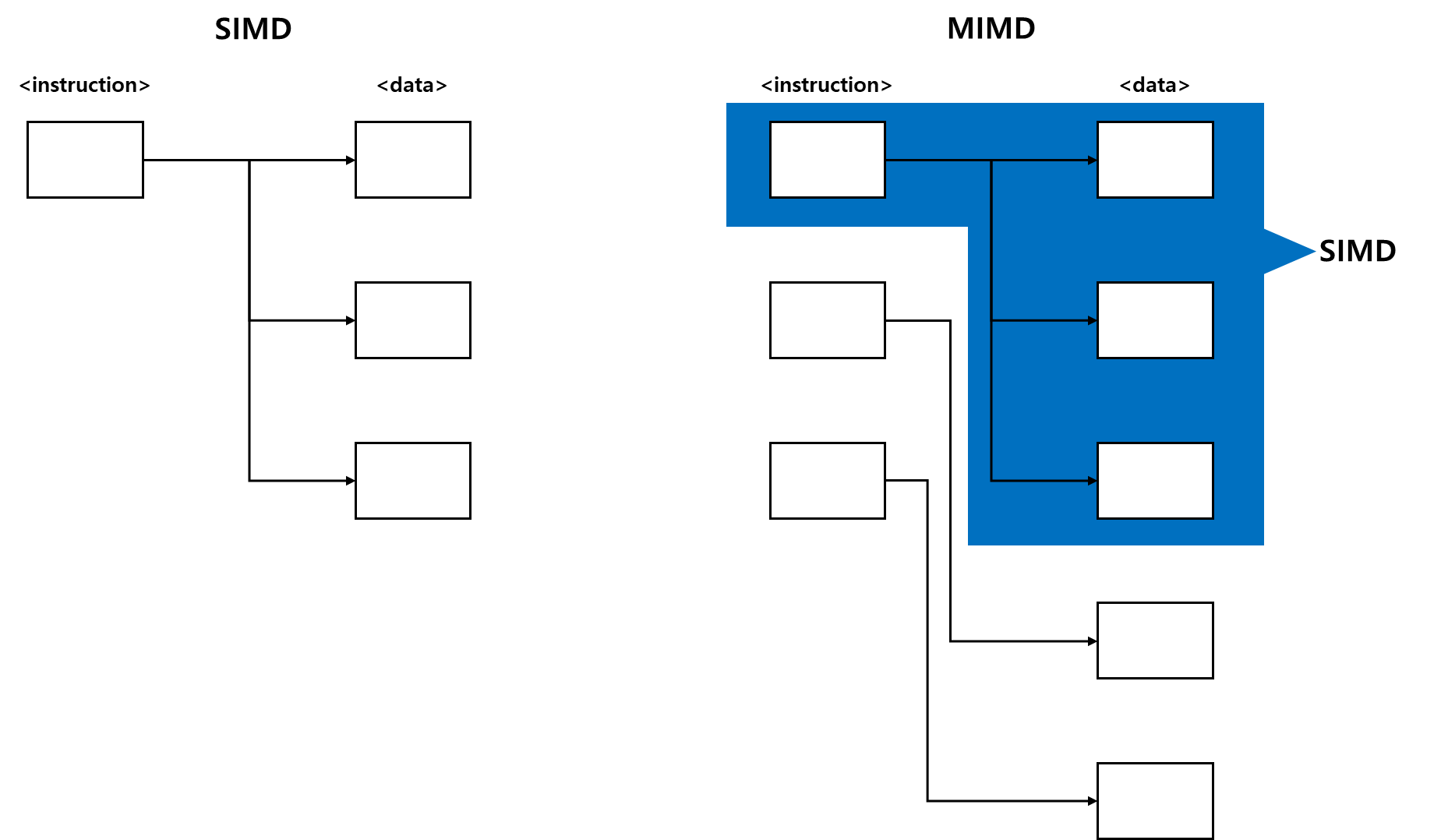
2. Single Instruction Multiple Data(SIMD)
- 병렬 아키텍처
- 여러 cores가 있으며, 모든 cores는 언제든지 동일한 instruction stream을 실행하며, 각각의 operating은 서로 다른 data streams에서 수행
- 벡터 컴퓨터는 일반적으로 SIMD로 특징지어지며, 대부분의 현대 컴퓨터는 SIMD 아키텍처를 사용
- CPU에서 코드를 작성할 때 프로그래머가 순차적으로 생각하면서도 병렬 데이터 연산으로 병렬 속도를 높일 수 있는데, 이는 컴파일러가 세부 사항을 처리하기 때문임.
※ 벡터 컴퓨터(vector computer)란?
- 벡터 처리(Vector Processing)라고 불리는 특정 유형의 컴퓨팅 방식을 사용하는 컴퓨터
- 벡터 처리: 한 번에 여러 데이터를 동시에 처리하는 방식으로, 특히 대규모 데이터 연산에 효율적
- 주로 과학 계산, 그래픽 처리, 신호 처리 등에서 사용
3. Multiple Instruction Single Data(MISD)
- 병렬 아키텍처
- 일반적이지 않음
- 각 core가 서로 다른 instruction stream을 통해 동일한 data stream에서 작업 수행
4. Multiple Instruction Multiple Data(MIMD)
- 병렬 아키텍처
- 여러 cores가 independent instructions을 수행하면서, 여러 data streams에서 작업 수행
- MIMD architecture에 SIMD가 하위 구성 요소로도 포함된다
5. 목표: latency 감소, bandwidth 증가, throughput 증가
지연 시간(latency)
- operation이 시작되고 완료되는 데 걸리는 시간
- 일반적으로 마이크로초 단위로 표현
대역폭(bandwidth)
- 단위 시간당 처리할 수 있는 data의 양
- 일반적으로 메가바이트/초 또는 기가바이트/초 단위로 표현
처리량(throughput)
- 단위 시간당 처리할 수 있는 operation의 양(주어진 시간 단위 내 처리도니 operation 수)
- 일반적으로 gflops(초당 10억 개의 부동 소수점 연산) 단위로 표현
- 특히 과학 계산 분야에서 부동 소수점 계산을 많이 사용하는 경우 유용.
1.5.2. 메모리 구성에 따른 세분화
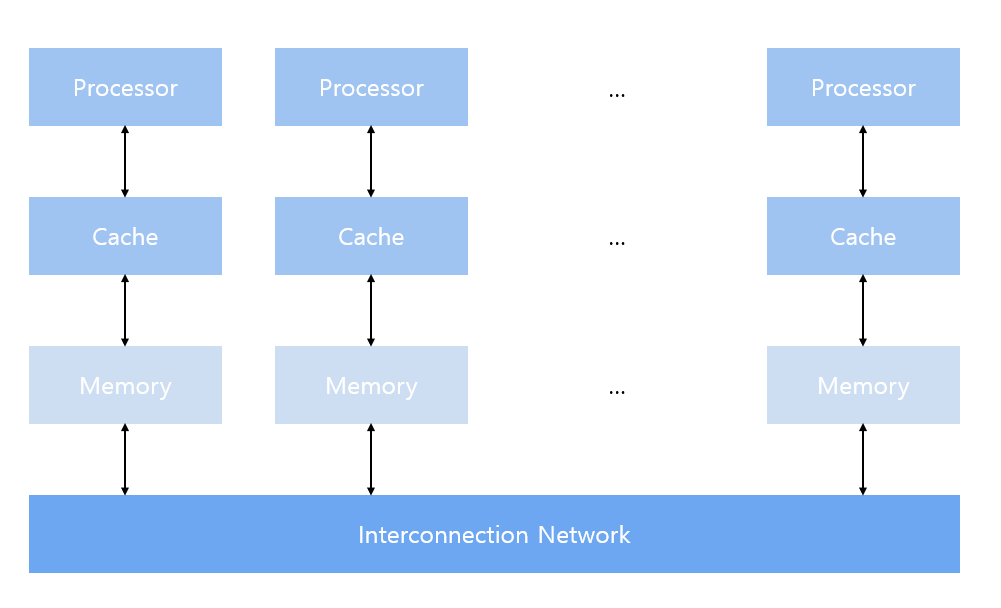
multi-node with distributed memory
- multi-node system에서는 네트워크로 연결된 많은 프로세서로 대규모 연산 엔진 구성
- 각 processor는 자체 local memory를 가짐
- processors는 네트워크를 통해 local memory의 contents을 주고 받을 수 있음
- 예시: Cluster
multiprocessor with shared memory
- multiprocessor architecture는 일반적으로 dual-processor에서 수십 또는 수백 개의 processors에 이르기까지 다양한 크기를 가지는데, 이러한 processors는 물리적으로 연결되어 있거나, PCI-Express(or PCIe)와 같은 low-latency link 공유 가능
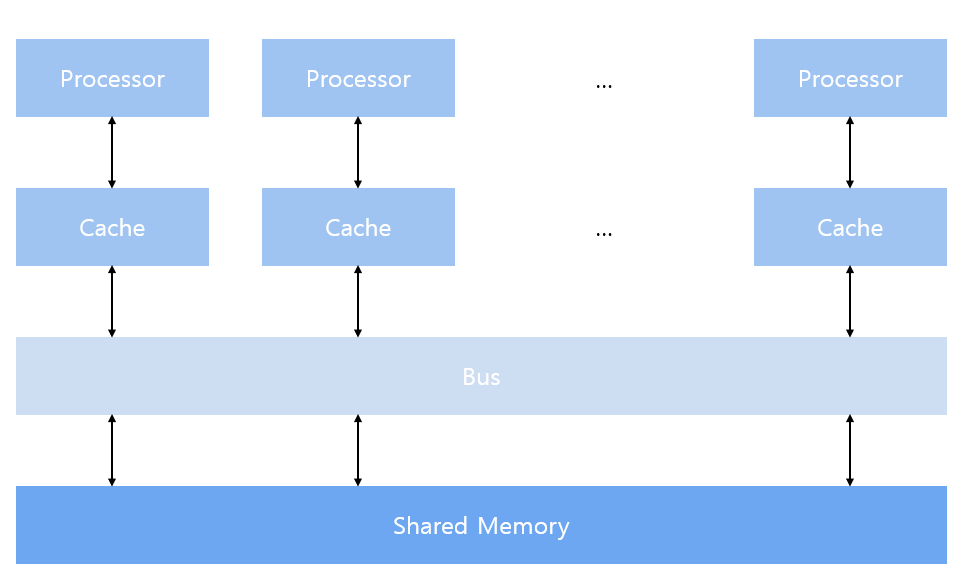
- 메모리 공유는 공유된 주소 공간을 의미하지만, 반드시 단일 물리적 메모리의 존재를 의미하지는 않음
- multicore로 알려진, 여러 cores로 구성된 single-chip 시스템과 multicore design을 가지는 여러 chips으로 구성된 컴퓨터를 포함
- multicore architectures는 single-core architectures을 영구적으로 대체
many-core
- many-core: 특히 많은 수의 cores(수십 개 또는 수백 개)을 가진 multicore architecture
- 최근 compter architecture가 multi-core에서 many-core로 바뀌어 가고 있음
- GPU: many-core architecture임, multithreading, MIMD, SIMD 및 instruction-level parallelism 등 거의 모든 유형의 병렬성을 가짐
→ NVIDIA는 이러한 유형의 architecture을 위해 Single Instruction, Multiple Thread(SIMT)라는 용어를 만듦
1.5.3 GPU core VS. CPU core
- GPU와 CPU는 그 원천이 다름
GPU
- GPU는 본래 그래픽 가속기였으며, 최근에서야 강력하고 범용적이고, 완전히 프로그래밍 가능하며, 대규모 병렬 컴퓨팅 문제를 해결하는데 이상적으로 적합한 task 및 data parallel processors로 발전
- light-weight
- 단순한 control logic으로 data-parallel tasks에 최적화
- parallel programs의 throughput에 중점
CPU
- heavy-weight
- 매우 복잡한 control logic 처리
- sequential programs 실행을 최적화하는데 중점
1.6 Heterogeneous Computing
초기 컴퓨터는 일반적인 프로그래밍 작업을 실행하도록 설계된 CPU만을 포함하고 있었다. 지난 10년 간, 고성능 컴퓨팅 분야의 주류 컴퓨터는 다른 처리 요소를 포함하도록 전환되어 왔다. 그 중 가장 널리 사용된 것은 본래 병렬로 특화된 그래픽 연산을 수행하도록 설계된 GPU이다. 시간이 지나면서, GPU는 더욱 강력하고 일반화되어, 뛰어난 성능과 높은 전력 효율성을 바탕으로 범용 parallel computing tasks에 적용될 수 있게 되었다.
일반적으로 CPU와 GPU는 단일 컴퓨팅 노드 내에서 PCI-Express bus로 연결된 개별 처리 구성 요소이다. 이러한 유형의 아키텍처에서는 GPU를 개별 장치(discrete devices)라고 한다.
homogeneous system에서 heterogeneous systems으로의 전환은 HPC 역사에서 중요한 이정표이다. homogeneous computing은 동일한 architecture의 processor를 하나 이상 사용하여 application을 실행합니다.
반면, heterogeneous computing은 여러 architecture의 processors을 사용하여 application을 실행하며, tasks을 알맞은 architecture에 할당하여 성능 향상을 도모한다.
heterogeneous systems은 전통적인 HPC 시스템에 비해 상당한 이점을 제공하지만, 이러한 시스템을 효과적으로 사용하는 것은 application 설계의 복잡성의 증가로 현재 제한되고 있다. parallel programming은 최근 많은 주목을 받고 있지만, heterogenous resourses의 포함은 복잡성을 더하고 있다.
1.7 Heterogeneous Architecture
오늘날의 전형적인 heterogenous compute node는 두 개의 multicore CPU socket과 두 개 이상의 many-core GPU로 구성된다. 현재 GPU는 독립적인 플랫폼이 아니라 CPU의 보조 프로세서로 작동한다. 따라서 GPU는 그림 1-9에서 보여지는 것처럼 PCI-Express bus를 통해 CPU 기반의 호스트와 함께 작동해야 합니다. 그렇기 때문에 GPU 컴퓨팅 용어에서 CPU를 host, GPU를 device라고 한다.
1.7.1 heterogeneous application
Host code
- CPU에서 실행
Device code
- GPU에서 실행
heterogeneous platform에서 실행되는 application은 일반적으로 CPU가 초기화한다. CPU는 연산 집약적인 tasks을 로드하기 전에, 환경, 코드, 그리고 데이터를 관리한다.
연산 집약적인 application에서 program section은 종종 많은 data parallelism을 나타내는데, 이 parallelism 실행을 GPU가 가속화한다. 이렇게 가속화하기 위해 CPU와 물리적으로 분리된 HW 구성 요소를 hardware accelerator라고 하는데, GPU가 그 예이다.
1.7.2 NVIDIA GPU computing platform 적용 사례
Tegra
- 모바일 및 임베디드 장치를 위해 설계
- Tegra K1:
① Kepler GPU을 포함하여 임베디드 application을 위한 GPU의 성능을 활용할 수 있는 모든 것을 제공
② Kepler: 2012년 가을에 Fermi 이후 출시된 현 세대의 GPU computing architecture. 이전 세대의 GPU보다 높은 처리 능력을 제공하며, GPU에서 병렬 workload 실행을 최적화하고 증가시키기 위한 새로운 방법 제공
GeForce
- 그래픽
Quadro
- 전문 시각화
Tesla
- 데이터 센터 병렬 컴퓨팅
- Fermi GPU accelerator:
① NVIDIA가 2010년에 출시한 세계 최초의 완전한 GPU computing architecture
② seismic processing, biochemistry simulation, weather and climate modeling, signal processing, computational finance, computer-aided engineering, computational fluid dynamics, data analysis
1.7.3 GPU capability & performance
GPU의 capability을 설명하는 두 가지 특징
- CUDA 코어 수
- 메모리 크기
GPU의 performance을 설명하는 두 가지 척도
-
peak computational performance:
① 초당 얼마나 많은 single-precision 또는 double-precision 부동 소수점 계산을 처리할 수 있는지를 정의
② gflops(초당 10억 부동 소수점 연산) 또는 tflops(초당 1조 부동 소수점 연산) 단위로 표현 -
memory bandwidth
① 데이터를 메모리에 읽고 쓰는 속도의 비율 측정
② [GB/s] 단위로 표현
피크 계산 성능은 보통 초당 얼마나 많은 단정밀도 또는 배정밀도 부동 소수점 계산을 처리할 수 있는지를 정의하며, 일반적으로 gflops(초당 10억 부동 소수점 연산) 또는 tflops(초당 1조 부동 소수점 연산) 단위로 표현됩니다. 메모리 대역폭은 데이터를 메모리에 읽고 쓰는 속도의 비율을 측정하며, 일반적으로 초당 기가바이트(GB/s) 단위로 표현됩니다.
※ single-precision(단정밀도)란?
- 비트 수: 32 bit
- 구성: 1 bit의 부호 bit, 8 bit의 지수(exponent) bit, 23 bit의 가수(mantissa) bit
- 표현 범위: 약
- 정확도: 소수점 이하 약 7 자리까지 정확
- 용도: 메모리 사용이 적고 연산 속도가 빠르므로, 그래픽 처리, 실시간 시뮬레이션 및 게임 등에서 주로 사용
※ double-precision(배정밀도)란?
- 비트 수: 64 bit
- 구성: 1 bit의 부호 bit, 11 bit의 지수 bit, 52 bit의 가수 bit
- 표현 범위: 약
- 정확도: 소수점 이하 약 15-17 자리까지 정확
- 용도: 더 높은 정확도와 넓은 범위가 필요할 때 사용되며, 과학 계산, 금융 계산, 공학 시뮬레이션 등에서 주로 사용
1.8 Paradigm of Heterogeneous Computing
GPU 컴퓨팅은 CPU 컴퓨팅을 대체하기 위한 것이 아니다. 각 접근 방식은 특정 종류의 프로그램에 대해 장점을 가지고 있으며, 두 방식이 상호 보환할 때 강력한 조합을 이룬다.
1.8.1 CPU computing
- control-intensive task에 적합
- 짧은 연산 작업과 예측 불가능한 제어 흐름이 특징인 dynamic workload에 최적화
- 복잡한 논리와 instruction-level parallelism을 처리할 수 있으므로, small data size, sophisticated control logic, and/or low-level parallelism의 problem에 적합
1.8.2 GPU computing
- data-parallel computation-intensive tasks에 적합
- 단순한 제어 흐름을 가진 계산 작업이 지배적인 workload에 최적화
- 많은 수의 프로그래밍 가능한 cores을 가지고 있어, 대규모 multi-threading을 지원하고, CPU에 비해 더 큰 peak bandwidth을 가지므로, huge amount of data and massive data parallelism의 problem에 적합
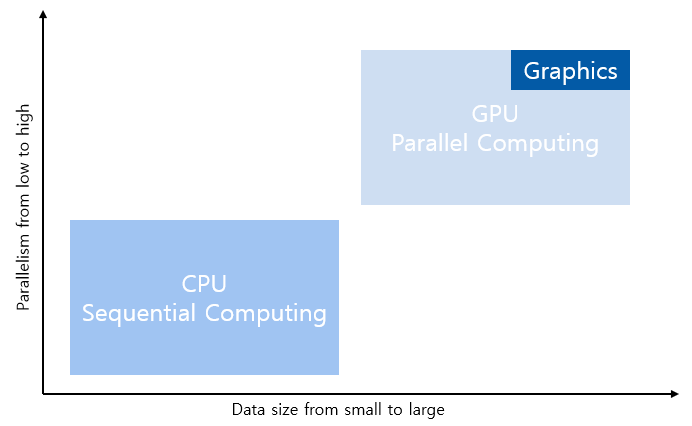
1.8.3 CPU + GPU heterogeneous parallel computing
- application의 sequential part 또는 task parallel parts은 CPU에서 실행
- application의 intensive data parallel parts은 GPU에서 실행
1.8.4 CPU thread vs. GPU thread
CPU thread
- heavy-weight
- OS는 multithread 기능을 제공하기 위해 CPU 실행 channel을 켜고 끄는 swap을 수행해야 한다. context switch는 느리고 비용이 많이 든다.
GPU thread
- light-weight
- 일반적인 시스템에서는 수천 개의 threads가 작업을 대기한다. 그런데 GPU는 한 그룹의 threads를 기다려야 한다면, 다른 작업을 단순히 실행하기 시작한다.
CPU core는 한 번에 하나 또는 두 개의 threads의 latency을 최소화하도록 설계되었지만, GPU core는 처리량을 극대화하기 위해 많은 수의 light-weight threads를 동시에 처리하도록 설계되었다.
오늘날 쿼드 코어 프로세서를 4개 가진 CPU는 최대 16개의 threads를 동시에 실행할 수 있는데, hyper-threading이 지원된다면, 최대 32개의 threads를 동시에 실행할 수 있다.
현대의 NVIDIA GPU는 multiprocessor 당 최대 1,536 개의 active threads를 동시에 지원할 수 있다. 16개의 멀티프로세서를 가진 GPU에서는 24,000개 이상의 actuve threads를 동시에 지원할 수 있다.
1.9 CUDA: A Platform for Heterogeneous Computing
1.9.1 CUDA Runtime API and CUDA Driver API
CUDA는 GPU 장치를 관리하고 threads를 구성하기 위해 두 가지 API levels로써 CUDA Runtime API와 CUDA Driver API을 제공한다.
CUDA Runtime API
- Driver API 위에 구현된 high-level API
- Runtime API의 각 기능은 Driver API에 전달되는 더 기본적인 작업으로 분해
CUDA Driver API
- low-level API
- 상대적으로 프로그래밍하기에는 어렵지만, GPU 장치의 사용을 보다 세밀하게 제어 가능
Runtime API Vs. Driver API
두 API의 성능 차이는 눈에 띄지 않는다. kernels이 메모리를 사용하는 방법과 장치에서 threads을 어떻게 구성하는지가 훨씬 더 영향력 있다.
한편, 두 API는 상호 배타적이다. 다시 말해, 둘 중 하나만 하나만 사용해야 하며, 두 API의 함수 호출을 혼합하는 것은 불가능하다.
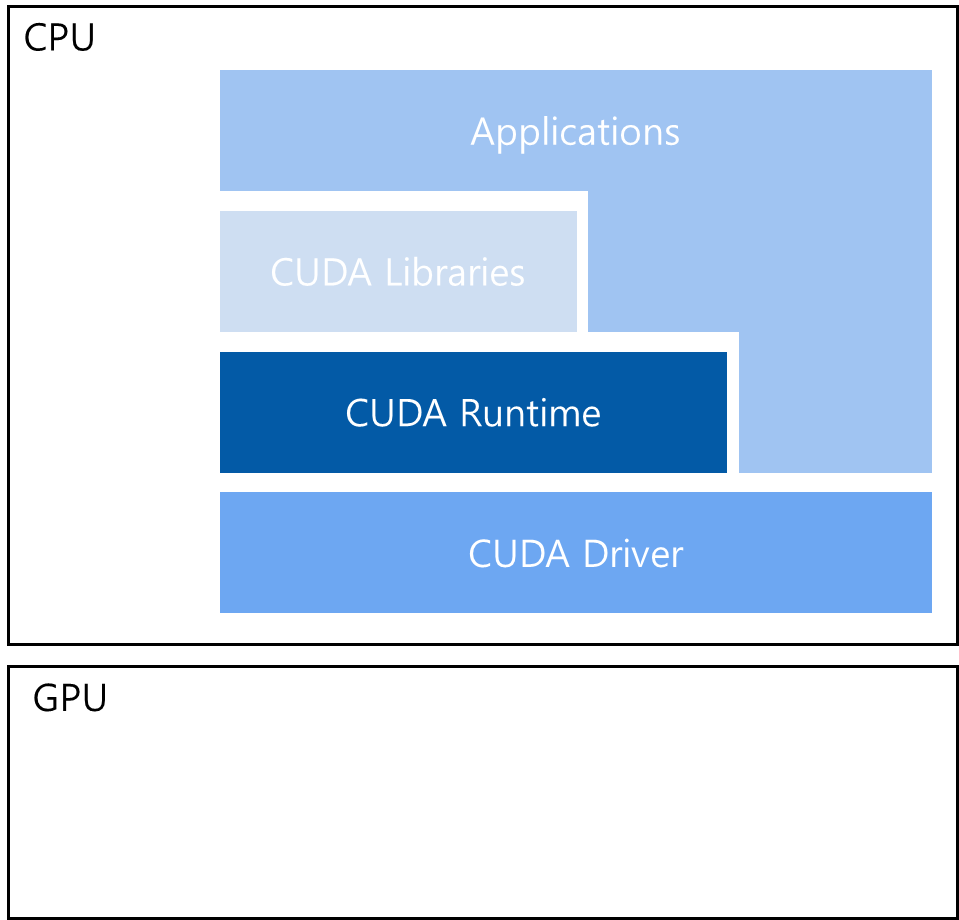
1.9.2 CUDA Program
CUDA Program은 다음 두 부분으로 구성된다:
- host code: CPU에서 실행
- device code: GPU에서 실행
NVIDIA의 CUDA nvcc 컴파일러는 컴파일 과정에서 device code을 host code와 분리한다. 다음 그림에서 보듯이, host code는 표준 C 코드이며 C 컴파일러로 컴파일된다. device code는 kernel이라 불리는 data-parallel functions에 label을 지정하기 위한 키워드가 추가된 CUDA C을 사용하여 작성된다. device code는 nvcc에 의해 추가로 컴파일된다. 링크 단계에서 kernel procedure 호출 및 명시적 GPU 장치 조작을 위해 CUDA runtime 라이브러리가 추가된다.
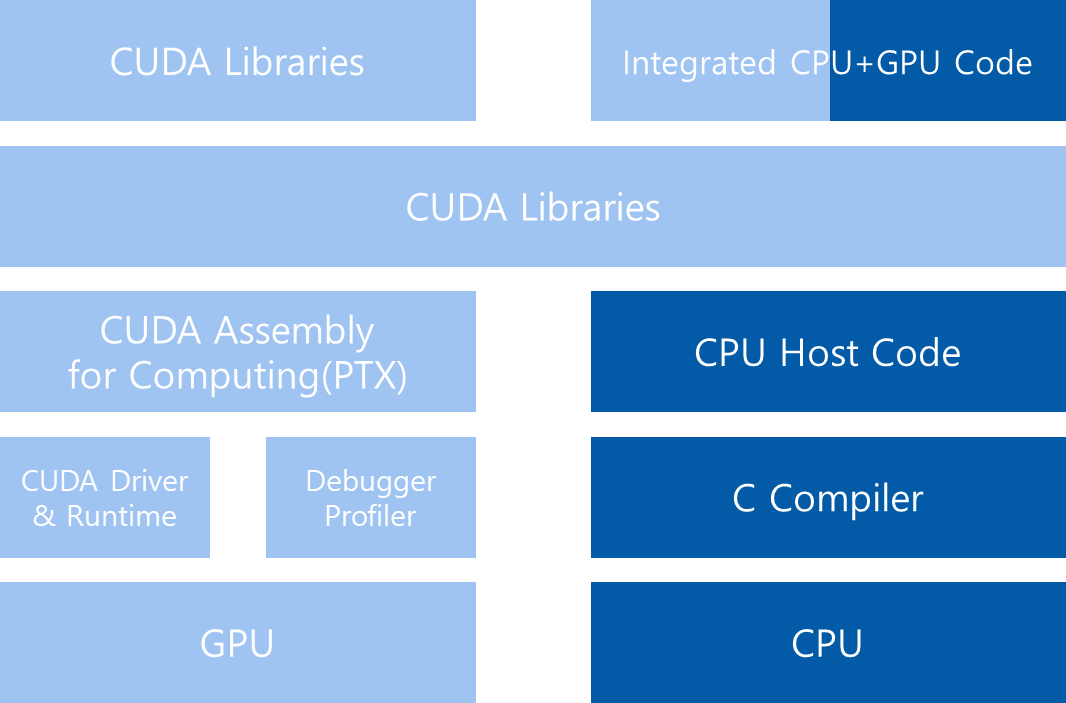
CUDA nvcc 컴파일러는 널리 사용되는 LLVM 오픈 소스 컴파일러 인프라를 기반으로 한다. CUDA 컴파일러 SDK로 GPU 가속을 지원하는 프로그래밍 언어를 만들거나 확장할 수 있습니다.
1.10 HELLO WORLD From GPU
1.10.1 예시 코드
#include "../common/common.h"
#include <stdio.h>
// kernel function
// qualifer __global__은 compiler에게
// 함수가 CPU에서 호출되고 GPU에서 실행됨을 전달
__global__ void helloFromGPU()
{
printf("Hello World from GPU!\n");
}
int main(int argc, char **argv)
{
printf("Hello World from CPU!\n");
// <<< >>> 내 parameters는 몇 개의 threads가 kernel을 실행할 지 나타냄
helloFromGPU<<<1, 10>>>(); // 10개의 threads
// cudaDeviceReset()는 현재 프로세스에서 현재 device와 연관된
// 모든 resources을 해제
CHECK(cudaDeviceReset());
return 0;
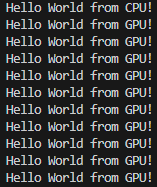
}1.10.2 실행 결과
1.11 Is CUDA C Programming Difficult?
1.11.1 locality
- 메모리 접근 latency을 줄이기 위해 data을 재사용하는 것
- reference locality은 두 가지 유형이 있음
① temporal locality: 상대적으로 짧은 시간 동안 data, resources, 또는 둘 다 재사용하는 것
② spatial locality: 상대적으로 가까운 저장소 위치 내에서 data 요소를 재사용하는 것
현대 CPU Architecture는 큰 caches을 사용하여 우수한 temporal locality와 spatial locality을 가진 application을 최적화한다.
1.11.2 hierarchy structure
CUDA는 memory hierarchy structure와 thread hierarchy structure라는 두 가지 개념을 사용하여 thread 실행 및 scheduling을 더 큰 규모로 제어할 수 있게 한다.
memory hierarchy structure
예를 들어, shared memory는 CUDA 프로그래밍 모델에서 등장하는 특수한 메모리이다. shared memory는 software-managed cache로 생각할 수 있으며, 메인 메모리 bandwidth을 절약하여 큰 속도 향상을 제공한다. 또한, shared memory를 사용하면 코드의 locality을 직접 제어할 수 있다.
thread hierarchy structure
ANSI C에서 parallel program을 작성할 때, pthread 또는 OpenMP와 같은 기술을 사용하여 명시적으로 thread을 구성해야 한다. 반면, CUDA C에서는 프로그램을 작성할 때, 실제로는 하나의 thread만이 호출할 수 있는 직렬 코드를 작성한다. GPU는 이 kernel을 가져와 수천 개의 thread를 실행하여 동일한 계산을 수행한다.
CUDA 프로그래밍 모델은 thread를 계층적으로 조직하는 방법을 제공한다. thread hierarchy structure을 조작하는 것은 GPU에서 thread가 실행되는 순서에 직접적인 영향을 미친다. 또한, CUDA C는 C에서 비롯되었기 때문에 C 프로그램을 CUDA C로 porting하는 것이 간단한다. 개념적으로 기존 C 코드에서 반복문을 사용하여 수행되는 작업을 CUDA C에서는 kernel 함수로 변환할 수 있고, 이를 통해 병렬 처리가 이루어진다.
<참고 문헌>
John Cheng, Max Grossman, Ty McKercher(2014). Professional CUDA C Programming. Indianapolis, Indiana, USA: Wrox (John Wiley & Sons, Inc.)
