2.1 Introducing The CUDA Programming Model
프로그래밍 모델은 가용 HW에서 응용 프로그램과 응용 프로그램 구현의 가교 역할을 하는 computer architecture의 abstraction을 제공한다. 다음 그림은 프로그램과 프로그래밍 모델 구현 사이에 있는, 중요한 abtractions layers을 나타낸다.

Communication Abstraction은 프로그램과 프로그래밍 모델 구현 사이의 경계로, 이는 컴파일러 또는 privileged hardware 기본 요소와 운영 체제를 사용하는 라이브러리로 실현된다. 프로그래밍 모델을 위해 작성된 프로그램은 프로그램 구성 요소가 어떻게 정보를 공유하고 활동을 조정하는지를 결정한다. 프로그래밍 모델은 특정 computing architecture에 대한 개념적 구조를 제공한다. 이는 프로그래밍 언어 또는 프로그래밍 환경으로 구현된다.
2.2 CUDA Programming Structure
2.2.1 Memory
CUDA 프로그래밍 모델은 C 프로그래밍 언어를 조금 확장시키는 것만으로 heterogeneous computing system에서 애플리케이션 구현을 가능하게 한다. heterogeneous environment은 GPUs가 CPUs을 보완하는 식으로 구성되어 있으며, 각각 PCIe-bus에 의해 분리된 채 고유의 메모리를 가진다.
- host: CPU와 그 메모리(host memory)
- device: GPU와 그 메모리(device memory)
개선된 모델인 CUDA6은 Unified Memory 을 선보이는 데, 이는 분리된 host memory와 device memory의 다리 역할을 한다. 즉, system이 host와 device 사이에서 data을 옮기는 동안, single pointer만으로도 CPU와 GPU 모두에 접근할 수 있게 한다.
2.2.2 kernel
CUDA는 programmer가 작성한 kernel을 GPU threads에 스케줄링하는 것을 관리하고, host는 application data와 GPU device capability을 기반으로 알고리즘이 device에 어떻게 대응되는지 정의한다. 이는 programmer가 GPU threads의 세부 사항에 얽매이지 않고 kernel을 sequential program으로 구현이 가능하게 한다.
2.2.3 The host can operate independently of the device for most operations.
kernel이 실행되면 해당 kernel 실행의 완료를 기다리지 않고 곧바로 host(CPU)가 device에서 실행되는 data parallel code와 보완되는 추가 작업을 할 수 있다. 즉, CUDA 프로그래밍 모델은 주로 비동기적(asynchronous)으로 작동하여 GPU에서 수행되는 연산이 host 및 device 간 communication과 동시에 일어날 수 있게 한다. 일반적으로 CUDA 프로그램은 serial code와 parallel code로 구성되는데, 각각은 CPU와 GPU에서 실행된다.
A typical processing flow of a CUDA program
1. CPU 메모리에서 GPU 메모리로 data을 복사한다.
2. GPU 메모리에 저장된 data을 처리하기 위해 kernels을 호출한다.
3. GPU 메모리에서 CPU 메모리로 data을 복사한다.
2.3 Managing Memory
2.3.1 host and device memory functions
| STANDARD C FUNCTIONS | CUDA C FUNCTIONS |
|---|---|
| malloc | cudaMalloc |
| memcpy | cudaMemcpy |
| memset | cudaMemset |
| free | cudaFree |
GPU 메모리가 성공적으로 할당되면 'cudaSuccess'라고 반환된다. 그렇지 않으면, 'cudaErrorMemoryAllocation'이라고 반환된다.
2.3.2 Memory Hierarchy
CUDA 프로그래밍 모델은 GPU architecture의 메모리 계층 구조의 abstraction을 제공한다. 다음은 GPU Memory Hierarchy이다.
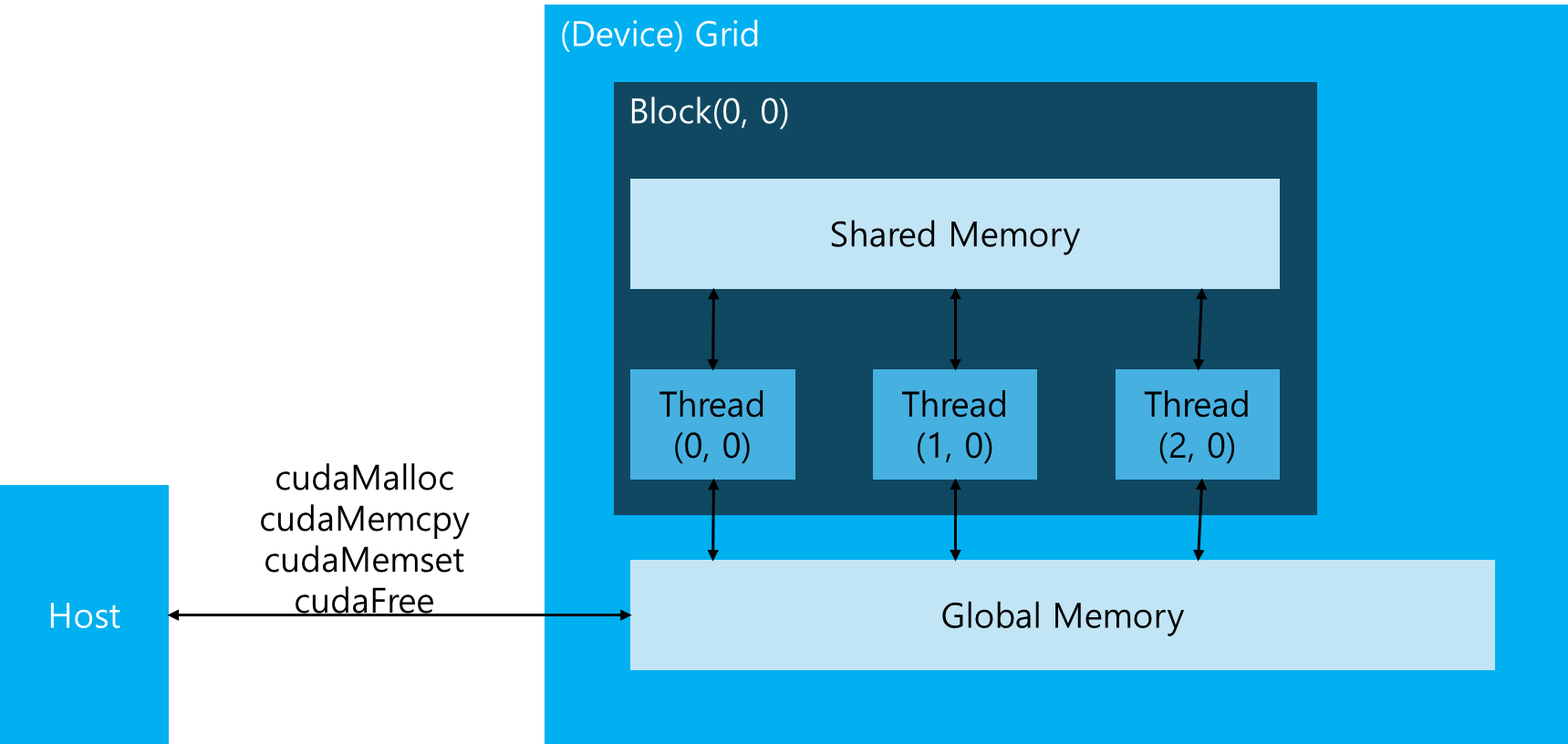
Global memory는 CPU system memory와 유사하고, Shared memory는 CPU cache와 비슷하다. 그런데 GPU shared memory는 CUDA C kernel로 직접 조작이 가능하다.
2.4 Organizing Threads
2.4.1 configuration
host 측에서 kernel 함수가 실행되면, 실행은 대량의 threads가 생성되는 device로 이동하고, 각 thread는 kernel 함수에 지정된 명령문을 실행한다. threads을 어떻게 조직하는지를 아는 것은 CUDA 프로그래밍에 있어서 중요하다. CUDA는 threads을 조직할 수 있도록 thread hierarchy abstraction을 제공하는데, 이는 thread block과 grid block으로 분해되는 two-level thread hierarchy이다.
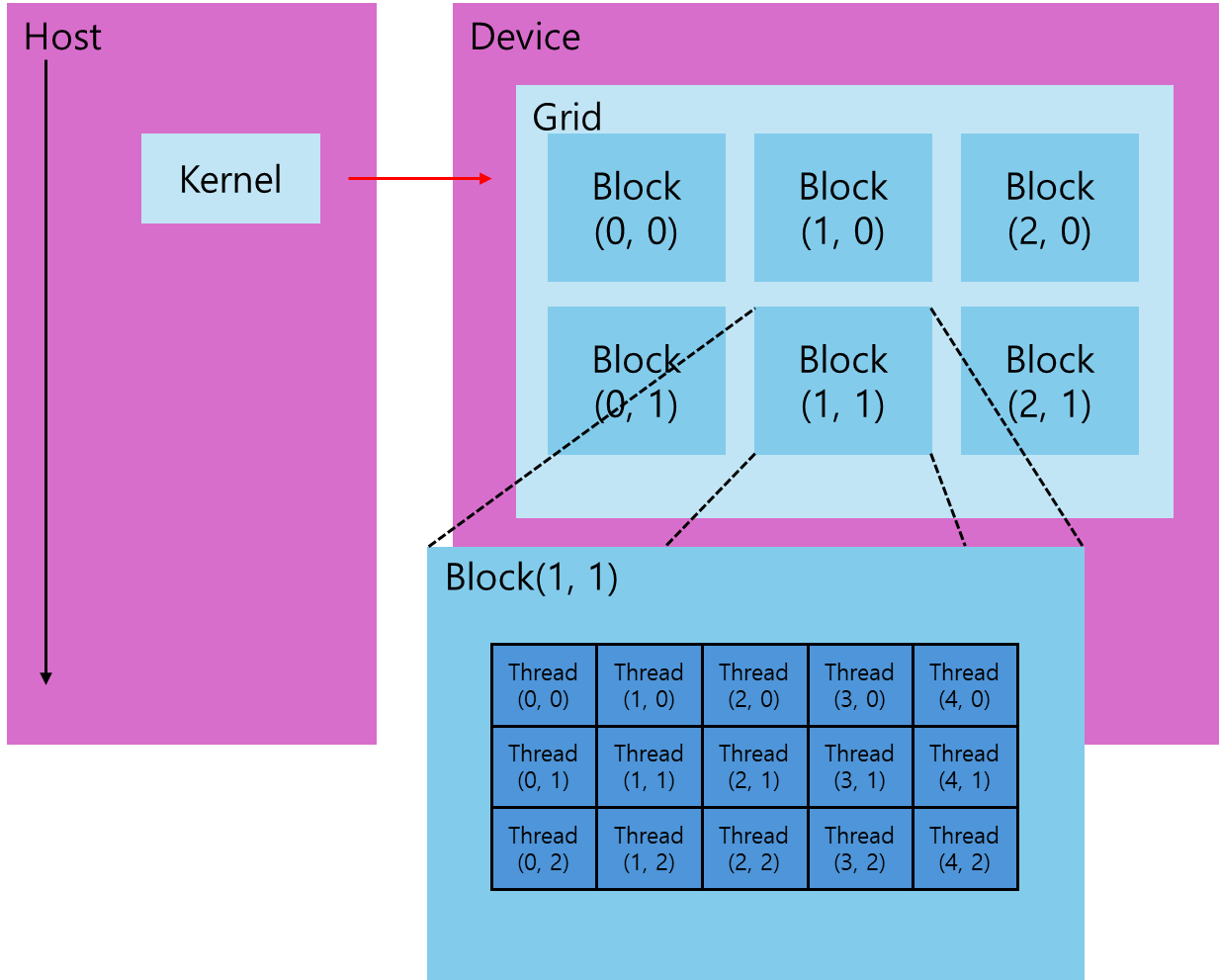
어떤 단일 kernel 실행으로 생성되는 모든 threads는 총체적으로 grid 라 불린다. grid 내 모든 threads는 동일한 global memory을 공유한다. 또한, grid는 여러 thread blocks으로 구성되어 있으며, 하나의 thread block은 block-local synchronization과 block-local shared memory을 사용하여 협력할 수 있는 하나의 thread group이다. 반대로, 다른 blocks에 속한 threads와는 협력이 불가하다.
한편, threads는 서로 구분짓기 위해 다음의 고유한 좌표를 사용한다.
- blockIdx (grid 내 block index)
- threadIdx (block 내 thread index)
위 변수는 kernel 함수 내에서 접근할 수 있는 내장된, 사전에 초기화된 변수로 나타난다. kernel 함수가 실행될 때, 두 좌표 blockIdx와 threadIdx는 CUDA runtime에 의해 각 thread에 할당된다. 그 좌표에 근거하여, 각각의 threads에 data을 할당할 수 있다.
한편, 그 좌표는 uint3 타입 변수인데, 이는 기본 정수 타입에서 파생된, CUDA 내장 벡터 타입이다. 이는 세 개의 unsigned integer로 구성된 구조체이고, 첫 번째, 두 번째, 세 번째 구성 요소는 각각 x, y, z field로 접근할 수 있다.
- blockIdx.x, blockIdx.y, blockIdx.z
- threadIdx.x, threadIdx.y, threadIdx.z
CUDA는 grids와 blocks을 3차원으로 구성한다. 위 그림은 2차원 blocks을 포함하는 2차원 grid의 thread hierarchy 구조의 예시이다. grid와 block의 차원은 다음 두 가지 내재된 변수로 특정된다.
- blockDim(block dimension, threads 단위로 측정)
- gridDim(grid dimension, blocks 단위로 측정)
위 변수는 차원을 나타내기 위해 uint3에서 파생된 integer vector 타입인, dim3 타입이다. dim3 타입의 변수를 정의할 때, 아무런 값도 지정하지 않으면 1로 초기화된다. dim3 타입 변수의 각 구성 요소는 x, y, z field로 접근할 수 있으며, 각각은 다음과 같이 표현할 수 있다.
- blockDim.x
- blockDim.y
- blockDim.z
보통, grid는 2차원 배열의 blocks으로 구성되고, block은 3차원 배열의 threads로 구성된다. grids와 blocks 모두 dim3 타입의 unsigned integer fields이며, 사용되지 않는 fields는 1로 초기화되고 무시된다.
2.4.2 data types
CUDA 프로그램에는 두 가지의 grid와 block 변수가 있는데, 하나는 수동으로 정의된 dim3 데이터 타입이고, 다른 하나는 사전에 정의된 uint3 데이터 타입이다. host 측에서는 kernel 호출의 일환으로 dim3 데이터 타입을 사용하여 grid와 block의 차원을 정의한다. kernel이 실행될 때, CUDA runtime은 그에 상응하는, 내장된 사전에 초기화된 grid, block 및 thread 변수를 생성하며, 이 변수들은 kernel 함수 내에서 접근할 수 있고 uint3 타입을 가진다.
수동으로 정의된 dim3 데이터 타입의 grid와 block 변수는 host 측에서만 볼 수 있으며, 사전에 정의된 uint3 데이터 타입의 내장된 grid와 block 변수는 device 측에서만 볼 수 있다.
2.4.3 Example: grid and block indices and dimensions
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* Display the dimensionality of a thread block and grid from the host and
* device.
*/
__global__ void checkIndex(void)
{
printf("threadIdx:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z);
printf("blockIdx:(%d, %d, %d)\n", blockIdx.x, blockIdx.y, blockIdx.z);
printf("blockDim:(%d, %d, %d)\n", blockDim.x, blockDim.y, blockDim.z);
printf("gridDim:(%d, %d, %d)\n", gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char **argv)
{
// define total data element
int nElem = 6;
// define grid and block structure
dim3 block(3); // (the block size)
dim3 grid((nElem + block.x - 1) / block.x); // (the grid size)
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
// check grid and block dimension from device side
checkIndex<<<grid, block>>>();
// reset device before you leave
CHECK(cudaDeviceReset());
return(0);
}결과
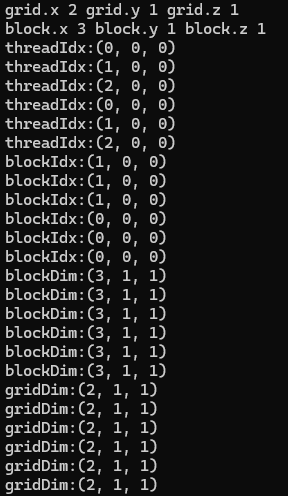
※ Why block.x == 3, block.y == 1, block.z == 1?
dim3 block(3);위와 같이, 'block'의 y와 z 방향 dimension은 지정하지 않았으므로 기본값으로 1이 된다. 한편, 1이 아닌 다른 값으로 지정하고 싶다면, 아래와 같은 예시처럼 하면 된다.
// block.x == 3, block.y == 2, block.z == 2
dim3 block(3, 2, 2);※ Why dim3 grid((nElem + block.x - 1) / block.x)?
'nElem'에 'block.x - 1'을 더하는 이유는 나누기 연산의 올림 효과를 얻기 위함이다. 위 예시에서는 6개의 Elements가 있고, 각 block이 3개의 Elements을 처리한다고 하면, 정확히 2개(6/3)의 blocks이 필요하다.
하지만 7개의 Elements가 있다면, 3개의 Elements을 처리할 수 있는 blocks의 수가 정확히 나누어 떨어지지 않고, 3개의 blocks이 필요하다. 이러한 값을 얻기 위해서 위와 같은 식으로 계산한다.
※ Why grid.x == 2, grid.y == 1, grid.z == 1?
block의 경우와 마찬가지로, grid의 y와 z 방향 dimension은 지정하지 않았으므로 기본값으로 1이 된다.
※ Explaination: checkIndex<<<grid, block>>>();
grid는 dim3(2, 1, 1)로 설정되는데, 이는 2개의 blocks을 가짐을 의미한다. block은 dim3(3, 1, 1)로 설정되는데, 이는 각 block이 3개의 threads을 가짐을 의미한다. kernel 함수는 GPU에서 병렬로 실행되며, 각 thread는 'checkIndex' 함수를 실행한다.
2.4.4 Example: grid and block dimensions on the host
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* Demonstrate defining the dimensions of a block of threads and a grid of
* blocks from the host.
*/
int main(int argc, char **argv)
{
// define total data element
int nElem = 1024;
// define grid and block structure
dim3 block (1024);
dim3 grid ((nElem + block.x - 1) / block.x);
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 512;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 256;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 128;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset device before you leave
CHECK(cudaDeviceReset());
return(0);
}결과
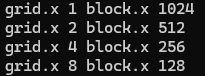
※ Explaination: when block.x == 1024
grid는 1개의 block으로, block은 1024개의 threads로 구성되어 있다.
※ Explaination: when block.x == 512
grid는 2개의 blocks으로, block은 512개의 threads로 구성되어 있다.
※ Explaination: when block.x == 256
grid는 4개의 blocks으로, block은 256개의 threads로 구성되어 있다.
※ Explaination: when block.x == 128
grid는 8개의 blocks으로, block은 128개의 threads로 구성되어 있다.
2.4.5 2-level Thread Hierarchy
실행하는 kernel의 grid와 block dimension이 성능에 영향을 미치는데, 이러한 간단한 abstraction은 프로그래머에게 추가적인 최적화 방법을 제공한다. grid와 block dimension에는 여러 제한이 있다. 그 중 하나는 registers, shared memory 등 사용 가능한 컴퓨팅 자원 내에서 block 크기를 알맞게 조정해야 하는 것이다.
2.5 Launching a CUDA Kernel
2.5.1 Specifying the grid and block dimensions
kernel_name <<<grid, block>>>(argument list);위 함수로 grid와 block dimension을 특정할 수 있으므로, 어떤 kernel에 대한 threads의 총 개수와 어떤 kernel에 대해 사용할 threads의 layout을 설정할 수 있다.
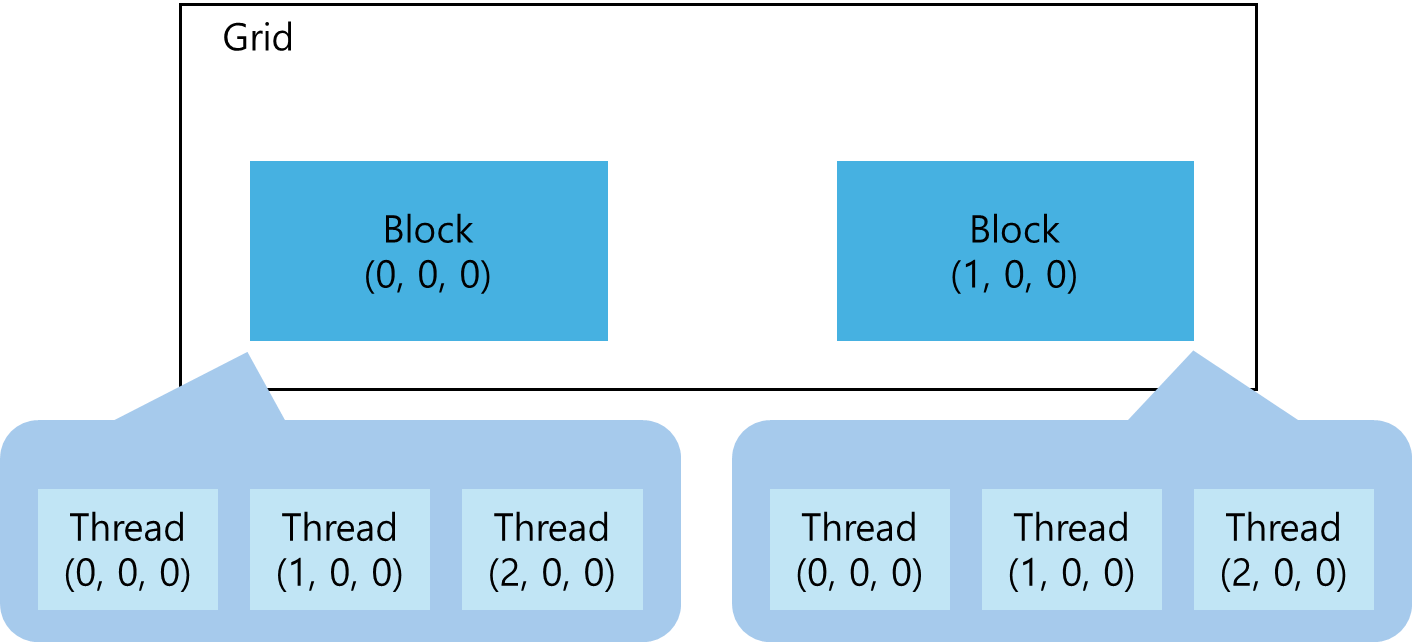
한편, 같은 block 내 threads끼리는 통신이 매우 간단하지만, 다른 blocks에 속한 threads와는 불가능하다. 예를 들어, 32개의 data elements을 block 별로 8 elements 씩 할당했다고 하겠다.
kernel_name <<<4, 8>>>(argument list);data는 global memory 내 선형적으로 저장되었으므로, built-in variables blockIdx.x 와 threadIdx.x 을 사용하여 어떤 grid 내 특정 thread을 가리키거나 threads와 data elements 간 mapping이 가능하다.
2.5.2 asynchronism
kernel 호출은 host thread와 비동기적이다. 그래서 kernel이 호출되면, control은 곧바로 host 측으로 넘어간다. 물론, 다음 함수를 사용하여 모든 kernels이 완료될 때까지 host application이 강제로 기다리도록 할 수 있다.
cudaError_t cudaDeviceSynchronize(void);한편, 몇몇 CUDA runtime API는 host와 device 사이에서 암묵적인 동기화를 하긴 한다. host와 device 사이에서 data를 복사하는 'cudaMemcpy'을 쓰면, host 측에서 동기화가 실행되고, host application은 data 복사가 끝날 때까지 기다리게 된다.
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind);선행 kernels 호출이 끝날 후에야 복사가 이루어지며, 복사가 끝났을 때에야 비로소 host 측으로 control이 넘어간다.
2.6 Writing Kernel
2.6.1 Function Type Qualifiers
| Qualifiers | Execution | Callable | Notes |
|---|---|---|---|
| __global__ | on the device | callable from the host, callable from the device for devices of compute capability 3 | must have a void return type |
| __device__ | on the device | callable from the device only | |
| __host__ | on the host | callable from the host only | can be omitted |
__device__와 __host__ qualifiers는 함께 쓰일 수 있으며, host와 device 모두에 대해 컴파일된다.
※ Restrictions
- device memory에 대해서만 접근 가능
- void 반환형만 사용 가능
- 가변 인자 함수, 정적 변수, 함수 포인터 미지원
- 비동기적 수행
2.6.2 iteration in C vs. parallel computation in CUDA
다음 예시는 C에서 반복문을 구현한 것이다.
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int i = 0; i < N; i++)
C[i] = A[i] + B[i];
}위 반복문 내 덧셈 연산을 N개의 threads로 대체 구현하여, 반복문을 사용하지 않고도 위 연산을 병렬적으로 수행할 수 있다. 여기서는 N = 32라고 가정하자.
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
sumArraysOnGPU<<<1, 32>>>(float *A, float *B, float *C);2.7 Verifying Kernel Code
kernel 결과의 타당성을 입증하기 위해서는 host function이 필요하다.
void checkResult(float *hostRef, float *gpuRef, const int N) {
double epsilon = 1.0E-8;
int match = 1;
for (int i = 0; i < N; i++) {
if (abs(hostRef[i] - gpuRef[i]) > epsilon) {
match = 0;
printf("Arrays do not match\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], gpuRef[i], i);
break;
}
}
if(match)
printf("Arrays match.\n\n");
return;
}위와 같이 유용한 디버깅 모델 이외에도, 매우 간단하면서도 유용한 방법이 두 가지 있다.
① Fermi 을 포함한 그 이후 세대의 device에서는 kernel에서 'printf'을 사용할 수 있다.
② execution configuration을 <<<1, 1>>>로 설정하여 kernel을 하나의 block과 하나의 thread로만 실행되도록 강제할 수 있다. 이는 순차적인 방식인데, 디버깅과 결과 입증에 유용하다. 또한, 연산 순서 문제에 직면했을 때 실행 간에 숫자 결과가 비트 단위로 정확한지 확인하는 데 도움이 된다.
2.8 Handling Errors
대다수의 CUDA 호출은 비동기적이므로, 어떤 곳에서 오류가 발생했는지 찾기가 어려울 것이다. 이때 CUDA API 호출을 포함하는 오류 처리 매크로를 정의하면 오류를 확인하는 과정을 용이하게 할 것이다.
#define CHECK(call)
{
const cudaError_t error = call;
if (error != cudaSuccess)
{
printf("Error: %s: %d, ", __FILE__, __LINE__);
printf("code: %d, reason: %s\n", error, cudaGetErrorString(error));
exit(1);
}
}다음 코드처럼 매크로를 사용할 수 있다.
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));만약 메모리 복사나 이전의 asynchronous operation이 오류를 일으켰다면, 매크로는 그에 대응되는 오류 코드를 알려주고, 사람이 읽을 수 있는 메시지를 출력하며, 그 프로그램을 멈춘다. 또한, kernel 오류를 확인하기 위해 kernel 호출 후에 다음과 같은 방법으로도 사용될 수 있다.
kernel_function<<<grid, block>>>(argument list);
CHECK(cudaDeviceSynchronize());'CHECK(cudaDeviceSynchronize())'는 device가 모든 요청된 작업을 완료할 때까지 host thread을 block하며, 마지막 kernel 실행에 의한 오류가 없음을 보장한다.
이 방식은 디버깅 목적으로만 권장되는데, 이는 kernel 실행 후에 check point(동기화 지점)을 추가하면 host thread을 block시키고 해당 지점을 global barrier로 만들어서 전체 프로그램의 병렬 처리 효율성이 저하되기 때문이다.
※ global barrier
병렬 컴퓨팅에서 모든 병렬 작업이 특정 지점에서 멈추고, 다른 모든 병렬 그 지점에 도달할 때까지 기다려야 하는 동기화 지점을 의미한다. 이는 모든 병렬 작업이 일정한 단계나 작업을 완료한 후, 다음 단계로 함께 이동하도록 보장하는 데 사용된다.
2.9 Compiling and Executing
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. Only a single thread block is used in this small case, for simplicity.
* sumArraysOnHost sequentially iterates through vector elements on the host.
*/
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
C[idx] = A[idx] + B[idx];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
CHECK(cudaSetDevice(dev));
// set up data size of vectors
int nElem = 1 << 5;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// malloc device global memory
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
dim3 block (nElem);
dim3 grid (1);
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
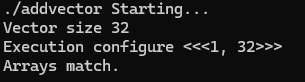
printf("Execution configure <<<%d, %d>>>\n", grid.x, block.x);
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// add vector at host side for result checks
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
CHECK(cudaDeviceReset());
return(0);
}결과
2.10 Timing
kernel이 실행되는 동안 걸리는 시간을 알면 kernel의 성능 조정 시 매우 유용하다. 가장 간단한 방법으로 CPU timer 또는 GPU timer를 사용하여 host 측에서 kernel 실행 시간을 측정하는 것이 있다.
2.10.1 Timing with CPU Timer
'gettimefoday' 시스템 호출로 CPU timer을 만들 수 있다. 이를 사용하기 위해서는 sys/time.h 헤더파일을 포함시켜야 한다.
double cpuSecond() {
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec*1.e-6);
}다음과 같은 방법으로 kernel에 대해 'cpuSecond'을 적용할 수 있다.
double iStart = cpuSecond();
kernel_name<<<grid, block>>>(argument list);
cudaDeviceSynchronize();
double iElaps = cpuSecond() - iStart;kernel 호출은 host에 대해 비동기적이므로, 모든 GPU threads가 끝마칠 때까지 기다리도록 'cudaDeviceSynchronize()'을 사용해야 한다.
가령, 데이터 세트의 크기를 다음과 같이 설정하여 1,600만 개의 elements을 가진 큰 벡터를 테스트한다고 하자.
int nElem = 1<<24;GPU 확장성(scalability)을 위해 kernel을 수정해야 하는데, block 및 thread 인덱스를 사용하여 행 우선 배열 index 'i'을 계산하고, 배열 경계를 초과할 수 있는 index을 확인하기 위해 'i < N' 테스트를 추가해야 한다.
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}참고로 생성된 총 thread 수가 벡터 elements의 총 개수보다 큰 경우를 처리하기 위해, 다음 그림과 같이 illegal global memory 접근으로부터 kernel을 제한해야 한다.

※ What is GPU scalability?
GPU 확장성은 GPU을 사용하는 프로그램이나 알고리즘이 더 큰 데이터 세트나 더 많은 작업량을 처리할 수 있도록 성능을 향상시키는 능력을 의미한다. 확장성이 좋은 GPU 프로그램은 데이터 크기나 작업량이 증가할 때, GPU의 리소스를 최대한 활용하여 성능 저하 없이 효율적으로 작업을 처리할 수 있다. 이를 위해 다음 요소를 고려해야 한다.
- 병렬화: 작업을 가능한 한 작은 부분으로 많이 나누어 동시에 처리
- thread 관리: 적절한 수의 thread을 생성하고 배치하여 리소스를 최대한 활용
- 메모리 접근: 전역 메모리, 공유 메모리, 레지스터 등을 효율적으로 사용하여 메모리 접근 병목 현상 최소화
- 동기화: 필요할 때만 thread 간 동기화를 사용하여 성능 저하 방지
※ What is illegal global memory access?
'불법적인 전역 메모리 접근'은 GPU 프로그래밍에서 kernel이 배열의 범위를 벗어난 메모리에 접근하려고 할 때 발생하는 문제를 말한다. 이는 프로그램이 예기치 않게 동작하거나 충돌할 수 있는 빌미를 제공한다. 특히, CUDA 등 병렬 프로그래밍 환경에서는 많은 threads가 동시에 실행되므로 이러한 문제가 발생하기 쉽다.
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. Only a single thread block is used in this small case, for simplicity.
* sumArraysOnHost sequentially iterates through vector elements on the host.
* This version of sumArrays adds host timers to measure GPU and CPU
* performance.
*/
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)( rand() & 0xFF ) / 10.0f;
}
return;
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
{
C[idx] = A[idx] + B[idx];
}
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of vectors
int nElem = 1 << 24;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
double iStart, iElaps;
// initialize data at host side
iStart = seconds();
initialData(h_A, nElem);
initialData(h_B, nElem);
iElaps = seconds() - iStart;
printf("initialData Time elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add vector at host side for result checks
iStart = seconds();
sumArraysOnHost(h_A, h_B, hostRef, nElem);
iElaps = seconds() - iStart;
printf("sumArraysOnHost Time elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int iLen = 1024;
dim3 block (iLen);
dim3 grid ((nElem + block.x - 1) / block.x);
iStart = seconds();
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
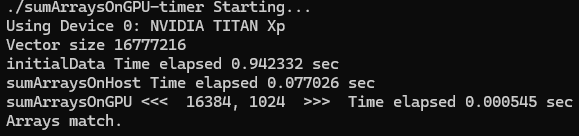
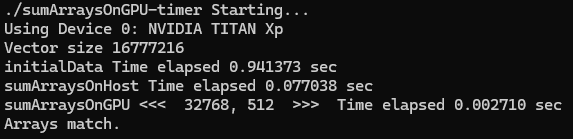
printf("sumArraysOnGPU <<< %d, %d >>> Time elapsed %f sec\n", grid.x,
block.x, iElaps);
// check kernel error
CHECK(cudaGetLastError()) ;
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}결과
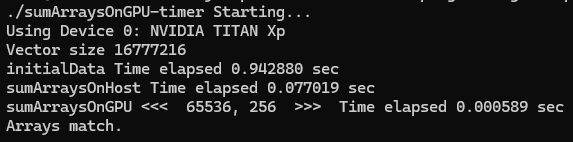
2.11 Timing with nvprof
CUDA 5.0부터 'nvprof'라는 command-line profiling tool을 사용할 수 있다. 이는 kernel 실행, 메모리 전송 및 CUDA API 호출을 포함하여 application의 CPU 및 GPU 활동에 대한 타임라인 정보를 수집하는데 도움이 된다.
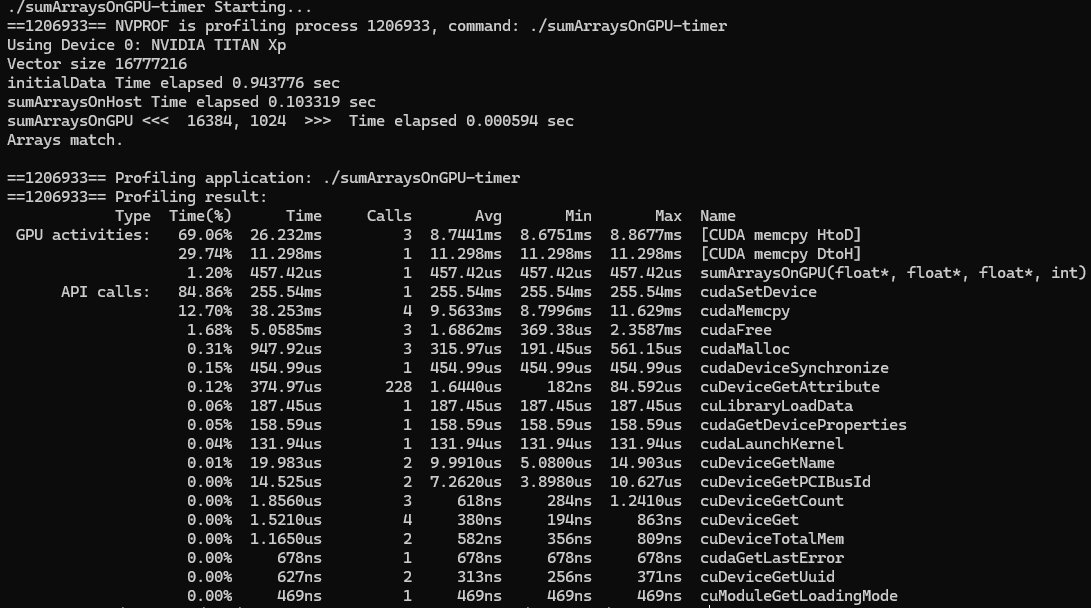
메시지의 전반부는 프로그램의 출력이고, 후반부는 'nvprof'의 출력을 포함한다. CPU timer는 kernel 실행 시간을 594 us로 보고했는데, 'nvprof'는 kernel 실행 시간을 457.42 us라고 보고했다. 'nvprof' 결과가 host 측 timing 결과보다 더 정확한데, 이는 CPU timer로 측정한 시간에 'nvprof'의 overhead가 포함되었기 때문이다. 본 예시에서는 host와 device 간 데이터 전송이 kernel 실행보다 더 많은 시간을 소요한다는 것을 알 수 있다.
HPC workload에서는 프로그램의 연산과 통신의 비율을 이해하는 것이 중요하다. application이 데이터 전송보다 연산에 더 많은 시간을 소비한다면, 이러한 작업을 겹쳐서 데이터 전송과 관련된 latency을 완전히 숨길 수 있다. 반면, application이 데이터 전송보다 연산에 더 적은 시간을 소비한다면, host와 device 간 전송을 최소화하는 것이 중요하다.
2.12 Organizing Parallel Threads
앞선 예시에서 알맞은 grid와 block size을 채택하여 kernel 성능을 조정하는 것을 보았다. 특히 vector 덧셈에서 최적의 성능을 위해 block size을 조정하였고, block size와 vector data size에 따라 grid size가 계산되었다.
지금부터는 행렬 연산을 다룰 것인데, 접근 방식으로는 단순하게 threads을 2차원 blocks으로 구성된 2차원 grid로 구성하는 형태가 떠오를 것이다. 그러나 이는 최고의 성능을 보장하지는 않는다. 따라서 다양한 차원의 block과 grid을 시도하여 최고의 성능에 다다를 것이다.
2.13 Indexing Matrices with Blocks and Threads
일반적으로 행렬은 global memory에 행 우선 방식으로 다음과 같이 linear하게 저장된다. 해당 예시는 8 x 6 행렬이다.

행렬 덧셈 kernel에서는 보통 각 thread가 하나의 data element을 처리하도록 할당된다. block 및 thread index을 사용하여 global memory에서 할당된 데이터에 접근하는 것이 첫 번째이다. 일반적으로 2차원은 세 가지 종류의 index을 다뤄야 한다.
- thread and block index
- coordinate of a given point in the matrix
- offset in linear global memory
주어진 thread에 대해, thread와 block index을 행렬의 좌표로 매핑한 다음, 그 행렬 좌표를 global memory 위치로 매핑하여 global memory에서의 offset을 얻을 수 있다.
ⓛ thread 및 block index을 행렬 좌표로 mapping
ix = threadIdx.x + blockIdx.x * blockDim.x;
iy = threadIdx.y + blockIdx.y * blockDim.y;② 행렬 좌표를 global memory 위치/인덱스로 mapping
idx = iy * nx + ix;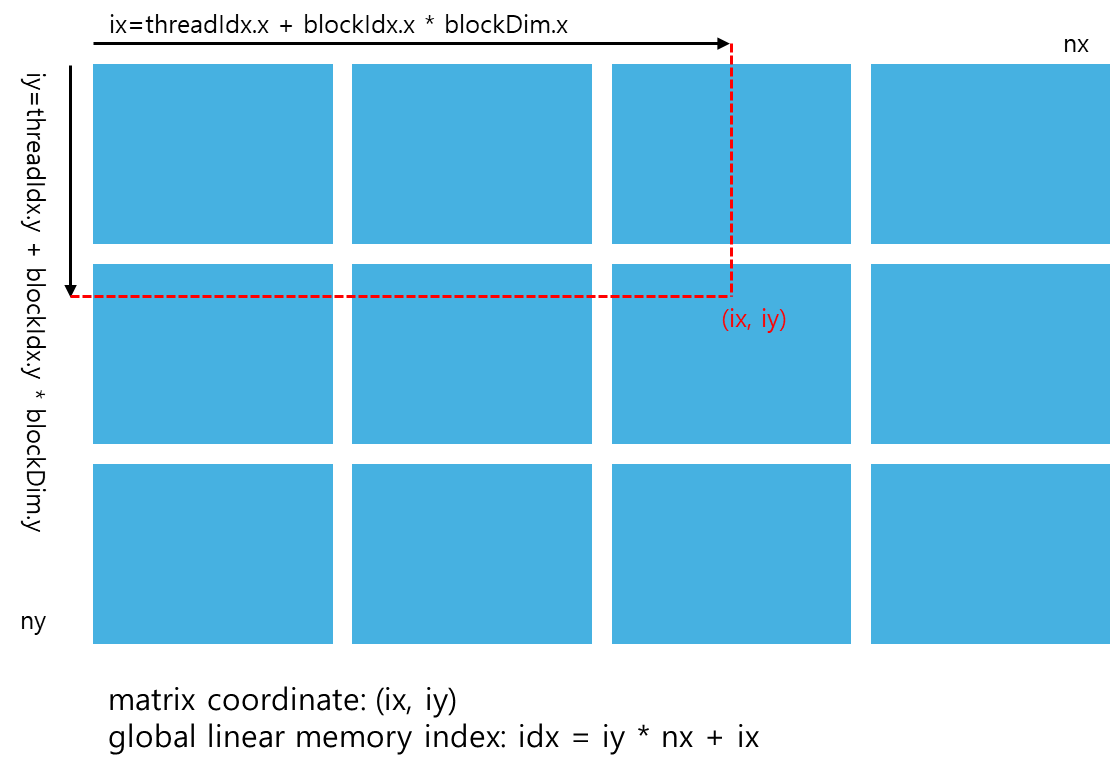
한편, 함수 'printThreadInfo'는 각 thread에 대한 다음의 정보를 출력할 때 쓰인다.
- thread index
- block index
- matrix coordinate
- global linear memory offset
- value of corresponding elements
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example helps to visualize the relationship between thread/block IDs and
* offsets into data. For each CUDA thread, this example displays the
* intra-block thread ID, the inter-block block ID, the global coordinate of a
* thread, the calculated offset into input data, and the input data at that
* offset.
*/
void printMatrix(int *C, const int nx, const int ny)
{
int *ic = C;
printf("\nMatrix: (%d.%d)\n", nx, ny);
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
printf("%3d", ic[ix]);
}
ic += nx;
printf("\n");
}
printf("\n");
return;
}
__global__ void printThreadIndex(int *A, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
printf("thread_id (%d,%d) block_id (%d,%d) coordinate (%d,%d) global index"
" %2d ival %2d\n", threadIdx.x, threadIdx.y, blockIdx.x, blockIdx.y,
ix, iy, idx, A[idx]);
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// get device information
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set matrix dimension
int nx = 8;
int ny = 6;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
// malloc host memory
int *h_A;
h_A = (int *)malloc(nBytes);
// iniitialize host matrix with integer
for (int i = 0; i < nxy; i++)
{
h_A[i] = i;
}
printMatrix(h_A, nx, ny);
// malloc device memory
int *d_MatA;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
// set up execution configuration
dim3 block(4, 2);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
// invoke the kernel
printThreadIndex<<<grid, block>>>(d_MatA, nx, ny);
CHECK(cudaGetLastError());
// free host and devide memory
CHECK(cudaFree(d_MatA));
free(h_A);
// reset device
CHECK(cudaDeviceReset());
return (0);
}결과
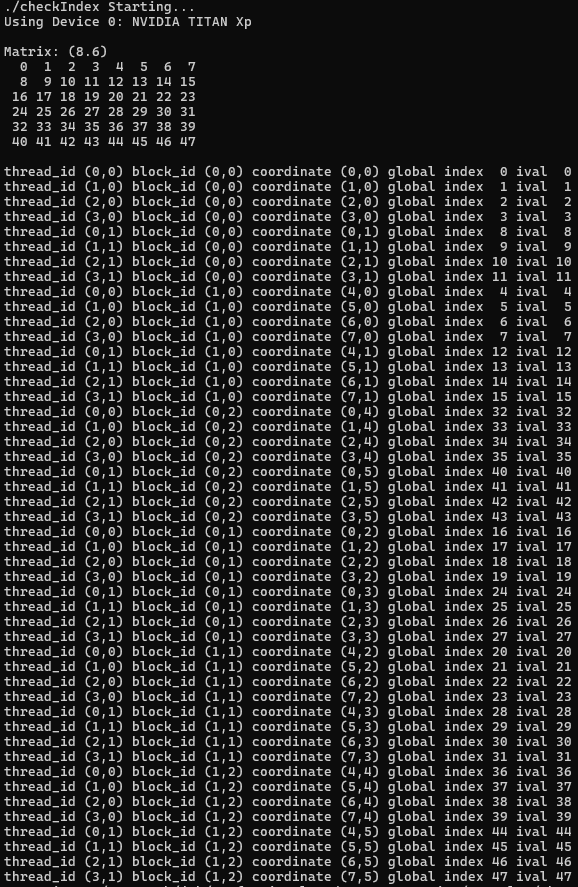
도식화
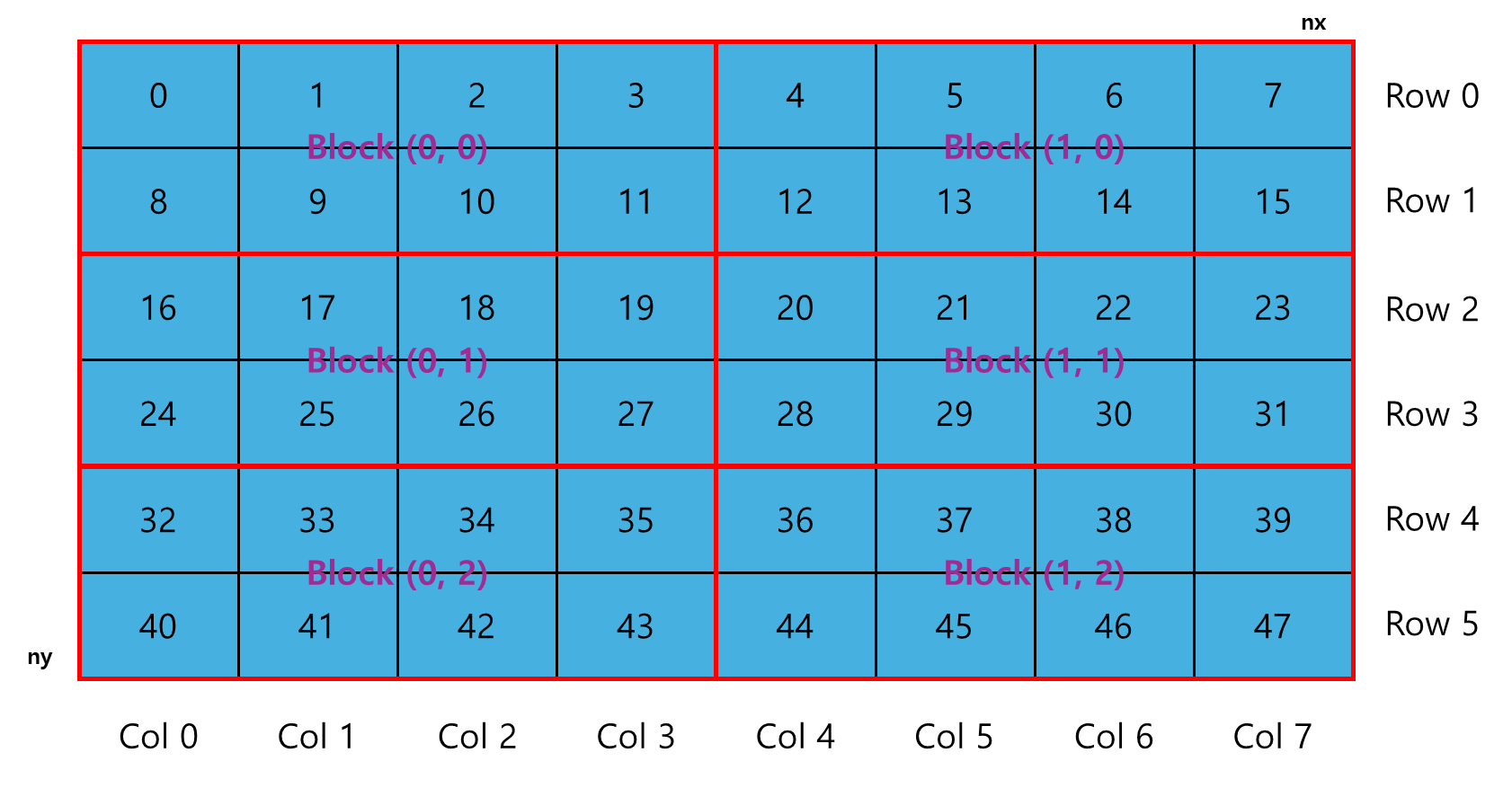
2.14 Summing Matrices with a 2D Grid and 2D Blocks
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. A 2D thread block and 2D grid are used. sumArraysOnHost sequentially
* iterates through vector elements on the host.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("Matrix initialization elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y,
block.x, block.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}결과
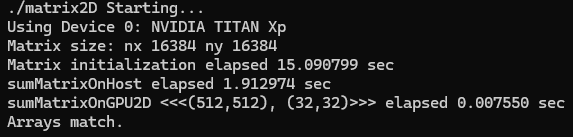
2.15 Summing Matrices with a 1D Grid and 1D Blocks
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. A 1D thread block and 1D grid are used. sumArraysOnHost sequentially
* iterates through vector elements on the host.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF ) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 1D block 1D
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx )
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("initialize matrix elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 32;
dim3 block(dimx, 1);
dim3 grid((nx + block.x - 1) / block.x, 1);
iStart = seconds();
sumMatrixOnGPU1D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y,
block.x, block.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}결과
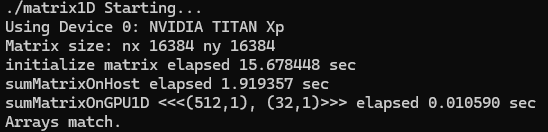
2.16 Summing Matrices with a 2D Grid and 1D Blocks
코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. A 1D thread block and 2D grid are used. sumArraysOnHost sequentially
* iterates through vector elements on the host.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 2D block 1D
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("Matrix initialization elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 32;
dim3 block(dimx, 1);
dim3 grid((nx + block.x - 1) / block.x, ny);
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y,
block.x, block.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}결과
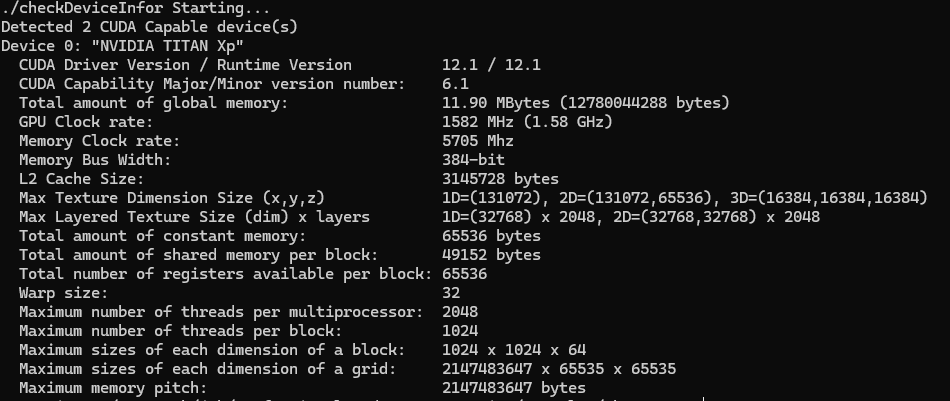
2.17 Using the Runtime API to Query GPU Information
다음 함수를 사용하여 GPU devices에 대한 정보를 조회(query)할 수 있다.
cudaError_t cudaGetDeviceProperties(cudaDeviceProp* prop, int device);코드
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* Display a variety of information on the first CUDA device in this system,
* including driver version, runtime version, compute capability, bytes of
* global memory, etc.
*/
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
int deviceCount = 0;
cudaGetDeviceCount(&deviceCount);
if (deviceCount == 0)
{
printf("There are no available device(s) that support CUDA\n");
}
else
{
printf("Detected %d CUDA Capable device(s)\n", deviceCount);
}
int dev = 0, driverVersion = 0, runtimeVersion = 0;
CHECK(cudaSetDevice(dev));
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Device %d: \"%s\"\n", dev, deviceProp.name);
cudaDriverGetVersion(&driverVersion);
cudaRuntimeGetVersion(&runtimeVersion);
printf(" CUDA Driver Version / Runtime Version %d.%d / %d.%d\n",
driverVersion / 1000, (driverVersion % 100) / 10,
runtimeVersion / 1000, (runtimeVersion % 100) / 10);
printf(" CUDA Capability Major/Minor version number: %d.%d\n",
deviceProp.major, deviceProp.minor);
printf(" Total amount of global memory: %.2f MBytes (%llu "
"bytes)\n", (float)deviceProp.totalGlobalMem / pow(1024.0, 3),
(unsigned long long)deviceProp.totalGlobalMem);
printf(" GPU Clock rate: %.0f MHz (%0.2f "
"GHz)\n", deviceProp.clockRate * 1e-3f,
deviceProp.clockRate * 1e-6f);
printf(" Memory Clock rate: %.0f Mhz\n",
deviceProp.memoryClockRate * 1e-3f);
printf(" Memory Bus Width: %d-bit\n",
deviceProp.memoryBusWidth);
if (deviceProp.l2CacheSize)
{
printf(" L2 Cache Size: %d bytes\n",
deviceProp.l2CacheSize);
}
printf(" Max Texture Dimension Size (x,y,z) 1D=(%d), "
"2D=(%d,%d), 3D=(%d,%d,%d)\n", deviceProp.maxTexture1D,
deviceProp.maxTexture2D[0], deviceProp.maxTexture2D[1],
deviceProp.maxTexture3D[0], deviceProp.maxTexture3D[1],
deviceProp.maxTexture3D[2]);
printf(" Max Layered Texture Size (dim) x layers 1D=(%d) x %d, "
"2D=(%d,%d) x %d\n", deviceProp.maxTexture1DLayered[0],
deviceProp.maxTexture1DLayered[1], deviceProp.maxTexture2DLayered[0],
deviceProp.maxTexture2DLayered[1],
deviceProp.maxTexture2DLayered[2]);
printf(" Total amount of constant memory: %lu bytes\n",
deviceProp.totalConstMem);
printf(" Total amount of shared memory per block: %lu bytes\n",
deviceProp.sharedMemPerBlock);
printf(" Total number of registers available per block: %d\n",
deviceProp.regsPerBlock);
printf(" Warp size: %d\n",
deviceProp.warpSize);
printf(" Maximum number of threads per multiprocessor: %d\n",
deviceProp.maxThreadsPerMultiProcessor);
printf(" Maximum number of threads per block: %d\n",
deviceProp.maxThreadsPerBlock);
printf(" Maximum sizes of each dimension of a block: %d x %d x %d\n",
deviceProp.maxThreadsDim[0],
deviceProp.maxThreadsDim[1],
deviceProp.maxThreadsDim[2]);
printf(" Maximum sizes of each dimension of a grid: %d x %d x %d\n",
deviceProp.maxGridSize[0],
deviceProp.maxGridSize[1],
deviceProp.maxGridSize[2]);
printf(" Maximum memory pitch: %lu bytes\n",
deviceProp.memPitch);
exit(EXIT_SUCCESS);
}결과
2.18 Determining the Best GPU
특정 kernel에 부합되는 최적의 GPU을 선택하는 작업은 매우 중요하다. 가장 높은 연산 능력을 가진 GPU를 식별하는 한 가지 방법은 그것에 multiprocessors 수를 확인하는 것이다. multi-GPU system이 있는 경우, 다음 코드를 사용하여 가장 연산 능력이 우수한 device을 채택할 수 있다.
int numDevices = 0;
cudaGetDeviceCount(&numDevices);
if (numDevices > 1) {
int maxMultiprocessors = 0, maxDevice = 0;
for (int device = 0; device < numDevices; device++) {
cudaDeviceProp props;
cudaGetDeviceProperties(&props, device);
if (maxMultiprocessors < props.multiProcessorCount) {
maxMultiprocessors = props.multiProcessorCount;
maxDevice = device;
}
}
cudaSetDevice(maxDevice);
}2.19 Using nvidia-smi to Query GPU Information
command-line tool 'nvidia-smi'는 GPU devices을 관리하고 모니터링하는데 도움을 주며, device 상태를 조회하고 수정할 수 있도록 한다. 예를 들어, 시스템에 몇 개의 GPU가 설치되어 있는지와 각 GPU의 device ID을 조회하려면, 다음과 같은 명령어를 입력하면 된다.
$ nvidia-smi -L
2.20 Setting Devices at Runtime
시스템에 N개의 GPU가 설치되어 있는 경우, nvidia-smi에서 보고하는 device ID는 0부터 N-1까지 라벨이 지정된다. 환경 변수 'CUDA_VISIBLE_DEVICES'로, application을 변경하지 않고도 실행 시 사용할 GPU를 지정할 수 있다.
runtime에서 'CUDA_VISIBLE_DEVICES=2'로 환경 변수를 설정할 수 있습니다. 그러면 nvidia driver가 다른 GPU를 마스킹하여 device 2를 application에서 device 0으로 인식하게 만든다.
또한, 'CUDA_VISIBLE_DEVICES'를 사용하여 여러 devices를 지정할 수도 있다. 예를 들어, GPU 2와 3을 테스트하려면 'CUDA_VISIBLE_DEVICES=2,3'로 설정하면 된다. 그러면 runtime에서 nvidia driver는 device ID 2와 3만 사용하고, 이들의 device ID를 각각 0과 1로 매핑한다.
<참고 문헌>
John Cheng, Max Grossman, Ty McKercher(2014). Professional CUDA C Programming. Indianapolis, Indiana, USA: Wrox (John Wiley & Sons, Inc.)
