3.1 GPU Architecture Overview
3.1.1 Maximizing Parallelism: Understanding SM and Thread Block Scheduling in GPUs
GPU architecture는 확장 가능한 Streaming Multiprocessors(SM) 배열을 중심으로 만들어졌다. GPU 내 각각의 SM은 수 백개의 threads의 동시 실행을 지원하도록 설계되어 있는데, GPU마다 다양한 SM이 있어서, 단일 GPU 상에서 수 천개의 thread의 동시 실행이 가능하다. kernel grid가 실행되면 thread blocks은 가용 SM resources에 따라 알맞은 SM으로 분배된다. 일단 SM 상에 스케줄링되면, thread block의 threads는 그 할당된 SM 상에서만 동시에 진행된다. 단일 thread 내 instructions은, CUDA에서 다뤘던 thread-level parallelism(TLP) 외에도 instruction-level parallelism(ILP)을 활용하기 위해 파이프라인화된다.
※ ILP
개념: ILP는 단일 thread 내에서 여러 instructions를 동시에 실행하여 성능을 향상시키는 방법
방법:
pipelining: instruction 실행을 여러 단계로 나누어 각 단계에서 다른 instruction를 동시에 처리
superscalar: 여러 instructions를 동시에 페치(fetch), 디코드(decode), 실행(execute)하는 방식
instruction reordering: instruction 재정렬하여 independent한 instructions을 동시에 실행
장점: 단일 thread의 실행 속도를 높일 수 있음
단점: instructions 간 dependency이 많으면 효과 저하 가능성 있음
※ TLP
개념: 여러 threads가 동시에 실행되는 것이다. 주로 multicore processor 또는 multi-thread를 지원하는 GPU에서 활용된다. CUDA와 같은 parallel computing platform에서는 많은 수의 threads가 동시에 실행되어 작업을 병렬로 처리할 수 있다.
종류:
multicore processor: 여러 개의 코어가 독립적으로 thread를 실행할 수 있어, 각 코어에서 다른 thread를 동시에 처리
GPU architecture: 많은 수의 SMs를 포함하며, 각 SM은 여러 threads를 병렬로 실행할 수 있음
CUDA는 32개의 threads을 묶은 warps 을 관리하고 실행하기 위해 Single Instruction Multiple Thread(SIMT) 구조를 사용한다. 하나의 warps 내 모든 threads는 같은 시간에 같은 instruction을 수행한다. 각 thread는 자체 instruction address counter와 register state가 있으며, 자체 데이터로 현재 instruction을 수행한다. 또한, 각 SM은 할당된 thread block을, 32개의 threads로 구성된 warp로 분할한 후, 사용 가능한 HW resources에서 실행하도록 스케줄링한다.
3.1.2 SIMT Vs. SIMD
공통점
- Both of them implement parallelism by broadcasting the same instruction to multiple execution units.
차이점
SIMD:
- All vector elements in a vector execute together in a unified synchronous group.
SIMT:
- Each thread has its own instruction address counter and register state.
- Each thread can have an independent execution path, even though all threads in a warp start together at the same program address.
3.1.3 Thread Block and Warp Scheduling and Resource Management in GPU SM
하나의 thread block은 유일한 SM에만 스케줄링되는데, 이후 실행이 완료될 때까지 그 SM에 머무른다. 한편, SM은 동시에 하나 이상의 thread block을 가질 수 있다.
Shared memory는 SM에 존재하는 thread blocks 간에 분할되고, registers는 threads 간에 분할된다. thread block 내 threads는 이러한 자원으로 상호 간에 cooperation 및 communication이 가능하다. 한편, thread block 내 모든 threads는 병렬적으로 수행되긴 하지만, 모든 threads가 동시에 실행되는 건 아니다. 이는 threads가 서로 다른 속도로 작업을 실행하게 한다.
병렬 threads 간 data을 공유하는 것은 race condition을 야기한다. 다시 말해, 여러 threads가 동일한 데이터를 임의의 순서로 다루게 되면, 예측 불허의 프로그램 동작이 발생한다. 따라서 CUDA는 thread block 내 threads을 동기화하여 모든 threads가 특정 포인트에 도달한 후에야 다음 단계로 넘어갈 수 있도록 한다. 그런데 block 간 동기화에는 어떠한 primitives도 제공되지 않는다.
thread block 내에서 warp가 어떤 순서로 스케줄링될지는 미지수이지만, active warp의 수는 SM 자원에 의해 제한된다. warp가 어떠한 이유로든 유휴 상태가 되면, SM은 동일한 SM에 존재하는 타 thread block에서 사용가능한 다른 warp을 스케줄링할 수 있다. 왜냐하면 하드웨어 자원이 SM의 모든 threads와 blocks에 나누어져 있어 새롭게 스케줄링된 warp는 이미 SM에 저장되어 있으므로, 동시 수행 중인 warps 간 스위칭에 오버헤드가 없어서 가능한 것이다.
Additional explanation for the last sentence
GPU는 warps 간 스위칭에 오버헤드가 없다는 것을 전통적인 CPU와 비교하여 다시 서술하겠다.
전통적인 CPU에서는 context switching을 할 때, 상태 저장 및 로드 작업이 필요하지만, GPU의 SM에서는 이러한 오버헤드가 발생하지 않습니다. 이는 각 워프의 상태가 항상 하드웨어 자원에 유지되기 때문이다.
CPU의 Context Switching:
하나의 프로세스나 스레드의 실행 상태를 저장하고, 다른 프로세스나 스레드의 실행 상태를 복원하는 과정이다. 다음 단계를 포함한다.
1. 현재 상태 저장
- 현재 실행 중인 프로세스의 레지스터 값, 프로그램 카운터, 스택 포인터 등 모든 상태 정보를 프로세스 제어 블록(PCB)에 저장
2. 새로운 상태 로드
- 다음으로 실행될 프로세스의 상태 정보를 PCB에서 읽어와 레지스터, 프로그램 카운터 등을 복원
위 과정에서 시간과 자원이 소요된다. 따라서 CPU에서의 context switching은 오버헤드가 발생할 수 있다.
GPU의 warp scheduling
GPU의 SM에서는 다수의 워프가 병렬로 실행된다. 각 워프의 상태는 미리 할당된 하드웨어 자원(레지스터 파일 등)에 저장되어 있어서 워프 간 스위칭 시 오버헤드가 없다. 이를 자세하게 살펴보면 다음과 같다.
1. 하드웨어 자원을 미리 할당
- SM 내의 register 파일과 shared memory는 각 warp와 thread block에 미리 할당된다. 각 warp는 자신의 상태(명령어 포인터, 레지스터 값 등)를 할당된 자원에 저장한다.
2. 즉시 접근 가능
- warp가 메모리 대기 등 유휴 상태가 되면, SM은 다른 warp을 즉시 스케줄링할 수 있따. 이때 새로운 warp의 상태는 이미 SM 내에 저장되어 있어 추가적인 상태 저장이나 로드가 필요없다.
3. 전환 오버헤드 없음:
- 전통적인 CPU와 달리, GPU의 SM은 워프 간 전환 시 추가적인 작업이 없으므로 전환 오버헤드가 발생하지 않는다.
Exposing Parallelism
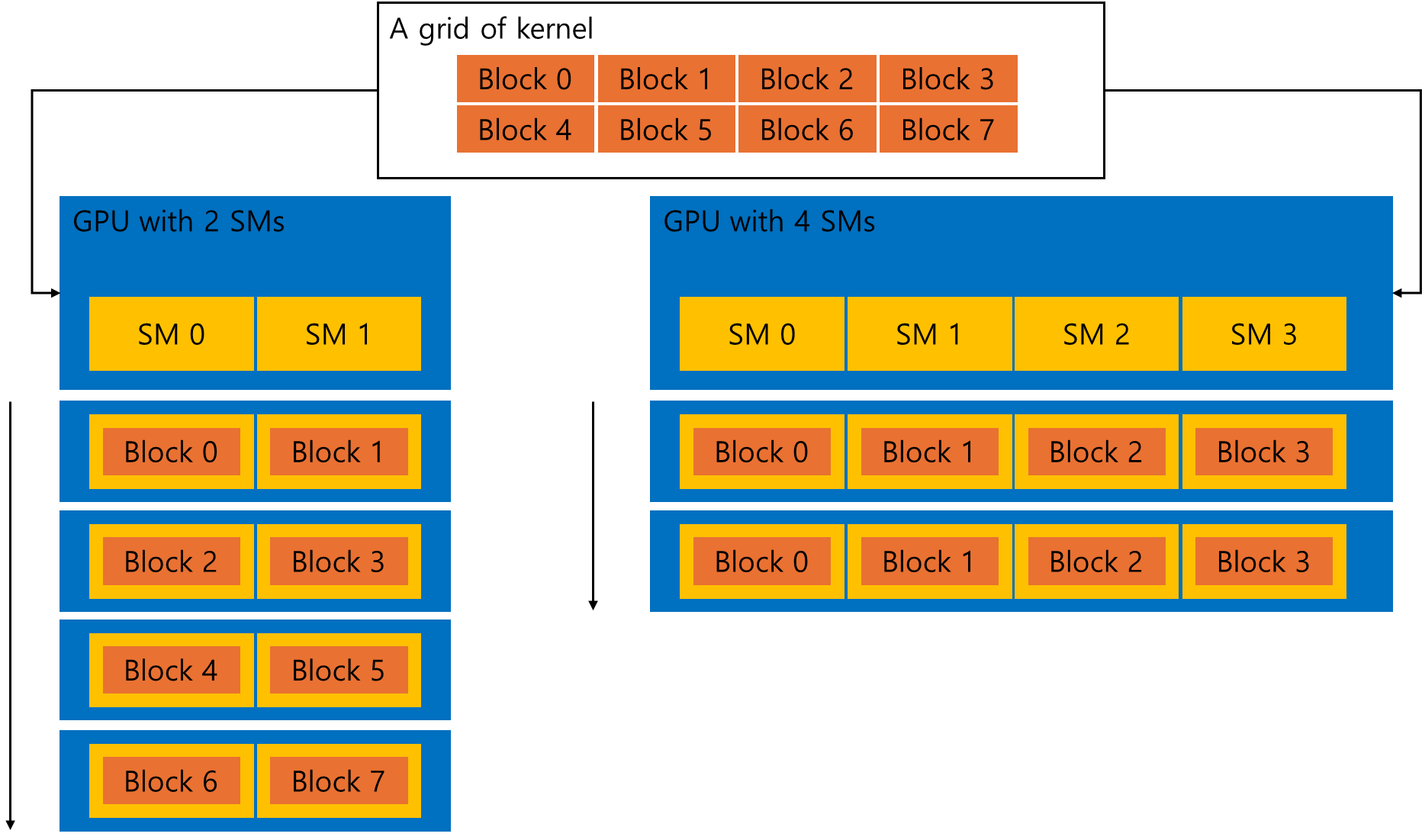
위 그림은 8개의 block으로 나누어진 커널의 grid을 나타낸다. 2개의 SM이 있는 GPU는 특정 순서로 블록을 실행할 수 있으며, 4개의 SM이 있는 GPU는 보다 더 많은 블록을 동시에 실행할 수 있다.
Checking Active Warps with nvprof
Avoiding Branch Divergence: The Parallel Reduction Problem
다음과 같은 코드가 있다고 가정하자.
int sum = 0;
for (int i = 0; i < N; i++)
sum += array[i];덧셈은 결합 법칙과 교환 법칙이 성립하므로, 위 코드에서 N이 굉장히 큰 수라면, 위 배열은 어떠한 순서로 더하든 결과에는 변함이 없다. 따라서 다음의 방법으로 덧셈을 병렬적으로 수행하면 된다.
- input vector을 더 작은 규모의 묶음으로 분할한다.
- 각 묶음의 합(부분합)을 수행한다.
- 그 부분합을 모두 더하여 최종 결과를 도출한다.
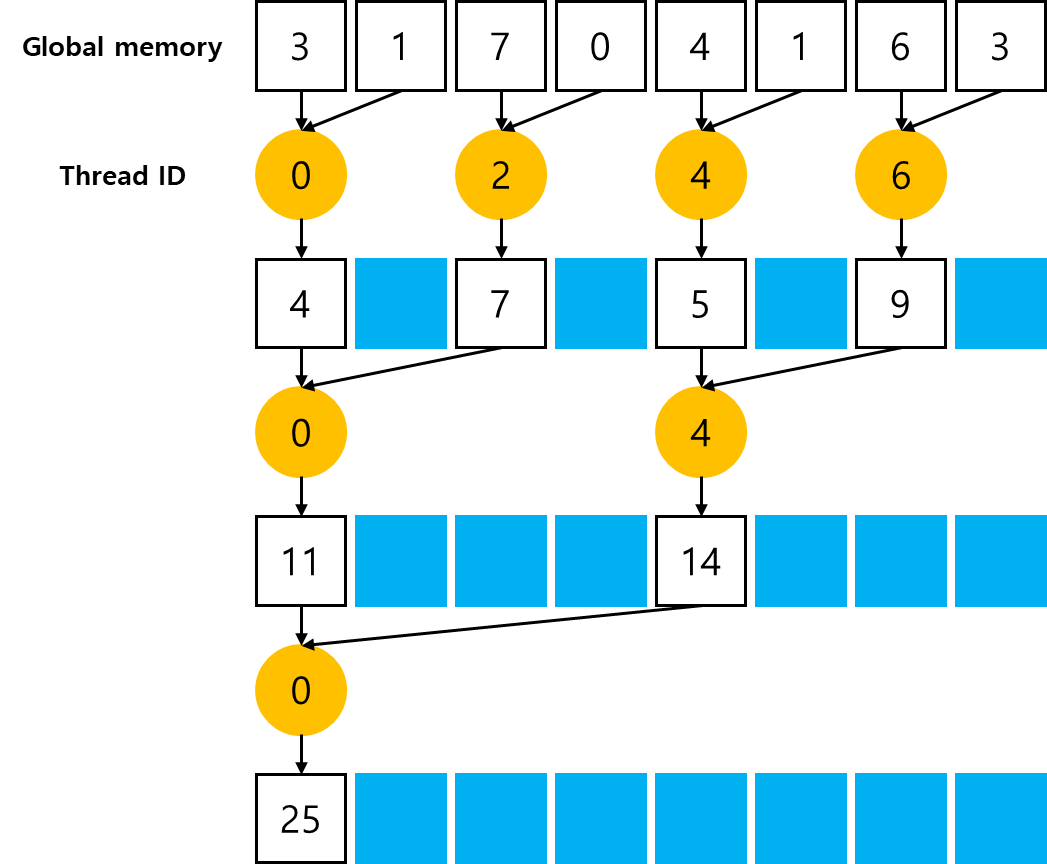
덧셈을 병렬적으로 수행하는 일반적인 방법 중 하나는 반복적인 쌍을 구현하는 것이다. 묶음(chunk)은 오직 두 개의 요소만을 포함하며, thread는 이 두 개의 요소만을 더한 부분합을 도출한다. 그리고 그 결과는 추가적인 메모리 공간을 사용하지 않고 기존 메모리 공간 내에 저장되며, 이러한 새로운 값이 추후 진행되는 덧셈의 입력값이 된다. 입력값의 수가 반복할 때마다 절반으로 줄어들기 때문에 출력 벡터의 길이가 1이 되면 최종 합이 계산된 것이다.
출력 요소가 매 반복마다 저장되는 위치에 따라, 각 쌍별 병렬 합 구현은 다음 두 가지 유형으로 분류된다.
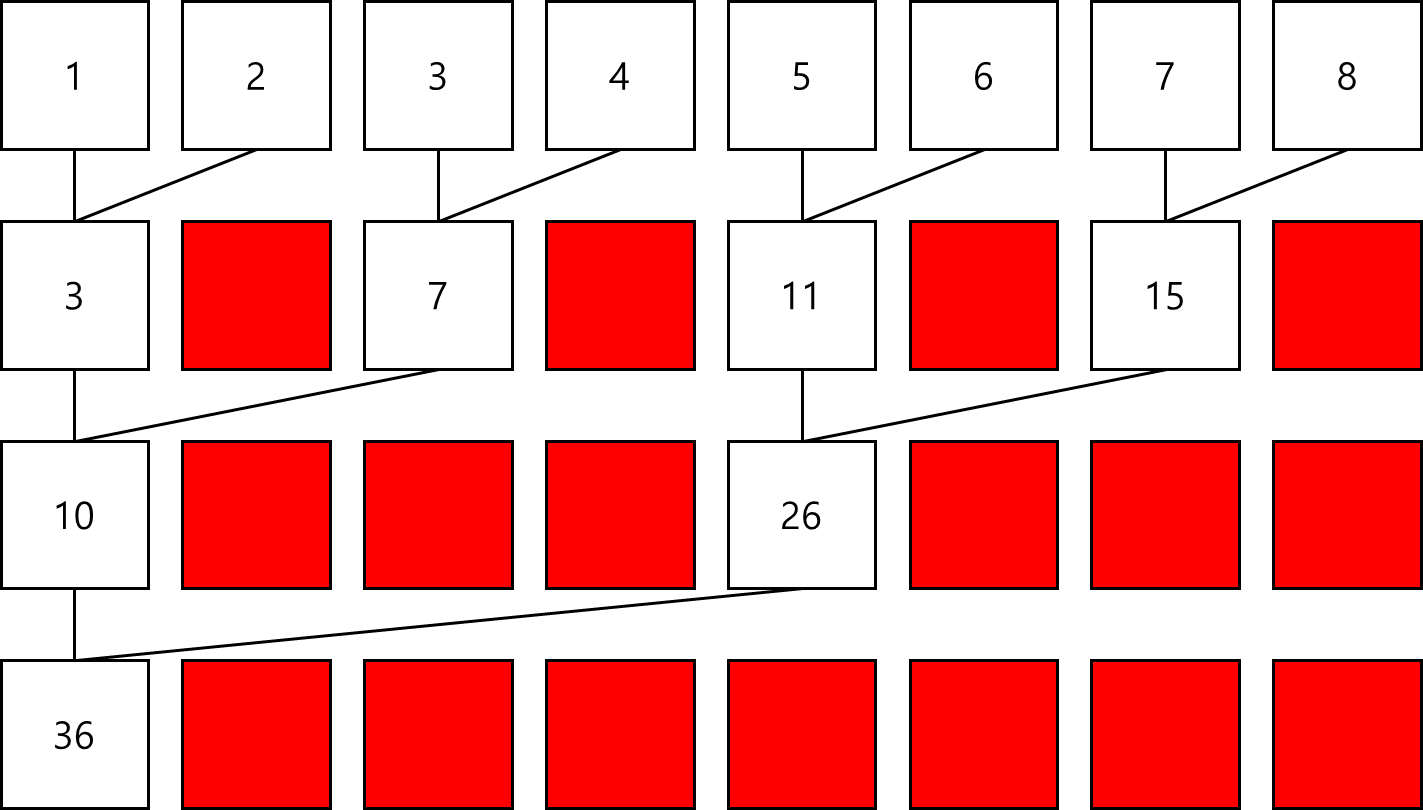
1. Neighbored pair
개의 요소를 가진 배열에 대해 번의 합 및 단계 필요
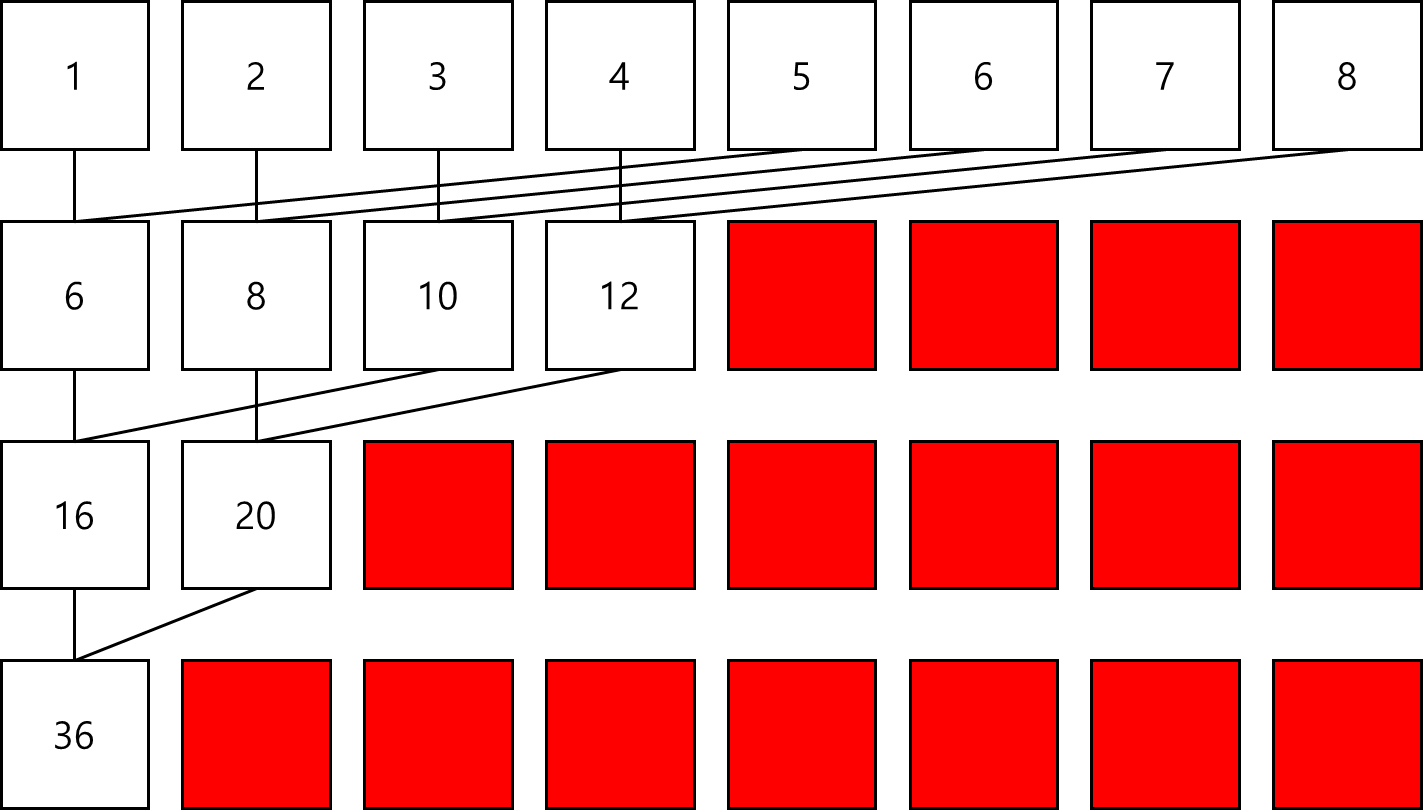
2. Interleaved pair
각 단계마다 thread에 대한 입력이 입력 길이의 절반만큼 건너뜀
덧셈뿐만 아니라, 교환법칙 및 결합법칙이 성립한다면 무엇이든 위 방법은 가능하다. 최댓값을 구하는 예시의 경우, 합계 대신에 최댓값을 호출하면 된다.
이렇게 벡터 전반에 걸쳐 교환법칙과 결합법칙이 성립하는 연산을 수행하는 문제를 Reduction Problem이라고 한다. Parallel Reduction Problem은 Reduction Problem을 병렬로 수행하는 것이다.
Divergence in Parallel Reduction
Neighbored pair에 대해 살펴보겠다. 이 커널에서는, 전체 배열을 줄이기 위한 큰 규모의 global memroy 배열과 각 thread block의 부분합을 저장하는 작은 규모의 global memory 배열이 필요하다. 각 thread block은 배열의 일부를 independent하게 처리한다. 또한, 어떤 loop의 하나의 반복문은 single reduction step을 밟는다.
__global__ void reduceNeighbored(int *g_idata, int *g_odata, unsigned int n) {
// thread ID 설정
unsigned int tid = threadIdx.x;
// global data pointer을 이 block의 local pointer로 변환
int *idata = g_idata + blockIdx.x * blockDim.x;
// boundary check
if (tid >= n) return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
if ((tid % (2 * stride)) == 0) {
idata[tid] += idata[tid + stride];
}
// block 내 synchronization
// 현재 iteration에서 모든 threads의 부분합이 전역 메모리에 저장된 후에야
// 동일한 thread block의 어떠한 thread이든 다음 iteration을 밟도록 함
// 다음 iteration에 진입하는 모든 thread는 이전 단계에서 생성된 값 사용
__syncthreads();
}
// 이 block의 결과를 global memory에 기록
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}이웃한 요소 간 거리 stride 는 처음에 1로 초기화된다. 각 reduction round 후 stride 는 두 배 증가한다. 첫 번째 단계 후, 'idata'의 짝수 번째 요소는 부분합으로 대체된다. 두 번째 단계 후, 'idata'의 4배수의 요소마다 부분합으로 대체된다. thread block 간 synchronization이 없기 때문에 각 thread block에 의해 생성된 부분합은 host로 복사되고, 그 곳에서 순차적으로 더해진다.
Improving Divergence in Parallel Reduction
예시 코드 내 reduceNeighbored라는 커널에서 다음과 같은 조건문이 있다.
if((tid % (2 * stride)) == 0)이 조건문은 짝수 번호 thread에 대해서만 유효하므로, 높은 확률로 divergent warps을 초래한다. parallel reduction의 첫 번째 iteration 단계에서, 짝수 번호의 thread만 이 조건문에 부합하는데, 모든 thread가 스케줄링되어야 한다. 두 번째 iteration 단계에서는 전체 thread의 1/4만 활성화되지만 여전히 모든 스레드가 스케줄링되어야 한다. 각 thread의 배열 인덱스를 재배열하여, 이웃하는 thread가 덧셈 기능을 하도록 강제하여 warp divergence을 줄일 수 있다.덱스를 재배열하여 이웃하는 스레드가 더하기를 수행하도록 강제하여 줄일 수 있습니다. 다음 그림은 이것의 구현을 나타낸 것이며, 앞선 그림과 비교했을 때, 부분합의 저장 위치는 그대로이지만, 작업 스레드가 바뀌었다.
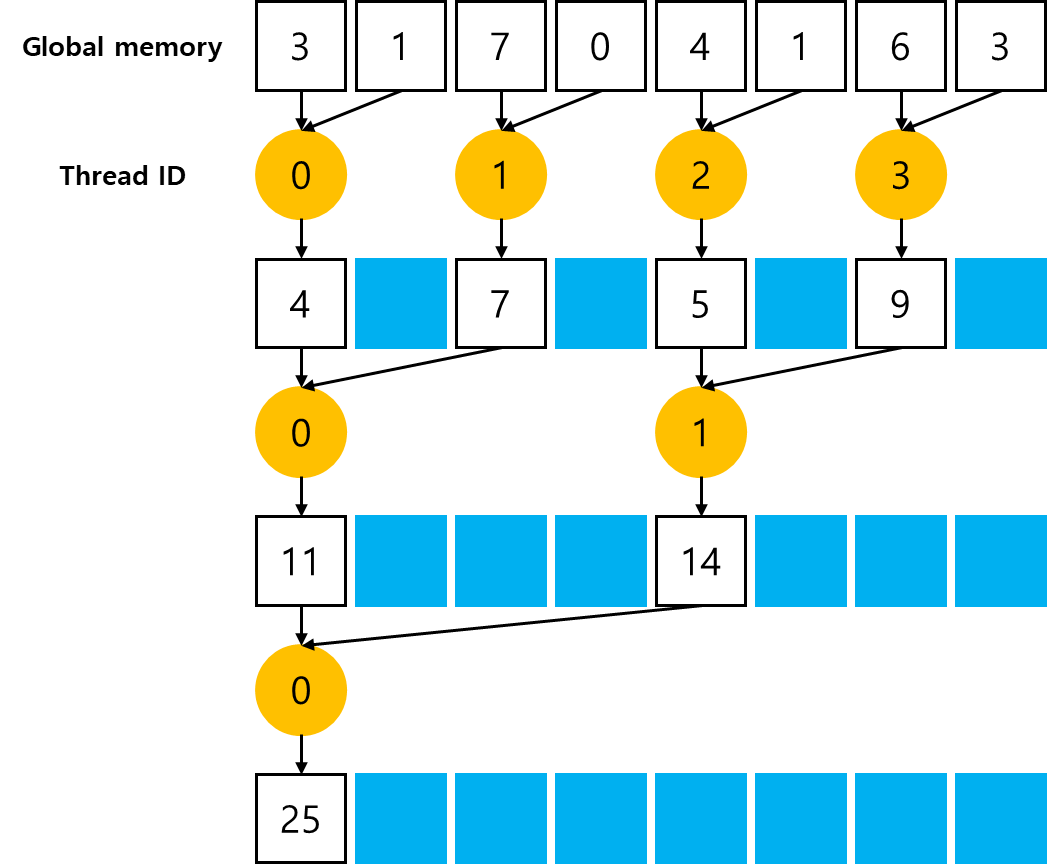
thread block의 크기가 512 thread일 때, 처음 8개의 워프가 첫 번째 round에서 reduction을 실행하고 나머지 8개의 워프는 아무 것도 하지 않는다. 바로 다음 round에서는 처음 4개의 워프가 reduction을 실행하고 나머지 12개의 워프는 아무 것도 하지 않는다. 따라서 마지막 5개의 round에서 각 round의 thread 총수가 warp 크기보다 적을 때만 divergence가 발생한다.
Reducing with Interleaved Pairs
Neighbored Pair을 쓰는 방식과 달리, Interleaved Pair을 쓰는 방식은 elements의 stride을 반전시킨다. stride는 thread block 크기의 절반으로 시작한 다음 각 iteration에서 절반으로 줄어든다.
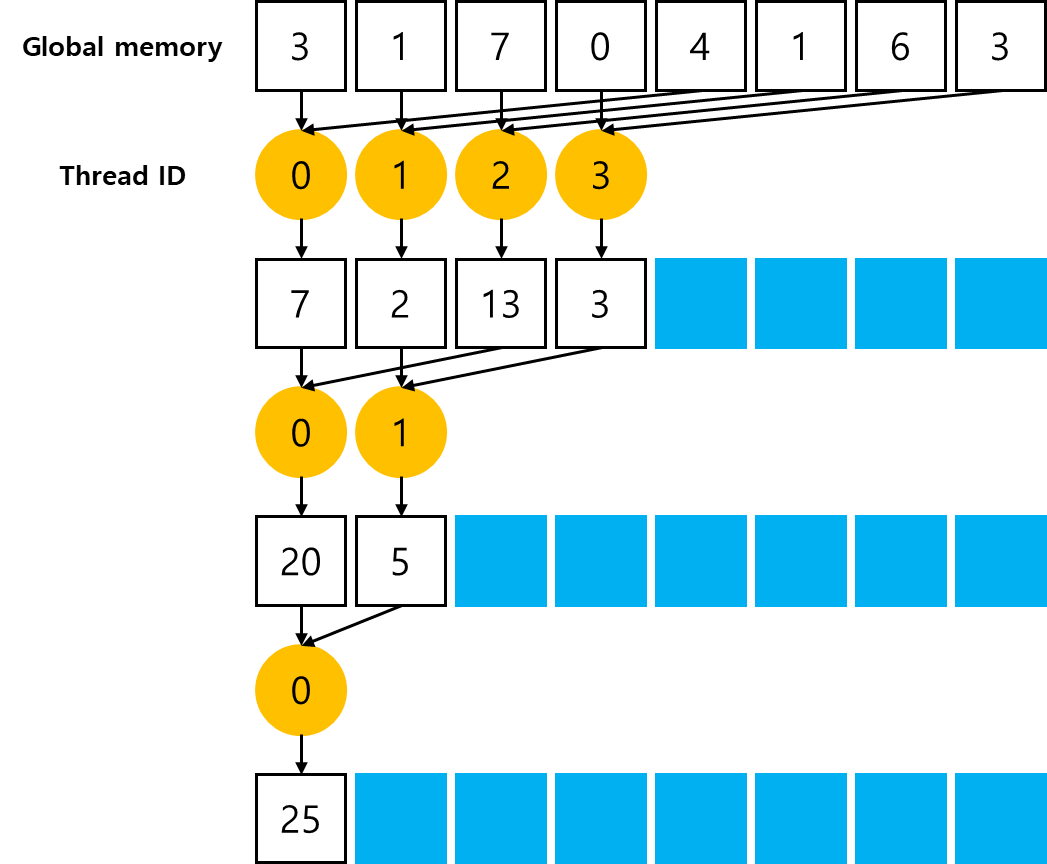
각 thread는 현재 stride로 분리된 두 elements를 더하여 각 라운드에서 부분합을 생성한다. 앞선 목차의 그림과 비교했을 때, interleaved reduction의 작업 thread는 변경되지 않았다. 그러나 각 thread의 global memory에서의 load/store 위치는 다르다.
Unrolling Loops
loop unrolling은 branches와 loop maintenance instruction의 빈도를 줄여 loop 실행을 최적화하려는 기술이다. loop unrolling에서는 본문을 한 번 작성하고 이를 반복 실행하는 것이 아니라, 코드를 여러 개 작성한다. 이에 따라 반복 횟수가 줄어들거나 루프문이 완전히 사라진다. loop 본문의 복사본 수는 loop unrolling factor라고 하는데, loop unrolling factor로 나눈 만큼 loop의 반복 횟수가 줄어든다.
for (int i = 0; i < 100; i++) {
a[i] = b[i] + c[i];
}위 코드의 loop을 unrolling하면
for (int i = 0; i < 100; i+=2) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}loop unrolling으로 성능이 개선되는 이유는 high level에서는 쉽게 알 수 없고, low level instruction 개선과 컴파일러가 unrolled loop에 수행하는 최적화에서 비롯된다.
CUDA에서의 unrolling은 다양한 의미를 가지지만, 종국적으로 목표는 'instruction overhead을 줄이고 더 independent한 instruction을 스케줄링하여 성능을 향상시키는 것'으로 동일하다. 그 결과, 더 많은 동시 작업이 파이프라인에 추가되어 instruction과 memory bandwidth의 포화도가 높아진다. 이는 warp 스케줄러에 더 많은 유효한 warp를 제공하여 instruction 또는 memory latency을 숨기는 데 도움이 된다.
Reducing with Unrolling
Reducing with Unrolled Warps
앞선 코드에서 '__syncthreads'는 block 내 synchronization을 목적으로 사용된다. reduction kernel에서는 각 round에서 모든 thread가 global memory에 부분 결과를 쓰는 것을 완료하기 전에 다음 round로 넘어가지 않도록 하기 위해 사용된다.
그러나 32개 이하의 thread(즉, single warp)만 남아 있는 경우를 고려해보겠다. warp 실행이 SIMT이므로, 각 instruction 이후에는 warp 내 synchronization이 암묵적으로 존재한다. 따라서 reduction loop의 마지막 6개의 iteration을 다음과 같이 unroll할 수 있다.
if (tid < 32) {
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}위 코드를 보면 'vmem' 변수가 'volatile' qualifier로 선언되었다. 이 qualifier는 컴파일러에게 'vmem[tid]'을 각 할당마다 global memory에 다시 저장해야 함을 알려준다. 해당 qualifier을 사용하지 않으면, 컴파일러나 캐시가 일부 global memory 또는 shared memory의 write/read을 최적화하여 생략할 수 있어 코드가 올바르게 동작하지 않을 수 있다.
Reducing with Complete Unrolling
compile time에 loop의 반복 횟수를 알 수 있다면, 이를 완전히 unroll할 수 있다. Fermi 또는 Kepler에서 block 당 최대 thread 수는 1,024로 제한되며, 이 reduction kernel의 loop 반복 횟수는 thread block의 크기를 기반으로 하기 때문에, reduction loop을 완전히 unroll할 수 있다.
Reducing with Template Functions
loop을 수동으로 unrolling할 수도 있지만, CUDA가 제공하는 template 함수를 사용하면 branch overhead을 더욱 줄일 수 있다.
Dynamic Parallelism
지금까지는 모든 커널이 host thread에서 호출되는 형태로 다뤄왔다. GPU workload은 완전히 CPU의 제어 하에 있다. CUDA Dynamic Parallelism은 새로운 GPU 커널이 GPU에서 직접 생성되고 동기화되도록 허용한다.
지금까지는 알고리즘을 개별적으로, 대규모 데이터 병렬 커널 실행으로 표현해야 했다. Dynamic Parallelism은 GPU 커널의 여러 level에서 concurrency을 표현할 수 있는 더 계층적인 접근 방식을 가능하게 한다. 또한, 재귀 알고리즘을 더 투명하고 이해하기 쉽게 만들 수 있다.
한편, Dynamic Parallelism을 사용하면 GPU에서 정확히 몇 개의 블록과 그리드를 생성할지에 대한 결정을 runtime까지 연기할 수 있는데, 이로 인해 GPU Hardware scheduler와 load balancer를 동적으로 활용하고 데이터 기반 결정이나 작업량에 따라 적응할 수 있다.
GPU에서 직접 작업을 생성할 수 있는 기능은 host 및 device 간의 실행 제어 및 데이터 전송 필요성을 줄일 수 있으며, launch configuration이 device에서 실행 중인 thread에 의해 runtime에 이루어질 수 있다.
Nested Execution
Dynamic Parallelism을 사용하면 GPU에서 kernel execution 개념(grid, block, launch configuration 등)을 직접 적용할 수 있으며, 동일한 커널 호출 구문으로 커널 내에서 새로운 커널을 실행할 수 있다. 커널 실행은 parent와 child로 분류되는데, parent thread, parent thread block 또는 parent grid가 child grid를 실행하고, child grid는 parent에 의해 실행된다. 모든 parent grid가 완료되기 전까지 parent thread, parent thread block 또는 parent grid는 완료된 것으로 간주되지 않으며, parent는 모든 child grid가 완료될 때까지 완료된 것으로 간주되지 않는다.
parent grid는 host thread에 의해 구성되고 실행되며, child grid는 parent grid에 의해 구성되고 실행된다. child grid의 호출과 완료는 올바르게 중첩되어야 하는데, 이는 parent grid가 해당 thread에서 생성한 모든 child grid가 완료될 때까지 완료된 것으로 간주되지 않음을 의미한다. thread 호출이, 실행된 child grid에서 명시적으로 동기화되지 않으면, runtime은 parent와 child 간의 동기화를 암묵적으로 보장한다. 그림에서도 parent thread에 child grid와 명시적으로 동기화되기 위한 barrier이 설정되어 있다.
device thread에서 grid 실행은 thread block 전체에서 볼 수 있다. 즉, 어떤 thread가 실행한 child grid에서 다른 thread가 동기화할 수 있다는 의미이다. thread block의 실행은 block 내 모든 threads가 생성한 모든 child grid가 완료될 때까지 완료된 것으로 간주되지 않는다. block의 모든 threads가 모든 child grid가 완료되기 전에 종료되면 해당 child grid에서 동기화가 암묵적으로 작동된다.
parent/child grids는 동일한 global 및 constant memory storage를 공유하지만, 각각 고유한 local 및 shared memory를 가진다. parent/child grids는 global memory에 동시 접근이 가능하며, child와 parent 간에는 약한 consistency guarantee 을 가진다. child grid의 실행에서 child grid가 시작될 때와 완료될 때, parent thread와 메모리의 일관성이 완전히 보장된다. child grid을 호출하기 전에 parent thread에서 수행된 모든 global memory 작업은 child grid에서 볼 수 있다. child grid의 모든 메모리 작업은 child grid가 완료된 후 parent가 해당 child grid의 완료에 대해 동기화한 후에 parent에게 보장된다.
shared memory와 local memory는 각각 thread block 또는 thread 전용이며, parent와 child 간에 표시되거나 일관되지 않는다. local memory는 thread의 전용 storage로, 해당 thread 외부에서는 볼 수 없다. child grid를 실행할 때 local memory의 포인터를 인수로 전달하는 것은 유효하지 않다.
Nested Hello World on the GPU
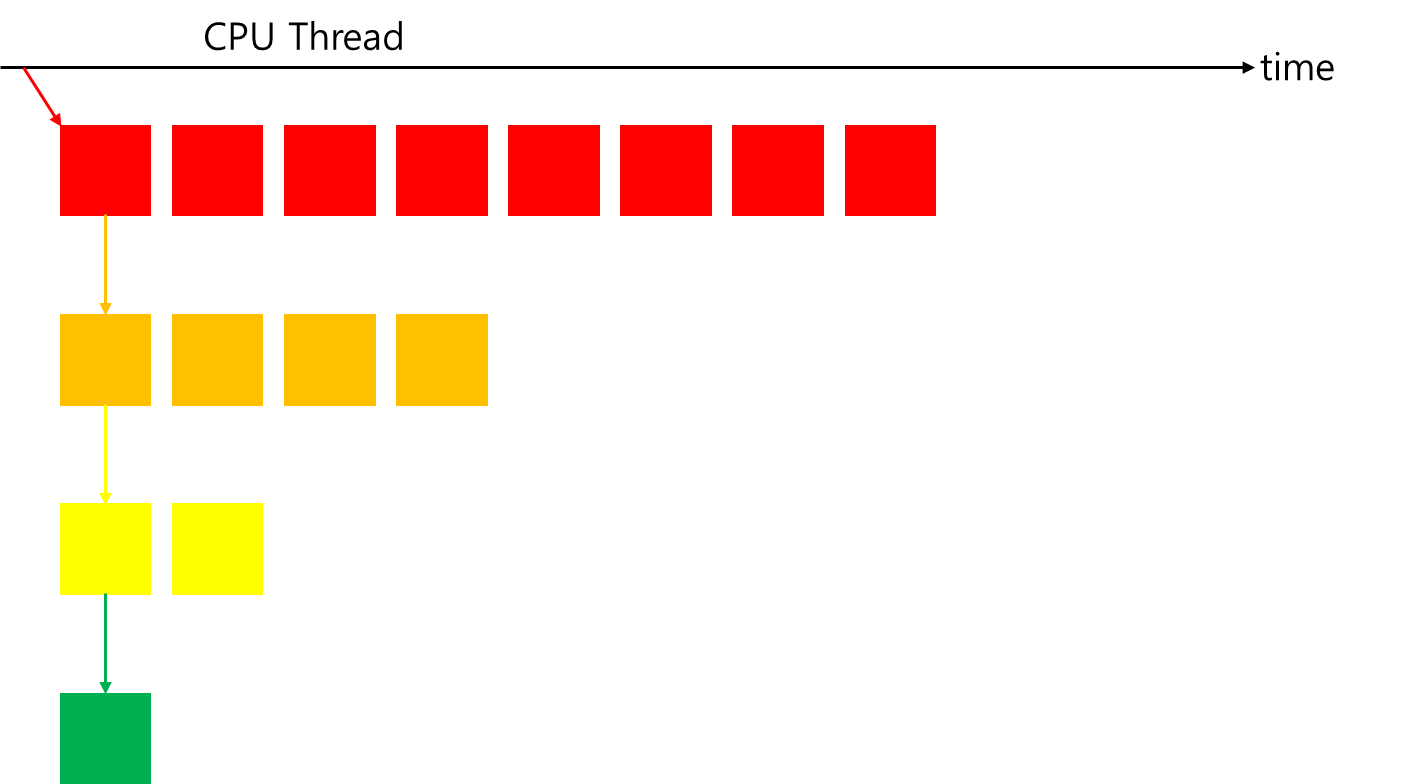
다음 그림은 Dynamic Parallelism를 사용하여 어떤 커널에 의해 구성된 nested recursive execution이다. host application은 single thread block에서 8개의 threads를 사용하여 parent grid를 호출한다. 그 다음, 해당 grid의 thread 0이 child grid를 호출하며, 이 child grid는 절반의 threads를 가진다. 그리고나서, 첫 번째 child grid의 thread 0이 다시 절반의 threads를 가지는 새로운 child grid를 호출한다. 이 과정은 하나의 thread만 남을 때까지 지속된다.
다음 예시는 Dynamic Parallelism으로 "Hello World"를 출력하는 커널이다. 모든 thread에 의한 커널의 실행은 "Hello World"를 출력하는 것으로 시작된다. 그 후, 각 thread는 자신이 종료해야 하는지 확인한다. 이 중첩된 레이어의 thread 수가 1보다 크면, thread 0은 절반의 thread 수를 가지는 child grid를 recursive하게 호출한다.
__global__ void nestedHelloWorld(int const iSize, int iDepth) {
int tid = threadIdx.x;
printf("Recursion=%d: Hello World from thread %d block %d\n", iDepth, tid, blockIdx.x);
// condition to stop recursive execution
if (iSize == 1) return;
// reduce block size to half
int nthreads = iSize >> 1;
// thread 0 launches child grid recursively
if (tid == 0 && nthreads > 0) {
nestedHelloWorld<<<1, nthreads>>>(nthreads, ++iDepth);
printf("-------> nested execution depth: %d\n", iDepth);
}
}결과는 다음과 같다.
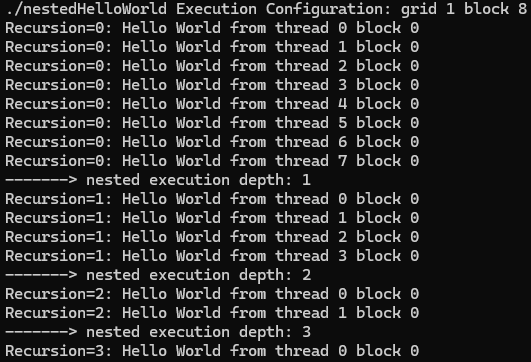
host에 의해 호출된 parent grid가 1개의 block과 8개의 threads를 가지고 있다. nestedHelloWorld 커널은 세 번 재귀적으로 호출되었으며, 각 호출마다 thread 수가 절반으로 줄어들었다.
다음 출력은 parent grid을 하나 대신 두 개의 block으로 호출한 것이다.
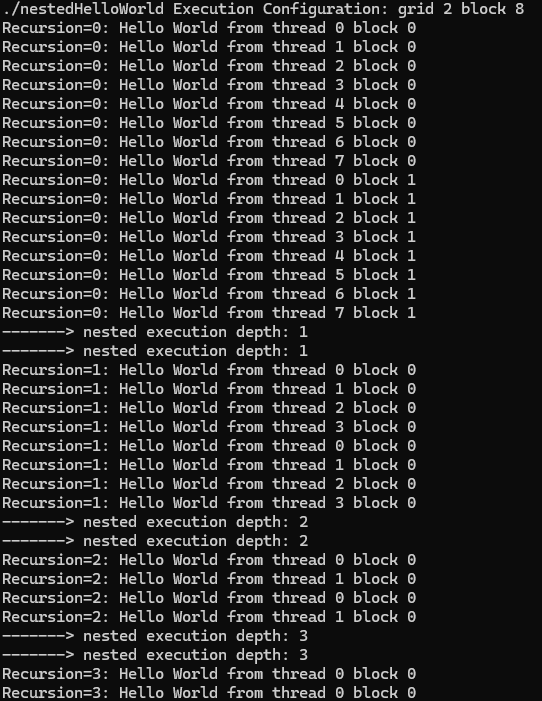
출력 메시지에서 child grid의 block ID가 모두 0이다. 다음 그림은 두 개의 초기 thread blocks으로 child grid가 재귀적으로 호출되는 방식을 보여준다. nestedHelloWorld 내부에서 커널 실행의 thread 구성이 다음과 같으므로, parent grid에는 두 개의 blocks이 있어도 child grid가 호출될 때 항상 하나의 block만 가지도록 한다.
nestedHelloWorld<<<1, nthreads>>>(nthreads, ++iDepth);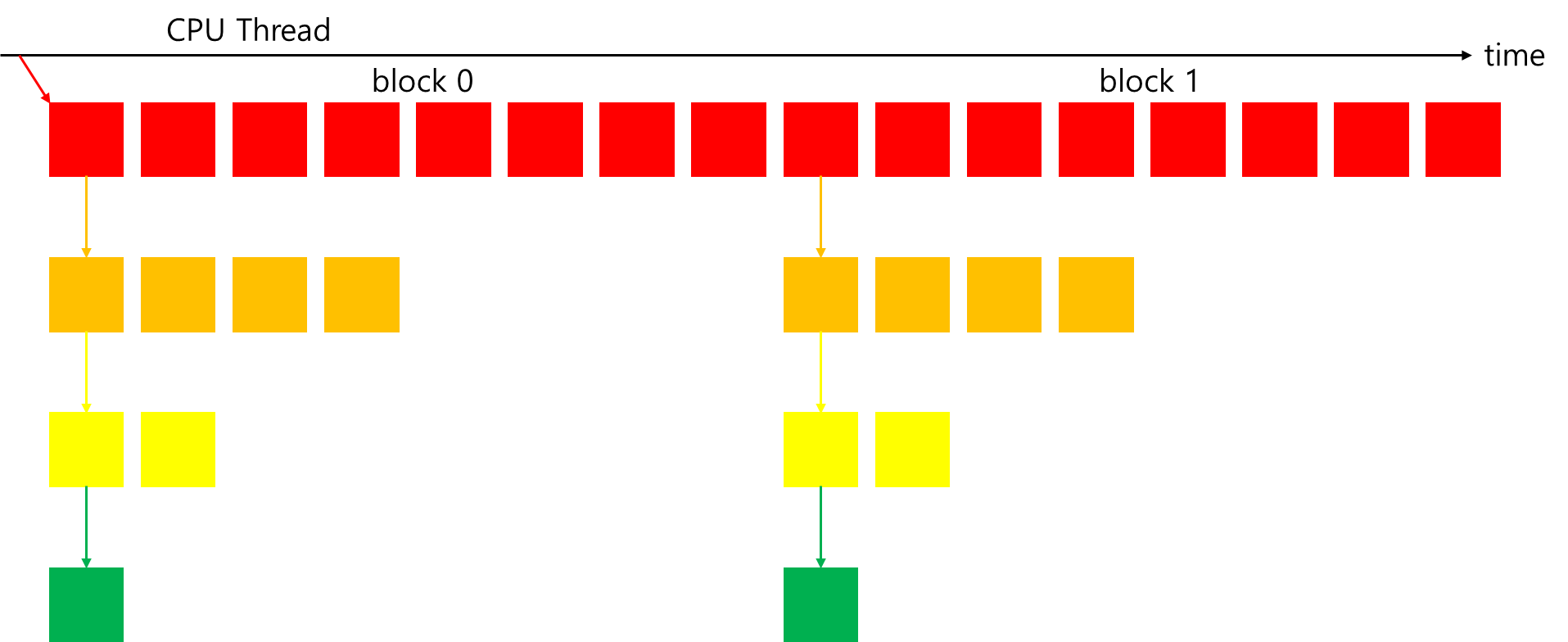
Nested Reduction
CUDA에서 Dynamic Parallelism으로 CUDA의 recursive reduction kernel을 다음과 같이 간단하게 구현할 수 있다.
__global__ void gpuRecursiveReduce (int *g_idata, int *g_odata, unsigned int isize) {
// set thread ID
unsigned int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = &g_odata[blockIdx.x];
// stop condition
if (isize == 2 && tid == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// nested invocation
int istride = isize >> 1;
if(istride > 1 && tid < istride) {
// in place reduction
idata[tid] += idata[tid + istride];
}
// sync at block level
__syncthreads();
// nested invocation to generate child grids
if(tid == 0) {
gpuRecursiveReduce <<<1, istride>>>(idata, odata, istride);
// sync all child grids launched in this block
cudaDeviceSynchronize();
}
// sync at block level again
__syncthreads();
}위 커널의 첫 번째 단계에서 global memory 주소 g_idata 을 각 thread block에 local address로 변환한다.
이후, 이 커널이 nested execution tree의 leaf node라는 종료 조건이 충족되면, 결과가 global memory로 복사되고 제어가 즉시 parent 커널로 반환된다. 종료 조건이 불충족되면, local reduction의 크기가 계산되고 절반의 thread가 in-place reduction을 수행한다. in-place reduction이 완료되면 block이 동기화되어 모든 부분합이 계산되었는지 확인한다.
그런 다음, thread 0이 현재 block의 절반 크기의 thread를 가지는 하나의 thread block을 포함하는 child grid를 생성한다. child grid가 호출된 후, 모든 child grid에 대한 barrier point가 설정된다. 각 block의 하나의 thread에 의해 하나의 child grid만 생성되므로, 이 barrier point는 하나의 child grid와만 동기화된다.
처음에는 2,048개의 blocks이 있는데, 각 block이 8번의 recursion을 수행하므로, 16,384개의 child block이 생성되었고, block 내 동기화(__syncthreads)도 16,384번 호출되었다. 이러한 대량의 커널 호출과 동기화는 커널 성능이 저조한 주요 원인으로 작용할 가능성이 크다.
child grid가 호출될 때, 그 메모리 뷰(프로그램이 메모리에 접근하고 해석하는 방식)는 parent thread와 완전히 일치한다. 각 child thread는 부분 reduction을 수행하기 위해 parent의 값만 필요로 하므로, child grid를 호출하기 전에 수행되는 block 내 동기화는 불필요하다. 모든 동기화 작업을 제거하면 다음과 같다.
__global__ void gpuRecursiveReduceNosync (int *g_idata, int *g_odata, unsigned int isize {
// set thread ID
unsigned int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = &g_odata[blockIdx.x];
// stop condition
if (isize == 2 && tid == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// nested invocation
int istride = isize >> 1;
if(istride > 1 && tid < istride) {
idata[tid] += idata[tid + istride];
if(tid == 0) {
gpuRecursiveReduceNosync<<<1, istride>>>(idata,odata,istride);
}
}
}그러나 성능은 여전히 neighbor-paired 커널과 비교할 때 저조하다. 이번에는 많은 자식 그리드 호출로 인한 오버헤드를 줄이는 방법을 제안한다. 현재 구현에서는 각 block이 child grid를 생성하여 엄청난 수의 호출이 발생한다. 대신 다음 그림과 같은 방식을 사용하면, child grid당 thread block 수가 증가하고 생성되는 child grid 수가 줄어들어 동일한 규모의 병렬성을 유지할 수 있다.
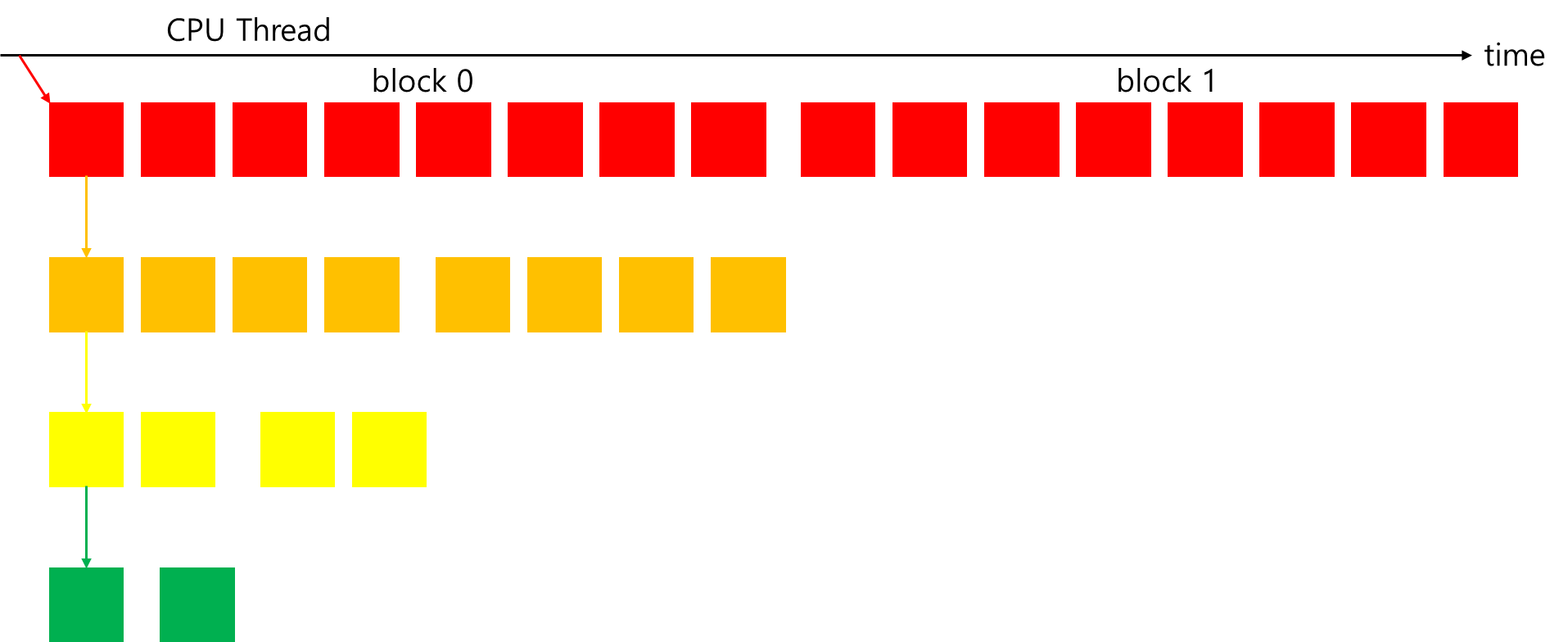
위 방식으로 개선된 코드는 다음과 같다. grid의 첫 번째 block의 첫 번째 thread가 각 중첩 단계에 대해 child grid를 호출한다. 각 nested invocation에서 child block 크기가 parent block 크기의 절반으로 줄어들기 때문에, parent block의 차원을 중첩된 child grid에 전달해야 한다. 이를 통해 각 thread는 자신의 작업 부분에 대한 올바른 전역 메모리 오프셋을 계산할 수 있다. 첫 번째 구현과 비교하면 각 중첩 레벨에서 커널 실행 중 절반의 thread가 유휴 상태인 대신, 모든 유휴 thread가 각 커널 호출에서 제거된다. 이러한 변화로, 첫 번째 커널이 소비한 compute resource의 절반이 해제되어 더 많은 thread block이 활성화될 수 있다.
__global__ void gpuRecursiveReduce2(int *g_idata, int *g_odata, int iStride, int const iDim) {
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * iDim;
// stop condition
if (iStride == 1 && threadIdx.x == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// in place reduction
idata[threadIdx.x] += idata[threadIdx.x + iStride];
// nested invocation to generate child grids
if(threadIdx.x == 0 && blockIdx.x == 0) {
gpuRecursiveReduce2 <<<gridDim.x, iStride/2>>>(g_idata, g_odata, iStride/2, iDim);
}