Mac, VM VirtualBox, WSL 모두에서 가능하다.
나는 wsl2에서 진행했다.
# 안해도 상관없는 과정
# hadoop용 user 추가
$ sudo addgroup bigdata
$ sudo adduser --ingroup bigdata hadoop
$ sudo adduser hadoop sudo
$ sudo apt-get install openssh
# su: 현 사용자를 로그아웃하지 않고, 다른 사용자의 권한을 획득할 때 사용
$ su - hadoop# java install
$ sudo apt-get install openjdk-8-jdk
# java 설치 확인 가능
$ java -version# hadoop 파일 다운로드
$ wget http://mirror.apache-kr.org/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
$ tar -xvzf hadoop-2.7.7.tar.gz# ssh
$ sudo apt-get install ssh
$ sudo service ssh restart
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
$ ssh localhost
# 접속되는거 확인했으면 나가기
$ exit# .bashrc에 환경변수 추가
$ vi ~/.bashrc
### .bashrc에 추가할 내용
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 # 설치한 java 버전으로 입력
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7 # 설치한 hadoop 버전으로 입력
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
$ source ~/.bashrcvi로 파일 수정하는 방법 모르는 사람을 위해,
i를 누르면 insert mode로 변환됨
내용 입력 후 esc누르면 insert mode 종료
:wq 입력(저장 후 종료)
# hadoop-env.sh 내용 변경
$ vi /home/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
### export JAVA_HOME 있는 부분 찾아서 아래 내용으로 변경
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 # .bashrc에 입력한 JAVA_HOME과 동일의사분산모드 환경설정이다.
single node cluster. 모든 하둡 데몬을 로컬 머신에서 실행한다. 따라서 작은 규모의 클러스터에서 실행하는 것과 같은 효과가 있다.
# HADOOP_HOME 에서 모두 진행
$ vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>$ vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
$ vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>$ vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>환경 설정을 끝냈다.
이제 namenode를 포맷하고 데몬들을 키고 하둡 연습을 해보자.
아래 과정은 ssh localhost 접속 후 실행했다.
namenode format은 최초 1회만 해야한다.
하지만 분명 설치에서 수많은 오류를 만나며,,,포맷을 또 시도하고 시도해야 하는 상황이 분명히 올것임 😥
그러면 logs파일을 삭제하고 포맷하면 된다. (logs파일의 default경로는 '$HADOOP_HOME/logs')
# format namenode
$ bin/hadoop namenode -foramt# run DFS daemons
$ sbin/start-dfs.sh
$ jps
Jps
NameNode
DataNode
SecondaryNameNode
# run YARN daemons
$ sbin/start-yarn.sh
$ jps
SecondaryNameNode
DataNode
Jps
ResourceManager
NameNode
NodeManager
# DFS와 YARN daemons 모두 한번에 키고 끄기
$ sbin/start-all.sh
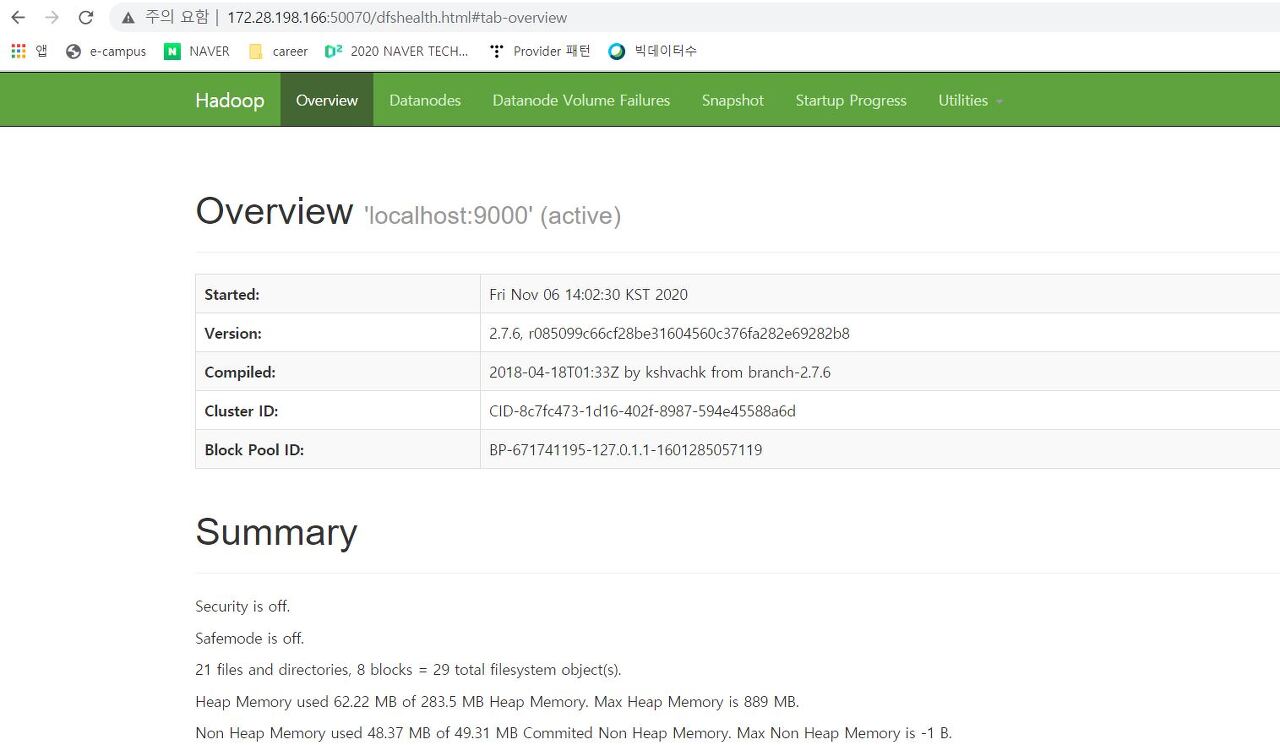
$ sbin/stop-all.sh이제 daemon을 켰으니, localhost:50070 (hadoop-3.0.0 부터는 localhost:9870 으로 바뀜) namenode web ui 접속할 수 있다.
localhost:8088 으로 resource manager web ui 접속이 가능하다.
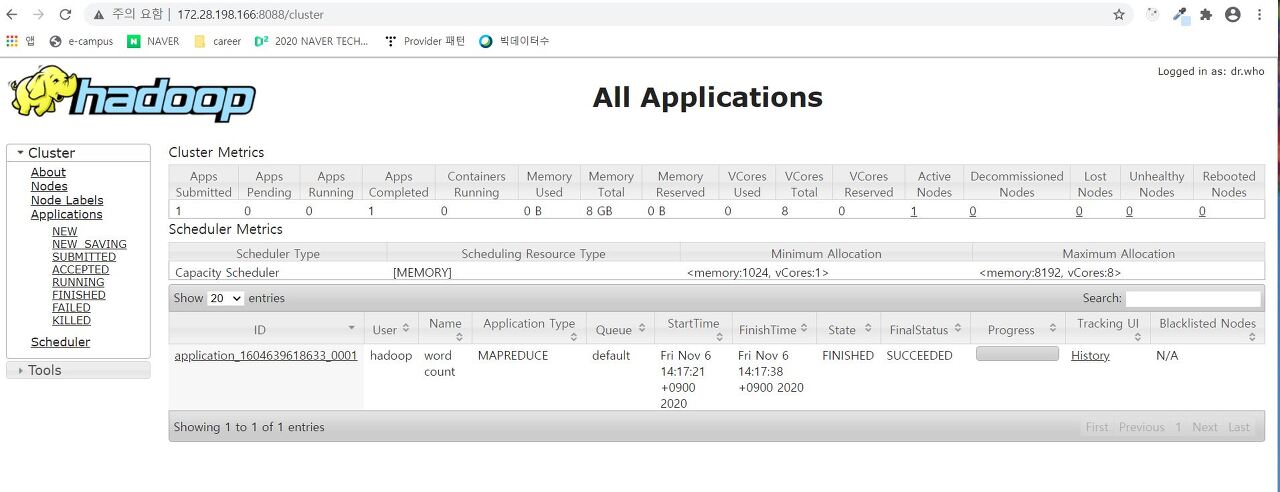
8088포트로 접속했을 때 지금 나는 완료된 task가 하나 있는데 이것은 wordcount를 해봐서 그렇다. 시작해보자.
# daemon을 키면 하둡 파일들을 확인할 수 있다
# 데이터를 저장할 디폴트 폴더 만들기 (디폴트로 만들어서 추후에 바로 접근 가능)
$ hdfs dfs -mkdir -p /user/hadoop
# 안되면 bin/hadoop ~~~
# 데이터 넣기
$ hdfs dfs -put README.txt
# $ hadoop dfs -put 로컬파일경로 hdfs경로에만들파일경로
# list 확인
$ hdfs dfs -ls /user
(또는 hdfs dfs -ls hdfs://localhost:9000/user)
# file or directory 삭제
$ hdfs dfs -rm 파일이름
$ hdfs dfs -rm -r 디렉토리이름# wordcount 실행예제
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount README.txt output_wc
# .jar 뒤에는 인풋파일이름(bin/hadoop fs -ls 했을 때 뜨는 input file)과 원하는 아웃풋파일이름을 적어준다그리고 음,,,,, 빅데이터수업 들으면서 교수님이 외부노드로 접속해 있다면 tunneling이 필요하다고 했는데
ssh -L 50070:localhost:50070 -L 8088:localhost:8088 username@본인ip주소내 상황에서는 딱히 필요 없는 것 같다 사실 외부노드로 접속한다는게 뭔지 잘 모르겠다ㅎㅎㅎㅎㅎㅎ
reference
1. https://www.notion.so/Hadoop-3aa81e72270c41108126579143b123ae
2. 책- 하둡 완벽가이드 4판. 부록A
3. https://www.youtube.com/watch?v=ZnrtnFEz22E
4. http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
