
1️⃣ JPA 연관 관계
JPA에서 꽃이라고 부를 수 있을 만큼 중요한 부분입니다.
✅ 연간관계란?
객체와 테이블의 외래 키(FK)를 어떻게 연결할 것인가? 를 결정짓는 부분입니다.
크게 단방향/양방향, Collection 관계, 즉시 로딩, 지연 로딩, Cascade/OrphanRemoval 등의 전략이 있습니다.
📌단방향 연관관계란?
한 객체가 다른 객체를 참조하지만, 역으로는 참조하지 않는 관계입니다.
코드로 예를 볼까요?
@Entity
public class Team {
@Id
@GeneratedValue
private Long id;
private String name;
}@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "team_id") // 외래 키 컬럼 지정
private Team team; // 객체 참조
}위와 같은 엔티티 구조가 존재할 때 Member은 Team을 알고 있지만, Team은 Member을 모릅니다.
또한 @ManyToOne 을 통해서 Many = Team, One = Member이라고 생각하면,
하나의 회원은 한팀에 소속할 수 있습니다.(N:1 관계) 위의 어노테이션을 통해 다대일 관계임을 JPA에 알려줍니다.
위에 따르면, member.getTeam() 은 가능하지만, team.getMember()은 불가능합니다!
📌 양방향 연관관계란?
양쪽의 클래스 모두 서로의 객체를 참조하는 관계입니다.
@Entity
public class Team {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
}@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id") // 외래키 주인!!
private Team team;
}양방향 연관관계에서 중요한 것은 주인 입니다. 헷갈리기 쉽지만 따라와 봅시다.
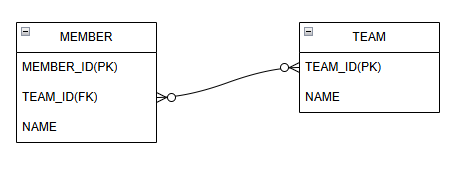
위 데이터베이스 테이블을 보면, MEMBER 테이블에는 TEAM_ID가 존재하지만, TEAM에는 MEMBER 정보가 존재하지 않습니다. 왜 그럴까요?
🎯 연관관계의 주인이란?
DB에 있는 외래 키를 관리하는 쪽으로, DB 변경(INSERT, UPDATE) 를 실제로 수행하는 엔티티 필드를 의미합니다.
위의 코드에서 Member 엔티티가 외래 키 (team_id)를 가지고 있으므로, 주인은 Member.team 입니다.
왜 주인이 중요할까요?
JPA 에서는 양방향 연관관계가 있을 때, 양쪽 다 엔티티 객체에 값을 세팅했다고 해서 DB에 반영되지 않습니다.
Team team = new Team();
Member member = new Member();
team.getMember().add(member); // 비주인 쪽만 설정
// member.setTeam(team); 은 안함
em.persist(team);
em.persist(member);위의 코드를 실행하면, 비주인은 단순 읽기 전용 필드이기에
DB에 team_id 값은 null로 들어갑니다.(외래 키 설정이 안됨)
왜냐하면 JPA는 주인 필드에 의존해 연관관계를 처리하게 됩니다.
@mappedBy를 이용하여 주인임을 명시합니다!
연관 관계의 주인이 아닌 쪽에서 사용하는 속성으로, 주인이 되는 필드명을 지정하는 것 입니다.
즉, 내가 주인이 아니라 저쪽이 주인이야. 라고 선언하는 것 입니다.
mappedBy 를 사용하지 않으면, 양쪽 다 외래 키를 관리하게 됩니다.
만약 둘 다 주인이게 된다면, 무결성 문제가 생겨 Team 객체에서도 member 필드를 통해 테이블에 접근이 가능하게 되어 혼란이 생기게 됩니다. 또한 불필요한 중복 INSERT/UPDATE 가 발생 가능합니다.
-
@OneToMany↔@ManyToOne: 일대다 양방향멤버는 한 팀에 소속될 수 있고, 한 팀은 여러 멤버가 존재합니다.
@ManyToOne이 외래키를 가집니다.이는 N 쪽에서 1 을 참조하는 구조이기에, 외래키는 항상 N 쪽 테이블에 생성됩니다. 따라서
@ManyToOne이 외래 키를 가지는 주인입니다.@AToB에서 A 자리를 현재 클래스를 기준으로 적으면 됩니다.
-
@OneToOne: 1:1 양방향한 명의 회원은 하나의 주소를 가지고, 주소도 한 명의 회원에만 소속됩니다.
외래 키는 주인 쪽에만 존재하며, 지정하지 않으면, 중복 FK가 생길 수 있습니다.
-
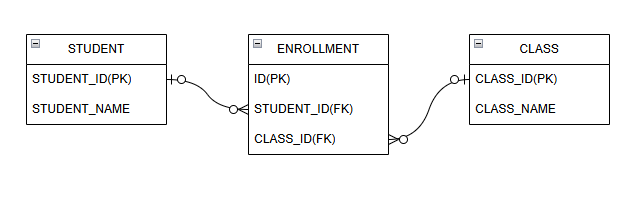
@ManyToMany: N:N 양방향한 명의 학생은 여러 강의를 수강할 수 있고, 하나의 강의도 여러 학생이 수강할 수 있습니다.
그러나! N:N 양방향은 추적 및 확장이 어렵기 때문에 @OneToMany로 풀어 매핑하는 것이 일반적 입니다.
중간 테이블을 놓아서 아래와 같이 처리하는 것을 권장합니다.
2️⃣ 즉시 로딩과 지연 로딩
✅ FetchType 이란?
이후 나올 N+1, 지연 로딩과 관련된 이슈와 직결되기에 꼭 이해하고 넘어가야 합니다.
FetchType 이란, JPA에서 연관된 엔티티를 언제 로딩할 지 결정하는 전략입니다.
즉, A라는 엔티티가 B 엔티티를 참조하고 있을 때, A를 조회하면서 B를 같이 가져올 지, 아니면 나중에 필요할 때 가져올 것인지 결정하는 설정입니다.
✅ 즉시 로딩(FetchType.EAGER)
엔티티를 조회할 때, 연관된 엔티티도 즉시 함께 조회한다. (즉시 JOIN)
언젠가 필요할 수 있으니까 모든 것을 즉시 로딩하는게 좋을까? → 🙅 절대 안됩니다!
즉시로딩을 사용하면 연관된 모든 엔티티를 즉시 로딩하기에, 성능 문제가 발생합니다!
따라서 연관 관계는 지연 로딩을 사용하는 것이 적절합니다.
✅ 지연 로딩(FetchType.LAZY)
연관된 엔티티를 실제로 접근할 때 쿼리를 실행해서 가져온다.
@Entity
public class Member {
@ManyToOne(fetch = FetchType.LAZY)
private Team team;
}Member member = em.find(Member.class, 1L); // 이 시점에는 team 쿼리 실행 x
member.getTeam().getName(); // 이 시점에서 team에 대한 쿼리가 나간다.따라서 실무에서는 @ManyToOne(fetch = FetchType.LAZY) 를 명시적으로 선언하는 것을 권장합니다.
3️⃣ N+1 문제
✅ N+1 문제란?
1번의 쿼리로 N개의 결과를 가져왔는데, 그로 인해 추가로 N 번의 쿼리가 더 발생되는 문제
이해하기 쉽게 예시로 설명하겠습니다
@Entity
public class Member {
@ManyToOne(fetch = FetchType.EAGER)
private Team team;
]List<Member> members = em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
for (Member member : members) {
Team team = member.getTeam(); // LAZY Loading
]위의 쿼리문을 실해하게 되면 먼저 Member를 모두 조회하게 됩니다.(1번 실행)
그리고 루프를 돌면서 member.getTeam().getName() 을 실행합니다.(FetchType.EAGER 이기 때문)
따라서 각 member 마다 Team을 조회하는 쿼리가 N 번 더 실행하게 되어, 총 쿼리가 N+1 번 발생합니다.
JPA 에서는 관게를 맺은 엔티티는 기본적으로 fetch=FetchType.LAZY 로 설정되게 됩니다.
따라서 연관된 데이터를 처음에는 로딩하지 않고, 실제 사용될 때 쿼리를 실행하게 되어 지연 로딩으로 인해 발생하게 됩니다.
왜 N+1 문제가 발생하면 안될까요?
데이터 양이 현저히 적으면 상관이 없지만,
멤버수가 10명 → 쿼리 수 11개
멤버수가 100,000명 → 쿼리 수가 100,001개
로 데이터 베이스 쿼리가 많아지면서 성능 저하가 발생하게 됩니다.
특히 연관된 엔티티가 많을 수록 DB 부하가 심각해져, 네트워크 비용이나 트랜젝션 시간이 증가하는 문제가 발생합니다.
✅ 해결 방법
1️⃣Fetch Join 으로 해결하기
root entity에 대해 조회 시 지연 로딩으로 설정 되어 있는 연관 관계에 대해 Join 쿼리를 발생시켜 한 번에 조회할 수 있으나, 단점으로는 jpql을 매번 작성해야 합니다.
📌 일반 Join 과 Fetch Join 차이점
- 일반 Join
SELECT m FROM Member m JOin m.team t일반 join의 예시로 단순히 조인만 실행합니다. 여전히 team은 LAZY 로딩일 수 있어, getTeam() 호출 시 추가 쿼리가 발생합니다.
- Fetch Join
SELECT m FROM member m JOIN FETCH m.teamteam을 즉시 로딩 합니다. 즉, 쿼리 한 번에 Member와 Team을 모두 가져옵니다.
그 이후 member.getTeam()을 해도 추가 쿼리가 발생하지 않습니다.
Fetch Join을 통해 조회 시, 연관 관계는 영속성 컨텍스트 1차 캐시에 저장되어 다시 탐색하더라도, 조회 쿼리가 발생하지 않습니다.
- 참고로 JPQL 이 복잡해 질 수 있고, 동적으로 사용하기 불편하며, 컬렉션 조인 시 불리하다는 단점이 존재합니다.
2️⃣@EntityGraph 으로 해결하기
@EntityGraph 는 JPA 에 도입된 기능으로, 연관된 엔티티를 즉시 로딩 할 수 있도록 지정하는 방법입니다.
SQL 문을 직접 작성해야 하는 것이 1번의 귀차니즘 이었는데! 이를 작성하지 않아도 연관관계를 fetch join 처럼 한 번에 불러오도록 설정 가능합니다.
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();- attributePaths = {”team”} 을 통해서 team 연관 객체를 함께 가져오겠다 는 의미를 가집니다.
- 따라서 내부적으로 fetch join처럼 작동하게 되어 findAll() 을 호출하면, Team도 함께 조회하게 됩니다.
fetch Join 은 collection 과 함께 사용하면 페이징이 안되기 때문에 더 유리할 수 있습니다!
다만, @EntityGraph 로 컬렉션 로딩은 가능하지만, 이 경우 중복 데이터나 페이징 불가 문제가 생길 수 있습니다. → @BatchSize 또는 hibernate.default_batch_fetch_size 로 해결하는 게 더 유리 할 수 있습니다.
3️⃣Batch Size 으로 해결하기
JPA 에서 제공하는 기능으로, 연관된 엔티티를 일정한 크기의 batch 로 로드하는 방법입니다.
JPA(Hibernate) 는 LAZY 로딩 시 연관된 엔티티를 하나식 쿼리로 불러오는데, 이 때 쿼리 호출을 모아서 한 번에 처리할 수 있도록 도와주는 설정입니다.
→ 즉, 여러 개의 findById 를 IN 절로 묶어주는 것과 유사한 동작 입니다.
- Annotation 개별적으로 설정하기
@ManyToOne(fetch = FetchType.LAZY)
@BatchSize(size = 100)
pricate Team team;- 전역 설정 (application.yml)
spring:
jpa:
properties:
hibernate.default_batch_fetch_size: 100예를 들어 1000명의 Member을 조회하고 각 Member의 team을 지연 로딩 해야 한다면,
기본 LAZY 로딩으로는 1000번의 쿼리가 발생하고,
Batchsize 를 100으로 설정한다면, SELECT * FROM team WHERE id IN (?,?,…?) 으로 총 10번의 쿼리가 발생합니다.
참고로 Batch Size 는 Fetch Join 이 아닌, LAZY Loading 을 최적화 하는 전략입니다.
따라서 Batch Size가 너무 크면, 한 번에 로드되는 데이터 양이 많아져 메모리 사용량이 증가합니다.
너무 작다면, 많은 수의 쿼리 값이 발생해 적절히 설정해야 합니다.
