
Yolo Site: https://pjreddie.com/darknet/yolo/
Yolov2 paper: https://arxiv.org/pdf/1612.08242.pdf
욜로v1의 단점을 보완해서 나온 욜로v2는 더 빠르고 강하고 좋다고 하는데 이번 논문도 읽기 전에 기대가 많이 된다.
Abstract
- Yolo9000: 9000개의 객체 카테고리를 감지함
- 첫번째, 욜로 디텍션 방법이 향상됨
Yolov2는 Faster Rcnn, SDD같이 뛰어난 퍼포먼스를 보이고 빠르다 - 두번째, object detection과 classification을 합쳐서 훈련하는 방법을 제안함
yolo9000을 훈련 시킬때 coco 데이터셋과 ImageNet 분류 데이터 셋을 동시에 학습시킴
라벨링 되지 않은 데이터의 클래스를 예측하게 됨
욜로는 9000개가 넘는 객체 카테고리를 예측한다 그래서 실제로 가용될 수 있다
Figure 1


- yolo 9000은 실시간으로 다양한 객체 클래스를 감지할 수 있다
- 객체 인식은 빠르고 정확했지만 이 방법은 여전히 객체의 작은 세트로 구성되었다
- 최근 객체 인식 데이터셋이 분류나 태깅같은 과제의 데이터 셋과 비교했을때 부족했다
- 디텍션 데이터 셋은 이미지, 태그가 엄청 많고 분류 데이터 셋은 수천가지의 카테고리가 있다
- 디텍션 시스템의 범위를 확장하려고 분류 데이터를 결합해 사용했다
Joint training algorithm
- detection data와 classification data 모두 객체 인식을 훈련시킬 수 있는 알고리즘
- 라벨링 된 디텍션 이미지에서 정확하게 객체가 어디에 위치해있는지를 학습하는데 이때, 분류 이미지의 단어와 견고성을 높이는데 사용했다
- 이 방법을 YOLO9000에 훈련시키고 9000개의 다른 객체 카테고리를 감지했다
How to
- 기존 yolo 시스템을 베이스로 yolov2를 만든다
- 그 다음 데이터셋 컴비네이션 방법과 joint training algorithm을 모델을 훈련하는데 쓴다
(데이터는 ImageNet의 9000개의 클래스와 COCO데이터 셋을 사용함)
Better
- fast rcnn과 비교해서 기존 욜로의 문제는 Localization errors(여러개 물체가 겹쳐있을때 객체의 위치를 잘 찾지 못함)를 가지고 rigion proposal-based method에서 낮은 recall을 가짐
즉, 분류 정확도를 유지하면서 recall과 Localization을 높히는 것에 초점을 맞췄다
yolov2는 빠르면서 정확한 디텍터를 하게 만들었는데 네트워크 크기는 심플하고 학습은 쉽게 했다
1. Batch Normalization
- 다른 정규화 형식이 필요성을 제거하면서 convergence(수렴)를 상당히 개선함
- conv layer에 배치 정규화를 추가하면서 mAP가 2% 상승함
mAP
- 객체 탐지 정확도 평가지표
- ap는 0~1사이에 recall에 대응하는 평균 precision
- ap가 높을수록 알고리즘 성능이 전체적으로 우수하다는 것
- 이러한 ap들을 평균을 낸게 mAP
- BN은 모델의 정규화를 도와주기때문에 dropout없이 모델 과적합을 막아준다
2. High Resolution Classifier
- 기존 yolov1은 해상도가 낮았다
- yolov2를 위해서 ImageNet 데이터를 사용해 분류 네트워크를 448x448해상도로 10에포크로 파인튜닝했다
- 이를 통해 네트워크 해상도가 높아지고 더 좋아지게 수정됐다
- 그 다음 디텍션 네트워크에도 파인튜닝을 했고 mAP가 거의 4% 증가 했다
3. Convolutional with Anchor Boxes
- yolo는 bbox coordinates를 fully connected layer에서 직접적으로 구하는 반면에 faster rcnn은 RPN(region proposal network)를 사용해서 앵커박스의 confidences와 offsets으로 예측함
- 그래서 faster rcnn은 예측층이 컨볼루셔널 하기때문에 RPN이 피처맵의 모든 위치에서 맞아떨어지는 것을 예측한다
- predicting offsets이 문제를 간단하게 만들고 네트워크 학습시키는 것을 쉽게 만든다
욜로의 fully connected layer를 제거하고 앵커박스를 바운딩 박스를 예측하는데 사용함
- 높은 해상도를 만들어주는 one pooling layer를 제거함
- 416의 인풋이미지를 사용하기 위해 네트워크를 줄임
앵커 박스를 사용하고 정확도가 약간 줄었다
- 욜로는 한 이미지안에 98개의 박스들만 예측했는데 앵커박스를 쓰니까 1000개가 넘게 예측한다
- mAP는 약간 줄었지만 recall값이 향상되었다
4. Dimension Clusters
- 욜로에 앵커박스를 사용하면서 2가지 문제가 생겼는데 첫번째는 박스 차원을 직접 골랐고 박스들이 수정되면서 네트워크를 학습할수 있었지만 만약 우리가 더 좋은 priors를 고르면 네트워크를 학습시키는데 훨씬더 쉬워졌을 것이다
- 그래서, 직접 priors를 고기보다 k-means clustering을 훈련 셋 바운딩 박스에 자동적으로 좋은 priors를 찾았다
- 큰 박스에 사용하면 오류가 많이 발생하는데 더 좋은 iou score를 얻기위해서 박스사이즈를 독립적으로 가져갔고 아래가 그 공식이다
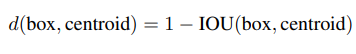
Figure 2
- k=5를 선택했는데 이게 모델 복잡성과 높은 recall 사이의 가장 좋은 tradeoff기 때문이다
-그래서, 길고 얇은 박스들보단 짧지만 넓은 박스들이 있다
5. Direction location prediction
앵커박스를 사용했을때 두번째 문제는 특히 초기 이터레이션때 model instability(모델 불안정성)이 발생함
- 그래서, logistic activation을 사용해서 gt 범위를 0~1사이로 만들었다
- 네트워크가 5개의 바운딩박스를 예측하고 각각의 박스에 5coordinates를 예측해서 학습이 더 쉬워지고 모델이 더 안정적으로 되었다
6. Fine-Grained Feature
- 13x13은 피처맵이 큰 객체에는 충분하고 작은 객체의 위치를 찾기위해 섬세한 그레인드 피처에 효과적이다
- 낮은 해상도 피쳐들과 높은 해상도의 피쳐들을 합쳐서 다른 채널로 인접한 피쳐들을 paththrough layer를 사용해 보내는데 이게 13x13x2048의 피쳐맵이 만들어져서 fine grained features에 접근할 수 있게 된다
- 그로인해 퍼포먼스가 1% 상승하게 된다
7. Multi-Scale Training
- 모든 이터레이션에서 인풋 이미지 사이즈를 바꾼게 아니라 네트워크의 10개 배치에는 랜덤으로 이미지 차원 사이즈를 선택해서 진행했다
Faster
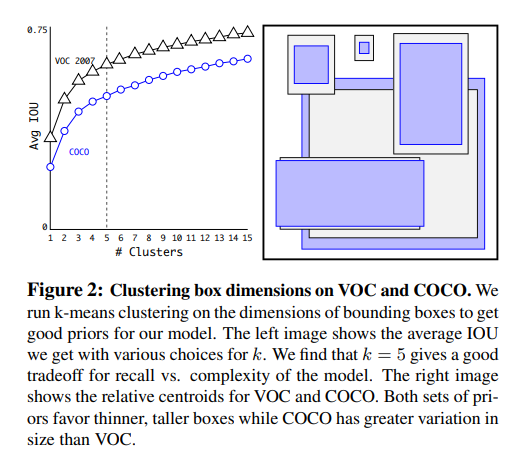
1. Darknet-19
- 3x3 필터와 더블 넘버 채널들을 모든 풀링 스텝 뒤에 사용해서 vgg랑 비슷하다
- 최종 모델은 Darkenet-19이고 19개의 컨브층과 5개의 맥스풀링 층을 가진다
- top-1 accuracy는 72.9%, top-5 accuracy는 91.2%를 가졌다
Stronger
- 디텍션 데이터랑 분류 데이터랑 합쳐서 사용하고 분류할때 softmax를 사용해서 카테고리 구분했다
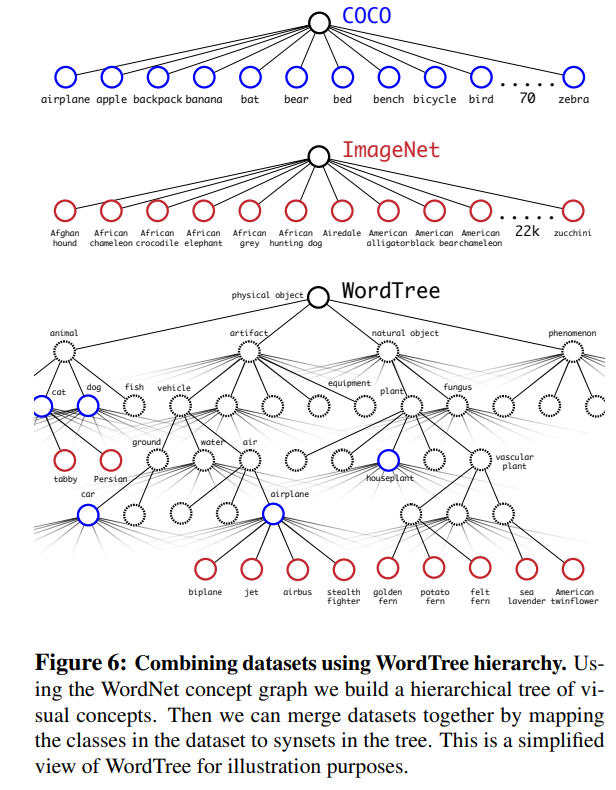
- 워드넷 컨셉 그래프를 사용해서 계층적인 구조를 빌드하고 데이터셋을 합친다음에 트리안에 있는 개념별 클래스를 맵핑했다
- ImageNet 옷과 장비들같은 카테고리 학습이 어렵다
- coco 데이터 셋도 옷에는 바운딩 박스 라벨이 안되어있어서 선글라스나 스위밍 트렁크같은 카테고리 학습이 어렵다

안녕하세요. 기억보다 기록을 믿는 레나입니다!