
욜로 모델을 제대로 읽어보는 건 처음인데 어떤 모델인지만 알고 그 안을 들여다보는 건 숙제 같은 느낌이라 자꾸 미뤄왔던거 같다. 이번 기회에 꼼꼼하게 읽어보고 욜로기반으로 개인 프로젝트까지 진행해보려고한다.
욜로는 빠르고 쉽게 가져와서 사용할 수 있는게 큰 장점인거 같다. 그 이유로 실제 산업이나 현장에서도 많이 사용하는 것 같다. 그러나 아쉬운 점은 최근에 나온 모델들에 비해 정확도가 낮은편이지만 아직은 단점보다 장점이 큰 모델이다.
YOLOv1 Paper: https://arxiv.org/pdf/1506.02640.pdf
Abstract
- 욜로는 공간적으로 분리된 바운딩 박스와 연관된 클래스 확률을 보여주는 regression problem으로 객체 인식 문제를 해결했다
- 단일 신경망이 전체 이미지를 한번만 평가하여 바운딩 박스와 클래스 확률을 직접적으로 예측한다
- 욜로는 초당 45프레임을 가져서 빠르다
- 최근의 객체감지 시스템과 비교했을때 욜로는 Localization errors가 있지만 배경에 False posivives로 예측하는게 적다
- 욜로는 일반적인 이미지를 학습했고 내추럴 이미지에서 예술 작품까지 일반화 할 수 있어서 DPM이나 R-cnn보다 객체 감지 문제에 뛰어나다
Localization errors: 주어진 이미지 안에 object가 이미지 안에 어느 위치에 있는지 위치 정보를 출력해주는 것으로 주로, bounding box를 많이 사용하며 주로 bounding box의 네 꼭지점 pixel좌표가 출력되는 것이 아닌 left top, right bottom 좌표를 출력한다.
False positives: 실제로 객체가 없지만 객체가 있다고 판단하는 것
Figure 1: The YOLO Detection System

욜로를 사용한 이미지 프로세싱은 쉽고 직관적이다.
1. input image를 448*448로 이미지 사이즈를 수정한다.
2. 단일의 신경망을 적용한다.
3. 모델의 컨피던스에 의해 디텍션 결과의 임계점을 계산한다.
3번이 이해하기 어려웠는데 그림에는 Non-max suppression이라고 나와있어서 추가로 찾아보니 이해가 갔다.
[NMS] Non max suppression
NMS란 object가 존재하는 위치에 여러개의 점수가 높은 바운딩박스로 만드는데, 이중 하나를 선택해야하는데 이때 사용하는 기법이 NMS이다.NMS 과정
- 모든 바운딩 박스는 자신이 해당 객체를 얼마나 잘 잡아내는지 나타내는 confidence score를 가지는데 threshold 이하의 confidence score를 가지는 바운딩박스는 제거한다
- 남은 바운딩 박스들을 confidence socre기준으로 내림차순 정렬한다
- 맨 앞에 있는 바운딩박스를 기준으로 다른 바운딩박스와 IOU값을 구한 후 IOU가 treshold 이상인 바운딩 박스를 제거한다. (바운딩박스끼리 IOU가 높을수록=많이 겹칠수록 같은 물체를 검출한다고 판단해서)
- 위의 과정을 순차적으로 시행 후 모든 바운딩박스를 비교하고 제거한다
- confidence threshold가 높을수록, IOU threshold가 낮을수록 더 많은 바운딩 박스가 제거됨
출처 및 참고하면 좋은 링크: https://wikidocs.net/142645
Figure 2: The Model
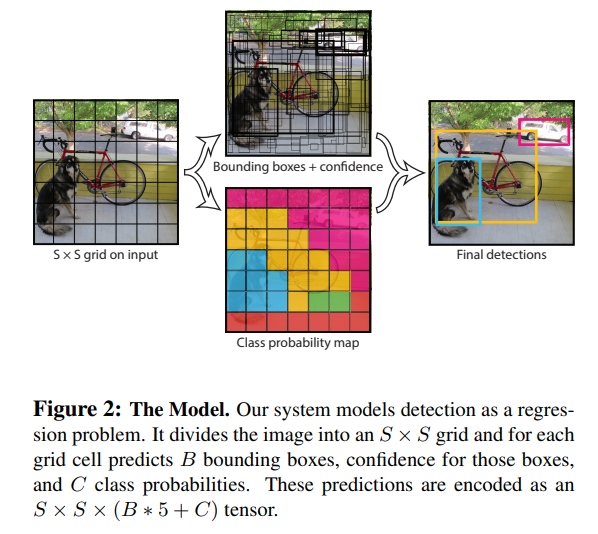
욜로는 Regression problem으로 객체를 감지하는데
이미지를 SxS 그리드로 나누고 각각의 그리드 셀은 B 바운딩 박스와 박스의 confidence를 예측한다
동시에 C 클래스 확률도 구한다
이러한 예측은 SxSx(Bx5+C)의 텐서로 인코딩된다
Grid Cell
- 각각의 그리드셀은 Bbounding box와 각각의 박스의 confidence 점수를 예측한다
- confidence score는 어떻게 물체가 있는지 확신할수 있게하고 어떻게 예측을 정확하게 하는지를 알려준다
- 해당 셀에 물체가 없다면 점수는 0이 되거나 예측된 박스와 정답은 맞춘거 사이의 IOU가 confidence score 점수가 같아야한다
- 또한, 그리드 셀은 클래스의 조건부 확률을 예측한다
- 바운딩 박스의 수와는 상관없이 그리드셀당 하나의 클래스 확률만 예측한다
Bounding box
- 바운딩 박스는 5개의 예측(x, y, w, h, confidenc)로 구성된다
- x, y는 바운딩 박스의 중심점을 의미하고 그리드셀의 경계에는 상대적이다
(헷갈리면 안되는 포인트인데 bounding box랑 grid cell를 구분해서 이해가 필요함)- 높이와 너비를 전체 이미지를 기준으로 예측한다
Pascal VOC에서 욜로를 평가하기 위해서 그리드셀은(S)은 7개, 바운딩 박스(B)는 2개, VOC는 20개의 라벨의 클래스를 가지기 때문에 C는 20개로 총 7x7x30 텐서 즉, 1470개의 텐서를 가진다
Figure 3: The Architecture

욜로는 구글넷의 영향을 받았는데 인셉션 모듈이 아닌 3x3 conv layer 이후에 1x1 감소 레이어를 사용한다
24개의 conv layer와 2개의 fully connected layer를 가진다
Limitations of YOLO
- 욜로의 문제는 한개의 그리드셀안에서 두개의 박스를 예측하기 때문에 가까이 있는 물체의 수에 제한이 생긴다
- 그룹안에 작은 물체를 찾아내는 것에 어려움을 가진다(예시, 새 무리)
- 두번째는 데이터로부터 경계상자를 예측하는걸 학습해서 새롭거나 흔하지 않는 물체를 일반화하는 것이 어렵다
- 손실함수에대해 훈현하는 동안 손실함수는 작은 바운딩박스와 큰 바운딩박스에서의 오류를 동일하게 처리해서 작은 상자의 오차는 IOU에 큰 영향을 미쳐서 Localization error가 잘 발생하게 된다
Figure 4: Error Analysis (Fast R-CNN vs YOLO)
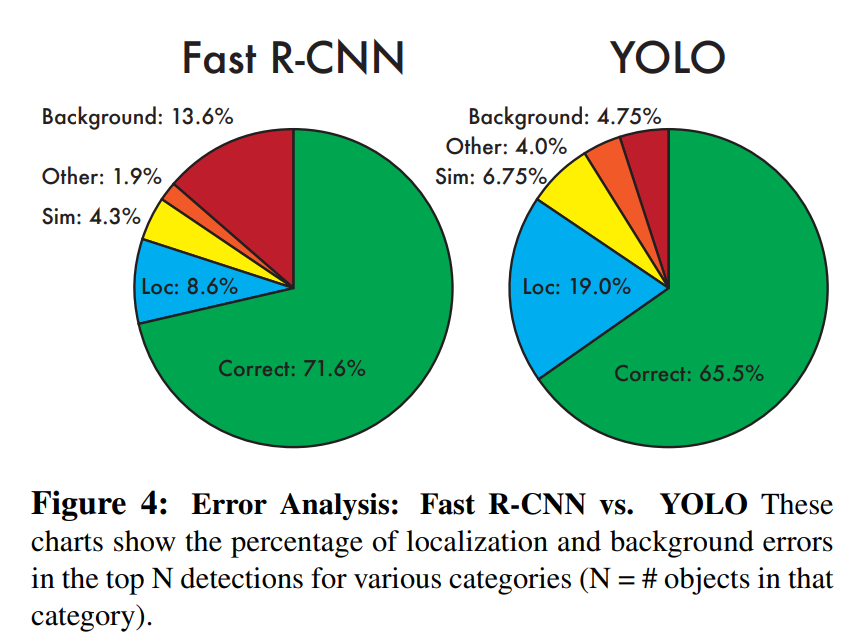
이 차트는 localization과 백그라운드 에러의 퍼센테이지를 나타낸다
욜로는 localization error(19%)를 보이지만 Fast R-cnn은 백그라운드 에러(객체가 없는데 객체가 있다고 예측하는것)가 13.6%를 차지한다
Figure 5: Generalization results on Picasso and People-Art datasets
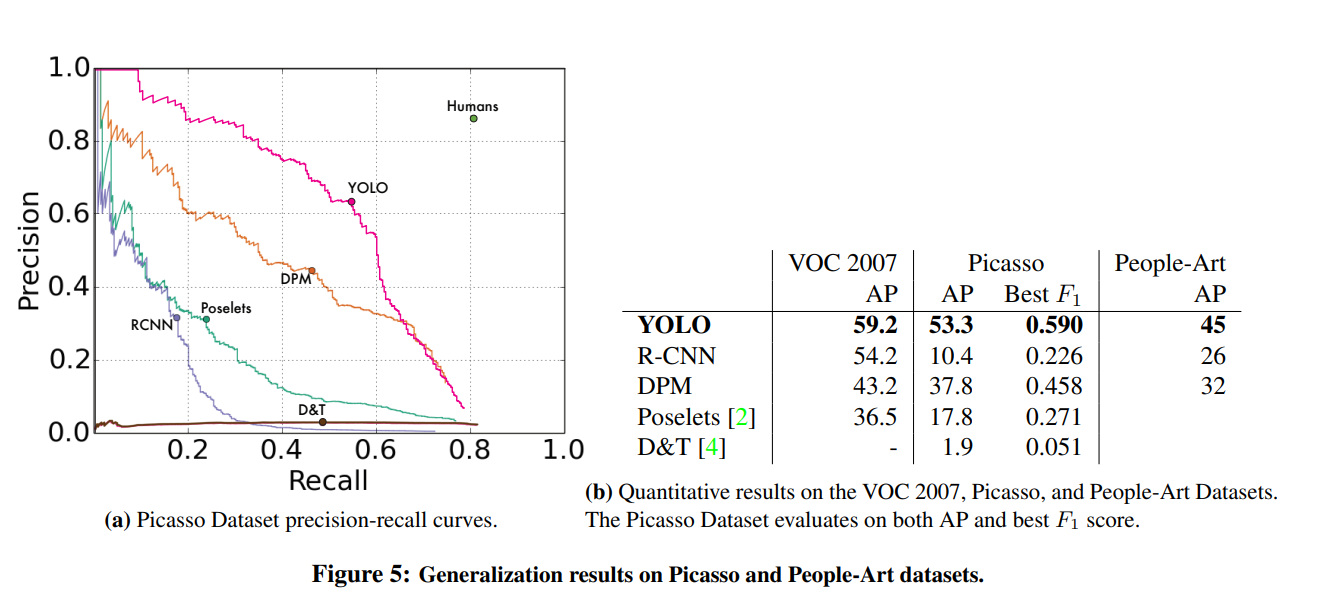
- 그래프를 보면 알 수 있듯이 욜로는 피카소 데이터 셋에서 가장 높은 정확도를 보이는 것을 알 수 있다
- 예술 작품과 자연 이미지는 픽셀 사이즈가 매우 다르지만 객체의 크기와 모양면에선 유사하기때문에 욜로는 바운딩 박스와 디텍션이 좋다고 할 수 있다
Figure 6: Qualitative Results

- 욜로는 빠르고 객체 감지가 정확하기때문에 컴퓨터 비전에 적용하는데 이상적이다
- 욜로는 아트워크와 네추럴 이미지에 적용해 봤는데 대부분 좋은 결과를 보여줬다 아래서 2번째 이미지에 사람이 비행기로 인지한거 빼고는!
