삽입 정렬이란?
- 삽입 정렬은 두 번째 인덱스부터 시작
- 해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B값을 뒤 인덱스로 복사
- 이를 key 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동
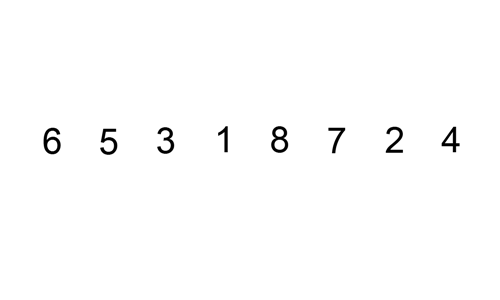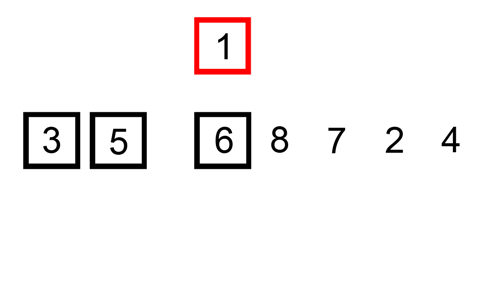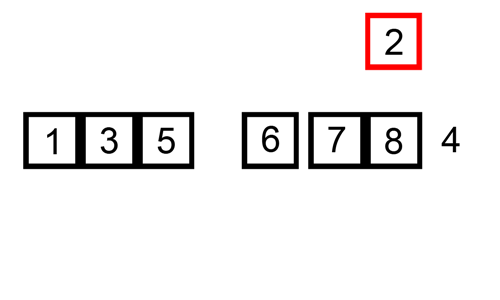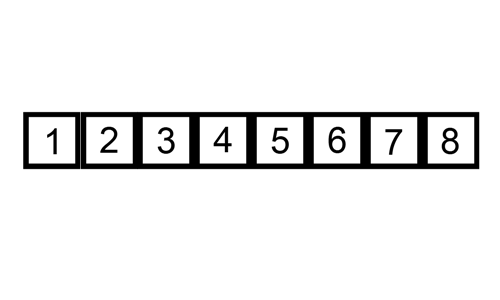
for index in range(10, 1, -1):
print (index)
# 10
# 9
# 8
# 7
# 6
# 5
# 4
# 3
# 2코드를 어떻게 만들까?
다음 단계를 밟아가며, 연습을 해보자.
- 데이터가 두개 일 때, 동작하는 삽입 정렬 알고리즘을 함수로 만들어 보자.
- 데이터가 세개 일 때, 동작하는 삽입 정렬 알고리즘을 함수로 만들어 보자.
- 데이터가 네개 일 때, 동작하는 삽입 정렬 알고리즘을 함수로 만들어 보자.
- 데이터가 네 개 일때 (데이터 갯수에 따라 복잡도가 떨어지는 것은 아니므로, 네 개로 바로 로직을 이해해보자.)
- 예: data_list = [9, 3, 2, 5]
- 처음 한번 실행하면, key값은 9, 인덱스(0) - 1 은 0보다 작으므로 끝: [9, 3, 2, 5]
- 두 번째 실행하면, key값은 3, 9보다 3이 작으므로 자리 바꾸고, 끝: [3, 9, 2, 5]
- 세 번째 실행하면, key값은 2, 9보다 2가 작으므로 자리 바꾸고, 다시 3보다 2가 작으므로 끝: [2, 3, 9, 5]
- 네 번째 실행하면, key값은 5, 9보다 5이 작으므로 자리 바꾸고, 3보다는 5가 크므로 끝: [2, 3, 5, 9]
알고리즘 구현
- for stand in range(len(data_list)) 로 반복
- key = data_list[stand]
- for num in range(stand, 0, -1) 반복
- 내부 반복문 안에서 data_list[stand] < data_list[num - 1] 이면,
- data_list[num - 1], data_list[num] = data_list[num], data_list[num - 1]
- 내부 반복문 안에서 data_list[stand] < data_list[num - 1] 이면,
def insertion_sort(data):
for index in range(len(data) - 1):
for index2 in range(index + 1, 0, -1):
if data[index2] < data[index2 - 1]:
data[index2], data[index2 - 1] = data[index2 - 1], data[index2]
else:
break
return dataimport random
data_list = random.sample(range(100), 50)
print (insertion_sort(data_list))
# [1, 2, 3, 5, 8, 9, 10, 11, 14, 16, 17, 20, 22, 23, 32, 33, 34, 36, 40, 43, 46, 47, 49, 50, 51, 53, 56, 57, 60, 61, 62, 64, 65, 67, 68, 71, 72, 74, 75, 81, 82, 83, 85, 86, 89, 90, 91, 93, 96, 99]4. 알고리즘 분석
- 반복문이 두 개 O()
- 최악의 경우,
- 완전 정렬이 되어 있는 상태라면 최선은 O(n)

신입사원...