정규화를 통한 성능 향상 전략
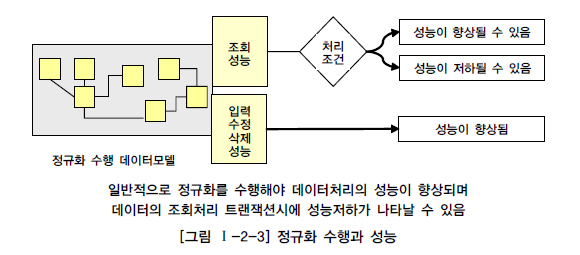
데이터베이스에서 데이터를 처리할 때 성능이라고 하면 조회 성능과 입력/수정/삭제 성능의 두 부류로 구분된다. 이 두 가지 성능이 모두 우수하면 좋겠지만 데이터 모델을 구성하는 방식에 따라 두 성능이 Trade-Off 되어 나타나는 경우가 많이 있다.
- 정규화의 목적
- 데이터 중복 제거: 동일한 데이터가 여러 곳에 저장되지 않도록 함으로써 데이터 일관성을 유지한다.
- 이상현상 방지: 데이터 삽입, 삭제, 수정 시 발생할 수 있는 이상현상을 방지한다.
- 데이터의 논리적 구조 개선: 데이터가 관심사별로 처리되도록 하여 논리적 구조를 개선한다.
- 정규화와 성능
- 입력/수정/삭제 성능 향상: 정규화를 통해 데이터 중복을 제거하고, 테이블 크기를 줄이기 때문에 입력/수정/삭제 성능이 향상된다. 데이터가 적절한 테이블에 저장되기 때문에 변경 작업이 효율적이다.
- 조회 성능: 정규화된 테이블은 조인을 많이 필요로 할 수 있다. 조인은 테이블 간의 연관 관계를 통해 데이터를 결합하는 작업으로, 조인 연산이 많아지면 조회 성능이 저하될 수 있다. 그러나 이는 항상 그런 것은 아다. 특정 조건에서는 정규화가 오히려 조회 성능을 향상시킬 수 있다.
- 성능의 두 가지 측면
- 조회 성능: 데이터를 읽어오는 속도. 여러 테이블 간의 조인 작업이 많으면 성능이 저하될 수 있다.
- 입력/수정/삭제 성능: 데이터를 추가, 수정, 삭제하는 속도. 정규화를 통해 데이터 중복을 최소화하면 이 성능이 향상된다.
- 반정규화의 필요성
- 반정규화는 의도적으로 정규화를 일부 해제하여 데이터 중복을 허용하는 것이다. 이는 조회 성능을 향상시키기 위해 사용된다.
- 조인 연산을 줄이기 위해 자주 조회되는 데이터를 하나의 테이블에 모으는 등의 방법을 사용할 수 있다.
- 반정규화는 상황에 따라 필요할 수 있으며, 반정규화만이 조회 성능을 향상시키는 유일한 방법은 아니다.
정규화의 단계
| 정규화 | |
|---|---|
| 제1정규형(1NF) | 모든 테이블의 컬럼이 원자값을 가지도록 함. |
| 제2정규형(2NF) | 제1정규형을 만족하고, 기본 키가 아닌 모든 속성이 기본 키에 완전 종속되도록 함. |
| 제3정규형(3NF) | 제2정규형을 만족하고, 기본 키가 아닌 모든 속성이 기본 키에 이행적 종속되지 않도록 함. |



성능 향상을 위한 전략
정규화는 데이터베이스 설계의 기본이지만, 모든 경우에 정규화가 항상 최선은 아니다!! 데이터베이스 설계자는 데이터 모델링 과정에서 데이터의 무결성과 성능 간의 균형을 맞추는 것이 중요하다!!
- 정규화와 반정규화의 균형
- 처음에는 정규화를 통해 데이터의 일관성과 무결성을 유지하는 것이 중요하다.
- 성능 문제(특히 조회 성능)가 발생할 경우, 분석을 통해 반정규화 적용 여부를 판단한다.
- 인덱싱
- 테이블에 적절한 인덱스를 추가하여 조회 성능을 향상시킬 수 있다. 인덱스는 데이터베이스에서 검색을 빠르게 해준다.
- 쿼리 최적화
- 쿼리 작성 시 최적화된 쿼리를 사용하여 성능을 개선할 수 있다. 필요 없는 조인을 피하고, 서브쿼리를 최소화하는 등의 방법을 사용할 수 있다.
- 하드웨어 및 데이터베이스 설정
- 하드웨어 업그레이드(예: 더 빠른 디스크, 더 많은 메모리)와 데이터베이스 설정 튜닝을 통해 성능을 향상시킬 수 있다.
반 정규화된 테이블의 성능 저하 사례 분석
반정규화는 데이터베이스 선능을 최적화하려는 시도로, 특정 상황에서는 효과적이지만, 잘못된 반정규화는 ㅇ히려 성능을 저하시킬 수 있다.
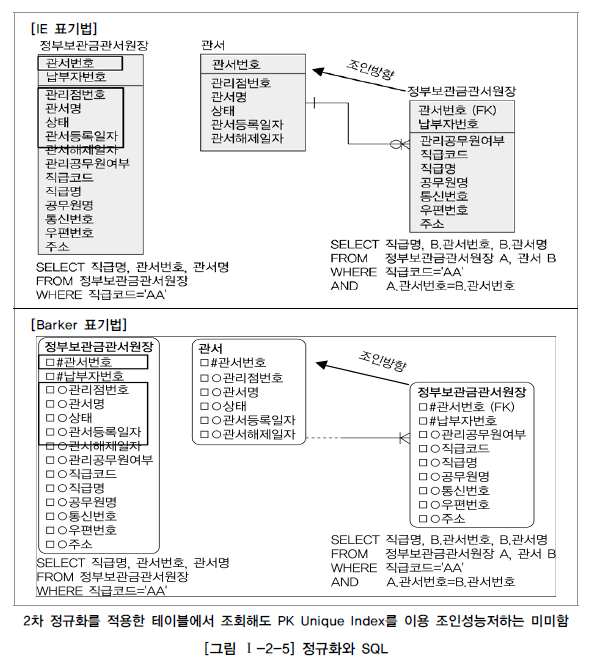
1️⃣ 사례: 2차 정규화 적용 테이블의 조인 성능
- 설명: 2차 정규화된 테이블과 반정규화된 테이블의 성능 비교.
- 상황: 정규화된 테이블은 두 개의 테이블을 조인해야 하고, 반정규화된 테이블은 단일 테이블에서 조회가 가능하다.
- 결론: PK(Primary Key) Unique Index를 이용한 조인은 성능 저하가 미미하다. 특정 조건(예: 날짜 조회)에서는 정규화된 테이블이 더 빠를 수 있다.
- 예시: 정규화된 테이블은 불필요한 중복 데이터 읽기를 줄여 효율성을 높인다.
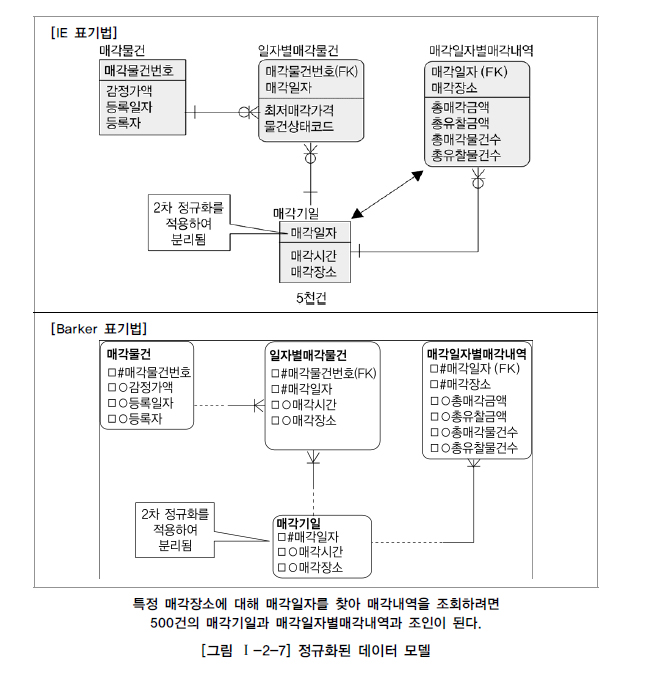
2️⃣ 사례: 두 개의 엔티티가 통합된 반정규화된 경우
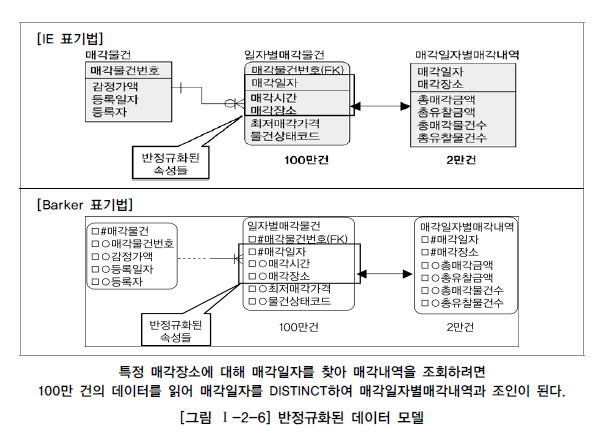
- 설명: 매각일자와 관련 속성을 포함하는 반정규화된 테이블.
- 상황: 매각일자가 결정자, 매각시간과 매각장소가 의존자. 매각일자별 조회 시 100만 건의 데이터를 DISTINCT로 읽어야 함.
- 결론: 정규화된 모델에서는 5천 건의 매각기일 테이블만 읽으면 되므로 성능이 향상된다.
- 예시: 반정규화된 테이블은 불필요한 대량 데이터를 읽어야 하므로 성능 저하를 초래한다.
쿼리 (반정규화 된 모델)
SELECT B.총매각금액, B.총유찰금액
FROM (
SELECT DISTINCT 매각일자
FROM 일자별매각물건
WHERE 매각장소 = '서울 7호'
) A,
매각일자별매각내역 B
WHERE A.매각일자 = B.매각일자;- 서브쿼리
- SELECT DISTINCT 매각일자 FROM 일자별매각물건 WHERE 매각장소 = '서울 7호'
- 일자별매각물건 테이블에서 매각장소가 ‘서울 7호’인 모든 매각일자를 조회한다.
- DISTINCT를 사용하여 중복된 매각일자를 제거한다.
- 이 서브쿼리는 100만 건의 데이터를 읽어서 중복을 제거해야 한다.
- 메인 쿼리
- 서브쿼리의 결과를 테이블 A로 사용하여 매각일자별매각내역 B 테이블과 조인한다.
- 조인 조건은 매각일자가 일치하는 경우이다.
- 최종적으로 B.총매각금액과 B.총유찰금액을 조회한다.
쿼리 (정규화된 데이터 모델 사용)
SELECT B.총매각금액, B.총유찰금액
FROM 매각기일 A, 매각일자별매각내역 B
WHERE A.매각장소 = '서울 7호'
AND A.매각일자 = B.매각일자;- 매각기일 테이블에서 매각장소가 ‘서울 7호’인 모든 레코드를 조회한다.
- 이 테이블은 5천 건의 데이터를 가지고 있다.
- 매각기일 테이블의 결과를 매각일자별매각내역 테이블과 조인한다.
- 조인 조건은 매각일자와 매각장소가 일치하는 경우이다.
- 최종적으로 B.총매각금액과 B.총유찰금액을 조회한다.
성능 비교
1.데이터 처리량:
- 첫 번째 쿼리는 서브쿼리에서 중복된 매각일자를 제거하기 위해 100만 건의 데이터를 읽어야 한다.
- 두 번째 쿼리는 5천 건의 데이터만 읽으면 된다.
- 조인 방식:
- 첫 번째 쿼리는 서브쿼리를 사용하여 매각일자만으로 조인한다.
- 두 번째 쿼리는 매각일자와 매각장소를 사용하여 조인하므로 더 정확한 매칭이 이루어진다.
- 쿼리 복잡성:
- 첫 번째 쿼리는 서브쿼리를 사용하므로 복잡도가 높다.
- 두 번째 쿼리는 더 간단하고 명확하다.
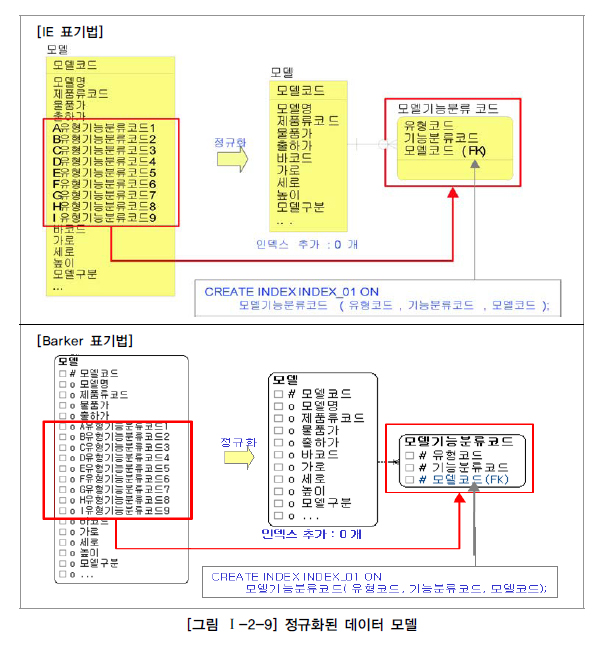
3️⃣ 사례: 동일한 속성 형식을 여러 개의 속성으로 나열한 경우
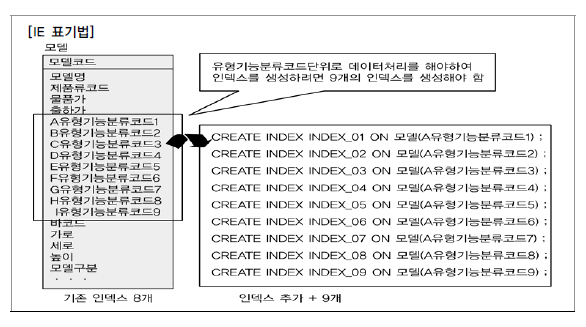
- 설명: 반복되는 속성을 칼럼으로 나열하여 반정규화된 테이블.
- 상황: 9개의 인덱스를 생성해야 하며, 인덱스 수가 많아지면 입력/수정/삭제 성능이 저하된다.
- 결론: 정규화를 통해 중복 속성을 분리하면 인덱스 수가 줄어들고 성능이 향상된다.
- 예시: 모델기능분류코드 테이블로 분리하여 PK 인덱스를 사용함으로써 성능이 향상된다.
참고로, 한 테이블에 인덱스가 많아지면 조회 성능은 향상되지만 데이터 입력/수정/삭제 성능은 저하된다. (즉, 이 예시의 반정규화에서는 조회 성능은 나쁘지 않지만 CUD의 성능이 저하된다는 거다.)
쿼리 (반정규화된 테이블)
SELECT 모델코드, 모델명
FROM 모델
WHERE
(A유형기능분류코드1 = '01') OR
(B유형기능분류코드2 = '02') OR
(C유형기능분류코드3 = '07') OR
(D유형기능분류코드4 = '01') OR
(E유형기능분류코드5 = '02') OR
(F유형기능분류코드6 = '07') OR
(G유형기능분류코드7 = '03') OR
(H유형기능분류코드8 = '09') OR
(I유형기능분류코드9 = '09');- 설명
- 테이블 구조: 반정규화된 테이블 구조로, ‘모델’ 테이블에 여러 개의 기능 분류 코드가 각기 다른 칼럼(A유형기능분류코드1, B유형기능분류코드2, …)에 저장되어 있다.
- 조건: 각 기능 분류 코드 칼럼에 대해 조건을 OR 연산자로 결합하여 원하는 모델을 조회한다.
- 문제점
- 중복된 구조: 동일한 유형의 데이터를 여러 칼럼으로 나누어 저장함으로써 테이블 구조가 중복되고 비효율적이다.
- 인덱스 문제: 각 칼럼에 대해 별도의 인덱스를 만들어야 하며, 이는 인덱스가 많아지면 데이터 입력/수정/삭제 성능이 저하될 수 있다.
- 확장성 부족: 새로운 유형 코드가 추가되면 테이블 구조를 변경해야 하며, 이는 유지보수가 어렵다.
쿼리 (정규화된 테이블)
SELECT A.모델코드, A.모델명
FROM 모델 A, 모델기능분류코드 B
WHERE
(B.유형코드 = 'A' AND B.기능분류코드 = '01' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'B' AND B.기능분류코드 = '02' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'C' AND B.기능분류코드 = '07' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'D' AND B.기능분류코드 = '01' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'E' AND B.기능분류코드 = '02' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'F' AND B.기능분류코드 = '07' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'G' AND B.기능분류코드 = '03' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'H' AND B.기능분류코드 = '09' AND A.모델코드 = B.모델코드) OR
(B.유형코드 = 'I' AND B.기능분류코드 = '09' AND A.모델코드 = B.모델코드);- 설명
- 테이블 구조: 정규화된 테이블 구조로, ‘모델’ 테이블과 ‘모델기능분류코드’ 테이블로 분리되어 있다.
- 조인: ‘모델’ 테이블과 ‘모델기능분류코드’ 테이블을 모델코드로 조인하여 필요한 데이터를 조회한다.
- 조건: 각 유형 코드와 기능 분류 코드에 대한 조건을 OR 연산자로 결합하여 원하는 모델을 조회한다.
- 장점
- 유연성: 새로운 유형 코드가 추가되어도 테이블 구조를 변경할 필요가 없다. ‘모델기능분류코드’ 테이블에 새로운 레코드를 추가하기만 하면 된다.
- 인덱스 효율성: ‘모델기능분류코드’ 테이블에 인덱스를 생성하면 검색 성능이 향상된다.
- 중복 최소화: 데이터의 중복을 최소화하여 저장 공간을 절약하고 데이터 일관성을 유지한다.
비교 및 결론
- 데이터 구조
- 첫 번째 쿼리는 반정규화된 테이블 구조로, 동일한 데이터 유형이 여러 칼럼에 중복되어 저장된다.
- 두 번째 쿼리는 정규화된 테이블 구조로, 데이터가 적절하게 분리되어 저장된다.
- 성능
- 첫 번째 쿼리는 인덱스가 많아지면 데이터 입력/수정/삭제 성능이 저하될 수 있다.
- 두 번째 쿼리는 인덱스를 효율적으로 사용할 수 있어 검색 성능이 향상된다.
- 유지보수
- 첫 번째 쿼리는 새로운 유형 코드가 추가되면 테이블 구조를 변경해야 하므로 유지보수가 어렵다.
- 두 번째 쿼리는 새로운 유형 코드가 추가되어도 테이블 구조를 변경할 필요가 없으므로 유지보수가 용이하다.
참고: 인덱스
인덱스는 데이터베이스 테이블에서 검색 성능을 향상시키기 위해 사용하는 데이터 구조이다. 인덱스를 사용하면 특정 조건을 만족하는 레코드를 효율적으로 찾을 수 있다. 이제 인덱스가 검색 성능을 향상시키는 이유와 그 원리는 다음과 같다.
- 인덱스 구조
- 인덱스는 일반적으로 B-트리(Balanced Tree) 또는 해시(Hash) 구조를 사용하여 구성된다. 이러한 구조는 데이터 검색을 빠르게 수행할 수 있도록 설계되었다.
- B-트리 인덱스는 트리 구조로 데이터를 정렬하여 저장하며, 검색, 삽입, 삭제 작업을 로그(log) 시간 복잡도로 수행할 수 있습니다.
- 인덱스의 역할
- 인덱스는 특정 컬럼에 대한 값을 빠르게 검색할 수 있도록 도와준다. 테이블 전체를 스캔하는 대신, 인덱스를 사용하면 인덱스 트리에서 빠르게 원하는 값을 찾을 수 있다.
- 예를 들어, 특정 유형코드와 기능분류코드를 검색할 때, 인덱스를 사용하면 해당 조건을 만족하는 레코드를 인덱스 트리에서 빠르게 찾아낼 수 있다.
4️⃣ 사례: 일재고와 일재고 상세 구분
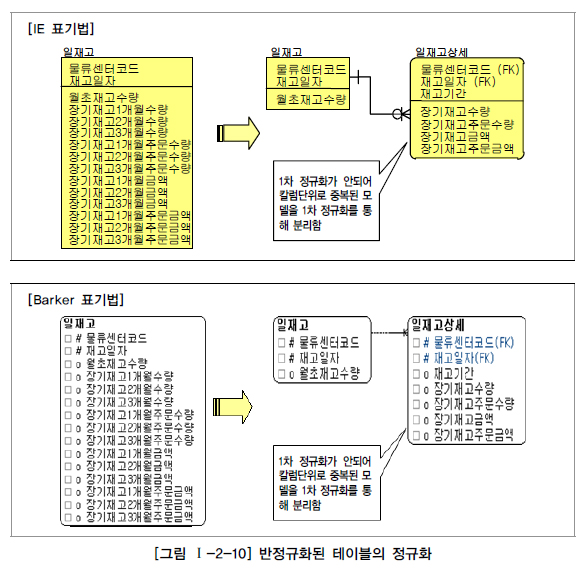
- 설명: 일재고와 일재고 상세 테이블의 반정규화.
- 상황: 반정규화된 테이블에서는 트랜잭션 성능이 저하될 수 있음.
- 결론: 일재고와 일재고 상세를 구분하여 트랜잭션의 성능 저하를 예방할 수 있습니다.
- 예시: 정규화를 통해 데이터 분리 및 트랜잭션 처리 효율성을 높입니다.
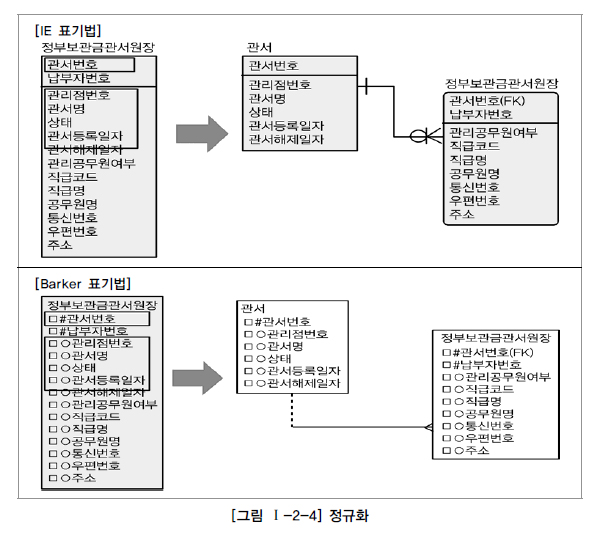
5️⃣ 함수적 종속성(Functional Dependency)에 근거한 정규화 수행 필요
함수적 종속성은 데이터베이스 설계에서 매우 중요한 개념으로, 정규화 과정을 이해하고 수행하는 데 기본이 된다. 이를 통해 데이터의 일관성을 유지하고 중복을 최소화할 수 있다.
1. 함수적 종속성의 정의
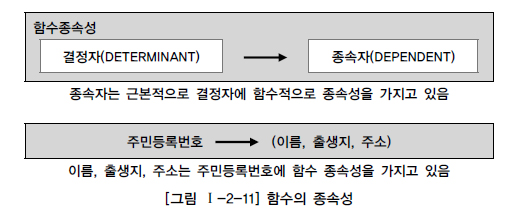
- 함수적 종속성: 한 속성 집합이 다른 속성 집합을 함수적으로 결정하는 관계이다. 이는 특정 속성(결정자, Determinant)의 값이 주어지면 다른 속성(종속자, Dependent)의 값이 유일하게 결정되는 것을 의미한다.
- 결정자: 다른 속성의 값을 결정하는 속성.
- 종속자: 결정자의 값에 의해 결정되는 속성.
예를 들면, 주민등록번호가 주어지면 그에 해당하는 이름, 출생지, 가족 관계가 유일하게 결정된다. 이를 기호로 표시하면 다음과 같다.
주민등록번호 -> (이름, 출생지, 가족 관계)
2. 함수적 종속성과 정규화
함수적 종속성에 근거한 정규화는 데이터베이스 설계의 필수 과정이다. 정규화의 목적은 데이터의 중복을 제거하고, 이상현상을 방지하는 것이다. 이를 위해 함수적 종속성을 이용하여 데이터를 적절히 분리하고 배치해야 한다.
- 제1정규형(1NF): 모든 속성이 원자값(Atomic Value)을 가져야 한다.
- 제2정규형(2NF): 제1정규형을 만족하고, 기본 키가 아닌 모든 속성이 기본 키에 완전 함수적 종속을 가져야 한다.
- 제3정규형(3NF): 제2정규형을 만족하고, 기본 키가 아닌 모든 속성이 기본 키에 이행적 종속이 없어야 한다.
3. 정규화의 중요성
- 데이터 무결성: 정규화를 통해 데이터의 일관성과 무결성을 유지할 수 있다.
- 중복 최소화: 데이터 중복을 제거하여 저장 공간을 절약하고, 데이터 관리의 효율성을 높인다.
- 이상현상 방지: 삽입, 삭제, 갱신 이상현상을 방지한다.
위의 예제에서, 사람이라는 엔티티에는 주민등록번호, 이름, 출생지, 호주 속성이 존재한다. 여기서 이름, 출생지, 가족 관계가 주민등록번호에 함수적으로 종속되어, 한 사람의 주민등록번호가 주어지면 그 사람의 이름, 출생지, 가족 관계가 결정된다.
4. 정규화의 필수성
- 프로젝트 수행에서 필수: 정규화는 선택 사항이 아니라 필수 사항다. 이는 데이터베이스의 구조를 함수적 종속관계에 맞게 분리하는 기본적인 설계 원칙다.
- 정확한 이해 필요: 프로젝트 설계자가 정규화 이론을 정확히 이해하지 못하면 데이터 모델링 설계는 불가능하다. 이는 기본적인 설계 원칙을 숙지하지 못하고 건축물을 설계하는 것과 같다.
- 설계 검증: 정규화 이론은 정보시스템 설계의 근간이 되며, 이를 통해 설계가 명확하게 검증받을 수 있다.
정규화
1️⃣ 제1정규화
1차 정규화 (1NF: First Normal Form)
1차 정규화는 테이블의 모든 필드가 원자값(atomic value)을 가져야 한다는 것을 의미한다. 즉, 각 필드에는 하나의 값만 존재해야 한다. 이를 통해 중복되는 데이터를 제거하고, 데이터베이스의 무결성을 유지할 수 있다.
- 조건
- 모든 열이 원자값을 가져야 한다.
- 테이블에는 중복된 행이 없어야 한다.
제1정규화 예시
잘못된 형태: -- 각 필드에는 하나의 값만 존재해야 한다!
StudentID | Name | Subjects
------------------------------------
1 | John Doe | Math, Science
2 | Jane Smith | Math, English
1NF 형태:
StudentID (PK) | Name | Subject
-------------------------------------
1 | John Doe | Math
1 | John Doe | Science
2 | Jane Smith| Math
2 | Jane Smith| English잘못된 형태:
EmployeeID | Name | PhoneNumbers
----------------------------------------
1 | Alice Johnson| 123-4567, 234-5678
2 | Bob Smith | 345-6789, 456-7890
1NF 형태:
EmployeeID (PK) | Name | PhoneNumber
--------------------------------------------
1 | Alice Johnson| 123-4567
1 | Alice Johnson| 234-5678
2 | Bob Smith | 345-6789
2 | Bob Smith | 456-78902️⃣ 제2정규화
2차 정규화 (2NF: Second Normal Form)
2차 정규화는 1차 정규화를 만족하면서, 부분 함수 종속성을 제거하는 것이다. 이는 기본 키가 아닌 열이 기본 키의 부분 집합에 종속되지 않도록 하는 것을 의미한다.
-조건
- 1차 정규화를 만족해야 한다.
- 기본 키의 모든 비기본 속성이 기본 키 전체에 대하 완전 함수 종속이어야 한다.
제2정규화 예시
1NF 형태:
OrderID | ProductID | ProductName | Quantity
-------------------------------------------
1 | 101 | Widget | 10
2 | 102 | Gizmo | 20
잘못된 2NF 형태:
OrderID | ProductID | ProductName | Quantity
-------------------------------------------
1 | 101 | Widget | 10
2 | 102 | Gizmo | 20
2NF 형태:
OrderID | ProductID | Quantity
------------------------------
1 | 101 | 10
2 | 102 | 20
ProductID | ProductName
-----------------------
101 | Widget
102 | Gizmo1NF 형태
OrderID | ProductID | ProductName | Quantity | Price
----------------------------------------------------
1 | 101 | Widget | 10 | 5.00
1 | 102 | Gizmo | 20 | 10.00
2 | 101 | Widget | 15 | 5.00
2 | 103 | Gadget | 5 | 15.00
2NF형태
OrderID (PK) | ProductID (PK) | Quantity
-----------------------------------------
1 | 101 | 10
1 | 102 | 20
2 | 101 | 15
2 | 103 | 5
ProductID (PK) | ProductName | Price
------------------------------------
101 | Widget | 5.00
102 | Gizmo | 10.00
103 | Gadget | 15.003️⃣ 제3정규화
3차 정규화 (3NF: Third Normal Form)
3차 정규화는 2차 정규화를 만족하면서, 기본 키가 아닌 열이 다른 기본 키가 아닌 열에 종속되는 경우를 의미한다. (이행적 함수 종속성을 제거 한다는 뜻이다.)
3차 정규화 (3NF: Third Normal Form)
쉽게 말해, A -> B, B -> C가 성립하면 A -> C도 성립하는 경우를 의미한다. 3차 정규화(3NF)는 이러한 이행적 종속성을 제거하여 데이터 무결성을 더욱 강화한다.
이행적 함수 종속성
2NF 상태의 테이블
StudentID (PK) | Name | CourseID (FK) | CourseName | InstructorID (FK) | InstructorName
----------------------------------------------------------------------------------------------
1 | John Doe | 1001 | Math | 201 | Dr. Smith
2 | Jane Smith | 1002 | English | 202 | Prof. Johnson
3 | Sam Brown | 1001 | Math | 201 | Dr. Smith위 테이블에서는 CourseID와 InstructorID가 각각 CourseName과 InstructorName에 종속된다. 즉, CourseID -> CourseName, InstructorID -> InstructorName이라는 종속성이 있다.
이때, StudentID가 기본 키입니다. 이 테이블에는 이행적 종속성이 존재한다.
- StudentID -> CourseID
- CourseID -> InstructorID
- InstructorID -> InstructorName
따라서, StudentID -> InstructorName이라는 이행적 종속성이 생긴다. 이러한 이행적 종속성은 데이터 무결성을 해칠 수 있다.
따라서 3차 정규화(3NF)로 변환하여, 이러한 이행적 종속성을 제거하여, 기본 키에 직접 종속된 열들만 남도록 테이블을 분리하면 아래와 같다.
3NF
StudentID (PK) | Name | CourseID (FK)
--------------------------------------------
1 | John Doe | 1001
2 | Jane Smith | 1002
3 | Sam Brown | 1001
CourseID (PK) | CourseName | InstructorID (FK)
----------------------------------------------
1001 | Math | 201
1002 | English | 202
InstructorID (PK) | InstructorName
----------------------------------
201 | Dr. Smith
202 | Prof. Johnson여기서, CourseID와 InstructorID는 더 이상 StudentID에 이행적으로 종속되지 않는다. 대신, 각 테이블이 직접적으로 기본 키에만 종속되게끔 구조화된다. 즉, CourseName과 InstructorName은 각각 CourseID와 InstructorID에 직접 종속되며, 이로 인해 이행적 종속성이 제거된다.
요약하자면, 3차 정규화는 비기본 키 열이 다른 비기본 키 열에 종속되지 않도록 하여 데이터의 무결성을 유지하고 데이터 중복을 최소화하는 과정이다.
이행적 종속성과 데이터 무결성
이행적 종속성이 데이터 무결성을 해칠 수 있는 이유는 다음과 같은 상황들에서 발생할 수 있는 문제들 때문이다
- 데이터 중복: 이행적 종속성이 있는 경우, 동일한 정보가 여러 테이블에 중복 저장될 가능성이 높다. 중복된 데이터는 관리가 어렵고, 수정 시 일관성을 유지하기 어렵다.
- 갱신 이상(Anomalies):
- 갱신 이상
- 한 곳에서 데이터를 수정하면 다른 곳에서도 동일한 변경을 해야 하는데, 이를 놓치면 데이터가 불일치하게 된다. 예를 들어, 강사의 이름을 변경해야 하는 경우 여러 행에서 동일한 강사의 이름을 모두 수정해야 한다.
- 삽입 이상
- 불필요한 정보가 없으면 데이터를 삽입할 수 없는 경우가 생길 수 있다. 예를 들어, 새로운 강사를 추가하려면 학생 정보도 함께 추가해야 한다면 비효율적이다.
- 삭제 이상
- 특정 데이터를 삭제하면 원치 않는 데이터도 함께 삭제되는 경우가 생긴다. 예를 들어, 마지막 학생을 삭제하면 강사 정보도 삭제되어야 한다면 문제가 된다.
- 갱신 이상
예시
이행적 종속성이 있는 2NF 테이블 예시
StudentID | Name | CourseID | CourseName | InstructorID | InstructorName
-----------------------------------------------------------------------------
1 | John Doe | 1001 | Math | 201 | Dr. Smith
2 | Jane Smith | 1002 | English | 202 | Prof. Johnson
3 | Sam Brown | 1001 | Math | 201 | Dr. Smith이 테이블에서는 CourseID -> InstructorID, InstructorID -> InstructorName이라는 종속성이 존재한다. 따라서 StudentID -> InstructorName이라는 이행적 종속성이 있다. 문제점은 아래와 같다.
- 데이터 중복:
Dr. Smith의 이름이 여러 행에 반복적으로 나타난다. - 갱신 이상:
Dr. Smith의 이름을Dr. John Smith로 변경하려면 여러 행을 수정해야 한다. 만약 한 행에서만 수정이 이루어진다면 데이터 불일치가 발생한다. - 삽입 이상: 만약 새로운 강사 Dr. Emily White를 추가하고자 할 때, 아직 강의 정보를 가지는 학생이 없다면 강사 정보를 추가할 수 없다.
- 삭제 이상: 만약 학생
Sam Brown이 테이블에서 삭제되면,Math강의와Dr. Smith강사 정보도 함께 삭제되어야 하는 상황이 발생할 수 있다.
위 문제를 해결하기 위해 3차 정규화로 변환(3NF)를 하면 아래와 같이 변한다.
StudentID (PK) | Name | CourseID (FK)
--------------------------------------------
1 | John Doe | 1001
2 | Jane Smith | 1002
3 | Sam Brown | 1001
CourseID (PK) | CourseName | InstructorID (FK)
----------------------------------------------
1001 | Math | 201
1002 | English | 202
InstructorID (PK) | InstructorName
----------------------------------
201 | Dr. Smith
202 | Prof. Johnson해결된 문제점은 아래와 같다.
- 데이터 중복 제거:
InstructorName은InstructorID테이블에서 한 번만 저장된다. - 갱신 이상 해결: 강사 이름을 변경할 때 한 곳(Instructor 테이블)만 수정하면 된다.
- 삽입 이상 해결: 강사 정보를 독립적으로 추가할 수 있다.
- 삭제 이상 해결: 학생 정보를 삭제해도 강사 정보는 남아 있다.
