학습 목표 및 학습 내용
학습 목표
- 요구시 페이징을 설명할 수 있다.
- 페이지 교체 정책을 설명할 수 있다.
학습 내용
- Demand Paging
- Page Replacement Algorithms
- Thrashing
Virtual memory는 컴퓨터 시스템에서 메모리 관리를 효율적으로 할 수 있게 도와주는 기술이다. 이를 통해 여러 프로세스를 동시에 실행할 수 있고, 컴퓨터의 실제 물리 메모리 크기보다 큰 프로그램도 실행할 수 있게 해준다.
Virtual Memory Concepts
Restricted physical memory size
- Programs larger than the available space of the physical memory cannot be executed.
General program execution pattern
- Only a part of a program is executed, but not the entire program.
- Error codes and exception code
- Array 100x100 elements, but only 10x10 elements used.
- Certain options and features of programs may be used rarely.
- Even when the entire program is needed, it may not all be needed at the same time.
Restricted physical memory size
물리 메모리의 크기에는 한계가 있어서, 그 크기를 초과하는 프로그램은 실행할 수 없다. Virtual memory는 이 문제를 해결하기 위해 프로그램을 여러 조각으로 나누어 물리 메모리에 로드할 수 있게 도와준다.
General program execution pattern
실제로 프로그램의 일부분만 실행되는 경우가 많다. 이를 이용하여 필요한 부분만 메모리에 로드하고, 나머지는 디스크에 두는 것이 가능하다. 이를 통해 물리 메모리를 절약할 수 있다.
Virtual Memory Concepts
Virtual memory
- Allows the execution of processes that are not completely in memory.
- Part of the program needs to be in memory for execution.
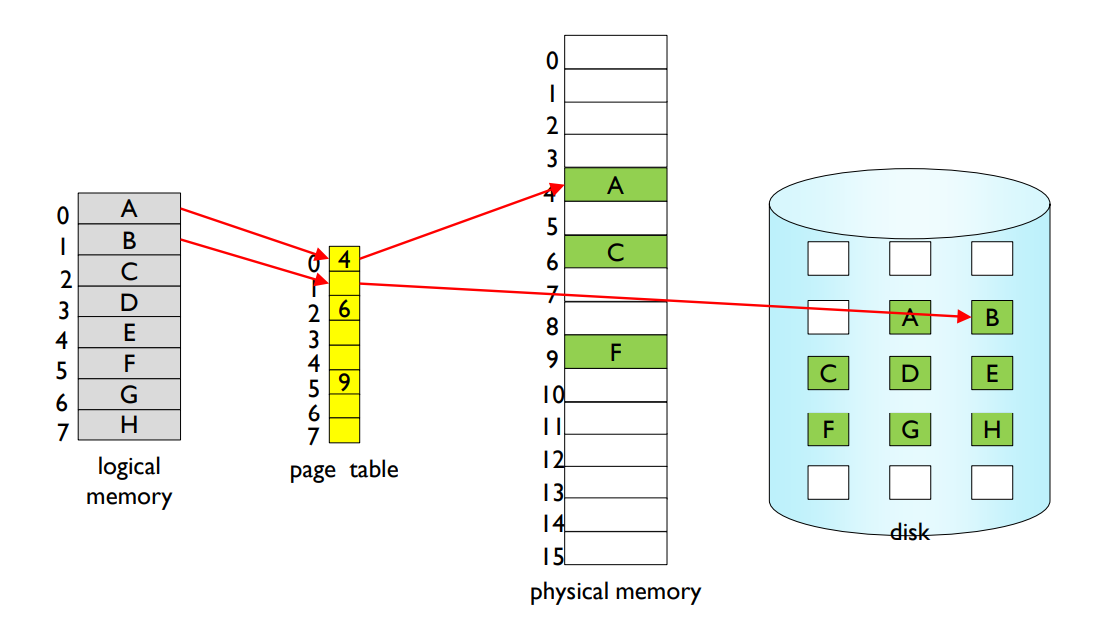
- Separation of logical memory address space from physical memory address space.
- Logical memory address space can be larger than physical memory address space.
Virtual memory
Virtual memory는 프로그램이 실제 물리 메모리에 완전히 로드되지 않아도 실행할 수 있게 합니다. 프로그램의 일부분만 메모리에 로드되어 실행되기 때문에 물리 메모리의 공간을 효율적으로 활용할 수 있습니다.
논리 메모리 주소 공간(logical memory address space)과 물리 메모리 주소 공간(physical memory address space)을 분리하는 방법은 주로 MMU(Memory Management Unit)를 사용하여 이루어진다. MMU는 CPU와 물리 메모리 사이에 위치하며, 논리 주소를 물리 주소로 변환하는 역할을 한다. 이 과정은 주소 변환(address translation)이라고도 부른다.
주소 변환을 위해, 운영체제는 페이지 테이블(page table)이라는 데이터 구조를 사용한다. 페이지 테이블은 논리 주소와 물리 주소 사이의 매핑을 저장하고 있다. 페이지 테이블은 메모리 내에 존재하며, 운영체제와 MMU에 의해 관리된다.
논리 주소를 물리 주소로 변환하는 과정은 다음과 같다:
- 프로세스가 논리 주소를 생성하여 메모리에 접근하려고 한다.
- 논리 주소는 페이지 번호(page number)와 오프셋(offset)으로 분리된다.
- 페이지 번호는 페이지 테이블을 참조하여 해당 페이지가 매핑되어 있는 물리 메모리의 프레임 번호(frame number)로 변환된다.
- 프레임 번호와 오프셋이 결합되어 최종적인 물리 주소가 생성된다.
- MMU는 물리 주소를 사용하여 메모리에 접근하고, 해당 데이터를 CPU에 전달한다.
이러한 방식을 통해 논리 메모리 주소 공간과 물리 메모리 주소 공간이 분리되어 관리되며, 메모리를 효율적으로 사용할 수 있다. 이 과정을 통해 프로세스는 자신만의 독립된 논리 메모리 주소 공간을 가질 수 있고, 물리 메모리 공간은 여러 프로세스 간에 공유된다.
Virtual Memory Concepts
Virtual Address Space
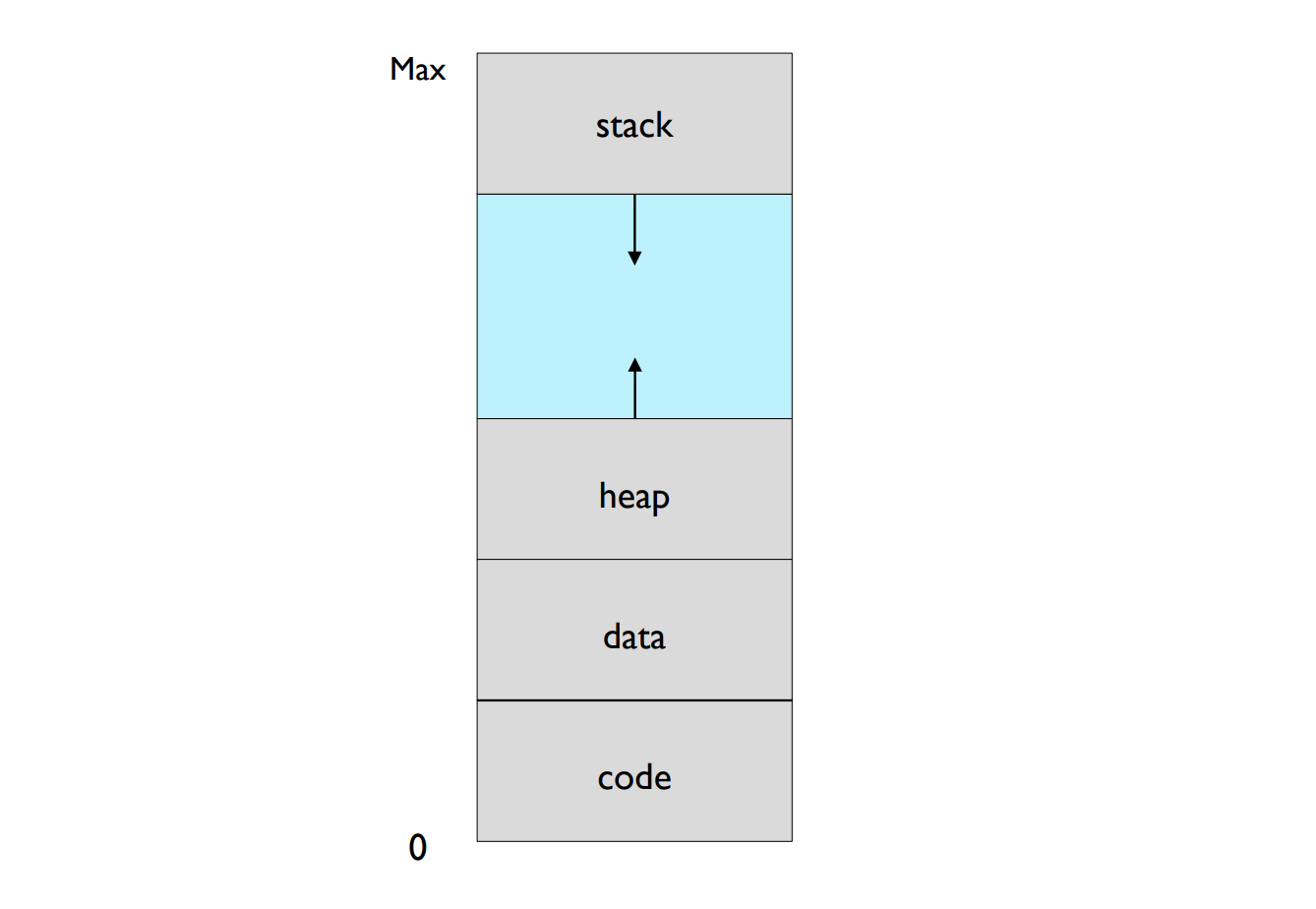
Virtual Address Space(가상 주소 공간)은 프로세스가 메모리에 접근할 때 사용하는 가상 메모리 주소의 범위이다. 프로세스는 가상 주소 공간 내의 주소를 사용하여 메모리에 데이터를 읽거나 쓸 수 있다. 가상 주소 공간은 논리 주소 공간(logical address space)이라고도 불린다.
Virtual address space는 물리 메모리 주소 공간과 구분되어 관리되며, 일반적으로 물리 메모리 주소 공간보다 크게 설정할 수 있다. 이를 통해 프로세스는 실제 물리 메모리 크기에 상관없이 큰 메모리 공간을 사용할 수 있게 된다.
가상 주소 공간은 메모리 관리의 기본 단위인 페이지(page)로 나누어진다. 각 페이지는 일정한 크기를 가지며, 디스크에 저장되어 있는 페이지들 중 일부가 필요한 경우 물리 메모리에 로드된다. 이를 통해 실제로 사용되는 페이지들만 물리 메모리에 올려 놓을 수 있어 메모리 사용 효율이 증가한다.
가상 주소 공간은 일반적으로 다음과 같은 영역으로 구성된다:
- Code segment (코드 세그먼트): 프로그램의 실행 코드가 저장되는 영역이다. 일반적으로 읽기 전용으로 설정되어 있다.
- Data segment (데이터 세그먼트): 전역 변수와 정적 변수가 저장되는 영역이다. 읽기와 쓰기가 가능한다.
- Stack (스택): 함수 호출과 지역 변수 관리를 위한 영역이다. 스택은 후입선출(LIFO, Last In First Out) 방식으로 동작한다.
- Heap (힙): 동적 메모리 할당을 위한 영역이다. 프로그래머가 직접 메모리를 할당하고 해제할 수 있다.
가상 주소 공간의 관리는 운영체제와 메모리 관리 유닛(MMU)이 담당하며, 논리 주소를 물리 주소로 변환하는 주소 변환 과정을 통해 물리 메모리에 접근할 수 있다. 이를 통해 여러 프로세스가 동시에 실행되어도 각각의 프로세스가 독립된 메모리 공간을 가질 수 있고, 시스템의 메모리를 효율적으로 사용할 수 있다.
Demand Paging
Virtual memory can be implemented via demand paging.
Bring a page into memory only when it is needed.
- Less I/Os are needed.
- Less memory is needed.
Needs to allow pages to be swapped in and out.
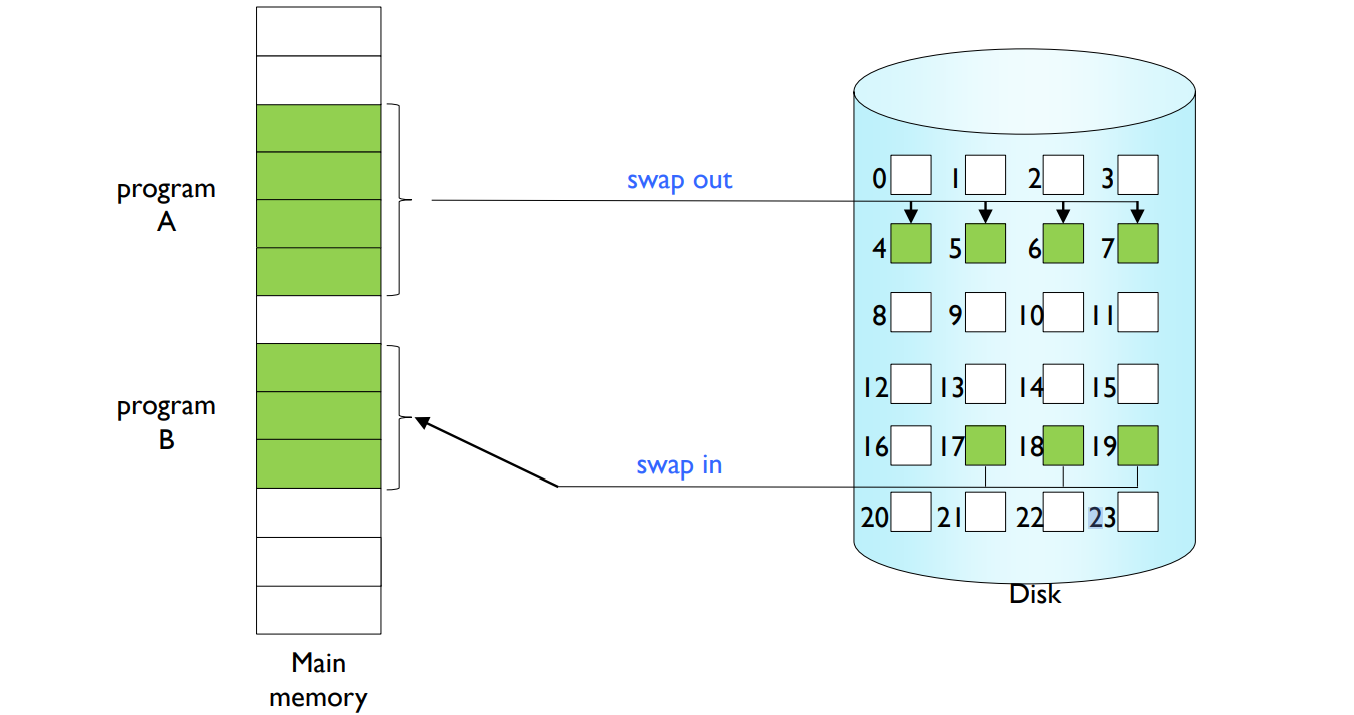
When a page is referenced,
- valid reference → reference it.
- invalid reference → not-in-memory → bring it into memory.
valid–invalid bit is associated with each page table entry.
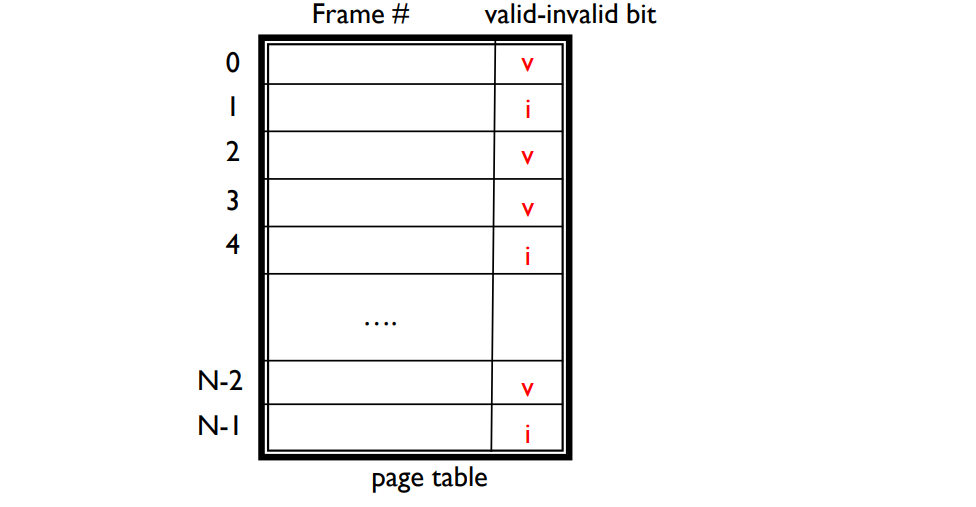
- v → in-memory
- i → not-in-memory or not legal (bad address, protection violation)
- During address translation, if valid–invalid bit is i, page fault.
Page table when some pages are not in main memory.
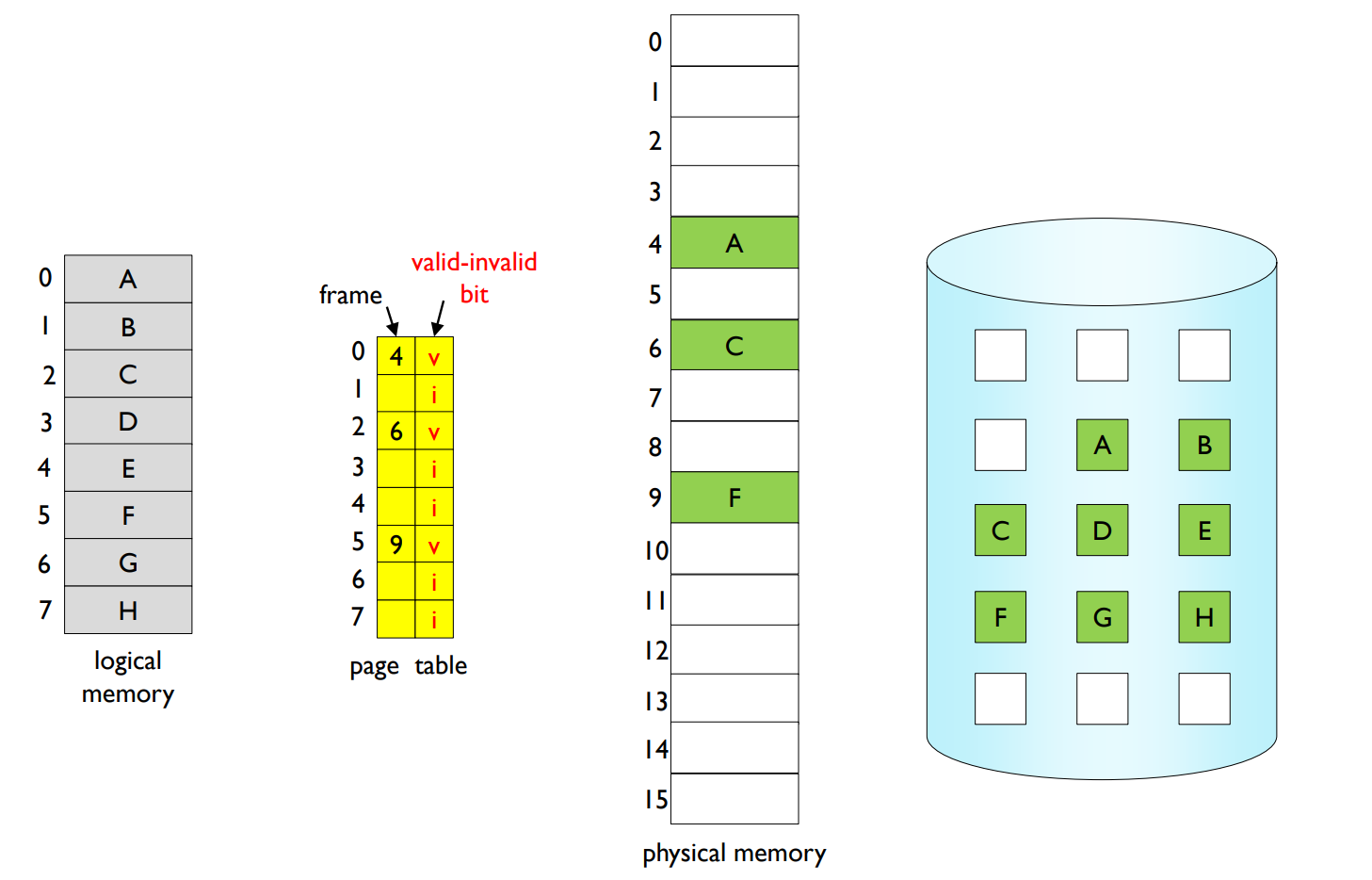
Access to invalid page causes page fault.
- → Page fault handler within OS is invoked.
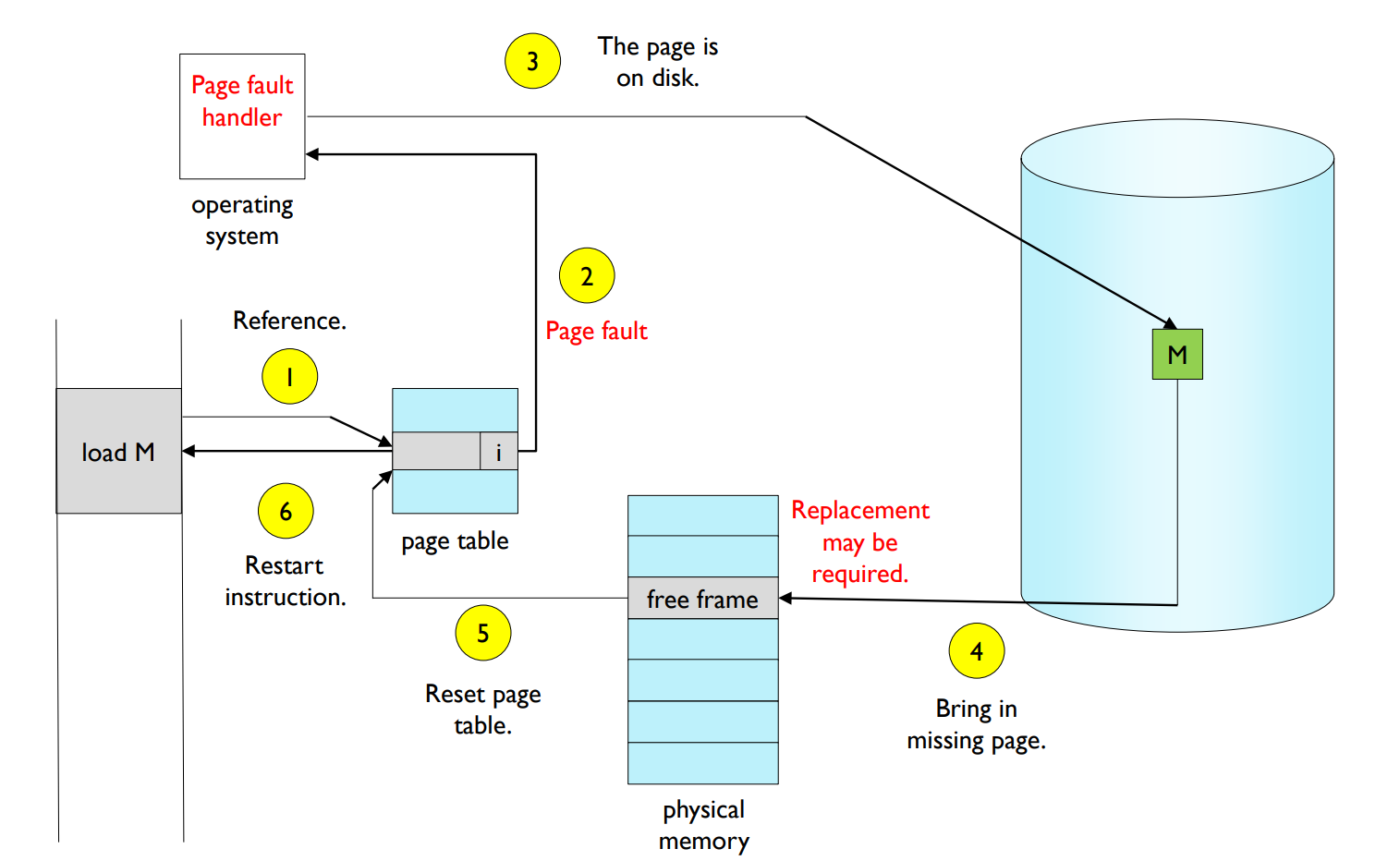
Page fault handler deals with the page fault as follows.
- 1.invalid reference?
- If bad address or protection violation → abort process.
- If not in memory → continue the followings.
- 2.get empty page frame.
- If no empty page frames, replace some page frames.
- 3.read the page into the page frame.
- This process is blocked until the disk I/O is performed.
- When the disk I/O is completed, set the page tables entry to valid.
- Insert the process into ready queue again, and dispatch later.
- 4.restart the instruction that caused the page fault.
Page fault handling
Page Fault Rate 0 ≤ p ≤ 1.0
- if p = 0, no page faults.
- if p = 1, every reference is a fault.
Effective Access Time (EAT)
- EAT = (1 – p) x memory access time + p x page fault service time
- Example
- Memory access time = 200 ns
- Average page fault service time = 8 ms (=8,000,000ns)
- EAT = (1 – p) x 200 + p x 8,000,000 = 200 + p x 7,999,800
- If one access out of 1,000 causes a page fault, then
- EAT = 8,200 ns
- This is a slowdown by a factor of 40.
It is important to keep the page fault rate low.
- Good page replacement policy is required.
Demand Paging은 가상 메모리를 구현하는 한 가지 방법이다. 이 방식에서는 페이지가 실제로 필요한 경우에만 메모리에 로드된다. 이로 인해 입출력(I/O) 횟수가 줄고 메모리 사용량도 줄어들게 된다. Demand Paging을 사용하려면 페이지가 메모리에 로드되거나 메모리에서 교체될 수 있는 기능이 필요하다.
페이지가 참조되었을 때 다음과 같은 경우를 구분할 수 있다:
- 유효한 참조(valid reference): 메모리에 있는 페이지에 대한 참조로, 해당 페이지를 참조할 수 있다.
- 유효하지 않은 참조(invalid reference): 메모리에 없는 페이지에 대한 참조로, 페이지를 메모리에 로드해야 한다.
각 페이지 테이블 항목에는 유효-무효 비트(valid-invalid bit)가 연결되어 있다. 이 비트는 페이지가 메모리에 있는지 (v) 아니면 메모리에 없거나 잘못된 주소나 보호 위반이 있는지 (i) 나타낸다. 주소 변환 과정에서 유효-무효 비트가 i인 경우 페이지 부재(page fault)가 발생한다.
유효하지 않은 페이지에 대한 접근이 페이지 부재를 발생시키면 운영 체제 내의 페이지 부재 처리기(page fault handler)가 호출된다. 페이지 부재 처리기는 다음과 같은 절차로 페이지 부재를 처리한다.
- 무효한 참조인지 확인한다.
-잘못된 주소거나 보호 위반이 있는 경우, 프로세스를 중단한다.
-메모리에 없는 경우, 다음 단계를 진행한다. - 비어있는 페이지 프레임을 가져온다.
-비어 있는 페이지 프레임이 없는 경우, 페이지 프레임을 교체한다. - 페이지를 페이지 프레임에 읽어온다.
-디스크 I/O가 완료될 때까지 프로세스가 차단된다.
-디스크 I/O가 완료되면 페이지 테이블 항목을 유효하게 설정한다.
-프로세스를 다시 준비 대기열에 삽입하고 나중에 디스패치한다. - 페이지 부재를 발생시킨 명령을 다시 시작한다.
페이지 부재율(page fault rate)은 0에서 1 사이의 값으로, 페이지 부재가 발생하는 비율을 나타낸다. 이 값이 높을수록 시스템 성능이 저하된다. 따라서 효과적인 페이지 교체 정책이 필요하다.
Page Replacement
- Page replacement
- find some page not really in use → swap it out.
- Good page replacement algorithm
- results in minimum number of page faults.
- Locality of reference
- Same pages may be brought into memory several times.
- 실제 대부분의 프로그램에서 관찰되는 현상임.
- 일정 시간에 극히 일부 page 만 집중적으로 reference하는 program behavior
- Loop
- Paging system이 성능이 좋게 되는 근거임.
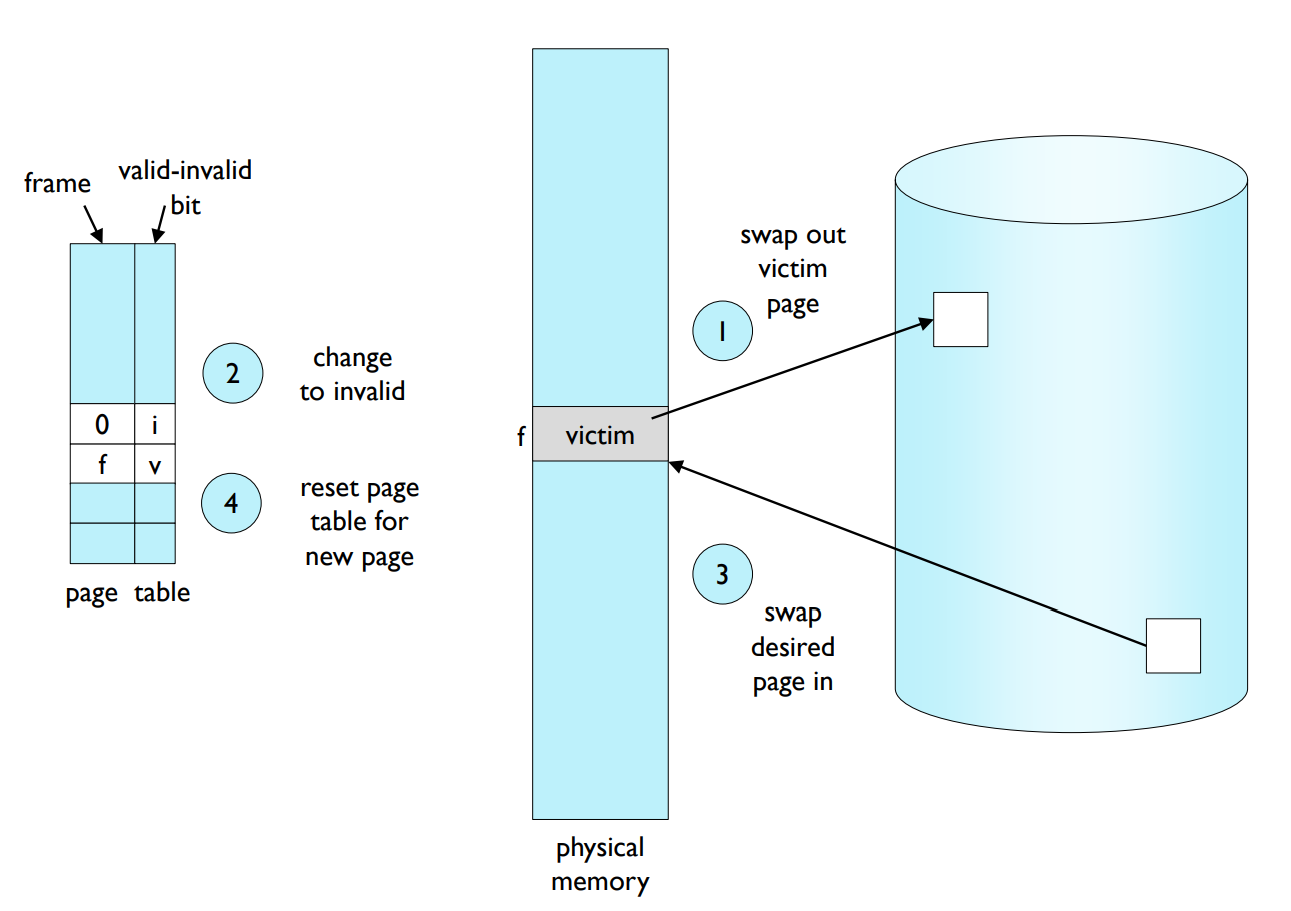
Page fault handler including page replacement.
- Find the location of the desired page on disk.
- Find a free frame.
-If there is a free frame, use it.
-If there is no free frame, use a page replacement algorithm to select a victim. - Bring the desired page into the (newly) free frame; update the page tables.
- Restart the process.
- Ideal algorithm
- gains the lowest page-fault rate.
- Algorithm can be evaluated by
- running it on a particular string of memory references,
- reference string.
- and computing the number of page faults on that string.
- running it on a particular string of memory references,
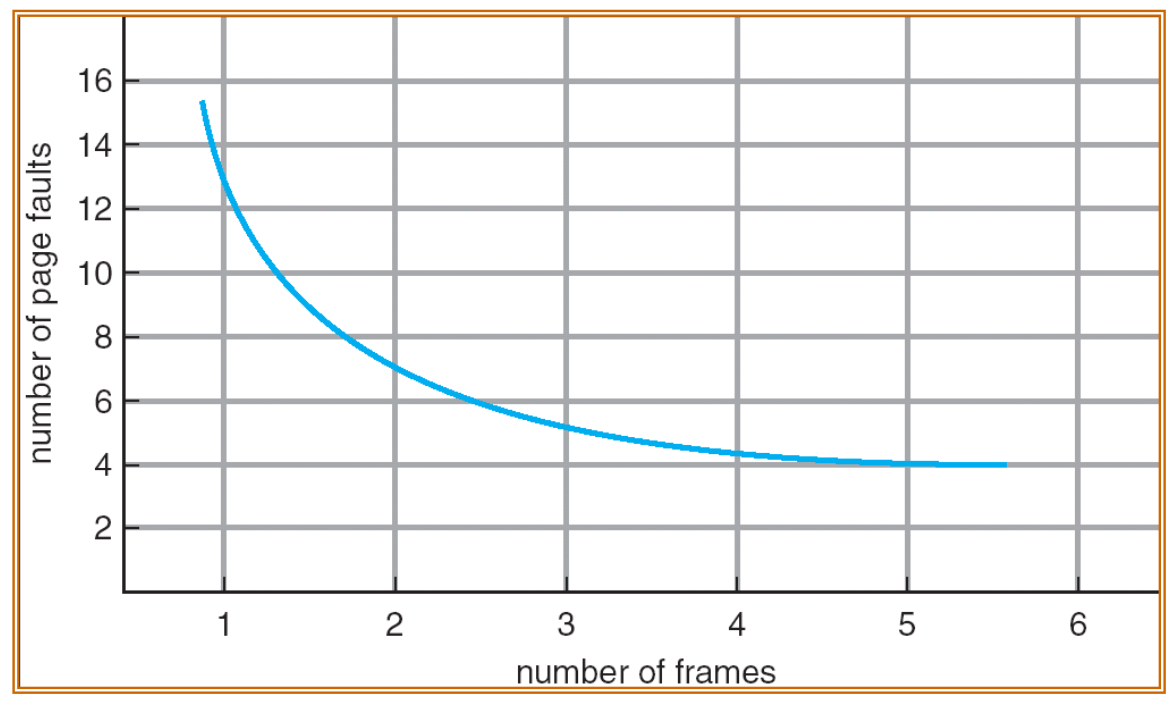
- In some examples, the reference string is
- 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
- The number of page faults vs. The number of frames
페이지 교체(Page Replacement)는 가상 메모리 시스템에서 페이지 부재가 발생할 때 사용되는 메커니즘이다. 이 과정에서는 현재 사용되지 않고 있는 페이지를 찾아 메모리에서 내보내고(스왑 아웃), 요청된 페이지를 메모리로 불러온다. 효과적인 페이지 교체 알고리즘은 페이지 부재 횟수를 최소화하는 결과를 가져온다.
참조 지역성(Locality of Reference)은 프로그램이 실행되는 동안 일부 페이지에 집중적으로 참조가 발생하는 현상이다. 이러한 현상은 대부분의 프로그램에서 관찰되며, 루프(loop)와 같은 구조에서 특히 두드러진다. 페이징 시스템의 성능 향상에 기여하는 요소이다.
페이지 부재 처리기에 페이지 교체를 포함하면 다음과 같은 과정을 거친다.
- 디스크에서 원하는 페이지의 위치를 찾는다.
- 비어 있는 프레임을 찾는다.
-비어 있는 프레임이 있다면 사용한다.
-비어 있는 프레임이 없다면 페이지 교체 알고리즘을 사용하여 희생할 페이지를 선택한다. - 원하는 페이지를 (새롭게) 비어 있는 프레임에 가져옵니다. 페이지 테이블을 업데이트한다.
- 프로세스를 다시 시작한다.
페이지 교체 과정에서 다음과 같은 단계가 포함된다.
- Swap out victim page (희생 페이지 스왑 아웃): 페이지 교체 알고리즘에 따라 희생할 페이지를 선택하여 메모리에서 디스크로 이동시킨다.
- Change to invalid (유효하지 않음으로 변경): 희생된 페이지에 대한 페이지 테이블 항목의 valid–invalid 비트를 invalid로 설정한다. 이로써 해당 페이지가 메모리에 없음을 나타낸다.
- Swap desired page in (요청된 페이지 스왑 인): 요청된 페이지를 디스크에서 메모리로 불러온다.
- Reset page table for new page (새 페이지에 대한 페이지 테이블 재설정): 불러온 페이지에 대한 페이지 테이블 항목을 업데이트하고 valid–invalid 비트를 valid로 설정한다. 이로써 해당 페이지가 메모리에 존재함을 나타낸다.
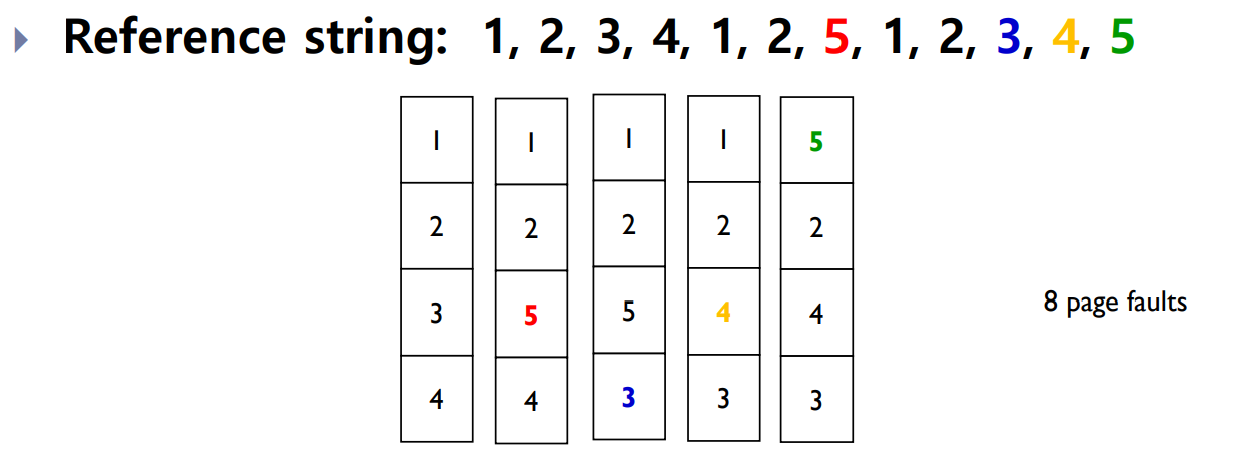
이상적인 알고리즘(Ideal Algorithm)은 가장 낮은 페이지 부재율을 얻는다. 알고리즘은 메모리 참조 문자열을 사용하여 평가할 수 있으며, 해당 문자열에서 발생하는 페이지 부재 횟수를 계산한다. 예를 들어 참조 문자열이 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 인 경우에 페이지 부재 횟수와 프레임 수를 비교할 수 있다.
페이지 부재 횟수(Number of Page Faults)와 프레임 수(Number of Frames)의 관계는 다음과 같다.
프레임 수가 증가할수록 전체적으로 페이지 부재 횟수가 감소하는 경향이 있다. 더 많은 메모리 프레임이 사용 가능할 때, 프로세스가 메모리에 더 많은 페이지를 저장할 수 있으므로 참조할 페이지가 이미 메모리에 존재할 가능성이 높아진다. 이로 인해 페이지 부재 횟수가 줄어든다.
그러나 프레임 수가 일정 수준 이상으로 증가하면 페이지 부재 횟수의 감소가 완만해질 수 있다. 이는 참조 지역성으로 인해 프로세스가 일부 페이지에만 집중적으로 접근하기 때문이다. 따라서 추가적인 프레임 할당이 페이지 부재 횟수를 크게 줄이지 못할 수 있다.
이러한 관계를 고려하여 시스템의 메모리 사용 효율과 성능을 최적화하기 위해서는 적절한 프레임 할당 및 페이지 교체 알고리즘을 사용해야 한다.
일반적으로 사용되는 페이지 교체 알고리즘에는 최적(Optimal), FIFO(First In First Out), LRU(Least Recently Used) 및 Clock 알고리즘이 있다. 이 알고리즘들은 각각의 장단점이 있으며, 애플리케이션의 특성과 요구 사항에 따라 적절한 알고리즘을 선택하는 것이 중요하다.
FIFO Page Replacement
- Replace page that replaces in FIFO (First In First Out) order.
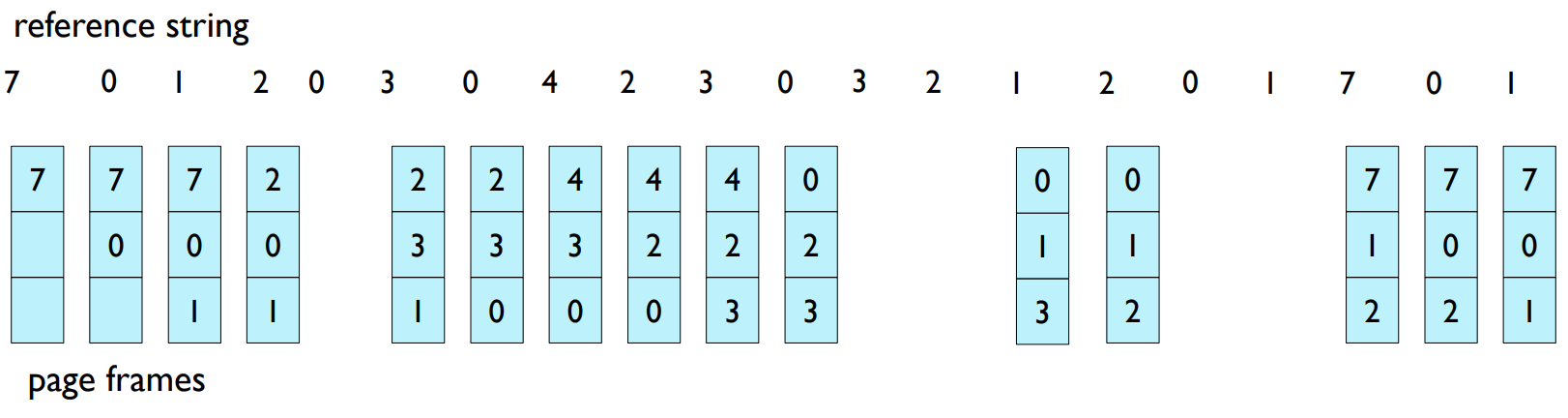
15 page faults
- Reference string
- 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
- 3 frames
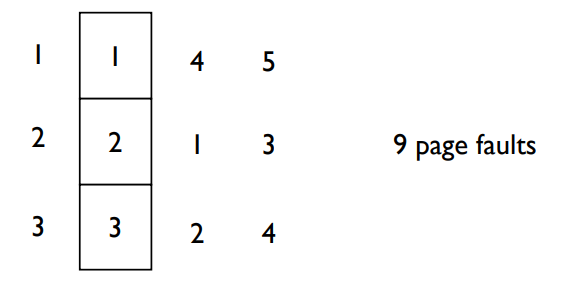
- 4 frames

- Belady’s Anomaly
- more frames → more page faults
FIFO (First In First Out) 페이지 교체 알고리즘은 메모리에 들어온 순서대로 페이지를 교체하는 방식입니다. 메모리에 먼저 들어온 페이지가 가장 먼저 교체됩니다. 이 알고리즘은 간단한 구현 방식을 가지고 있지만, 최적의 페이지 교체를 보장하지는 않습니다.
예시로 든 참조 문자열(reference string)은 다음과 같습니다.
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
이 참조 문자열에 대해 3개의 프레임으로 FIFO 알고리즘을 적용하면 아래와 같은 페이지 부재가 발생합니다.
[1, , ] → [1, 2, ] → [1, 2, 3] → [4, 2, 3] → [4, 1, 3] → [4, 1, 2] → [5, 1, 2] → [5, 1, 3] → [5, 4, 3] → [2, 4, 3] → [2, 4, 5]
이 경우 총 9번의 페이지 부재가 발생했습니다.
이 참조 문자열에 대해 4개의 프레임으로 FIFO 알고리즘을 적용하면 다음과 같은 페이지 부재가 발생합니다.
[1, , , _] → [1, 2, , ] → [1, 2, 3, _] → [1, 2, 3, 4] → [5, 2, 3, 4] → [5, 1, 3, 4] → [5, 1, 2, 4] → [5, 1, 2, 3] → [4, 1, 2, 3] → [4, 5, 2, 3]
이 경우 총 10번의 페이지 부재가 발생했습니다.
여기서 주목해야 할 것은 프레임 수가 늘어났음에도 페이지 부재 횟수가 증가했다는 점입니다. 이 현상을 벨라디의 이상(Belady's Anomaly)이라고 합니다. 벨라디의 이상은 FIFO 페이지 교체 알고리즘에서만 발생하며, 프레임 수가 증가함에도 페이지 부재가 더 많이 발생할 수 있다는 것을 보여줍니다.
결론적으로 FIFO 페이지 교체 알고리즘은 구현이 간단하지만, 벨라디의 이상으로 인해 최적의 페이지 교체를 보장하지 않습니다. 따라서 다른 알고리즘(예: 최적 페이지 교체 알고리즘, LRU 알고리즘 등)을 사용하여 더 나은 성능을 얻을 수 있습니다.
Optimal Page Replacement
- Another frames example
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
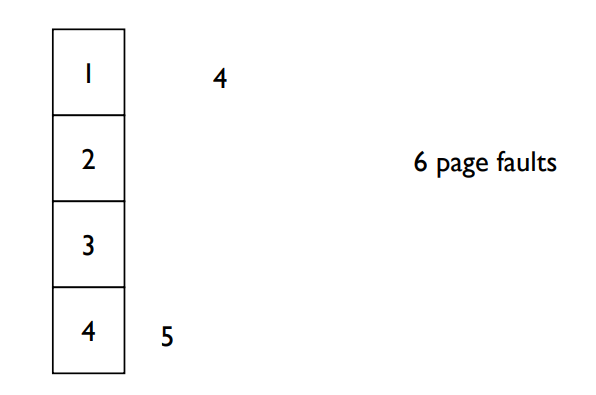
- How do you know this?
- Used for measuring how well your algorithm performs.
- Optimal algorithm presents lower bound of page fault rate.
Optimal Page Replacement
Optimal Page Replacement 알고리즘은 앞으로 참조할 페이지들에 대한 완벽한 정보가 있다고 가정하고, 가장 나중에 참조될 페이지를 교체하는 방식이다. 이 알고리즘은 실제로 구현할 수 없지만, 다른 페이지 교체 알고리즘들의 성능을 측정하는 기준으로 사용된다. Optimal 알고리즘은 페이지 부재율의 하한선을 제공하므로, 다른 알고리즘들은 이 기준에 가까울수록 더 효율적이라고 할 수 있다.
LRU (Least Recently Used)
- Replace page that used least recently.
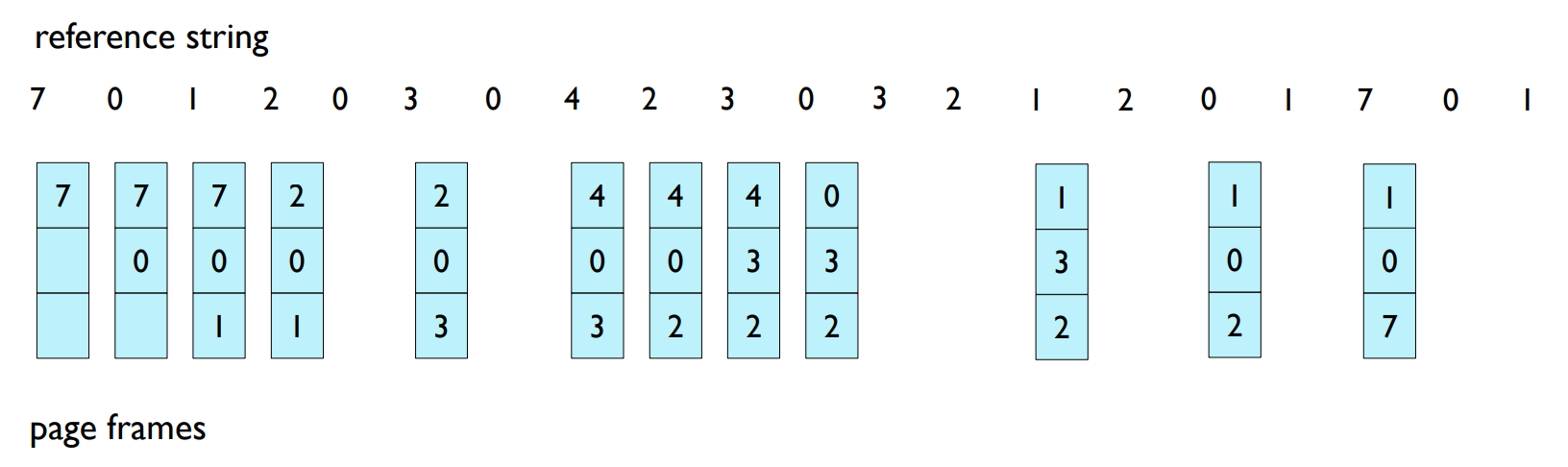
- How to implement it?
- Reference time should be recorded for each page.
- Page with the oldest reference time should be found.
- Too large space and time overhead
- → Many approximation algorithms are proposed.
- Counter implementation
- Every page entry has a counter.
- Whenever page is referenced, the clock is incremented.
- When page A is referenced, copy the clock into A’s counter.
- Replace the page with the smallest counter value.
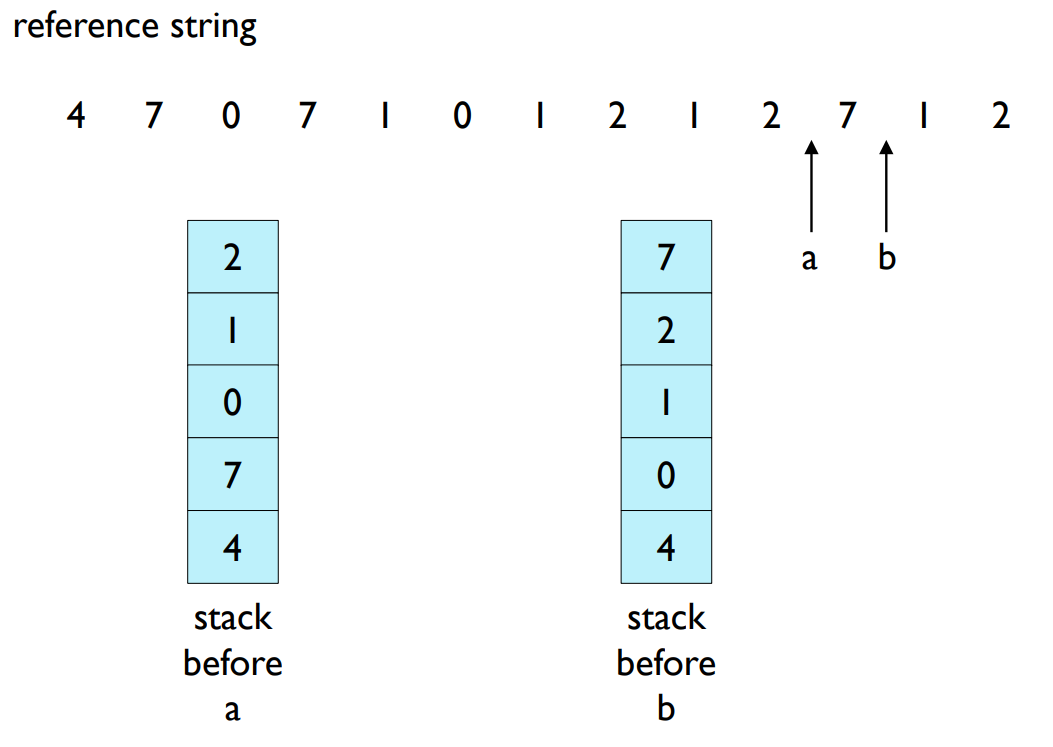
- Stack implementation
- keep a stack of pages.
- When a page is referenced, move it to the top.
- No search for replacement.
LRU (Least Recently Used)
LRU 알고리즘은 최근에 가장 적게 사용된 페이지를 교체하는 방식이다. 이 알고리즘의 목표는 최근 참조된 페이지들이 가까운 미래에 다시 참조될 가능성이 높다는 점에 기반하여, 오랫동안 사용되지 않은 페이지를 교체하는 것이다.
LRU 알고리즘을 구현하는 데는 여러 방법이 있다:
Counter implementation: 각 페이지 항목에 카운터를 두어 시간이 지날 때마다 카운터를 증가시키고, 페이지가 참조될 때마다 해당 페이지의 카운터에 시간 값을 복사한다. 가장 작은 카운터 값을 가진 페이지를 교체한다. 이 방법은 시간 및 공간 오버헤드가 크다는 단점이 있다.
Stack implementation: 페이지의 스택을 유지한다. 페이지가 참조될 때마다 스택의 상단으로 이동시킨다. 이 방법에서는 교체할 페이지를 찾는 과정이 필요하지 않는다. 최근에 사용되지 않은 페이지는 스택의 바닥에 위치하게 된다.
LRU 알고리즘은 완벽한 구현에 상당한 오버헤드가 따르기 때문에, 다양한 근사 알고리즘이 제안되었다. 이러한 근사 알고리즘들은 LRU의 기본 아이디어를 따르면서, 성능과 오버헤드 간의 균형을 찾으려고 한다.
LRU Approximation Algorithms
- For LRU page replacement,
- many systems provide hardware supports.
- Reference bit
- A bit for each page, initially is set to 0.
- When page is referenced, it is set to 1.
- Replace the one which is 0. (if one exists)
- But, we do not know the reference order.
- Second chance page replacement algorithm (clock algorithm)
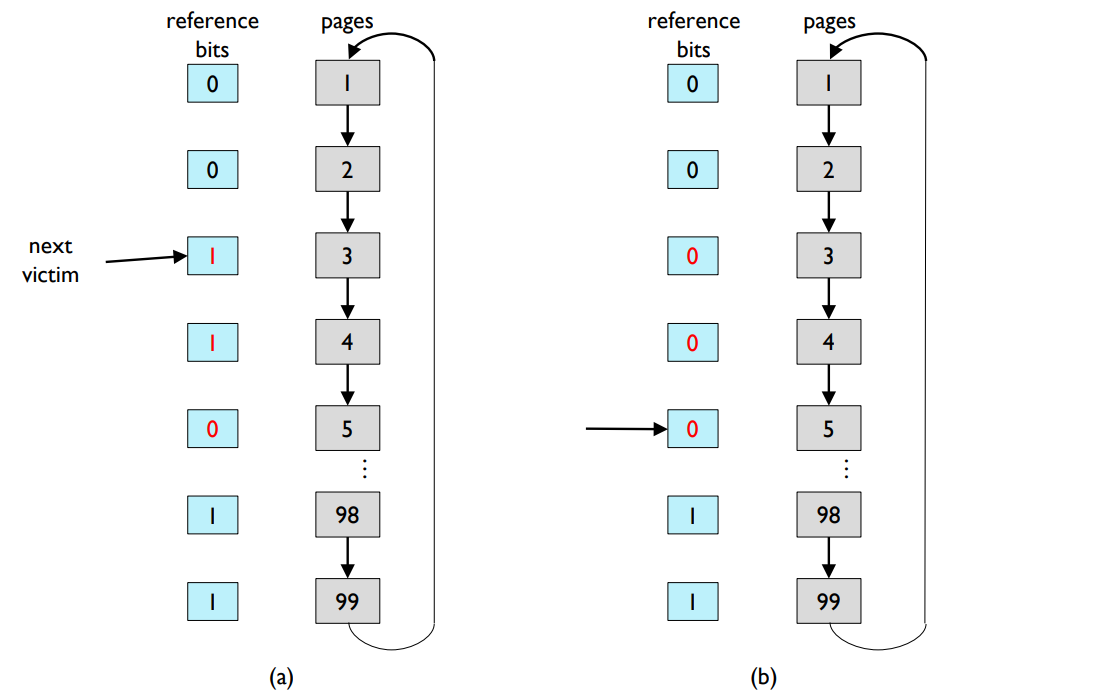
- If page to be replaced has reference bit 1,
- leave page in memory.
- set reference bit 0.
- advance pointer for next victim until it finds a page with reference bit 0.
LRU Approximation Algorithms
실제 시스템에서 LRU 페이지 교체를 구현하기 위해 하드웨어 지원이 제공되는 경우가 많습니다. 하나의 대표적인 방법은 참조 비트(Reference bit)를 사용하는 것입니다. 각 페이지마다 참조 비트가 있으며, 초기에는 0으로 설정됩니다. 페이지가 참조되면 비트가 1로 설정되며, 교체할 페이지를 찾을 때 0인 페이지를 선택합니다. 하지만 이 방식으로는 참조 순서를 알 수 없습니다.
두 번째 기회 페이지 교체 알고리즘(Second chance page replacement algorithm) 또는 클록 알고리즘(Clock algorithm)은 LRU 근사 알고리즘 중 하나입니다. 이 알고리즘에서는 교체할 페이지의 참조 비트가 1인 경우, 페이지를 메모리에 그대로 두고 참조 비트를 0으로 설정한 뒤 다음 희생자를 찾을 때까지 포인터를 전진시킵니다.
Counting Algorithms
- LFU (Least Frequently Used) Algorithm
- Keep the number of references that have been made.
- Replaces page with smallest count.
Counting Algorithms
LFU(Least Frequently Used) 알고리즘은 각 페이지에 대한 참조 횟수를 계산하여 가장 적게 참조된 페이지를 교체하는 방식입니다. 이 알고리즘은 참조 빈도를 기준으로 페이지를 교체합니다.
Allocation
- The previous replacement algorithm
- When page fault occurs, choose victim.
- They assumed fixed allocation, not variable allocation.
- Why not consider allocating one more page frames at page fault?
- When page fault occurs, choose victim.
- Allocation problem
- Decide allocation size at page fault.
- fixed allocation
- priority allocation
- Decide allocation size at page fault.
할당
지금까지 살펴본 페이지 교체 알고리즘들은 페이지 부재가 발생했을 때 희생자를 선택하는 방식을 사용했습니다. 이들 알고리즘은 고정 할당(fixed allocation)을 가정했지만, 페이지 부재가 발생했을 때 페이지 프레임을 하나 더 할당하는 가변 할당(variable allocation)을 고려할 수도 있습니다.
할당 문제(Allocation problem)는 페이지 부재가 발생했을 때 할당 크기를 결정하는 문제입니다. 이를 위한 방식으로는 고정 할당(fixed allocation)과 우선순위 할당(priority allocation)이 있습니다. 고정 할당은 각 프로세스에 고정된 개수의 페이지 프레임을 할당하는 반면, 우선순위 할당은 프로세스의 우선순위에 따라 페이지 프레임을 할당하는 방식입니다.
Fixed Allocation
- Equal allocation
- If there are 100 frames and 5 processes,
- give each process 20 frames.
- If there are 100 frames and 5 processes,
- Proportional allocation
- Allocate according to the size of process.
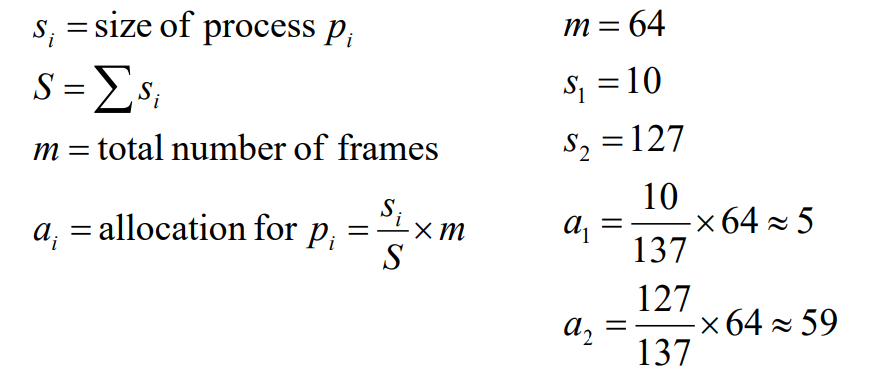
- Allocate according to the size of process.
Fixed Allocation
Equal allocation은 시스템이 사용 가능한 프레임을 모든 프로세스에 동일하게 분배하는 방식입니다. 예를 들어, 시스템이 100개의 프레임을 가지고 있고, 실행 중인 프로세스가 5개라면 각 프로세스에게 20개의 프레임이 할당됩니다. 이 방법은 간단하고 공평하지만, 프로세스의 크기나 요구사항에 따라 비효율적일 수 있습니다.
Proportional allocation은 프로세스의 크기에 따라 메모리를 할당하는 방식입니다. 큰 프로세스는 작은 프로세스보다 더 많은 프레임을 할당받습니다. 이 방법은 프로세스의 크기와 요구사항을 반영하므로 더 공평하고 효율적일 수 있습니다.
Priority Allocation
- Use a proportional allocation scheme
- using priorities rather than size
- Give more memory to higher process
Priority Allocation
Priority allocation은 프로세스의 우선순위에 따라 메모리를 할당하는 방식입니다. 높은 우선순위의 프로세스는 낮은 우선순위의 프로세스보다 더 많은 메모리를 할당받습니다. 이 방법은 중요한 작업에 더 많은 자원을 투자할 수 있지만, 낮은 우선순위의 작업이 메모리를 부족하게 겪을 수 있다는 단점이 있습니다.
Global vs. Local Allocation
- Global replacement
- Process selects a replacement frame from the set of all frames.
- One process can take a frame from another.
- Local replacement
- Each process selects from only its own set of allocated frames.
Global vs. Local Allocation
Global replacement는 모든 프레임에서 교체할 프레임을 선택하는 방식입니다. 즉, 한 프로세스는 다른 프로세스의 프레임을 가져갈 수 있습니다. 이 방식은 시스템 전체의 메모리 사용을 최적화할 수 있지만, 한 프로세스가 다른 프로세스의 성능에 영향을 미칠 수 있다는 단점이 있습니다.
Local replacement는 각 프로세스가 자신에게 할당된 프레임만 교체하는 방식입니다. 이 방식은 프로세스 간의 간섭을 최소화하지만, 전체 시스템의 메모리 사용을 최적화하는 데는 한계가 있습니다.
Thrashing
- If a process does not have “enough” pages, page fault rate is very high.
- low CPU utilization
- Operating system thinks that
- it needs to increase the degree of multiprogramming.
- Another process is added to the system.
- Thrashing
- A process is busy in swapping pages in and out.
- A process is busy in swapping pages in and out.
- Why does thrashing occur?
- Σ size of locality > total memory size
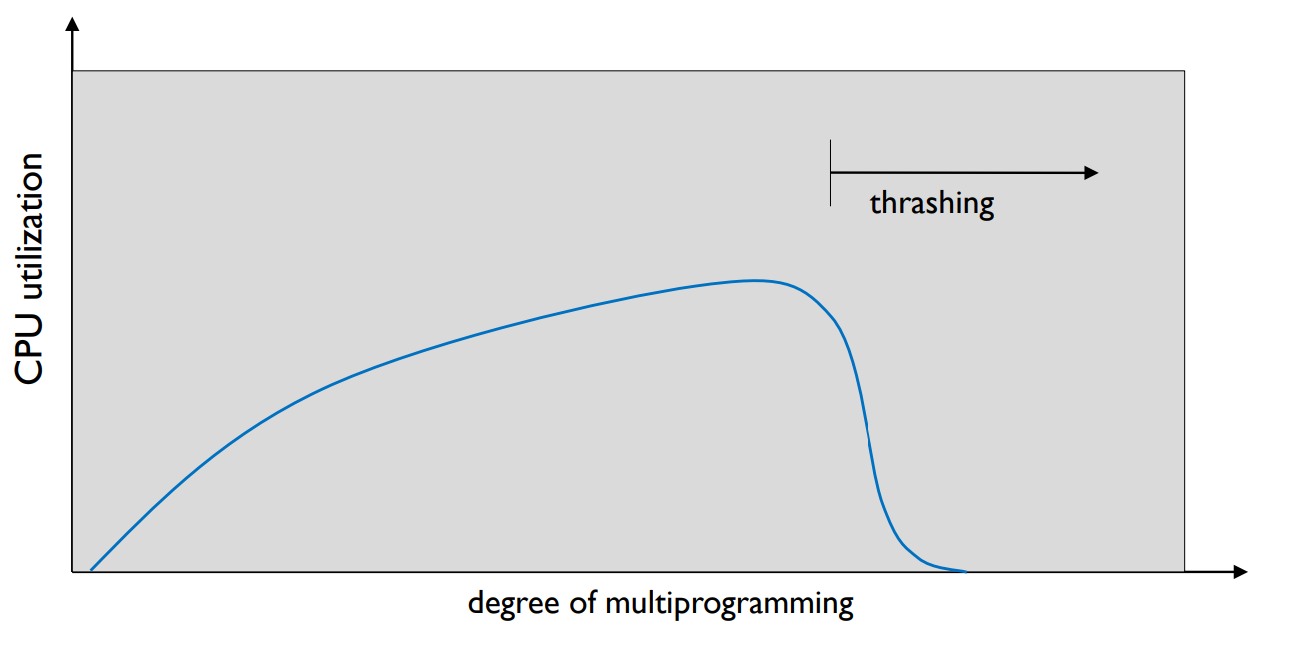
- Σ size of locality > total memory size
Thrashing
스레싱은 프로세스가 충분한 페이지를 가지지 않을 때 발생합니다. 이 경우, 페이지 폴트 (페이지를 메모리에 가져오는 작업)의 비율이 매우 높아집니다. 이는 CPU 이용률을 크게 떨어뜨리게 되며, 운영체제는 다중 프로그래밍의 정도를 증가시켜야 한다고 판단할 수 있습니다. 따라서 시스템에 또 다른 프로세스가 추가되고, 프로세스는 페이지를 들여오고 내보내는 작업에 바쁘게 됩니다. 이렇게 프로세스가 페이지를 교환하는 데 많은 시간을 소비하는 현상을 스레싱이라고 합니다.
스레싱이 발생하는 주요 원인은 모든 프로세스의 locality(메모리 참조 패턴의 일부)의 합이 전체 메모리 크기보다 클 때입니다. 이 경우, 모든 프로세스가 필요로 하는 메모리가 충분하지 않으므로, 각 프로세스는 페이지를 계속해서 스왑해야 합니다.
Working-set Model
- Locality in a memory-reference pattern
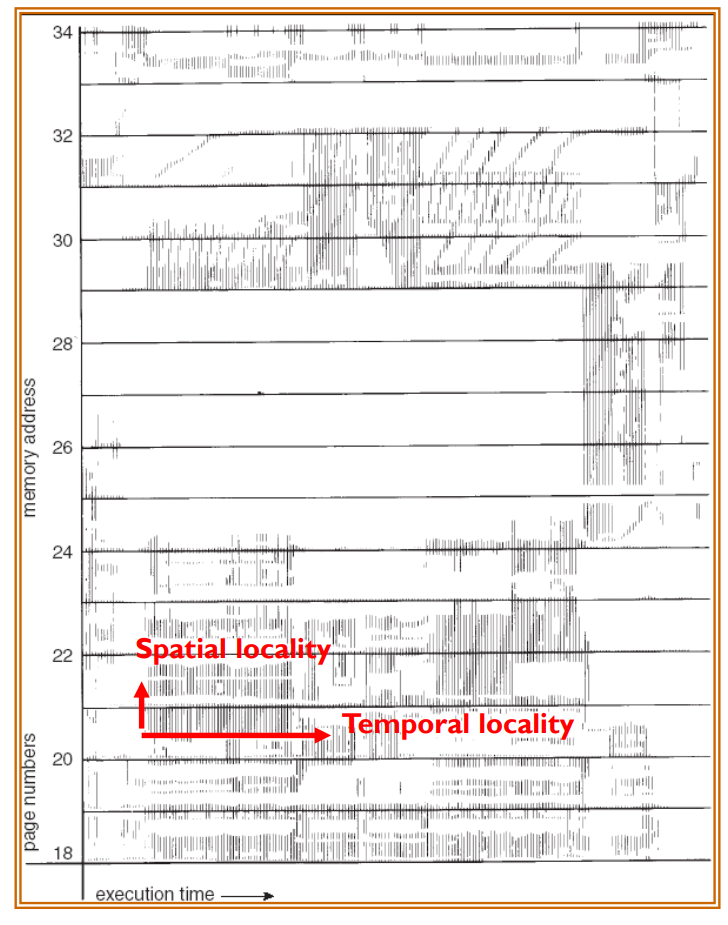
- Temporal locality: reuse of specific data and/or resources within relatively small time durations.
- Spatial locality: use of data elements within relatively close storage locations.
Working-set Model
워킹셋 모델은 프로세스의 메모리 참조 패턴을 모델링하는 방법입니다. 메모리 참조 패턴은 일반적으로 locality를 가지며, 이는 시간적 locality와 공간적 locality로 구분됩니다.
Temporal locality은 특정 데이터 또는 자원이 상대적으로 짧은 시간 동안 재사용되는 경향을 나타냅니다. 예를 들어, 루프 내에서 변수를 반복적으로 사용하는 경우가 이에 해당합니다.
Spatial locality은 상대적으로 가까운 저장 위치의 데이터 요소가 사용되는 경향을 나타냅니다. 예를 들어, 배열의 연속적인 요소를 참조하는 경우가 이에 해당합니다.
워킹셋 모델에서는 이런 locality를 사용하여 각 프로세스가 얼마나 많은 메모리를 필요로 하는지를 추정하고, 이를 바탕으로 메모리를 효과적으로 할당하려고 합니다. 이렇게 하면 스레싱을 방지하고 시스템의 성능을 개선할 수 있습니다.
Working-set Model
-
Working set model
- is based on the assumption of locality.
- ∆ ≡ working-set window ≡ a fixed number of page references
-
WSSi (working set of Process Pi)
- total number of pages referenced in the most recent ∆
- if ∆ is too small, it will not encompass entire locality.
- if ∆ is too large, it will encompass several localities.
- if ∆ = ∞, it will encompass entire program.
- total number of pages referenced in the most recent ∆
-
D = Σ WSSi ≡ total demand frames
- If D > m , Thrashing.
- → suspend one of the processes.
-
Working set example
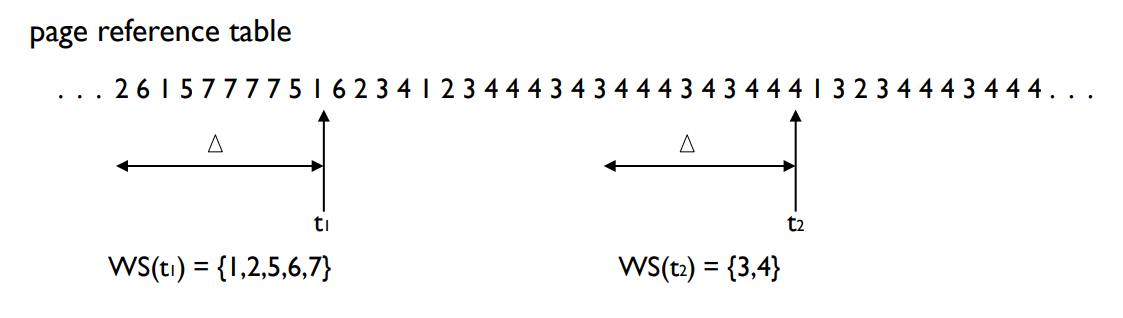
Working-set Model
워킹셋 모델은 프로세스의 locality, 즉 메모리 참조 패턴에 기반합니다. 워킹셋 윈도우(∆)는 고정된 페이지 참조 수를 나타냅니다. 워킹셋의 크기 (WSSi, Process Pi의 워킹셋)는 가장 최근 ∆ 내에서 참조된 페이지의 총 수입니다.
워킹셋 윈도우 ∆의 크기 선택은 중요한데, 너무 작으면 전체 locality를 포함하지 못하고, 너무 크면 여러 locality를 포함하게 됩니다. ∆가 무한대라면 전체 프로그램을 포함하게 됩니다.
D는 모든 프로세스의 워킹셋 크기의 합계를 나타내며, 이를 요구 프레임의 총합이라고 합니다. D가 전체 사용 가능 메모리(m)보다 크면, 스레싱이 발생합니다. 이 경우, 시스템은 하나 이상의 프로세스를 중단(서스펜드)해야 합니다.
Page-Fault Frequency Scheme
- Establish “acceptable” page-fault rate.
- If actual rate is too low, process loses frame.
- If actual rate is too high, process gains frame.
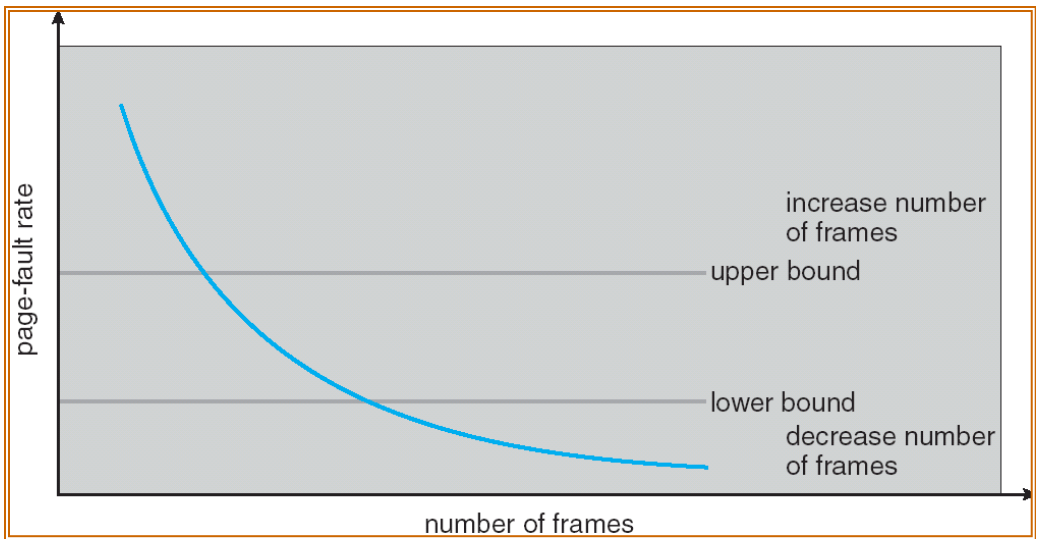
Page-Fault Frequency Scheme
페이지 폴트 빈도 스킴은 "수용 가능한" 페이지 폴트 비율을 설정합니다. 실제 비율이 너무 낮으면 프로세스는 프레임을 잃게 되고, 비율이 너무 높으면 프로세스는 프레임을 얻게 됩니다.
이러한 방식을 통해 시스템은 페이지 폴트 비율을 적절한 범위 내에서 유지하려고 시도하며, 이를 통해 스레싱을 방지하고 시스템 성능을 개선하려고 합니다.
Summary
- Virtual memory is a mechanism that allows the execution of processes that are not completely in memory.
- In demand paging. a page is brought into the memory only when it is needed.
- It is important to keep the page fault rate low. To this end, good page replacement policy is required.
- LRU (Least Recently Used) replaces page that used least recently.
- Thrashing occurs if a process does not have enough page frames.
요약
가상 메모리는 완전히 메모리에 존재하지 않는 프로세스의 실행을 가능하게 하는 메커니즘입니다. 수요 페이징에서는 필요할 때만 페이지가 메모리로 가져와집니다. 페이지 폴트 비율을 낮게 유지하는 것이 중요하며, 이를 위해 좋은 페이지 교체 정책이 필요합니다. 가장 최근에 사용되지 않은 페이지를 교체하는 LRU (Least Recently Used) 알고리즘이 있습니다. 만약 프로세스가 충분한 페이지 프레임을 가지지 못하면 스레싱이 발생할 수 있습니다.
