학습 목표 및 학습 내용
학습 목표
- 주소 바인딩 개념을 설명할 수 있다.
- 연속적인 메모리 할당의 장단점을 설명할 수 있다.
- 페이징 기법을 설명할 수 있다.
- 세그먼테이션 기법을 설명할 수 있다.
학습 내용
- Address binding
- MMU (Memory Management Unit)
- Contiguous allocation
- Paging
- Segmentation
Multistep Processing of a User Program
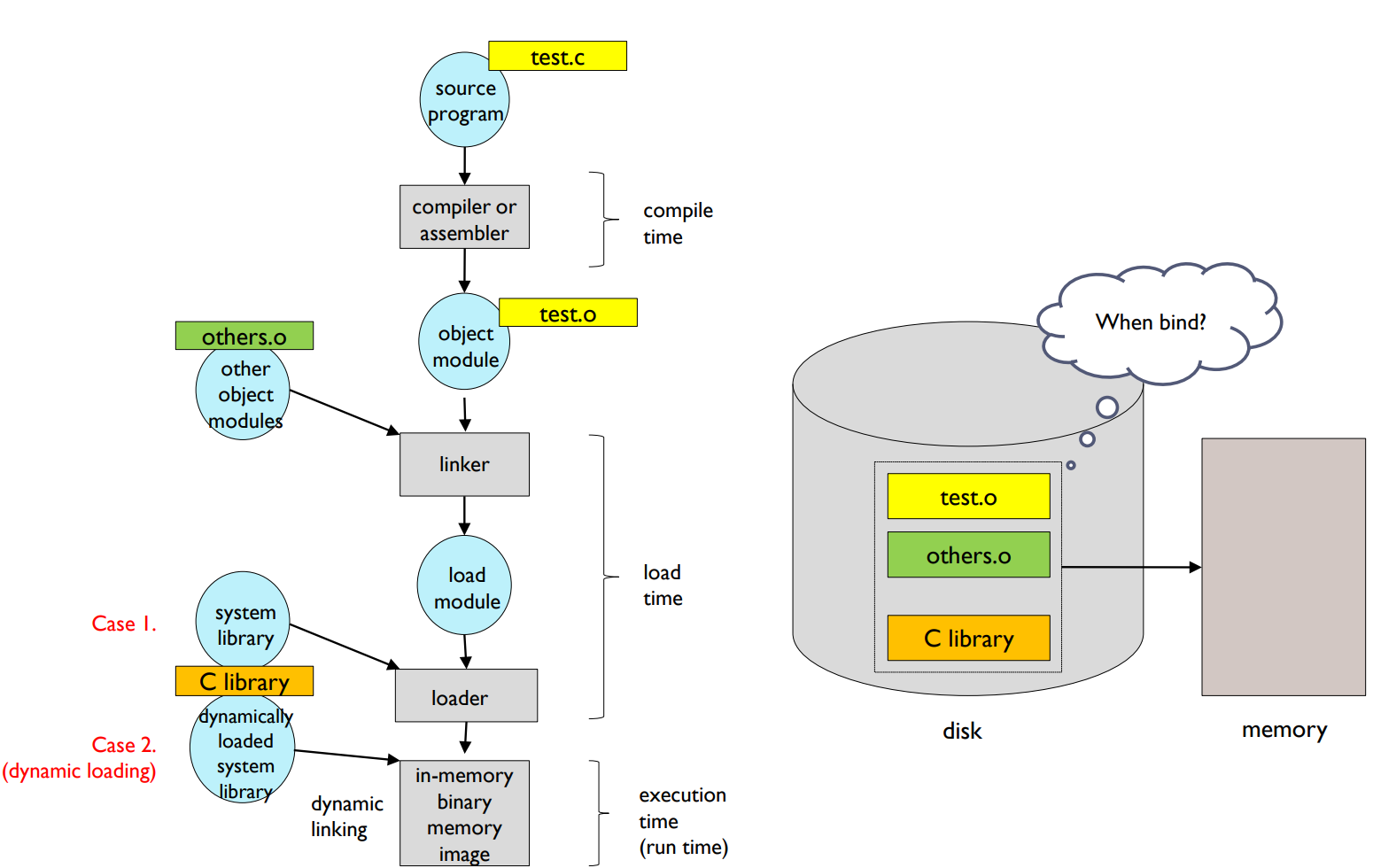
Multistep Processing of a User Program: 사용자 프로그램이 실행될 때 여러 단계를 거치게 됩니다. 이러한 단계들은 아래와 같습니다.
- Program: 초기에는 사용자 프로그램은 디스크에 저장되어 있습니다.
- Compiler: 컴파일러는 소스코드를 읽고 해당 언어의 문법과 구조를 분석하여 기계가 이해할 수 있는 저수준 언어인 오브젝트 코드로 변환합니다.
- Linker/Loader: 링커는 여러 개의 오브젝트 파일을 하나의 실행 파일로 만들며, 필요한 라이브러리와 연결(link)도 담당합니다. 로더는 실행 파일을 메모리에 적재하는 역할을 합니다.
- In-memory: 로더에 의해 메모리에 적재된 프로그램은 CPU에서 실행되며, 필요한 자원을 요청하고 결과를 출력하게 됩니다.
Address binding
Address binding
- The process of associating program instructions and data to physical memory addresses
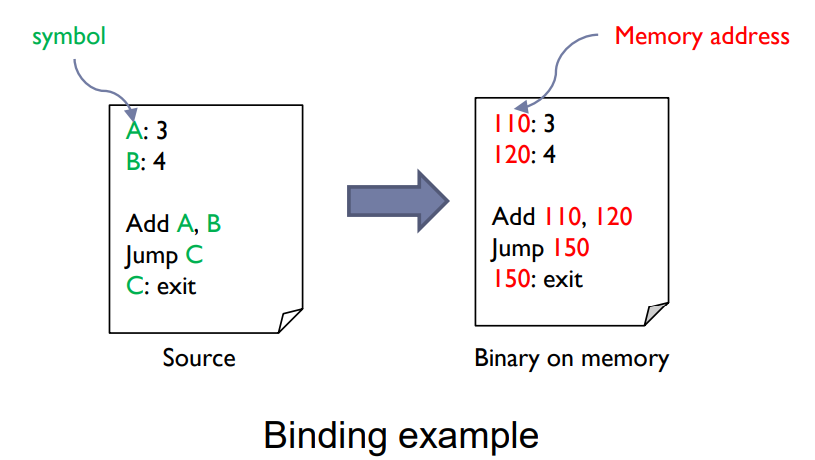
Address Binding: 주소 바인딩은 프로그램의 명령어와 데이터를 물리 메모리 주소에 연결하는 과정을 의미합니다. 이 과정은 프로그램의 명령어나 데이터가 메모리에서 정확히 어디에 위치할지를 결정합니다.
Address binding can happen at three different stages.
- Compile time binding
- Load time binding
- Execution time binding
Address Binding Stages: 주소 바인딩은 일반적으로 세 단계에서 발생합니다.
Compile time binding
- If memory location is known at compile time, absolute code with absolute addresses can be generated.
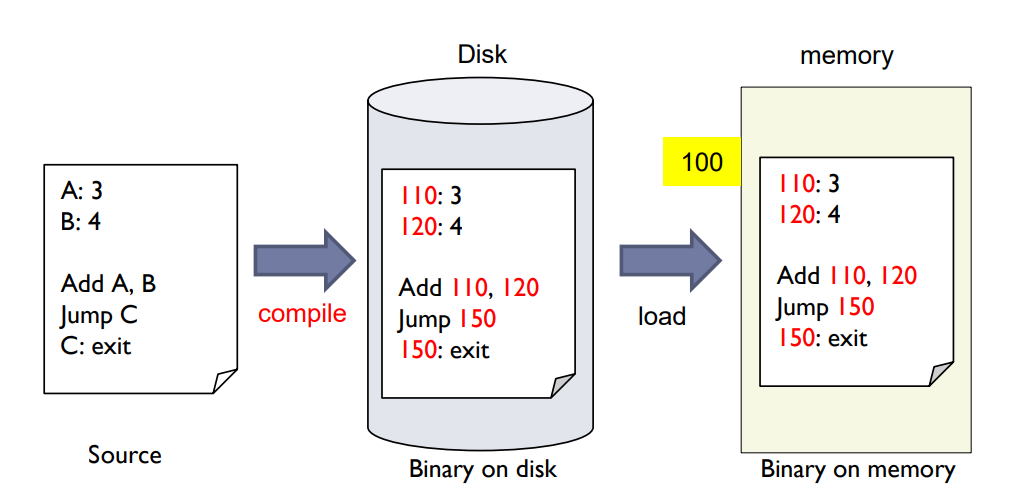
- Must recompile code if starting location changes.
Compile Time Binding: 이 단계에서 메모리 위치가 컴파일 시점에 이미 알려져 있다면, 절대 주소를 가진 절대 코드를 생성할 수 있습니다. 하지만 만약 시작 위치가 변경된다면 코드를 다시 컴파일해야 합니다.
Load time binding
- If memory location is not known at compile time, relocatable code with relative addresses can be generated.
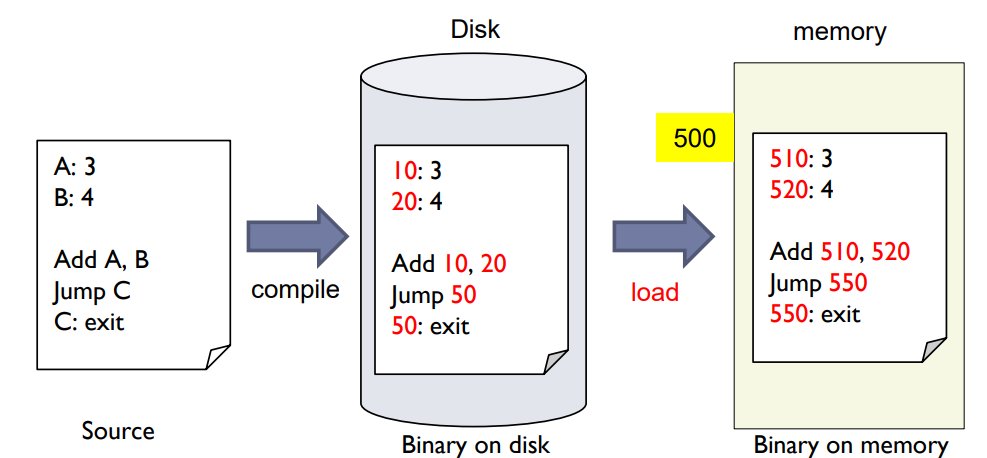
- Need only reload though starting location changes.
Load Time Binding: 이 단계에서는 메모리 위치가 컴파일 시점에 알려져 있지 않다면, 상대 주소를 가진 이동 가능한 코드를 생성합니다. 시작 위치가 변경되더라도 단순히 코드를 다시 로드하면 됩니다.
로드 타임 바인딩이란 프로그램의 코드나 데이터가 실제 물리 메모리 주소에 연결되는 것을 로드 시간까지 지연하는 방법입니다. 이 방법은 컴파일 시점에 프로그램이 메모리에 위치할 정확한 위치를 알 수 없을 때 유용합니다.
로드 타임 바인딩에서는 컴파일러가 상대적인 주소를 가진 재배치 가능한 코드(relocatable code)를 생성합니다. 이는 각 명령어나 데이터 항목이 프로그램의 시작부터 얼마나 떨어져 있는지를 나타냅니다. 프로그램이 메모리에 로드될 때, 로더(loader)는 이 재배치 가능한 코드의 모든 상대 주소를 실제 물리 메모리 주소로 변환합니다. 따라서, 프로그램이 메모리의 다른 위치로 이동하더라도 다시 로드하기만 하면 됩니다.
Execution time binding
- Binding is delayed until run time.
- Whenever CPU generates the address, binding is checked.
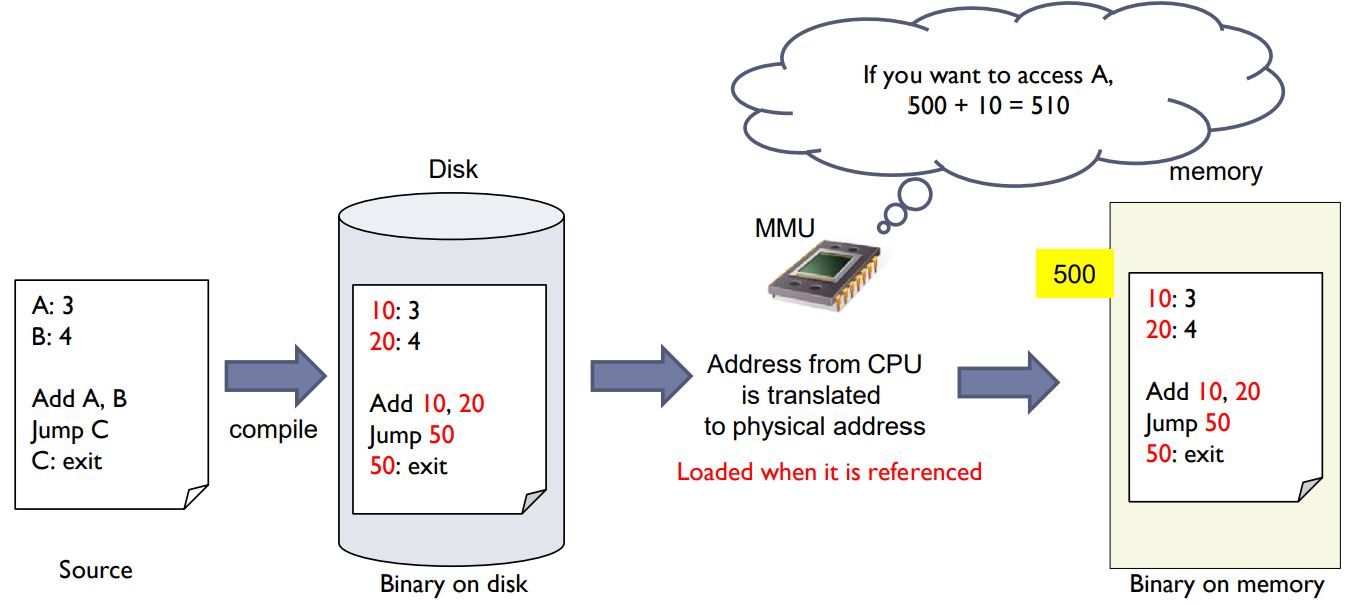
- Need hardware support such as MMU for address mapping.
- Most OSs use this method.
Execution Time Binding: 이 단계에서는 바인딩이 실행 시간까지 지연됩니다. CPU가 주소를 생성할 때마다 바인딩이 확인됩니다. 이 방식은 주소 매핑을 위해 하드웨어 지원, 예를 들어 메모리 관리 유닛(MMU)이 필요하며, 대부분의 운영체제에서 사용하는 방법입니다.
실행 타임 바인딩 (Execution Time Binding):
실행 타임 바인딩은 바인딩 작업을 실행 시간까지 미루는 방식입니다. 이 방법은 프로그램이 실행되는 동안에도 메모리의 위치를 변경할 수 있게 해주며, 이는 멀티태스킹과 스왑, 동적 메모리 할당 등의 작업을 가능하게 합니다.
CPU가 주소를 생성할 때마다 메모리 관리 유닛(Memory Management Unit, MMU)이 논리적 주소를 물리적 주소로 변환하므로, 실행 타임 바인딩은 하드웨어 지원이 필요합니다. MMU는 일반적으로 CPU에 내장되어 있으며, 주소 변환, 메모리 보호, 캐시 제어 등의 기능을 수행합니다.
실행 타임 바인딩은 페이징 및 세그멘테이션과 같은 메모리 관리 기법을 사용하는 운영 체제에서 흔히 사용됩니다. 이러한 기법들은 프로그램이 물리 메모리에 연속적으로 위치할 필요가 없으므로, 메모리를 훨씬 더 효율적으로 사용할 수 있습니다.
Memory Management Unit
- Logical address
- generated by the CPU.
- also referred to as virtual address.
- Physical address
- address seen by the memory unit.
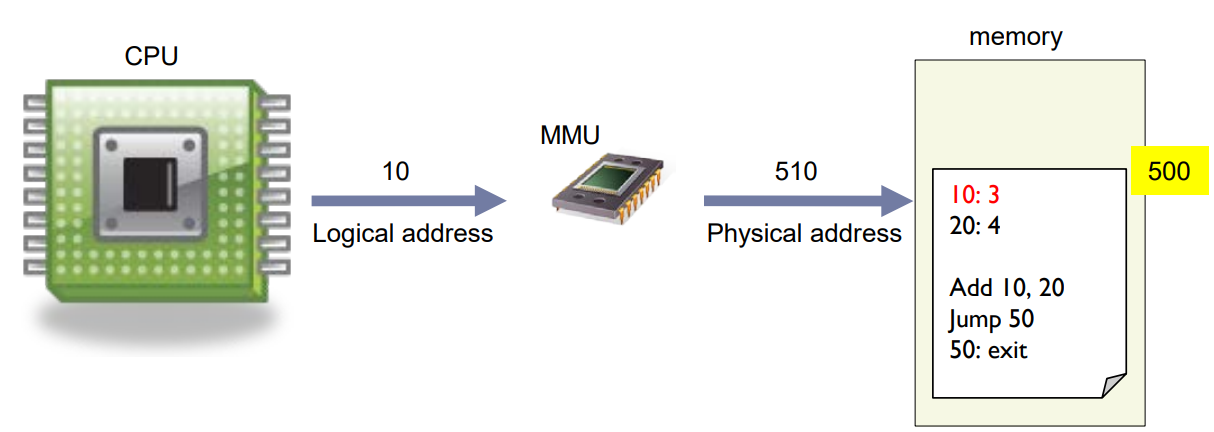
- MMU
- hardware that maps logical addresses to physical addresses.
- Simple MMU scheme
- The value in the relocation register is added to every address generated by CPU.
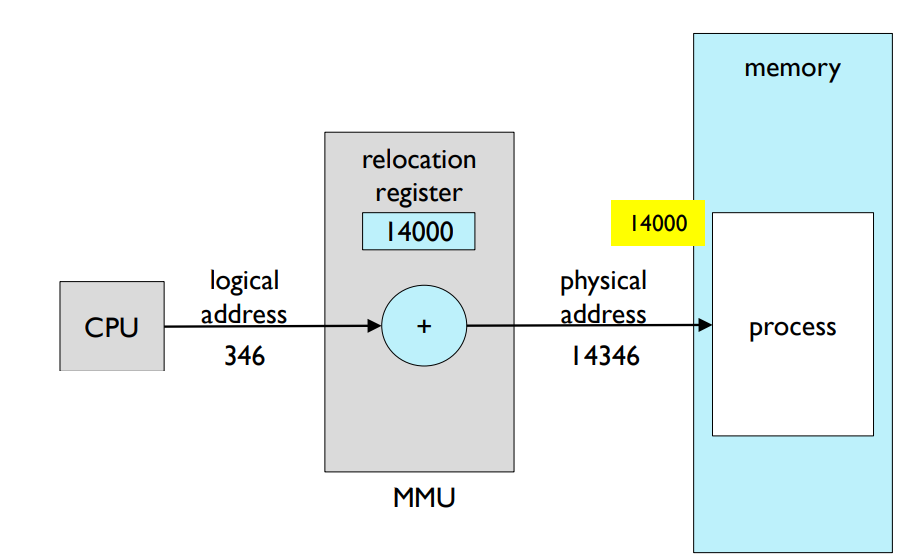
- The value in the relocation register is added to every address generated by CPU.
- Program & CPU
- deal with logical addresses, but never sees physical addresses.
Memory Management Unit (MMU): 이것은 논리 주소를 물리 주소로 매핑하는 하드웨어입니다. 논리 주소는 CPU에 의해 생성되며 가상 주소라고도 불립니다. 반면에 물리 주소는 메모리 유닛이 보는 주소입니다.
Simple MMU scheme: 이 스킴에서는 재배치 레지스터의 값이 CPU에 의해 생성된 모든 주소에 추가됩니다. 이로 인해 프로그램이 메모리 상에서 어디에 있더라도 올바르게 작동할 수 있습니다.
Program & CPU: 프로그램과 CPU는 논리 주소를 다루지만 물리 주소를 직접 볼 수는 없습니다. 이것은 MMU가 논리 주소를 물리 주소로 변환하기 때문입니다. 이 과정을 통해 운영 체제는 프로그램을 보호하고, 주소 공간을 효율적으로 관리할 수 있습니다.
Memory Management Unit (MMU)는 CPU가 생성한 논리적 주소를 실제 메모리에 있는 물리적 주소로 매핑하는 컴퓨터의 하드웨어 부분입니다. 이 매핑 과정은 메모리 관리 및 보안을 강화하는 데 중요한 역할을 합니다.
MMU는 논리적 주소 공간과 물리적 주소 공간 간의 추상화를 제공합니다. 논리적 주소는 CPU가 생성하며, 프로그램에 의해 사용됩니다. 이것을 가상 주소라고도 부릅니다. 이와 달리 물리적 주소는 실제 메모리 유닛이 인식하고 접근할 수 있는 주소입니다.
Simple MMU scheme에서는 논리적 주소에 재배치 레지스터의 값을 더합니다. 이 재배치 레지스터는 프로그램이 메모리에서 어디에 위치하든 간에 올바르게 작동할 수 있도록 하는 데 필요한 오프셋을 제공합니다.
즉, MMU는 논리적 주소를 물리적 주소로 변환하여 프로그램이 실제 메모리의 특정 부분에 접근할 수 있도록 합니다. 이렇게 함으로써, 프로그램과 CPU는 논리적 주소만을 처리하며, 실제 메모리 위치에 대해 걱정할 필요가 없습니다. 이는 운영 체제가 프로그램을 보호하고, 주소 공간을 효율적으로 관리할 수 있게 합니다.
또한, MMU는 메모리 보호, 가상 메모리, 디스크 페이징 메커니즘 등 다양한 메모리 관리 기법을 지원하는 데도 사용됩니다. 이러한 기능들은 프로세스 간의 메모리 분리, 메모리 할당 및 해제, 스왑 등 복잡한 메모리 관리 작업을 가능하게 합니다.
Dynamic Loading
- Routine is not loaded until it is called.
- Better memory-space utilization
- Unused routine is never loaded.
- Useful when large amounts of error handling code are needed.
- Error does not occur frequently.
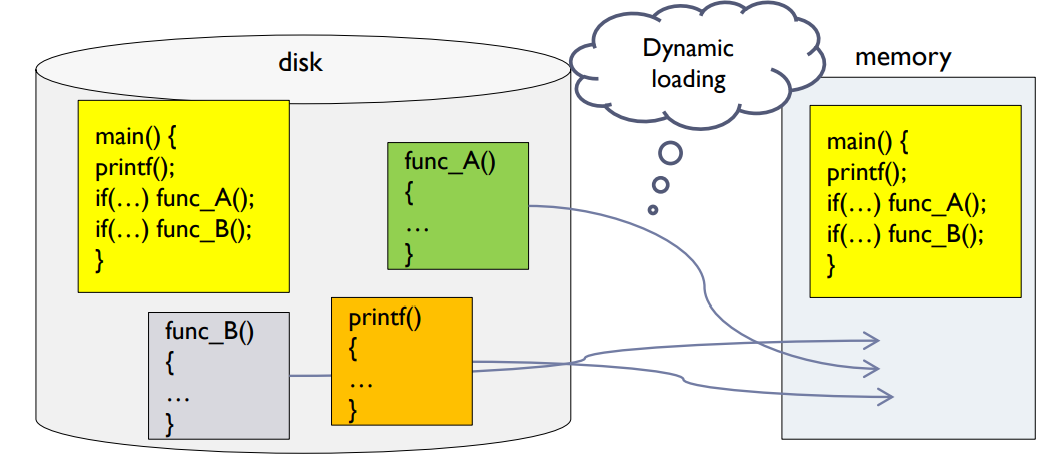
- Error does not occur frequently.
- Load할 때마다 매번 동일한 address가 비어 있을까? No.
- → 어디든지 load될 수 있기 때문에 dynamic linking이 필요함.
동적 로딩(Dynamic Loading): 이 방법은 프로그램에서 특정 루틴이 호출될 때까지 그 루틴을 메모리에 로드하지 않습니다. 이를 통해 메모리 공간을 더 효율적으로 사용할 수 있으며, 사용하지 않는 루틴은 절대 로드되지 않습니다. 이는 대량의 오류 처리 코드가 필요한 경우에 특히 유용하며, 오류가 자주 발생하지 않는다면 그 부분을 메모리에 올릴 필요가 없게 됩니다. 동적 로딩 시 매번 동일한 주소가 비어있지 않을 수 있기 때문에, 루틴이 어디에든지 로드될 수 있도록 동적 링킹이 필요합니다.
Dynamic Linking
- Dynamic linking
- Linking is postponed until execution time.
- Shared library
- For all processes that require library, one copy in memory is sufficient.
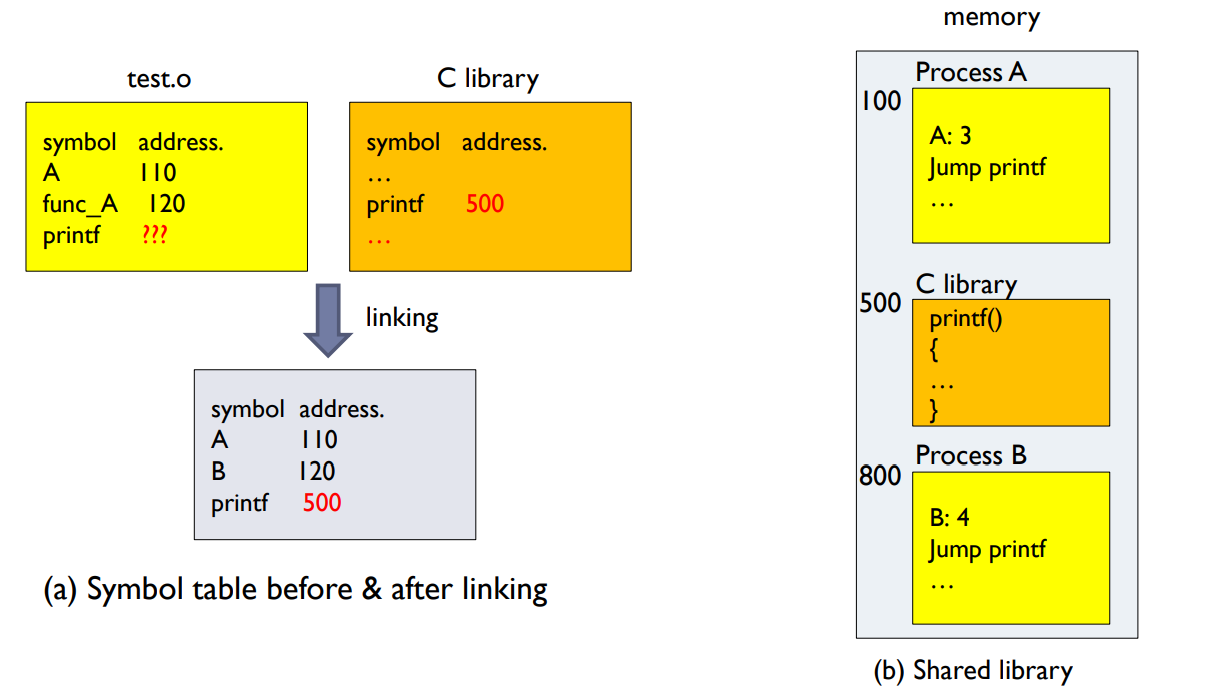
동적 링킹(Dynamic Linking): 이 방법은 링킹을 실행 시간까지 연기합니다. 즉, 프로그램이 실행되는 동안에만 필요한 라이브러리나 모듈을 로드합니다. 동적 링킹은 공유 라이브러리를 효율적으로 사용하는 데 유용합니다. 모든 프로세스가 같은 라이브러리를 필요로 할 경우, 메모리에는 해당 라이브러리의 한 개의 복사본만 있으면 충분합니다.
동적 링킹Dynamic Linking은 프로그램의 실행 시간 동안 라이브러리나 모듈을 로드하고 연결하는 방법입니다. 이 방식은 프로그램이 실행되는 동안에만 필요한 코드, 예를 들어 공유 라이브러리나 모듈,를 메모리에 로드하는 데 사용됩니다.
동적 링킹의 주요 장점 중 하나는 공유 라이브러리의 효율적인 사용입니다. 공유 라이브러리는 여러 프로그램이 공동으로 사용할 수 있는 코드와 데이터를 포함하며, 이러한 라이브러리는 각 프로그램이 개별적으로 동일한 라이브러리를 메모리에 로드하는 대신, 메모리에 한 번만 로드되고 필요에 따라 여러 프로그램에 연결됩니다. 이렇게 함으로써 메모리 사용량을 줄일 수 있고, 공유 라이브러리를 수정하거나 업데이트할 경우 모든 프로그램이 이점을 얻을 수 있습니다.
동적 링킹의 또 다른 이점은 실행 파일의 크기를 줄일 수 있다는 것입니다. 왜냐하면 실행 파일이 실제로 필요한 코드와 데이터만 포함하고 있기 때문입니다. 그 외에 필요한 함수나 데이터는 실행 시간에 필요할 때 로드됩니다.
하지만 동적 링킹에는 단점도 있습니다. 예를 들어, 프로그램 실행 시에 필요한 라이브러리가 없거나 호환되지 않는 버전일 경우, 프로그램이 제대로 실행되지 않을 수 있습니다. 또한, 각 함수 호출마다 추가적인 오버헤드가 발생할 수 있습니다. 왜냐하면 해당 함수의 실제 위치를 찾기 위해 링킹 과정을 거쳐야 하기 때문입니다.
그럼에도 불구하고, 많은 운영 체제와 프로그램에서는 메모리 사용량을 최소화하고 코드를 공유하기 위해 동적 링킹을 사용합니다. 이는 특히 메모리 리소스가 제한적인 시스템에서 중요합니다.
Swapping
- Swapping
- A process can be swapped temporarily out of memory to a backing store.
- and then brought back into memory later.
- Backing store
- fast and large enough to accommodate all images.
- E.g. disks
- Schematic View of Swapping
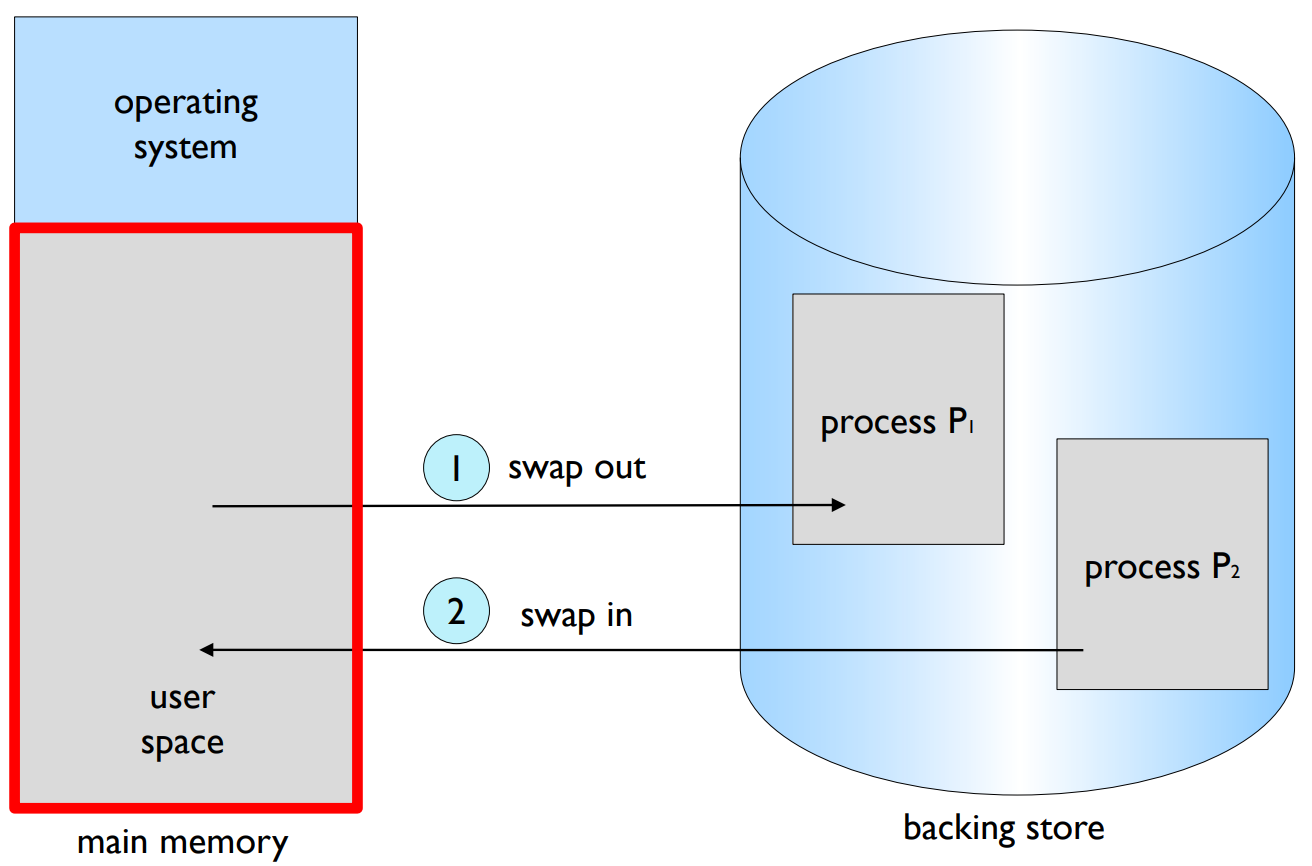
스와핑(Swapping): 스와핑은 프로세스를 잠시 메모리에서 백업 스토어로 내보낼 수 있게 하는 기술입니다. 나중에 이 프로세스를 메모리로 다시 가져올 수 있습니다. 백업 스토어는 모든 이미지를 수용할 수 있을 만큼 충분히 빠르고 크며, 대체로 디스크가 이에 해당합니다. 스와핑은 메모리를 효과적으로 관리하고, 여러 프로세스를 동시에 실행할 수 있게 해주는 중요한 기술입니다.
Contiguous Allocation
- Main memory is usually divided into two partitions.
- One for operating system.
- The other for user processes.
- Memory mapping and protection
- Relocation registers is used to protect user processes.
- Limit register contains range of logical addresses.
- Each logical address must be less than the limit register.
- MMU maps logical address dynamically
- by adding the value in the relocation register.
- Hardware supports for contiguous memory allocation
- Memory allocation
- Hole (a large block of available memory)
- holes of various size are scattered throughout memory.
- When a process is created,
- it is allocated memory from a hole large enough to accommodate it.
- Operating system maintains information about
- allocated partitions
- free partitions (hole)
- Hole (a large block of available memory)
- Dynamic Storage-Allocation Problem
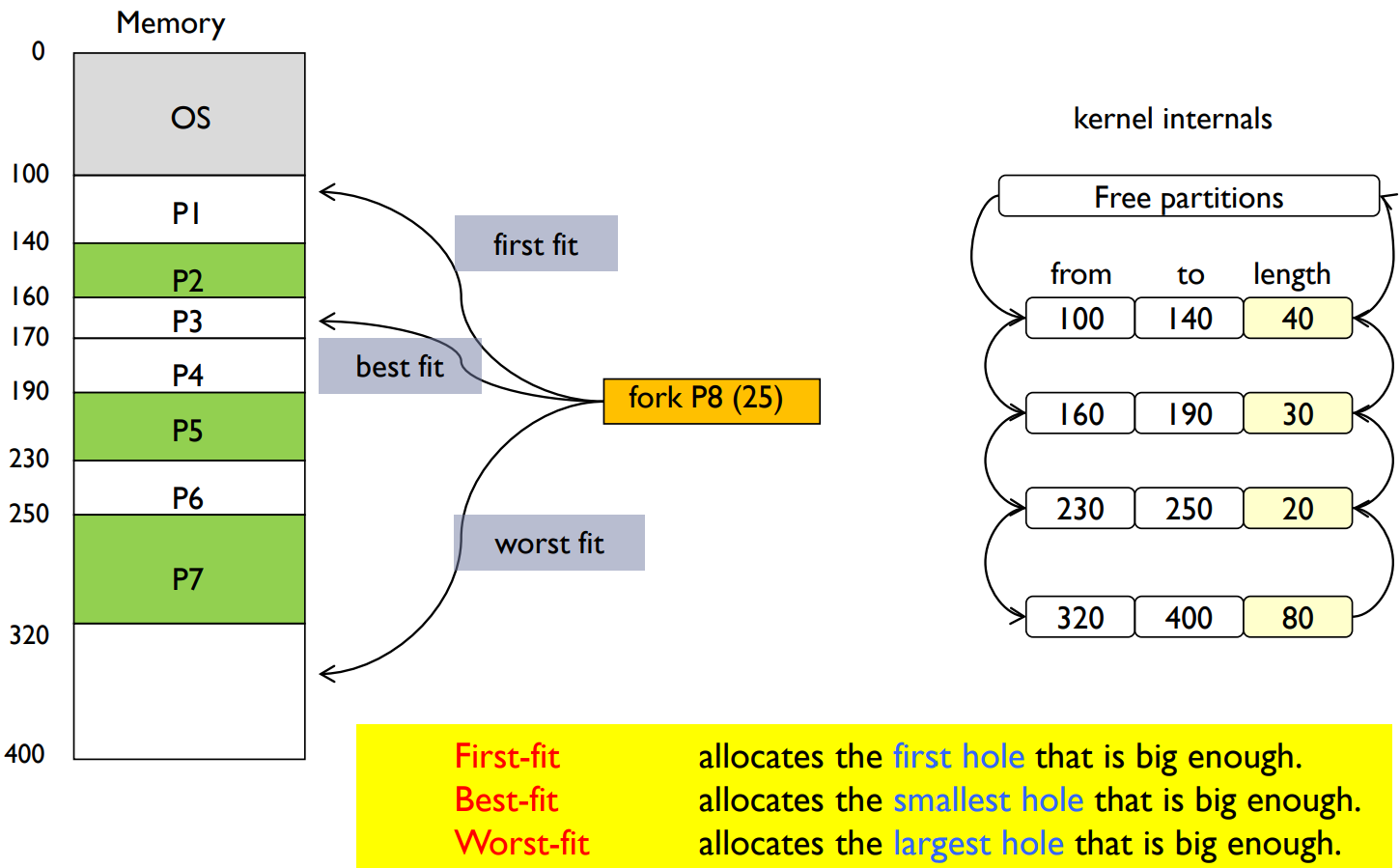
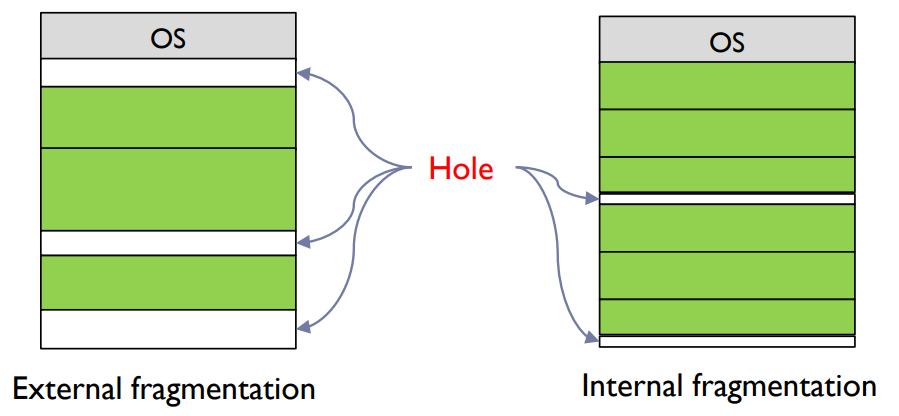
- External Fragmentation
- Total free memory space exists to satisfy a request, but it is not contiguous.
- Can be reduced by compaction.
- places all free memory together in one large block.
- Internal Fragmentation
- The allocated memory may be slightly larger than requested memory.
- Size difference is internal to a partition, but is not used.
-
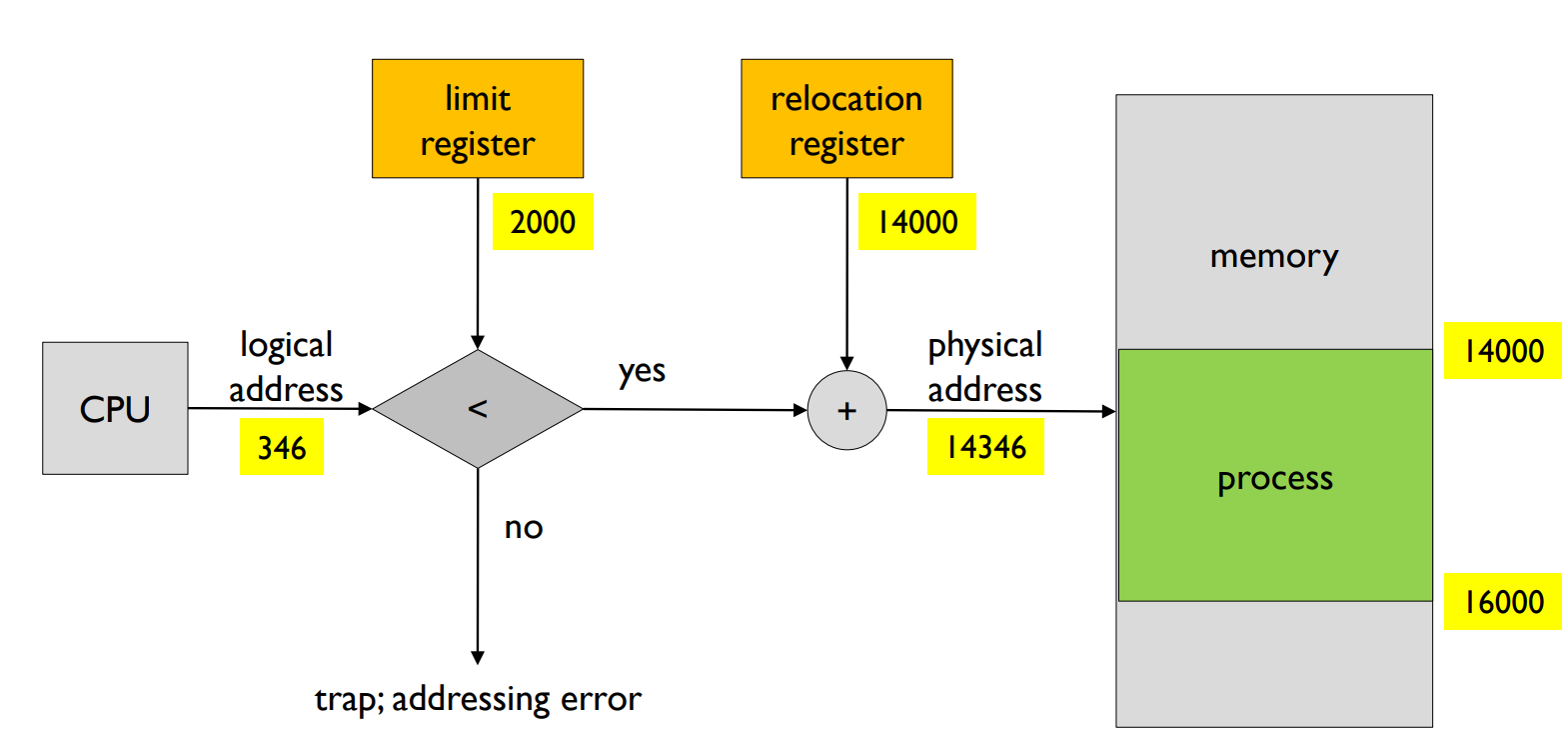
연속 할당(Contiguous Allocation): 이 메모리 관리 전략에서는 주 메모리가 보통 두 파티션으로 나뉩니다: 하나는 운영 체제를 위한 것이고, 다른 하나는 사용자 프로세스를 위한 것입니다. 이 전략은 'relocation register'를 사용하여 사용자 프로세스를 보호하며, 'limit register'는 논리적 주소의 범위를 포함합니다. 각 논리적 주소는 반드시 limit register의 값보다 작아야 합니다. MMU는 논리적 주소를 동적으로 매핑합니다. relocation register의 값을 더함으로써 이 작업을 수행합니다.
-
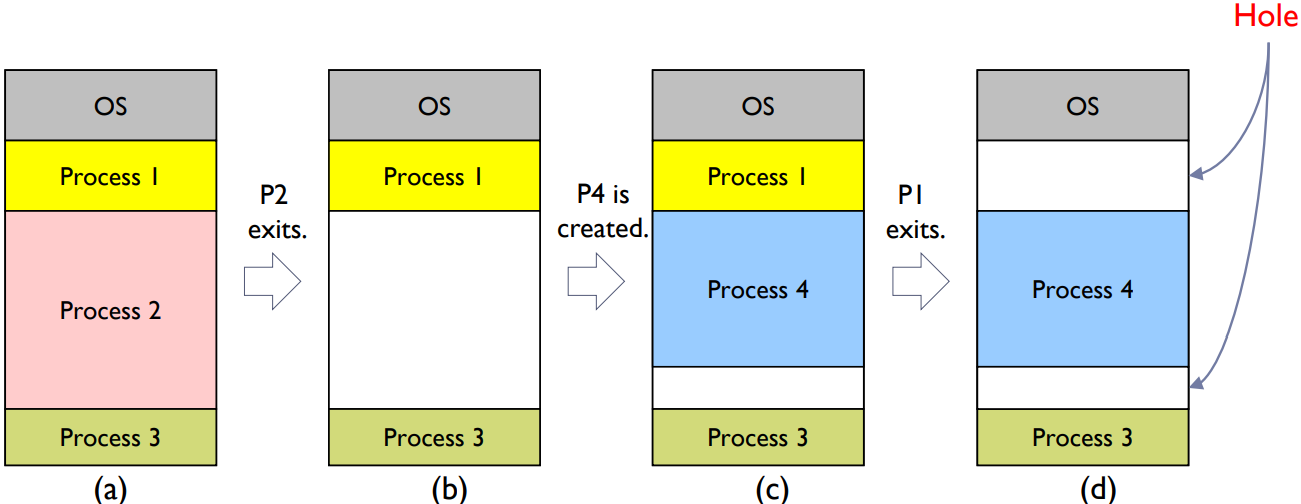
메모리 할당: 메모리는 여러 개의 '구멍'이라고 불리는 가용 메모리 블록으로 구성됩니다. 이 구멍들은 메모리 전체에 흩어져 있습니다. 프로세스가 생성되면, 그 프로세스를 수용할 수 있는 충분히 큰 구멍에서 메모리가 할당됩니다. 운영 체제는 할당된 파티션과 미할당된 파티션(구멍)에 대한 정보를 유지합니다.
-
동적 저장소 할당 문제: 이 문제는 어떤 구멍을 사용하여 메모리 요청을 만족시킬 것인지 결정하는 것입니다. 이에 대한 세 가지 전략이 있습니다: 최초 적합, 최적 적합, 최악 적합입니다.
-
외부 단편화(External Fragmentation): 이는 요청을 충족시키기에 충분한 총 가용 메모리 공간이 있지만, 그 메모리가 연속적이지 않는 경우 발생합니다. 이 문제는 '압축(compaction)'을 통해 해결할 수 있습니다. 압축은 모든 가용 메모리를 하나의 큰 블록으로 모읍니다.
-
내부 단편화(Internal Fragmentation): 이는 할당된 메모리가 요청된 메모리보다 약간 큰 경우 발생합니다. 이 차이는 파티션 내부에 존재하지만 사용되지 않습니다.
Paging
- Divide memory and image into fixed size, respectively.
- page frame and page
- Size is power of 2, between 512B and 8KB.
- Entire program image resides on disk.
- When the program starts, just load the first page only.
- The rest of pages are loaded in memory on-demand.
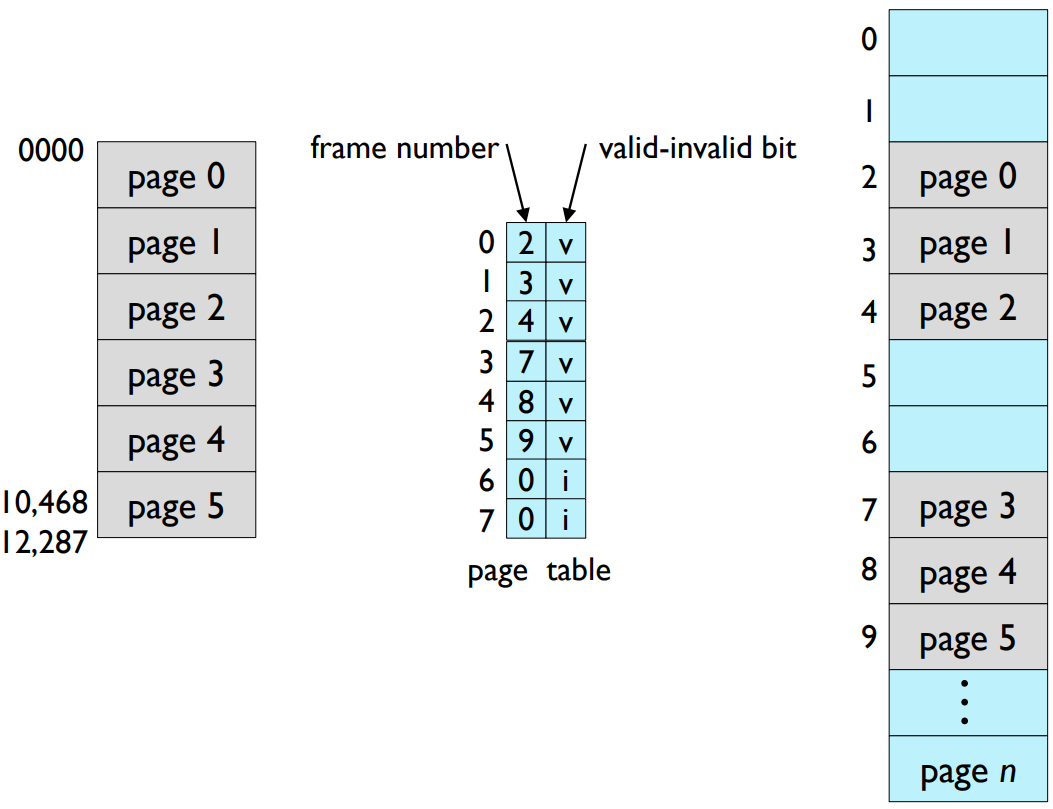
- A particular page X of the program can be either
- already loaded in memory page frame Y, or
- never been loaded before, it is in disk.
- Pages can be placed anywhere in memory.
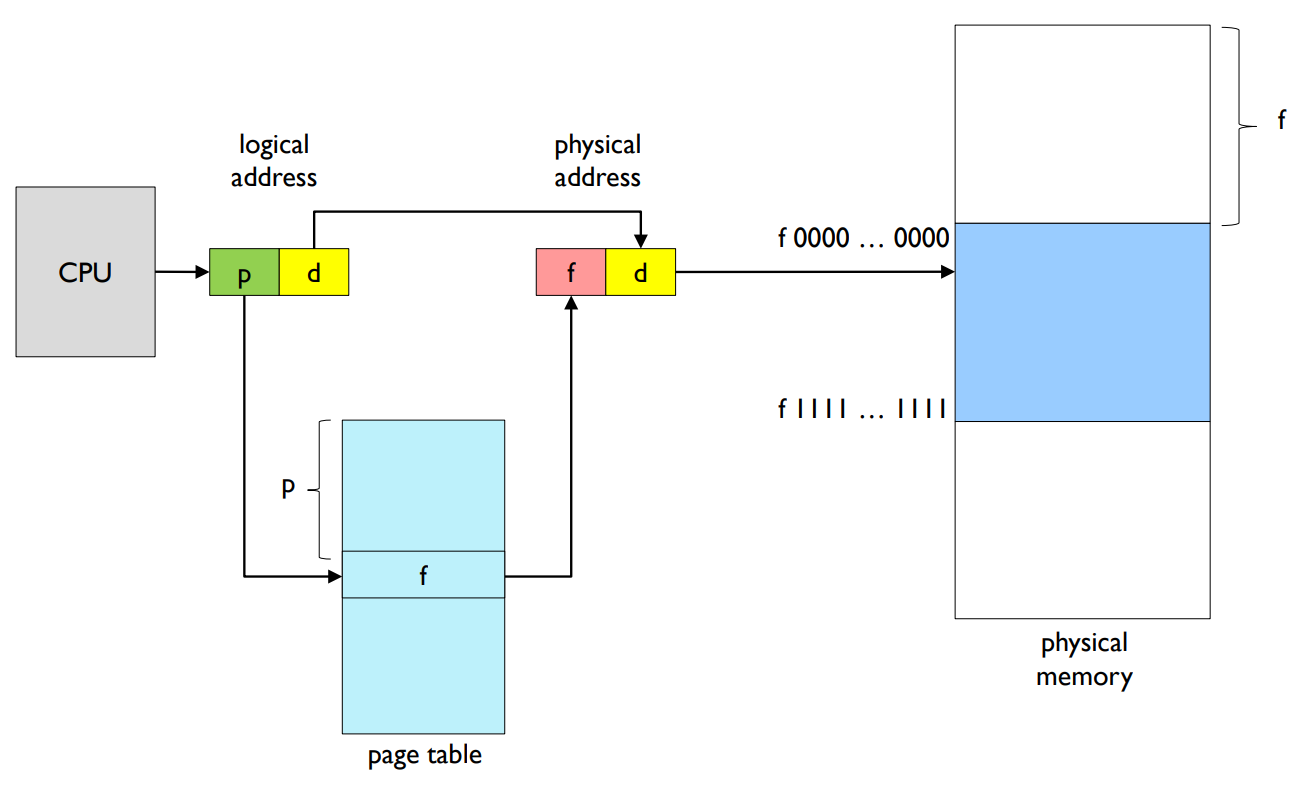
- Whenever CPU presents an address, MMU looks up page table.
- For translating logical address to physical address.
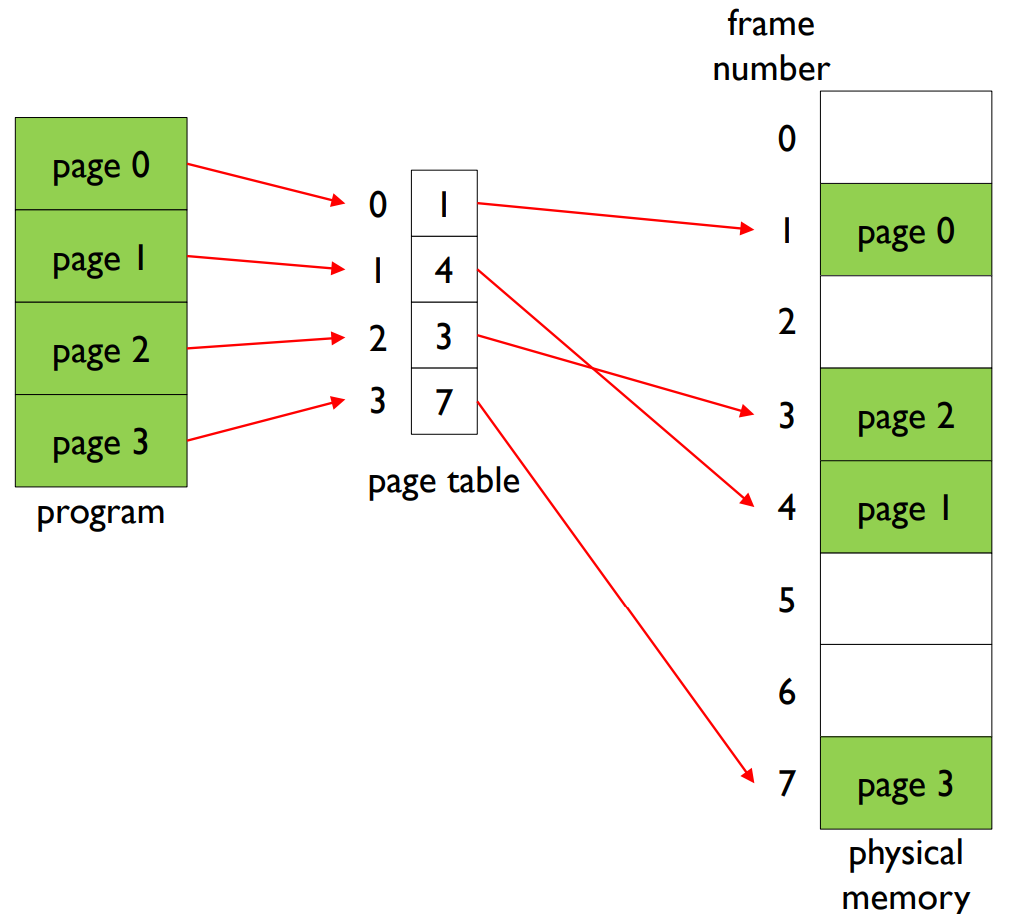
- Example of page table
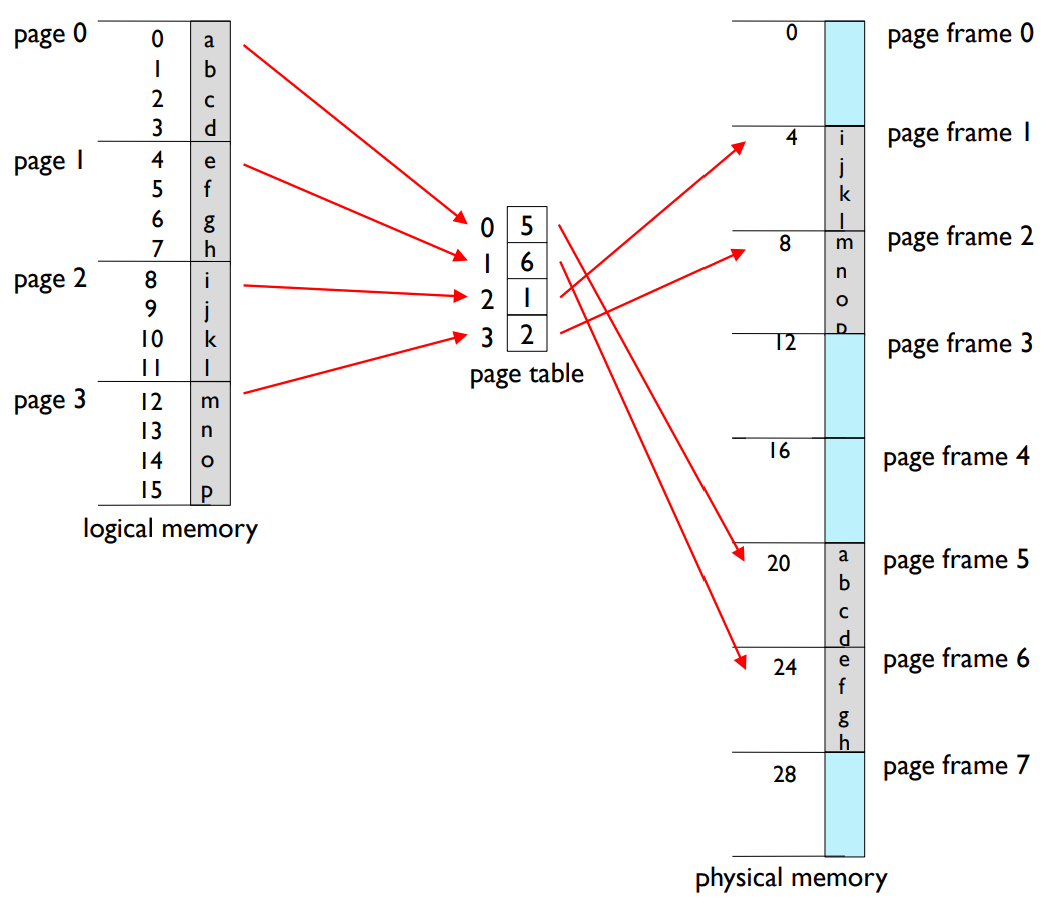
- Another paging example
- Address Translation Scheme
- The logical address generated by CPU is divided into two parts.
- E.g. Given address length 32 and page size 4KB.
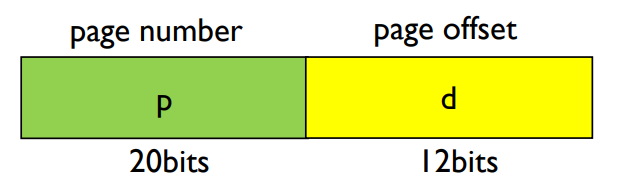
- Page number (p)
- Is used as an index of page table.
- Contains base address of each page frame in physical memory.
- Page offset (d)
- Is combined with base address to define the physical memory address.
- Address Translation Scheme
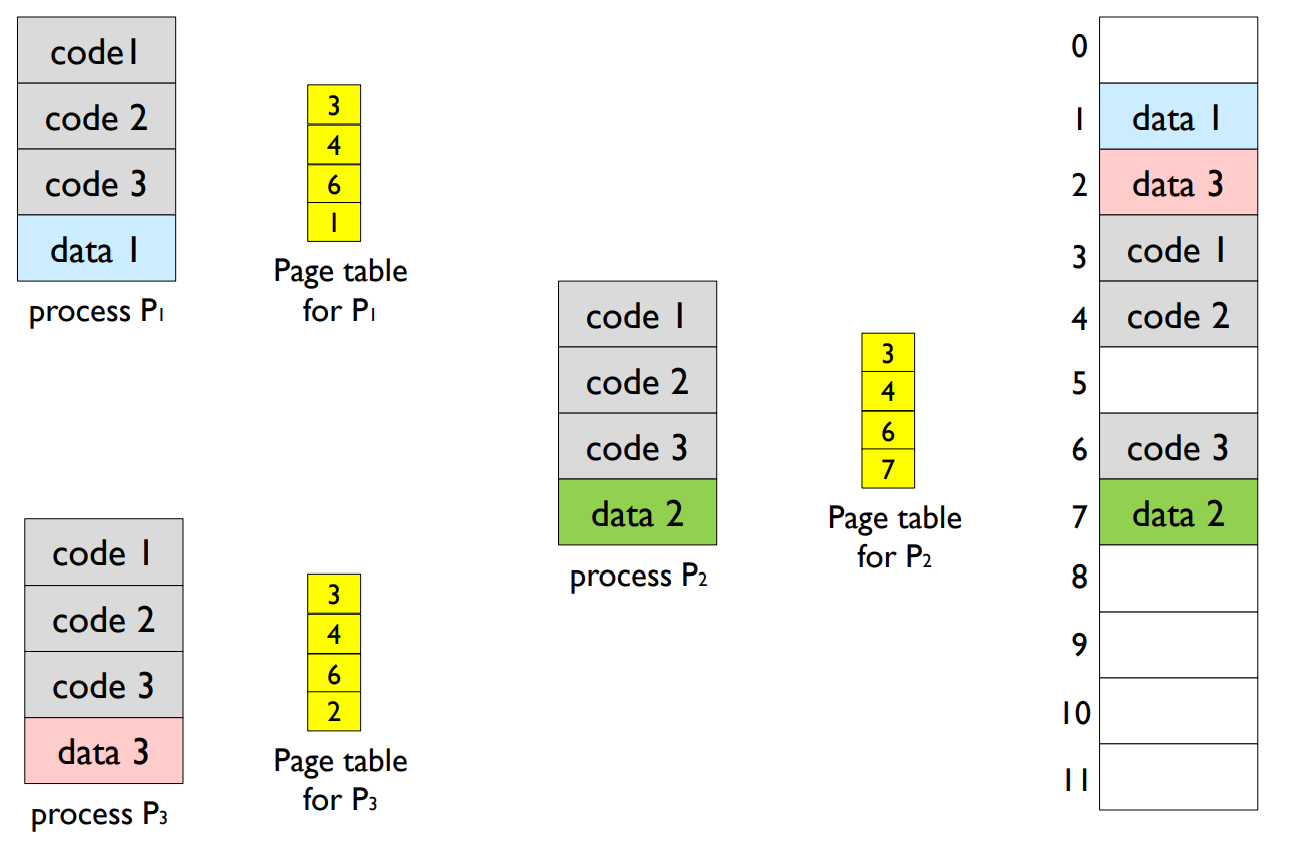
- Shared pages
- Memory protection is implemented
- by associating protection bits with each frame.
- Read-only, read-write, execute-only bit
- Valid-invalid bit
- by associating protection bits with each frame.
- Advantage
- Provides memory space larger than physical memory.
- If 32 bits processor, 4GB logical address space is possible.
- Supports demand paging
- Does not require memory placement policy.
- Provides page sharing
- Protects memory space each other
- Provides memory space larger than physical memory.
- Disadvantage
- Temporal overhead
- → TLB (Translation Look-aside Buffer)
- Spatial overhead
- → Multi-level page table, hashed page table, inverted page table
- Temporal overhead
1. 페이징(Paging): : 페이징은 물리 메모리를 고정된 크기의 프레임으로 나누고, 프로그램을 같은 크기의 페이지로 분할하는 메모리 관리 전략입니다. 이 방식은 프로그램이 메모리의 연속적인 영역에 위치하지 않아도 되게 하므로, 메모리를 더 유연하게 관리할 수 있습니다. 프로그램의 실행 도중 필요한 페이지만 메모리에 로드되므로, 물리 메모리보다 큰 프로그램을 실행할 수 있습니다.
2. 페이지 테이블(Page Table): 페이지 테이블은 논리적 주소(페이지 번호와 오프셋)를 물리적 주소(프레임 번호와 오프셋)로 변환하는 데 사용되는 자료구조입니다. 각 테이블 항목은 논리 페이지와 그에 해당하는 물리 프레임을 연결합니다. CPU가 주소를 생성하면, 페이지 번호는 페이지 테이블에서 해당 프레임을 찾는 데 사용되고, 페이지 오프셋은 해당 프레임 내에서 정확한 바이트를 찾는 데 사용됩니다.
3. 주소 변환 스키마(Address Translation Scheme): 이는 논리적 주소를 물리적 주소로 변환하는 프로세스입니다. CPU가 논리적 주소를 생성하면, MMU는 페이지 테이블을 사용하여 이를 물리적 주소로 변환합니다. 이 논리적 주소는 페이지 번호와 페이지 오프셋 두 부분으로 구성되며, 이 두 부분이 결합하여 물리적 메모리의 특정 위치를 지정합니다.
4. 공유 페이지(Shared Pages): 페이징은 프로세스 간에 메모리를 공유하는 것을 가능하게 합니다. 특히, 읽기 전용 코드 페이지(예: 시스템 라이브러리)는 여러 프로세스가 공유할 수 있습니다. 이는 메모리 사용을 최적화하는 데 도움이 됩니다.
5. 메모리 보호(Memory Protection): 각 페이지 테이블 엔트리는 보호 비트를 포함하고 있을 수 있으며, 이 비트는 해당 페이지에 대한 액세스를 제어합니다. 예를 들어, 읽기 전용 페이지, 읽기/쓰기 페이지, 실행 페이지 등으로 설정할 수 있습니다. 유효/무효 비트는 페이지가 현재 메모리에 로드되어 있는지 여부를 나타내는 데 사용될 수 있습니다.
6. 페이징의 장점:
- 조각화 해결: 페이징은 외부 조각화와 컴팩션 문제를 해결합니다. 이는 페이지가 모두 같은 크기이기 때문에 가능합니다.
- 메모리의 동적 할당: 페이징은 동적으로 페이지를 메모리에 로드하고 제거하므로, 물리 메모리 크기보다 큰 프로그램을 실행할 수 있습니다. 이것은 가상 메모리의 기본 개념입니다.
- 메모리 보호와 공유: 각 페이지는 독립적으로 보호 비트를 가질 수 있어서, 프로세스는 서로의 메모리 공간을 침범하지 못하게 됩니다. 또한 읽기 전용 페이지는 여러 프로세스가 공유할 수 있습니다.
7. 페이징의 단점:
- 페이지 테이블의 오버헤드: 큰 메모리를 사용하는 큰 프로그램의 경우, 페이지 테이블의 크기가 크게 될 수 있습니다. 이것은 메모리와 CPU의 오버헤드를 발생시킵니다.
- 내부 조각화: 페이지는 모두 같은 크기이므로, 프로세스가 사용하지 않는 메모리가 페이지 내에 남을 수 있습니다. 이를 내부 조각화라고 합니다.
- 메모리 접근 시간: 논리적 주소를 물리적 주소로 변환하는 과정은 메모리 접근 시간을 증가시킵니다. 이를 해결하기 위해 일반적으로 빠른 캐시 메모리인 TLB(Translation Lookaside Buffer)가 사용됩니다.
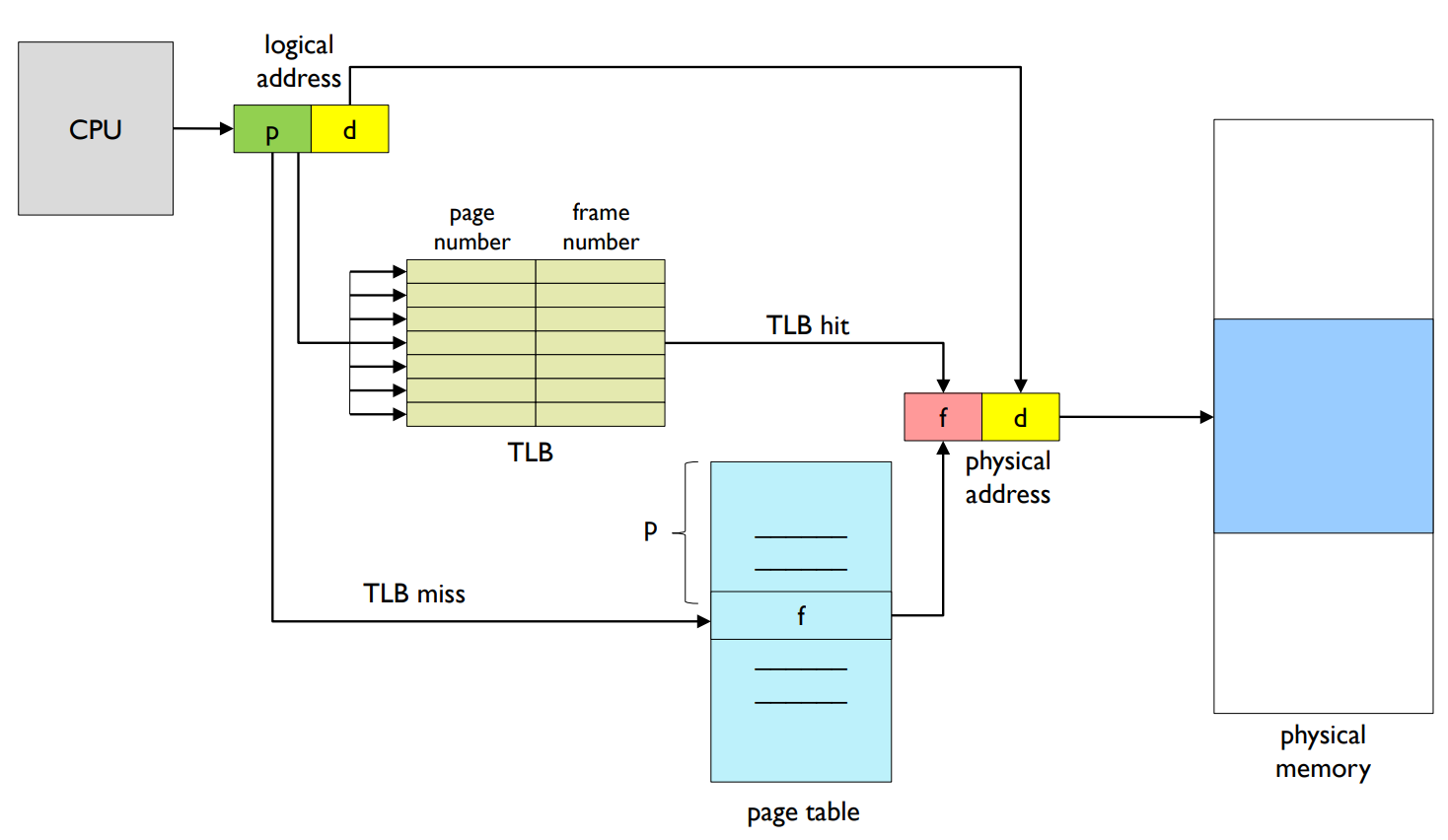
Implementation of Page Table
- Page table is kept in main memory.
- Page-table base register (PTBR) points to the page table.
- Every data/instruction access requires two memory accesses.
- One for the page table and one for the data/instruction.
- → The two memory access problem can be solved
- by the use of Translation Look-aside Buffer (TLB).
- Paging with TLB (Translation Lookaside Buffer)
- Effective Access Time
- TLB lookup time: ε
- Memory access time: 1
- Hit ratio: α
- Percentage that is found in TLB.
- Effective Access Time = (1 + ε) α + (2 + ε)(1 – α) = 2 + ε – α
- Additional memory space is required to store page table.
- Program has a large address space.
- If we use 32 bit addresses,
- → can address a program with 4GB size.
- → 1 million page table entries (if page size is 4KB)
- → 4 MB page table (if entry size is 4B)
- Page table is a per-process data structure.
- 4MB * N (the number of processes) is required to store page tables.
페이지 테이블 구현: 페이지 테이블은 주 메모리에 보관되며, 페이지 테이블 기본 레지스터 (PTBR)가 페이지 테이블을 가리킵니다. 모든 데이터/명령 접근은 두 번의 메모리 접근을 필요로 합니다. 하나는 페이지 테이블을 위한 것이고, 다른 하나는 데이터/명령을 위한 것입니다. 이 두 번의 메모리 접근 문제는 Translation Look-aside Buffer (TLB)의 사용으로 해결할 수 있습니다.
페이지 테이블의 추가 메모리 공간 필요성: 페이지 테이블을 저장하기 위한 추가적인 메모리 공간이 필요합니다. 프로그램이 큰 주소 공간을 가질 경우, 예를 들어 32비트 주소를 사용하면 4GB 크기의 프로그램을 주소 지정할 수 있습니다. 이 경우, 페이지 크기가 4KB라면 1백만개의 페이지 테이블 항목이 필요하며, 항목 크기가 4B라면 4MB의 페이지 테이블이 필요합니다. 페이지 테이블은 프로세스당 데이터 구조이므로, 페이지 테이블을 저장하기 위해선 4MB * N(프로세스의 수)의 공간이 필요합니다.
TLB와 효과적인 접근 시간: TLB를 사용하면, TLB 조회 시간(ε), 메모리 접근 시간(1), 히트 비율(α) 등을 고려하여 효과적인 접근 시간을 계산할 수 있습니다. 효과적인 접근 시간은 (1 + ε)α + (2 + ε)(1 - α) = 2 + ε - α로 계산됩니다. 여기서 히트 비율은 TLB에서 찾을 수 있는 비율을 의미합니다.
Two-level Page Table Scheme
- Two-level page table scheme
- The page table itself is also paged.
- Stores an entire page table in disks.
- Loads page table’s page on-demand.
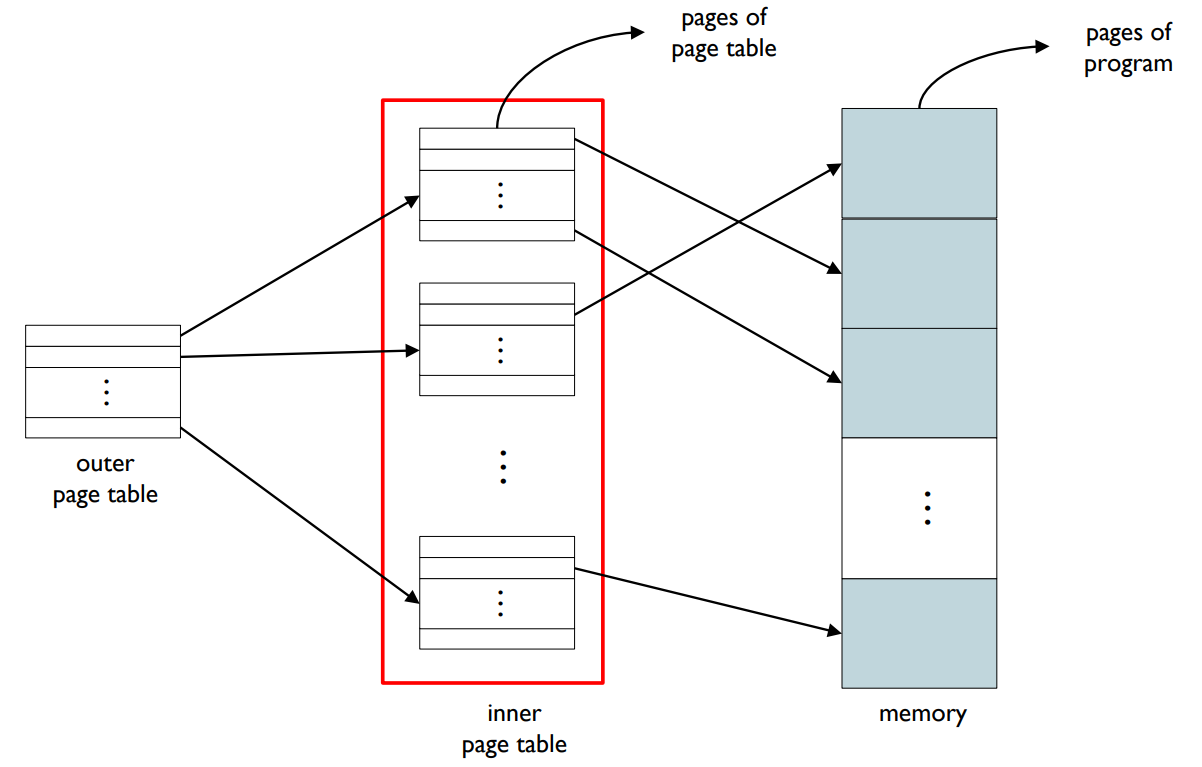
- The page table itself is also paged.
- Address translation with two-level page table scheme
- A logical address (on 32-bit with 4K page size) is divided.
- 20-bits page number.
- 12-bits page offset.
- Since page table itself is paged, page number is further divided.
- 10-bits for index in outer page table.
- 10-bits for index in inner page table.
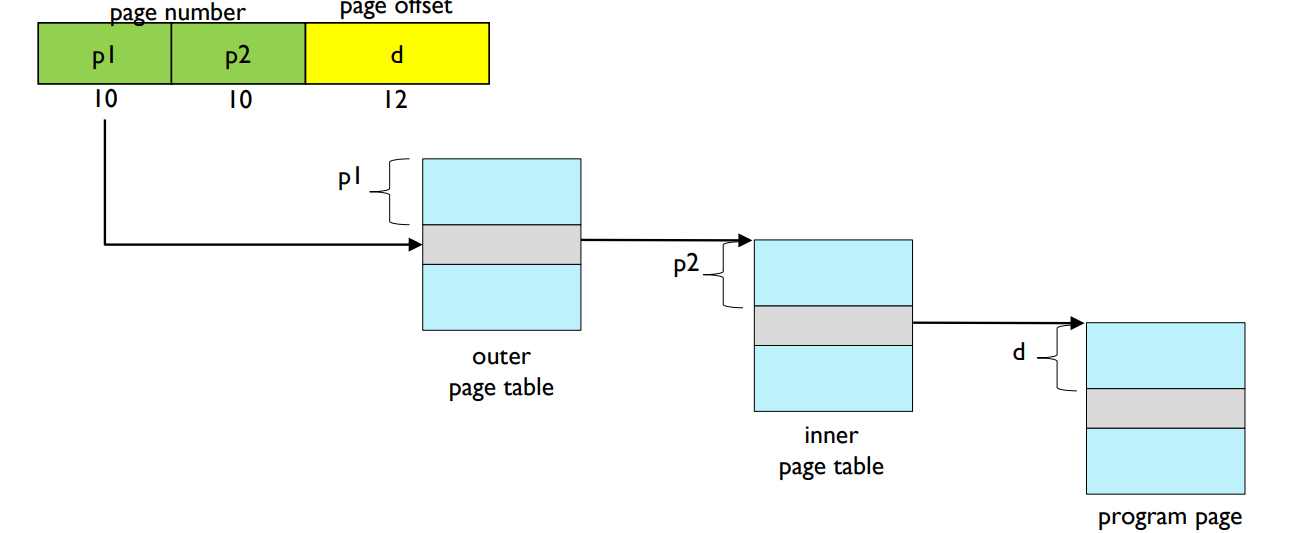
- A logical address (on 32-bit with 4K page size) is divided.
이중 페이지 테이블 체계(Two-level Page Table Scheme): 이중 페이지 테이블 체계는 페이지 테이블 자체도 페이지화된 구조입니다. 이는 전체 페이지 테이블을 디스크에 저장하고, 페이지 테이블의 페이지를 필요에 따라 로드합니다.
Three-level Page Table Scheme
- Three level paging for 64 bit processor
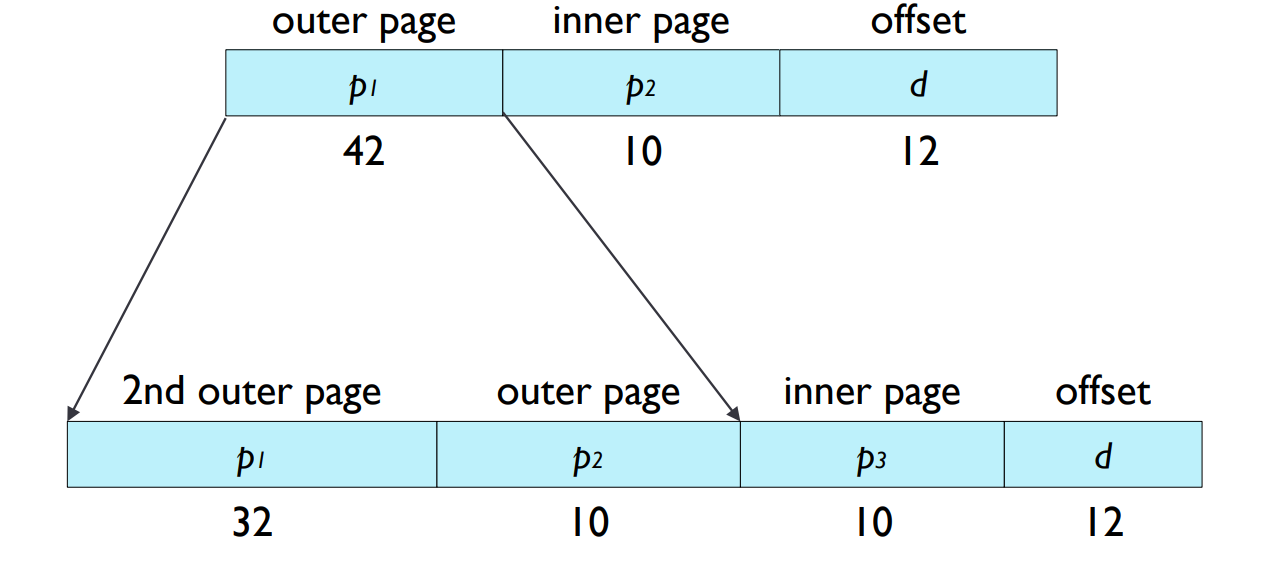
삼중 페이지 테이블 체계(Three-level Page Table Scheme): 이는 64비트 프로세서를 위한 삼중 페이징 구조입니다. 이 방법을 사용하면 매우 큰 주소 공간을 효율적으로 관리할 수 있습니다.
Hashed Page Table
- The logical page number is hashed into a table.
- Hash table
- The hash table contains
- a chain of elements hashed to the same location.
- The logical page number is compared with
- the first field of entries in chain for a match.
- If a match is found,
- the corresponding physical frame number is extracted.
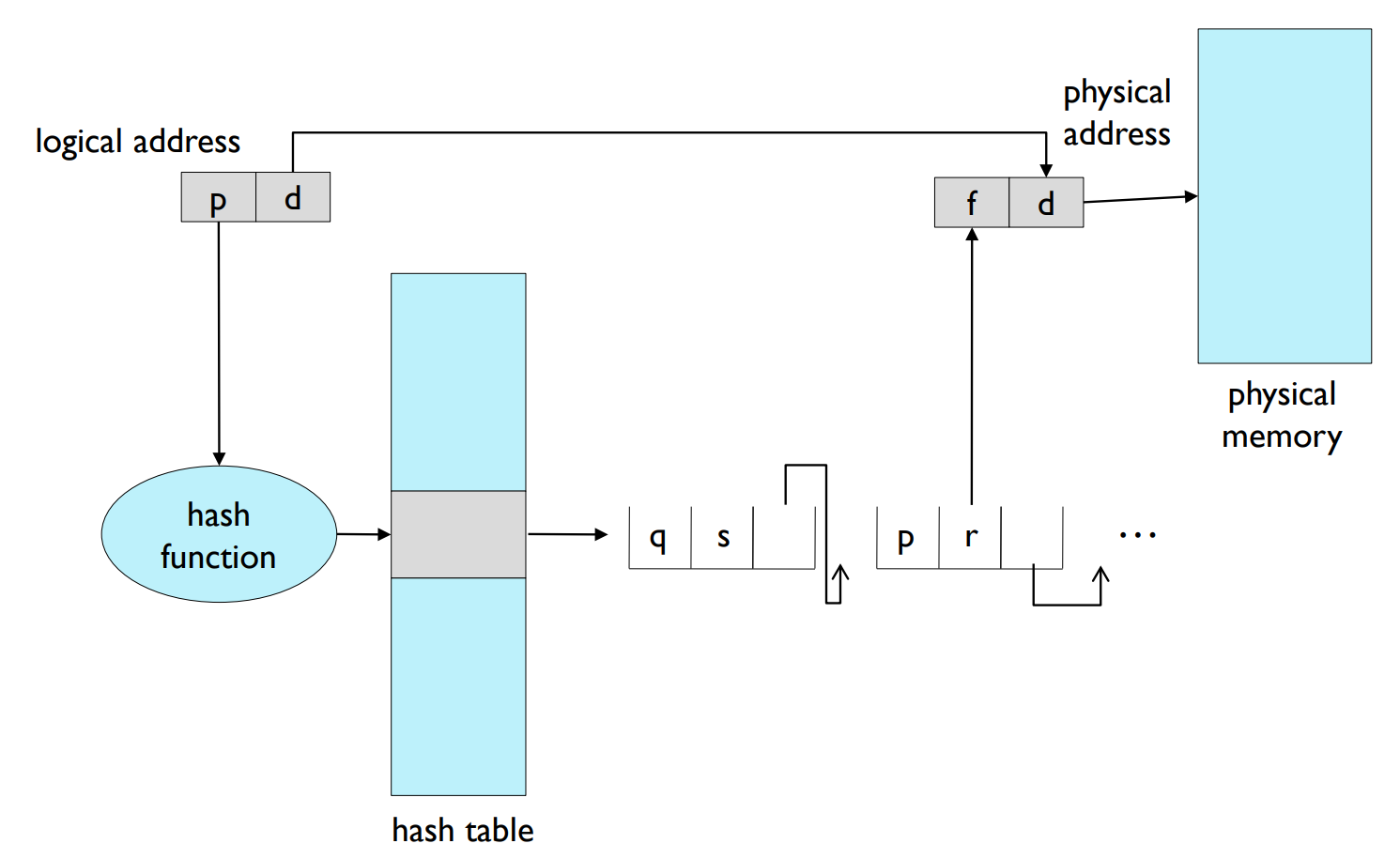
- the corresponding physical frame number is extracted.
해시 페이지 테이블: 해시 페이지 테이블은 논리 페이지 번호를 해시 테이블로 해시하는 방식을 사용합니다. 이 해시 테이블은 동일한 위치로 해시된 요소들의 체인을 포함하고 있습니다. 논리 페이지 번호는 체인 내의 항목들의 첫 번째 필드와 비교되어 매칭되는지 확인합니다. 매칭되는 항목이 발견되면, 해당하는 물리 프레임 번호가 추출됩니다.
해시 페이지 테이블: 해시 페이지 테이블은 페이지 테이블 관리에 대한 한 가지 방법입니다. 기본적으로, 논리적 페이지 번호를 키로 사용하여 해시 함수를 실행하고 이를 해시 테이블에 저장합니다. 해시 함수의 결과는 물리적 메모리의 페이지 프레임을 가리키는 인덱스 역할을 합니다.
각 해시 버킷에는 페이지 번호에 대한 매핑을 가진 일련의 항목들이 연결 리스트로 연결되어 있습니다. 이 리스트는 충돌이 발생할 때 사용되며, 이는 두 개 이상의 논리적 페이지 번호가 동일한 해시 버킷을 가리킬 때 발생합니다. 이러한 경우, MMU는 해당 연결 리스트를 검색하여 올바른 페이지 프레임을 찾습니다. 해시 페이지 테이블 방식은 주로 큰 메모리 공간을 가진 시스템에서 사용되며, 테이블의 크기를 크게 줄일 수 있습니다.
Inverted Page Table
- The space overhead of page table.
- The size of page table is proportional to program size.
- One page table entry for each page.
- Actually, just some pages are required at a time.
- Inverted page table
- One page table entry for each page frame.
- Each page table entry should contain process-id.
- Just one page table is sufficient in system.
- Entries are required as many as the number of page frames.
- It is an associative search, and need to search entire table.
- decreases memory needed to store each page table, but
- increases time needed to search the table.
- So, a hash table or associative registers should be used.
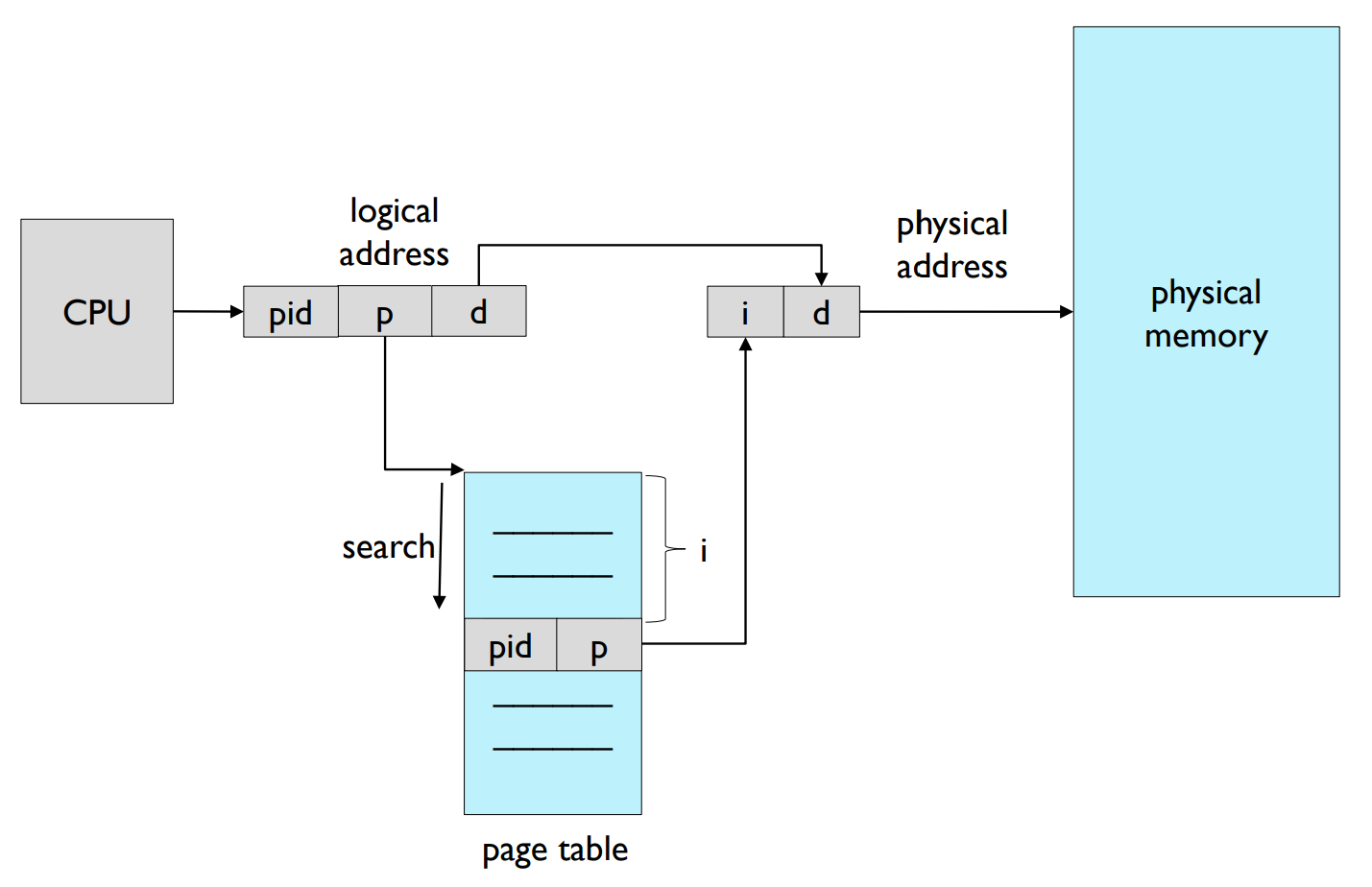
역 페이지 테이블: 페이지 테이블의 공간 오버헤드를 고려하여, 페이지 테이블의 크기는 프로그램 크기에 비례하도록 설계되었습니다. 즉, 각 페이지마다 페이지 테이블 항목이 하나씩 있습니다. 그러나 실제로는 한 번에 일부 페이지만 필요합니다. 역 페이지 테이블에서는 각 페이지 프레임마다 페이지 테이블 항목이 하나씩 있습니다. 각 페이지 테이블 항목에는 프로세스 ID가 포함되어야 합니다. 시스템에는 하나의 페이지 테이블만 있으면 충분하며, 페이지 프레임 수만큼의 항목이 필요합니다. 이는 연관 검색 방식을 사용하므로 전체 테이블을 검색해야 합니다. 이 방식은 각 페이지 테이블을 저장하는 데 필요한 메모리를 줄이지만, 테이블을 검색하는 데 필요한 시간을 늘립니다. 따라서 해시 테이블이나 연관 레지스터를 사용해야 합니다.
역 페이지 테이블: 역 페이지 테이블은 페이지 테이블의 다른 형태로, 메모리의 각 페이지 프레임에 대해 하나의 항목을 가지고 있습니다. 일반적인 페이지 테이블은 각 논리적 페이지에 대해 하나의 항목을 가지고 있으나, 역 페이지 테이블은 물리적 메모리를 기준으로 합니다.
각 역 페이지 테이블 항목에는 해당 프레임을 소유하고 있는 프로세스의 식별자와 해당 프로세스의 논리적 페이지 번호가 포함되어 있습니다. MMU가 논리적 주소를 물리적 주소로 변환할 때, 역 페이지 테이블은 해당 프레임이 메모리에 위치하는지, 혹은 스왑 공간에 위치하는지를 확인하는 데 사용됩니다.
역 페이지 테이블의 주요 이점 중 하나는 메모리를 절약하는 것입니다. 페이지 테이블은 프로그램의 크기에 따라 커지지만, 역 페이지 테이블은 물리적 메모리의 크기에 따라 크기가 결정됩니다. 이는 물리적 메모리 크기가 일반적으로 가상 메모리 크기보다 작기 때문에, 테이블의 크기를 줄일 수 있는 장점을 가지고 있습니다.
그러나 역 페이지 테이블을 사용하면 메모리 접근 시간이 증가할 수 있습니다. 이는 주소 변환을 위해 전체 테이블을 검색해야 합니다.
차이점
해시 페이지 테이블:
해시 페이지 테이블은 페이지 테이블 항목들을 해시 함수를 사용하여 인덱싱하는 방법을 사용합니다. 이 방식은 메모리 접근 시간을 상당히 줄일 수 있지만, 동일한 해시 값에 여러 페이지가 매핑될 수 있는 해시 충돌 문제를 해결해야 합니다. 충돌이 발생하면, 주로 연결 리스트를 사용해 충돌을 해결합니다. 해시 페이지 테이블은 주로 큰 메모리 공간을 가진 시스템에서 사용되며, 테이블의 크기를 크게 줄일 수 있습니다.
역 페이지 테이블:
역 페이지 테이블은 각 물리적 페이지 프레임에 대해 하나의 항목을 가지고 있으며, 이 항목은 현재 해당 페이지 프레임을 사용하고 있는 논리적 페이지의 정보를 담고 있습니다. 이는 페이지 테이블이 물리적 메모리의 크기에 따라 결정되므로, 메모리를 절약할 수 있는 장점이 있습니다. 그러나 역 페이지 테이블을 사용하면 메모리 접근 시간이 증가할 수 있습니다. 이는 주소 변환을 위해 전체 테이블을 검색해야 하기 때문입니다.
요약하면, 이 두 가지 방법은 트레이드오프(trade-off) 관계에 있습니다. 해시 페이지 테이블은 접근 시간을 줄이는 데 초점을 맞추고, 역 페이지 테이블은 메모리 공간을 절약하는 데 초점을 맞춥니다. 어떤 방법을 선택할지는 시스템의 요구 사항과 구현의 복잡성에 따라 달라집니다.
Segmentation
- A program is a collection of segments.

- Segment table
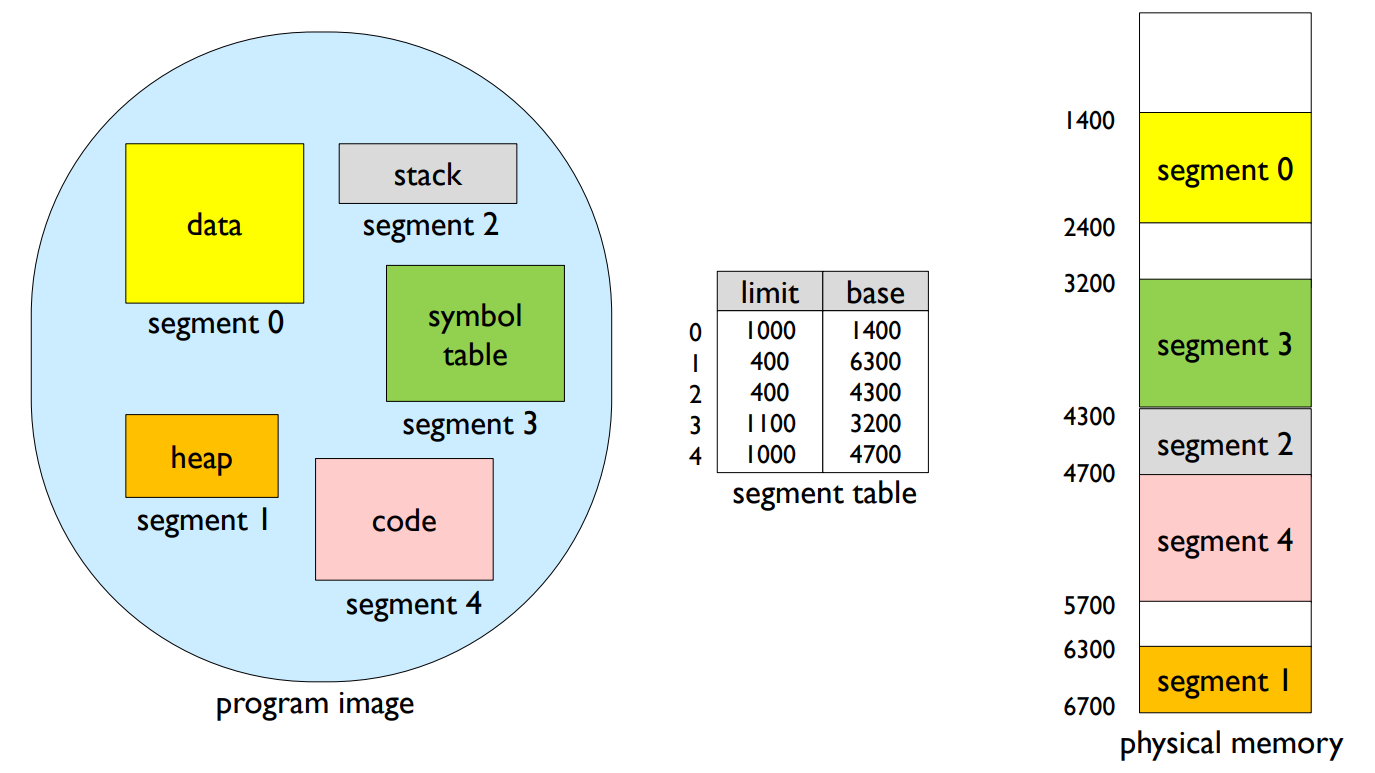
- Logical address consists of
- <segment-number, offset>.
- Segment table
- Each table entry has
- base – the starting physical address where the segments reside in memory
- limit – the length of the segment
- Each table entry has
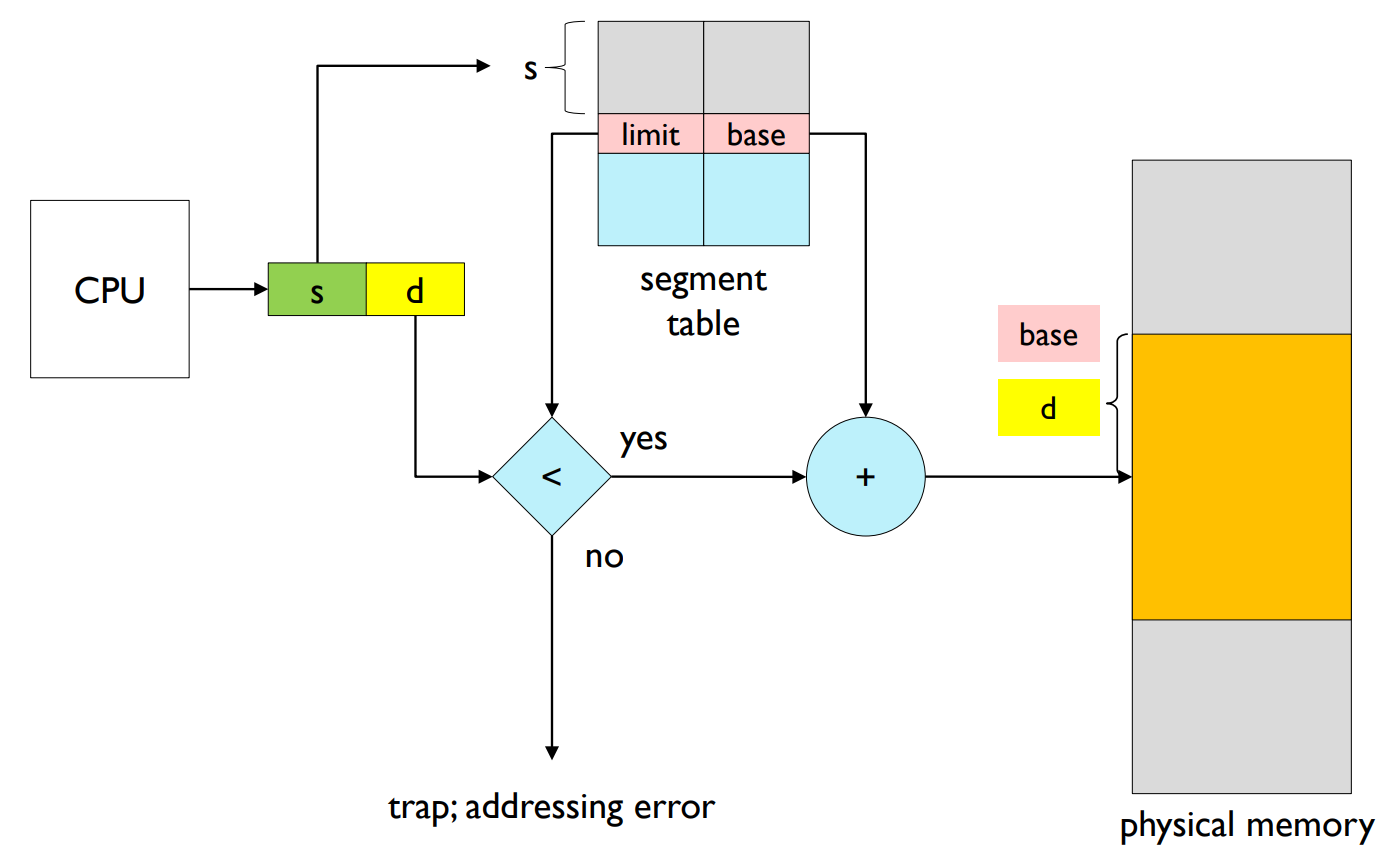
- Segment-table base register (STBR)
- points to the segment table’s location in memory.
- Segment-table length register (STLR)
- indicates the number of segments used by a program.
- segment number s is legal if s < STLR.
- Address translation with segmentation architecture
- Protection
- Protection bits are associated with segments
- validation bit.
- read/write/execute privileges.
- Protection bits are associated with segments
- code sharing occurs at segment level.
- Since segments vary in length,
- there exists a dynamic storage-allocation problem.
- Do you remember first-fit, best-fit, and worst-fit?
- there exists a dynamic storage-allocation problem.
-
세그먼테이션: 세그먼테이션은 프로그램을 여러 개의 세그먼트로 나누는 메모리 관리 기법입니다. 각 세그먼트는 기능적으로 의미있는 단위(예: 함수, 데이터 구조 등)로 나누어지며, 각각의 크기는 다양할 수 있습니다.
-
세그먼트 테이블: 세그먼트 테이블은 각 세그먼트에 대한 정보를 저장하는 자료구조입니다. 테이블의 각 항목은 세그먼트의 시작 물리주소(베이스)와 세그먼트의 길이(리미트)를 포함합니다.
-
세그먼트 테이블 베이스 레지스터(STBR)와 세그먼트 테이블 길이 레지스터(STLR): STBR은 메모리에서 세그먼트 테이블의 위치를 가리키며, STLR은 프로그램이 사용하는 세그먼트의 수를 나타냅니다. 즉, 세그먼트 번호 's'는 's < STLR'일 경우 합법적입니다.
-
주소 변환: CPU가 생성하는 논리 주소는 <세그먼트 번호, 오프셋>으로 구성되며, 이를 물리 주소로 변환하는 과정이 필요합니다. 이 과정에서는 세그먼트 테이블을 참조하여 해당 세그먼트의 베이스 주소와 오프셋을 더해 최종적인 물리 주소를 계산합니다.
-
보호: 세그먼트는 보호 비트를 가지고 있어, 이를 통해 해당 세그먼트에 대한 접근 권한(read/write/execute)을 제어할 수 있습니다. 또한 유효 비트를 통해 해당 세그먼트가 유효한지를 판단할 수 있습니다.
-
공유: 세그먼테이션에서는 세그먼트 수준에서의 코드 공유가 가능합니다. 이는 특정 세그먼트를 여러 프로세스가 동시에 접근할 수 있음을 의미합니다.
-
동적 저장소 할당 문제: 세그먼트는 크기가 다양하기 때문에, 메모리를 어떻게 할당할지에 대한 동적 저장소 할당 문제가 발생합니다. 이는 특정 메모리 공간에 어떤 세그먼트를 할당할 것인지 결정하는 문제로, 메모리를 효율적으로 사용하려면 이 문제를 효율적으로 해결해야 합니다. 이를 위해 사용되는 알고리즘으로는 First-fit, Best-fit, Worst-fit 등이 있습니다.
Summary
- Address binding is the process of associating program instructions and data to physical memory addresses.
- Address binding can happen at three different stages; compile time, load time, and execution time.
- In execution time binding, binding is delayed until run time. Namely, whenever CPU generates the address, binding is checked.
- MMU (Memory Management Unit) is a hardware that maps logical addresses to physical addresses.
- In paging, entire program image resides on disk. When the program starts, just load the first page only. The rest of pages are loaded in memory on-demand.
- Paging enables the execution of program larger than physical memory.
- In paging, every data/instruction access requires two memory accesses; one for the page table and the other for the data/instruction.
- In multi-level page table scheme, the page table itself is also paged.
요약: 주소 바인딩은 프로그램의 명령어와 데이터를 물리 메모리 주소에 연결하는 과정입니다. 이 바인딩은 컴파일 시간, 로드 시간, 실행 시간 세 가지 단계에서 발생할 수 있습니다. 실행 시간 바인딩에서는 실행 시간 동안 CPU가 주소를 생성할 때마다 바인딩이 검사됩니다. 이러한 작업은 MMU(Memory Management Unit)라는 하드웨어가 수행하며, 논리 주소를 물리 주소로 변환합니다. 페이징에서는 프로그램의 전체 이미지가 디스크에 저장되며 프로그램이 시작될 때 첫 번째 페이지만 로드됩니다. 나머지 페이지는 필요에 따라 메모리에 로드됩니다. 페이징은 물리 메모리보다 큰 프로그램의 실행을 가능하게 합니다. 페이징에서는 모든 데이터/명령어 액세스가 두 번의 메모리 액세스를 필요로 합니다; 하나는 페이지 테이블에 대한 것이고 다른 하나는 데이터/명령어에 대한 것입니다. 다단계 페이지 테이블 체계에서는 페이지 테이블 자체도 페이징됩니다.
