elkstack (ELKB)
- elasticsearch, logstash, kibana, beats (filebeat 외에도 Metricbeat, packetbeat 등 다양한 beat 존재) 이렇게 네개를 이르는 말. 근데 ELKB 보다는 ELKStack을 사용한다고 - why?
과정
filebeat -> logstash -> elasticsearch -> kibana (시각화)
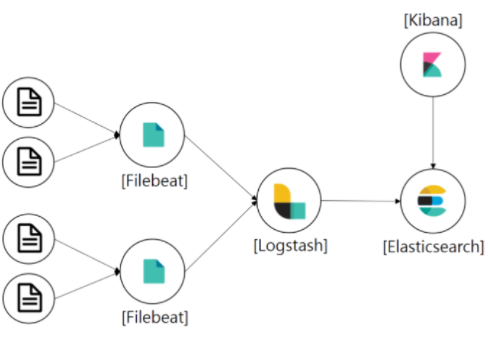
elasticsearch
- 실시간 분석 시스템 (클러스터가 실행되고 있는동안 데이터가 계속해서 입력되고, 그와 동시에 색인하여 리얼타임 검색/집계가 가능)
- 리얼타임으로 인덱싱이 가능한건 역인덱스 구조로 풀텍스트 검색을 하기 때문이라는데.. 자세한건 다음에
- 하둡은 데이터 수집 과정이 따로 필요한데, 얘는 그렇지 않다는게 장점
- 아파치 lucene 쿼리 사용
logstash
- Logstash는 Server-side 데이터 처리 파이프라인으로 다양한 소스에서 동시에 데이터를 수집하고 통합한다.
- 또한 수집된 데이터를 정규화하여 Elasticsearch 등의 목적지로 전송하는 역할을 한다.
- 거의 대부분의 이벤트를 수집하여 변호나할 수 있으며 기본으로 제공되는 여러 코덱을 이용하여 수집(Ingestion) 프로세스를 한층 더 간소화할 수 있다.
kibana
- 덜도말고, 더도말고 그냥 시긱화 대시보드.
filebeat
- Elastic 공식 홈페이지에서 소개하는 Filebeat를 설명하자면, Filebeat는 로그 데이터를 전달하고 중앙화하기 위한 경량의 Producer
- 서버에 에이전트로 설치되는 Filebeat는 지정한 로그 파일 또는 위치를 모니터링하고 로그 이벤트를 수집한 다음 인덱싱을 위해 Elasticsearch 또는 Logstash로 전달한다.
- 작동 방식
- Filebeat를 시작하면 설정에서 지정한 로그데이터를 바라보는 하나이상의 inputs을 가진다. 지정한 로그 파일에서 이벤트(데이터발생)가 발생할 때마다 Filebeat는 데이터 수확기(harvester)를 시작한다. 하나의 로그 파일을 바라보는 각 havester는 새 로그 데이터를 읽고 libbeat에 보낸다. 그리고 libbeat는 이벤트를 집계하고 집계된 데이터를 Filebeat 설정에 구성된 출력으로 데이터를 보낸다.
- Filebeat는 각 파일의 상태를 유지하며 레지스트리 파일의 상태를 디스크로 자주 플러시한다. 상태는 수확기(havester)가 읽었던 마지막 오프셋을 기억하고 모든 로그 라인이 전송되는지 확인하는 데 사용된다. Elasticsearch 또는 Logstash와 같은 출력에 도달 할 수 없는 경우 Filebeat은 마지막으로 보낸 행을 추적하고 출력이 다시 사용 가능 해지면 파일을 계속 읽는다. Filebeat가 실행되는 동안 상태 정보도 각 입력에 대해 메모리에 보관된다. Filebeat가 다시 시작되면 레지스트리 파일의 데이터가 상태를 다시 작성하는 데 사용되며 Filebeat은 마지막으로 알려진 위치에서 각 수확기를 계속 사용한다 또한 Filebeat는 적어도 한번 이상 구성된 데이터를 지정한 출력으로 전달함을 보장한다.
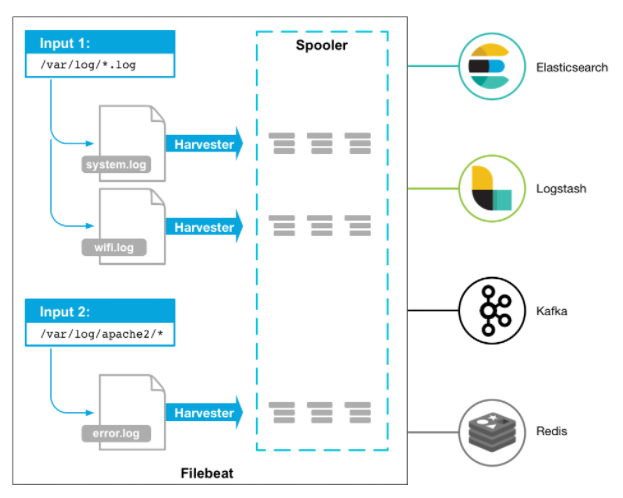
- 보통 logstash로 보내나, 로그의 고가용성 및 유실 방어를 위해 Kafka/redis에 전달하기도 함
- Logstash는 sharding과 replication 등을 지원하지 않기 때문
filebeat vs. logstash
내가 알기로는 elk 까지만 알고 있었는데.. filebeat가 얘의 일종일줄 몰랐음- 2015년 Beats가 도입되며 ELK -> ELK Stack / ELKB 등으로 불렸다고 함
- Beats: 서버에 에이전트로 설치하여 데이터를 수집하고, 그 결과를 ES로 직접 전송, 또는 Logstash로 전송
- logstash는 데이터 수집 / 가공+변환 해서 ES에 전송
- 이전에는 logstash의 데이터 수집 소스가 바로 서버의 파일들이었다면, 이제는 filebeat가 그 역할을 대신하고, logstash는 가공+변환에 집중
- 왜 logstash를 raw data collect에 사용하지 않냐고 ?
- log파일을 Logstash로 수집하지 않고 Filebeat를 사용하는 이유는 경량화되어 data 수집 및 전달에 최적화되어있기 때문이다.
- (Filebeat는 Logstash보다 시스템 공간과 사용 공간이 적기 때문에 더 적은 리소스를 요구한다.)
- 경량화, backpressure 조절 가능, persistence queue를 통한, 최소 한번 전송 보장
- 따라서 데이터 가공+변환이 필요 없다면 logstash를 끼지 않고, filbeat -> ES로 직접전송하는 것
- 즉 ETL에서 filebeat: Extract, logstash: Transformation, es: Load 의 느낌
출처
https://coding-start.tistory.com/135 [코딩스타트]
https://suyeon96.tistory.com/40
https://velog.io/@deet1107/logstash-filebeat
https://m.blog.naver.com/ksh60706/221729113310
https://findstar.pe.kr/2018/05/28/install-and_configuration-filebeat-logstash/
https://sabarada.tistory.com/46

꿈많은 개발자, 일상 기록을 곁들인