Beam Search and BLEU score
Further Question
- BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇일까요?
Beam Search
RNN의 학습과정에서 트리 탐색 기법으로 쓰인다.
Greedy decoding
현재 가장 좋아보이는 단어를 선택하는 방법
시간 복잡도 면에서는 좋지만 최종 정확도 관점에서는 좋지 않은 방법이다.
이전 예측이 다음 예측에 큰 영향을 주기 때문에 decoding 방식에서는 치명적인 문제가 생긴다.
Exhaustive search
너무 오래 걸림 → Beam search
Beam search
- Core idea: decoder의 매 time step마다 k개의 가능한 가지 수를 고려한다.
- k개의 후보군 중에서 다시 가장 가능성이 높은 k개의 후보군을 고른다.
- depth가 n일 때 의 child node 중 각 branch의 누적 확률이 가장 큰 k개의 node를 선택한다.
- 가 나올 때까지 계속 k개의 child node를 만들고 확률이 가장 큰 k개를 고른다.
- 를 만난 빔은 두고 다시 누적 확률이 가장 큰 k개를 선택해서 진행한다.
- 를 만난 빔이 k개가 되면 k개의 후보군 중에 가장 누적확률이 큰 빔을 최종 선택한다.
- Global optimal solution을 보장하지는 않지만 exhaustive search보다는 좋다.
ex) k=2
각각의 후보군에서 더 log 값이 큰 값을 선택한다.
모든 후보군에서 다음으로 예측되는 단어들을 계속 예측한다.
Greedy decoding에서는 token이 나오면 멈춘다.
Beam search decoding에서는 다른 hypotheses에서 다른 time step에서 token을 발생시킨다.
Beam search: Stopping criterion
timestep T에 도달하면 멈추게 된다.
Beam search: Finishing up
- Problem: 긴 길이의 sequence가 낮은 score를 갖게 됨(log 값이 음수이기 때문에 음수가 계속 더해짐)
- Fix: Normalize by length
BLEU score
LM의 성능 측정을 위한 평가 방법으로 PPL(Perplexity)가 있다. 기계 번역에서도 PPL을 사용할 수는 있지만 번역 성능을 직접적으로 반영하는 수치라 보기엔 어렵다. 기계 번역의 성능 측정에 사용되는 대표적인 방법이 BLEU이다.
Precision and Recall
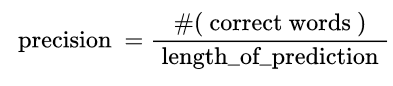

Ex) I love you - Oh I love you
→ 문장이 비슷하지만 단어 하나하나 비교할 때는 accuracy가 0으로 나오게 됨
문장 전체를 고려하는 평가 방법을 사용해야함
Precision과 Recall의 평균을 구함
- 산술
- 기하
- 조화 (ex. F - measure) 작은 값에 초점을 둔다.
조화 < 기하 < 산술
BLEU (BiLingual Evaluation Understudy)
- Uni-gram Precision
순서에 상관없이 reference와 겹치는 단어들로 precision을 구한다.
문장의 길이가 reference 문장보다 길어져도 1로 값을 유지한다.
- N-gram overlap
N개의 연속된 단어가 ground truth와 얼마나 겹치는지를 확인
순서가 고려되지 않는 uni-gram의 단점을 보완할 수 있다.
→ 기하 평균을 사용
조화 평균은 크기가 작은 것에 지나치게 크게 가중치를 주게 됨
Brevity penalty
n-gram으로 단어의 순서를 고려한 precision을 구한다고 해도 predict의 길이가 길어질수록 BLEU가 작아지는 문제가 남아있다.
Brevity penalty - Recall을 고려함
