Transformer
Attention is all you need
sequence data를 입력 받고 sequence data를 예측하는 모델
Bi-Directional RNNs
- Forward RNN
- Backward RNN
Transformer: Long-Term Dependency
Self-Attention → Long-Term dependency를 해결하는 sequence encoding 기법
Query
Key - 높은 유사도를 가지는 벡터를 가져오는 벡터
Value
Transformer: Scaled Dot-Product Attention
Value 값의 weight는 query와 key의 내적으로 계산된다.
내적 값을 계산하기 위해서 query와 key의 dimension은 d_k로 같다.
value vector의 dimension은 key와 query의 dimension과 꼭 같지 않아도 된다.
Transformer: Multi-head Attention
value, key, query로 여러 개의 attention을 수행한다.
동일한 sequence에 대해서 여러 개의 query로 여러 가지 정보를 얻어내야할 수 있다.
Self-Attention에서는 QK^T에서의 연산이 연산량의 가장 많은 부분을 차지한다.
self attention O(n^2 * d)
sequential operation → GPU 활용으로 O(1)
Max length path - O(1)
Long term dependency를 근본적으로 해결
RNN O(n *d^2)
hidden state에서 Whh와 h vector의 연산에서 d^2의 연산량이 발생하기 때문이다.
n은 sequence 길이이며 길이가 길어지면 연산량이 기하급수적으로 늘어난다.
d는 하이퍼 파라미터로 조절이 가능하다.
sequential operation → GPU 활용 x - O(n)
Transformer: Block based model
Residual connection : x+ self-attention(x)
Transformer: Layer Normalization
Standardization: column 별로 평균을 0, 표준편차를 1로 만들어줌
Affine transformation - node 별로 transformation을 적용
Position encoding
Attention을 통한 encoding에서는 문장의 순서가 바뀌어도 각 단어의 encoding 결과는 같다.
RNN은 순서가 달라지면 encoding 결과가 달라진다.
위치가 달라지면 결과값이 달라지게 한다.
Transformer: High View
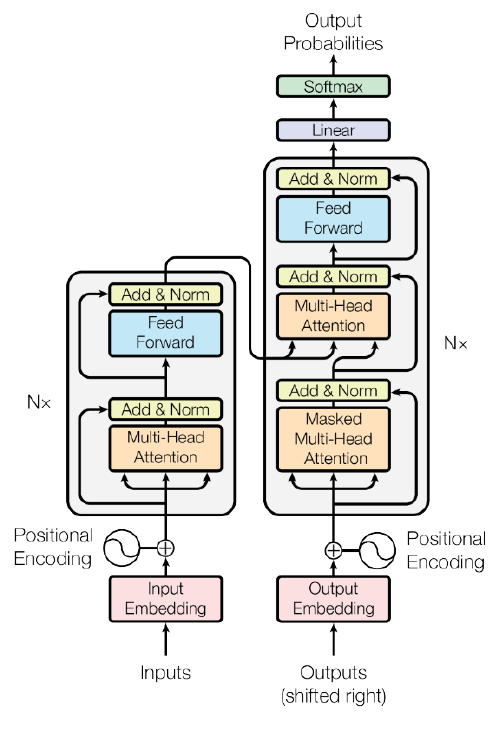
Decoder hidden state를 query 값으로 어느 encoding vector에 가중치를 줘야하는지 체크
Masked Self-Attention
이후에 나오는 단어들에 대해서 값을 0으로 바꾸면서 masking 한다.
