지구미 프로젝트를 진행하면서 구현한 기능 중에 하나는 지도에서 내 주변 공동 구매 정보를 지도에 마커를 찍어 표시한다.
그래서 좌표 데이터를 다루게 되었는데, 좌표를 다룰 수 있는 방법이 공간형 데이터 타입 spatial를 이용하거나, Decimal을 이용해서 다루는 2가지 방법이 있다는 것을 알았다.
어떻게 저장 하는 것이 좋을지 알아보자 !
MySQL 공간 데이터 개요
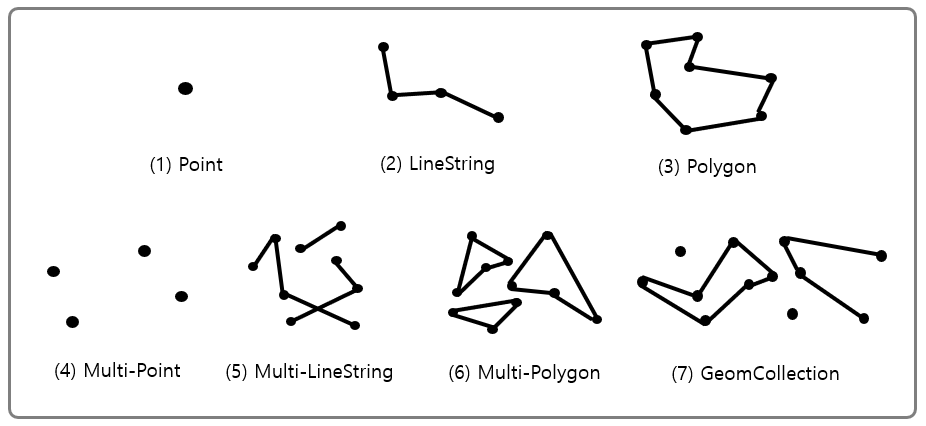
| 타입 | 정의 | 예시 |
|---|---|---|
| Point | 좌표 공간의 한 지점 | POINT(10 10) |
| LineString | 다수의 Point를 연결해주는 선분 | LINESTRING(10 10, 20 20, 30 30) |
| Polygon | 다수의 선분들이 연결되어 닫혀있는 상태 | POLYGON((10 10, 10 20, 20 10, 10 10)) |
| Multi-Point | 다수의 Point 집합 | MULTIPOINT(10 10, 20 20) |
| Multi-LineString | 다수의 LineString 집합 | MULTILINESTRING((10 10, 20 20), (15 15, 25 25)) |
| Multi-Polygon | 다수의 Polygon 집합 | MULTIPOLYGON(((10 10, 10 20, 20 10, 10 10)), ((40 40, 30 30, 40 40))) |
| GeomCollection | 모든 공간 데이터들의 집합 | GEOMETRYCOLLECTION(POINT(10 10), LINESTRING(20 20, 30 30)) |
MySQL이 지원하는 공간 데이터의 종류이다.
단일 타입으로는 Point, LineString, Polygon이 있고, 나머진 이 세가지 타입의 조합이다.
공간 함수는 MySQL Docs를 참고하자 !
R-Tree
공간 데이터를 다루면 필히 인덱스를 적용하게 된다. 그럼 공간 데이터의 인덱스도 B-Tree로 다룰까?
아니다. 공간 인덱스 R-Tree 라는 자료 구조를 이용한다.
R-Tree 는 점, 선, 면(다각형)과 같은 다차원 정보를 효율적으로 저장하기 위한 트리 형태의 자료구조이다.
R-Tree는 MBR을 알아야 하는데, 그래서 MBR이 뭘까?
그림을 보면서 이해를 해보자.
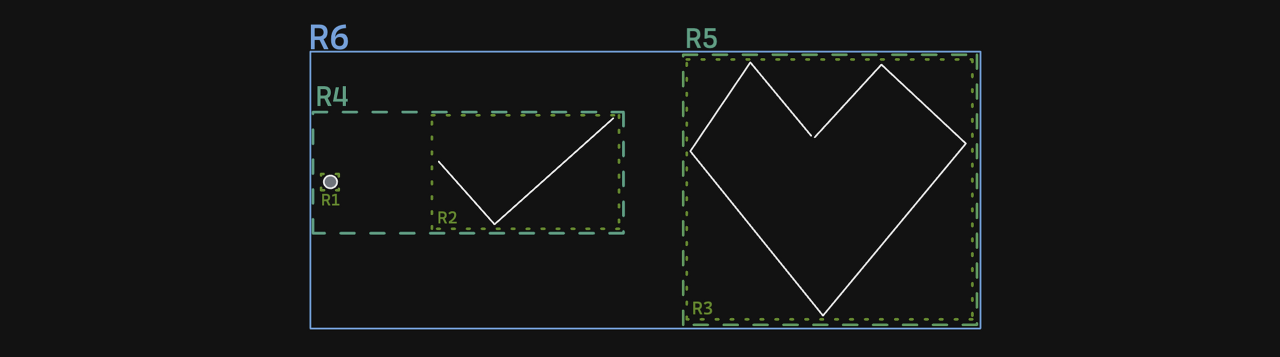
위의 그림을 보면 점, 선, 어떤 도형을 기준으로 그 도형을 포함한 사각형이 만들어졌고, 이 모든 도형을 포함하는 사각형이 만들어졌다.
MBR 은 Minimun bounding rectangle로 특정 도형을 감싸는 최소 크기의 사각형을 의미한다.
그래서 이를 바탕으로 R-Tree를 구성하는데 아래의 그림을 보면 더 이해가 쉬울 것이다.
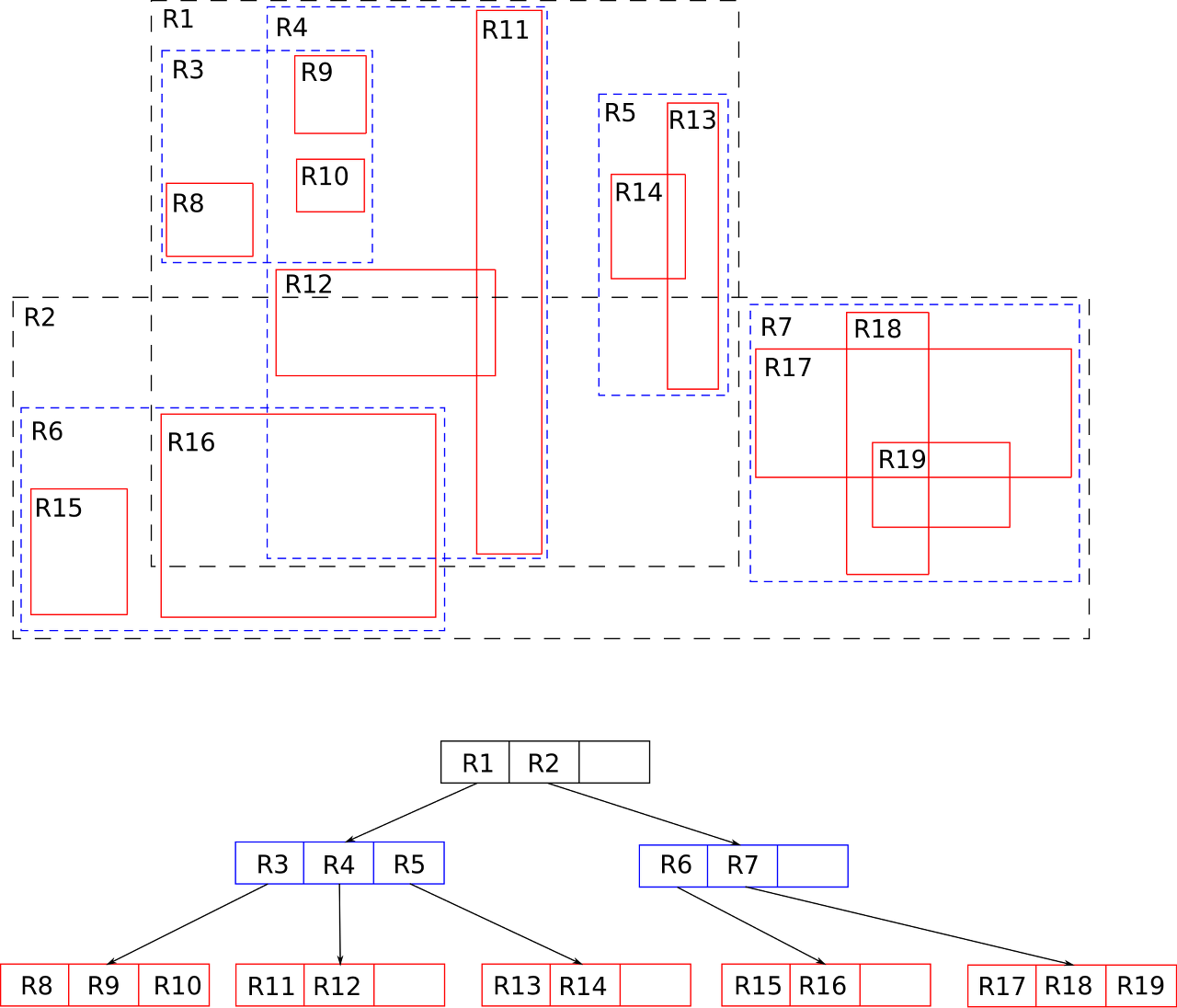
R-Tree 자료구조는 B-Tree 와 흡사한 형태로 구성되어있다.
각 노드에 저장할 수 있는 도형의 개수는 사전에 지정되는데, 최대 M개에서 최소 m(M/2)개 저장할 수 있다.
또한 B-Tree 처럼 리프 노드에 데이터(도형)를 저장하고, 리프 노드가 아닌 노드는 MBR 간의 포함관계를 표현한다.
탐색은 Top-down 방식으로 진행되며 루트 노드부터 리프 노드까지 내려간다.
이때 MBR 간에 중첩된 영역이 많을수록 탐색 성능은 떨어진다.
그 이유는 중첩된 영역이 이 많을수록 탐색할 노드가 많아지기 때문이다.
탐색 과정은 다음과 같다.
- 루트 노드부터 모든 하위 노드들을 순회하며 MBR 을 이용하여 검색 영역 내에 들어오는지 검사
- 리프 노드를 찾으면 포함된 도형들이 검색 영역에 포함되는지 확인
따라서 이를 바탕으로 공간 인덱스를 이용해 탐색하는 방법을 알아보자.
공간 인덱스를 이용한 탐색
아래는 내가 테스트를 위한 DDL이다.
CREATE TABLE test.goods
(
point POINT NOT NULL,
created_date datetime(6) null,
goods_id bigint auto_increment
primary key,
modified_date datetime(6) null,
);
ALTER TABLE test.goods MODIFY point POINT NOT NULL SRID 5181;
CREATE SPATIAL INDEX point_spatial_index ON test.goods(point);여기서 SRID는 공간 참조 식별자로 평면 지구 매핑 또는 둥근 지구 매핑에 사용되는 특정 타원을 기반으로 하는 공간 참조 시스템에 해당한다.
나는 카카오맵을 쓰기 때문에 카카오 맵의 SRID인 EPSG: 5181을 썼다.
이 값을 넣지 않을 경우 default 값인 0이 들어가게 되는데, 이 경우에 Insert 하게 되면 데이터도 default 값이 0으로 들어가게 된다.
그 후 5181로 조회한다면 인덱스를 타지 않고 테이블 풀스캔을 하게 된다. 또한 Insert 된 데이터도 다 날리고 다시 넣어야 SRID가 제대로 설정 되기 때문에 조심하자.
데이터가 밀집되어 분포되어 있을 때
더미 데이터를 반복문을 이용해서 일정하게 분포되게 넣었다.
JPQL이 작성한 쿼리를 바탕으로 SQL 문을 만들어 날려보니,
SELECT g1_0.goods_id
FROM test.goods g1_0
WHERE ST_INTERSECTS(
ST_SRID(
ST_GeomFromText('POLYGON((128.5 128.5, 128.6
128.5, 128.6 128.6,
128.5 128.6, 128.5 128.5))'),
5181),
g1_0.point)
ORDER BY g1_0.created_date DESC;
잘 타는 모습이다. Decimal, 공간 타입의 실제 운영의 차이를 보자 !
Decimal vs 공간 타입
처음 구현을 하게 됐을 때, 이전 MySQL이 공간 타입을 지원하지 않을 때 좌표 값을 Decimal 같은 숫자로 저장했다는 사실을 알게 되었다. 나도 물론 공간 타입이라는 걸 몰랐기 때문에, Decimal로 아래와 같이 구현했다.
create table test.goods
(
mapx decimal(17, 13) null,
mapy decimal(17, 13) null,
created_date datetime(6) null,
goods_id bigint auto_increment
primary key,
modified_date datetime(6) null
);
create index goods_mapy_mapx_index
on jigume.goods (mapy, mapx);위와 똑같이 더미 데이터 10000건을 넣고 JPQL이 작성한 쿼리를 바탕으로 SQL을 다음과 같이 날려보았다.
select g1_0.goods_id
from jigume.goods g1_0
where g1_0.mapx >= 128.5
and g1_0.mapx <= 128.6
and g1_0.mapy >= 128.5
and g1_0.mapy <= 128.6
order by g1_0.created_date desc;- Decimal 타입으로 Index를 타는 경우

- 공간 타입으로 Index를 타는 경우

Cost는 공간 인덱스를 타는게 미미한 차이로 싸고, 실행 시간은 Decimal 타입이 3배 정도 빠르다.
데이터 분포를 랜덤하게 했을 때
이제 데이터를 랜덤하게 넣어서 측정해보자.
더미 데이터를 반복문과 RAND() 함수를 이용해서 랜덤하게 분포되게 넣었다.
(데이터 크기를 완벽하게 같게 할 수는 없어서 비슷한 값이 나오도록 했다.)
Decimal vs 공간 타입
아래는 쿼리 실행 계획을 분석했다.
- Decimal 타입

- 공간 타입

(R-Tree 특징처럼 확실히 데이터 분포도가 퍼져있는게 빠른 듯 싶다.)
Cost는 공간 인덱스를 타는게 6~7배 효율적이고, 실제 걸린 시간은 Decimal이 미세하게 빠르다.
완벽히 정확하게 논할 수 없겠지만, 그래도 압도적으로 공간 인덱스가 빠를거라고 생각했는데 이게 어떻게 된 일일까?
추정한 바로는 2가지의 이유가 있었다.
- 인덱스 크기: 공간 인덱스는 일반적으로 B-Tree 인덱스보다 크기가 크다. 여기선 길이가 34였고, Decimal index는 18이였다. 따라서 인덱스 키의 길이 때문에 쿼리 실행 시간을 늘어났다.
- R-Tree의 복잡성: B-Tree보다 R-Tree가 더 복잡한 구조를 가지고 있기 때문에, 공간 인덱스를 통해 데이터를 검색할 때 이는 실행 시간이 늘었다.
결과
당장은 실행 시간이 우세한 Decimal이 유리해보인다. 그럼에도 공간 데이터를 쓰는 이유는 무엇일까?
공간 데이터를 쓰게 된다면 장점은 공간 데이터 타입을 사용하면 점, 선, 면 등 다양한 형태의 공간적 객체를 표현할 수 있다. 또한, 이러한 객체들 사이의 공간적 관계(예: 겹침, 교차, 인접 등)를 정확하게 표현하고 계산할 수 있다.
즉, 두 좌표 사이의 거리를 정확히 구하거나 복잡한 도형의 영역에 포함되는지 지원하는 공간 함수를 사용할 수 있다.
또한, 데이터가 커지게 되면 공간 인덱스는 데이터의 공간적 관계를 고려하여 인덱싱을 수행해서 데이터가 밀집되어 있어도 공간적 분포를 고려한 검색이 가능하다.
반면에, decimal 인덱스는 각 좌표를 개별적으로 인덱싱하므로, 좌표 간의 공간적 관계를 고려하지 않는다.
결국 모든 상황을 고려해보고 선택하는게 좋지만, 추후 우리 서비스가 나와의 거리가 가까운 순으로 정렬하거나 공간에 관한 다양한 기능을 넣게 된다면 유지, 보수에 있어 이점을 챙길 수 있을 것으로 보여 공간 인덱스를 도입하기로 했다!
느낀 점
요즘 이력서를 쓰고 서류를 넣다보니 프로젝트를 오랜만에 시작하게 됐다. 이번 글을 쓰면서 RDB, SQL 튜닝, JPA, 테스트 도구 활용에 대해 학습하고 적용해보면서 CS가 부족하다는 사실을 뼈저리게 느꼈다.
그리고 SQL과 RDB 책을 도서관에서 빌려 빠르게 읽고 적용했는데 백문이불여일견이라고 앉아서 책만 읽을 땐 죽어도 안읽히던 것들이 실제로 하나 하나 해보면서 찾아보니 금방 느는 것 같다.
빨리 프로젝트 고도화 작업을 끝내고 실제 서비스를 사용자들에게 선보이고 싶다..!
레퍼런스
https://kong-dev.tistory.com/245#google_vignette
https://sparkdia.tistory.com/24?category=1114027
https://dev.mysql.com/doc/refman/8.0/en/spatial-index-optimization.html
