Primary Index
- 기본키를 기반으로 만들어진 이덱스를 말합니다.
- 키는 각 레코드에 대해 고유하며, 레코드 간 1:1 관계를 맺고 있습니다.
- 기본 인덱스를 사용하여 데이터를 검색하여 정렬된 순서로 데이터를 저장하기 때문에 효율적입니다.
- Dense Index와 Sparse Index의 두 가지 유형으로 분류할 수 있습니다.
Dense Index
- 데이터 파일의 모든 검색 키 값에 대한 인덱스 레코드가 포함되어 있습니다
- 검색 속도가 빨라진다는 특징이 있습니다.
- 인덱스 테이블의 레코드 개수는 메인 테이블의 레코드 개수와 같습니다.
- 인덱스 레코드 자체를 저장하려면 많은 저장 공간이 필요합니다
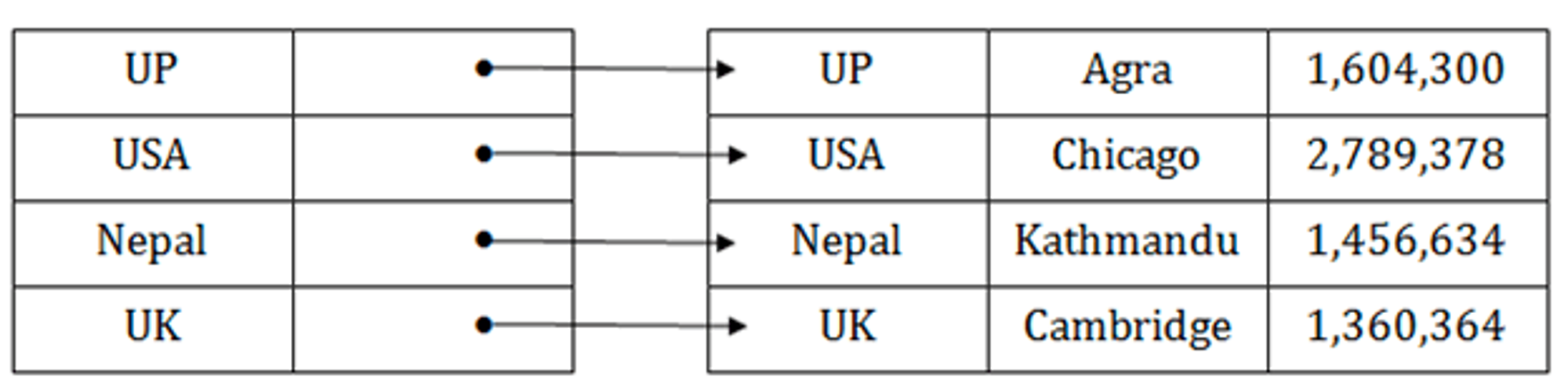
Sparse Index
- 데이터 파일에서 인덱스 레코드는 일부 항목에 대해서만 나타납니다.
- 각 항목은 블록을 가리킵니다.
- 기본 테이블의 각 레코드를 가리키는 대신 간격으로 기본 테이블의 레코드를 가리킵니다.
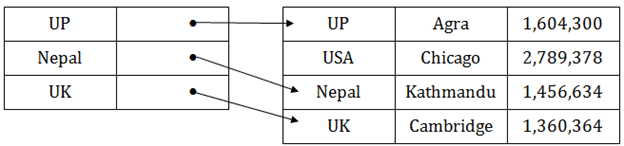
Secondary Index
테이블의 크기가 커질수록 매핑의 크기도 커집니다.
이런 매핑의 경우, 일반적으로 주소 가져오기가 더 빨라지도록 기본 메모리에 보관됩니다.
→ 이후 보조 메모리는 매핑에서 얻은 주소를 기반으로 실제 데이터를 검색합니다.
→매핑 크기가 커지면 주소 자체를 가져오는 속도가 느려집니다.
이런 경우에는 Sparse Index는 효율적이지 않게 됩니다. 이 문제를 해결하기 위해 Secondary Index가 생기게 되었습니다
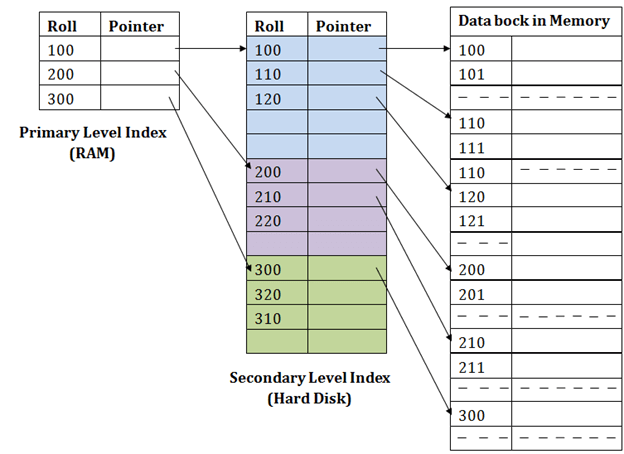
- 매핑 크기를 줄이기 위해 다른 수준의 인덱싱이 도입되었습니다.
- 첫 번째 수준의 매핑 크기가 작아지도록 열에 대한 거대한 범위가 초기에 선택됩니다.
- 이 후 각 범위는 더 작은 범위로 더 나누어지게 됩니다.
- 첫 번째 수준의 매핑은 기본 메모리에 저장되므로 주소를 가져오기가 더 빨라지게 됩니다.
- 두 번째 수준의 매핑과 실제 데이터는 보조 메모리(하드 디스크)에 저장됩니다.
Primary Index vs Secondary Index
1) 정의
Primary Index의 경우 기본키를 포함하며, 중복항복을 포함하지 않는 필드의 집합인 Index 이지만, Secondary Index의 경우 Primary Index가 아니며, 중복항목을 포함할 수 있는 인덱스라는 점이 가장 큰 차이점 이라고 할 수 있습니다.
2) Order
Primary Index는 데이터 블록의 행이 인덱스 키에서 정렬되어야 하는 반면 Secondary Index는 데이터 블록에서 행이 실제로 구성되는 방식에 영향을 미치지 않습니다.
3) 인덱스의 수
primary Index의 경우 하나만 가지고 있지만, secondary Index는 여러개의 인덱스를 가질 수 있습니다.
참고
https://www.javatpoint.com/indexing-in-dbms
https://pediaa.com/what-is-the-difference-between-primary-and-secondary-index/

개발자를 꿈꾸는 학생입니다!