Database - Index
정의
“데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조”
색인 이라고 생각하면 쉽습니다. 색인은 책 뒤에서 '그 내용을 알고 싶으면 몇 페이지로 가라'라고 지름길을 안내해주는 것으로,흔히 '찾아보기'라고 되어 있는 부분이 바로 색인입니다. 인덱스도 인덱스에서 내가 원하는 데이터를 먼저 찾고 저장되어 있는 물리적 주소로 찾아갑니다.
왜 사용하나요? (장점)
테이블에 데이터들이 인덱스의 가장 큰 특징은 데이터들이 정렬이 되어 조건 검색이라는 영역에서 장점이 있습니다. 즉, DB 데이터의 주소를 가지고 있어 원하는 데이터를 빠르게 찾을 수 있습니다.
- 조건 검색 Where 절의 효율성
where절에 특정 조건에 맞는 데이터들을 찾아낼때도 레코드의 처음부터 끝까지 다 읽어서 검색 조건과 맞는지 비교해야 합니다. 이것을 풀 테이블 스캔 (Full Table Scan)이라고 합니다. 하지만 인덱스 테이블은 데이터들이 정렬되어 저장되어 있기 때문에 해당 조건 (Where)에 맞는 데이터들을 빠르게 찾아낼 수 있습니다.
이것이 인덱스(Index)를 사용하는 가장 큰 이유라고 할 수 있습니다. - 정렬 Order by절의 효율성
Order by에 의한 Sort과정을 피할수가 있습니다.
Order by는 굉장히 부하가 많이 걸리는 작업입니다. 정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생됩니다. 하지만 인덱스를 사용하면 이러한 전반적인 자원의 소모를 하지 않아도 됩니다. (이미 정렬이 되어 있기 때문에 가져오기만 하면 됨) - MIN, MAX의 효율적인 처리가 가능하다
데이터가 정렬되어 있어 MIN값과 MAX값을 레코드의 시작값과 끝 값 한건씩만 가져오면 되기에 FULL TABE SCAN으로 테이블을 다 뒤져서 작업하는 것보다 훨씬 효율적으로 찾을 수 있습니다.
단점
- 타 성능의 악영향을 줌
데이터 조회(SELECT)를 제외한 모든 동작,즉, INSERT / UPDATE / DELETE 성능에 영향을 미친다.
⇒ 데이터를 삽입하고 수정하고 삭제하는데, 사용하는 동작이나, 이로 인해 인덱스를 걸어둔 컬럼의 데이터가 수정되면 인덱스 테이블의 수정도 필요하게되어 데이터의 삽입/수정/삭제 작업이 두 번 이루어지게 됨 - 추가 저장공간 필요
DB에 저장된 데이터의 주소를 인덱스의 Key 값으로 가지려면 별도의 공간에 저장하므로 추가 저장 공간이 필요합니다.
⇒ 인덱스를 사용하는 시스템을 설계할 때, 인덱스 영역을 전체 테이블 영역의 30-50% 까지 잡아놓을 만큼 추가 저장공간이 필수적이라고 할 수 있습니다.
사용하는 자료구조
1) B-Tree
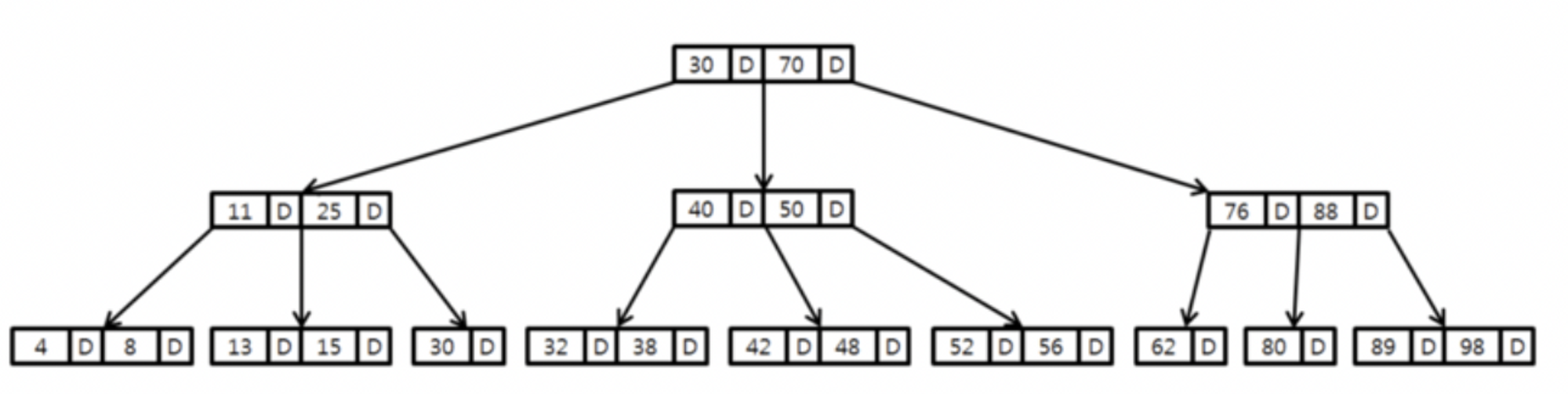
특징)
- Binary Serch Tree를 확장한 트리구조
- 각 노드는 여러개의 Key를 가질 수 있고, 여러개의 child를 가질 수 있음
- 각 노드에는 여러개의 Key를 가지며 각 Key에 대응하는 Data도 함께 가지고 있음
- 모든 Leaf 노드는 동일한 Depth를 가지고 있음
— 루트를 제외한 모든 노드의 자료수는 LIMIT/2개 여야 하며, 자식 노드의 수는 (부모 노드의 자료수 + 1)개 여야 하는 특징이 있습니다.
위 그림은 3 Order B-Tree이며 각 노드는 최대 2개의 키를 가질 수 있고, 최대 3개의 Child를 가질 수 있습니다.
→ 삽입, 삭제시에도 트리 균형을 유지할 수 있음
→ 균등한 탐색속도
→ 트리의 균형을 유지하기 휘해 복잡한 연산 + 중위 순회방식을 사용해 순회 탐색이 비효율적
2) B+Tree
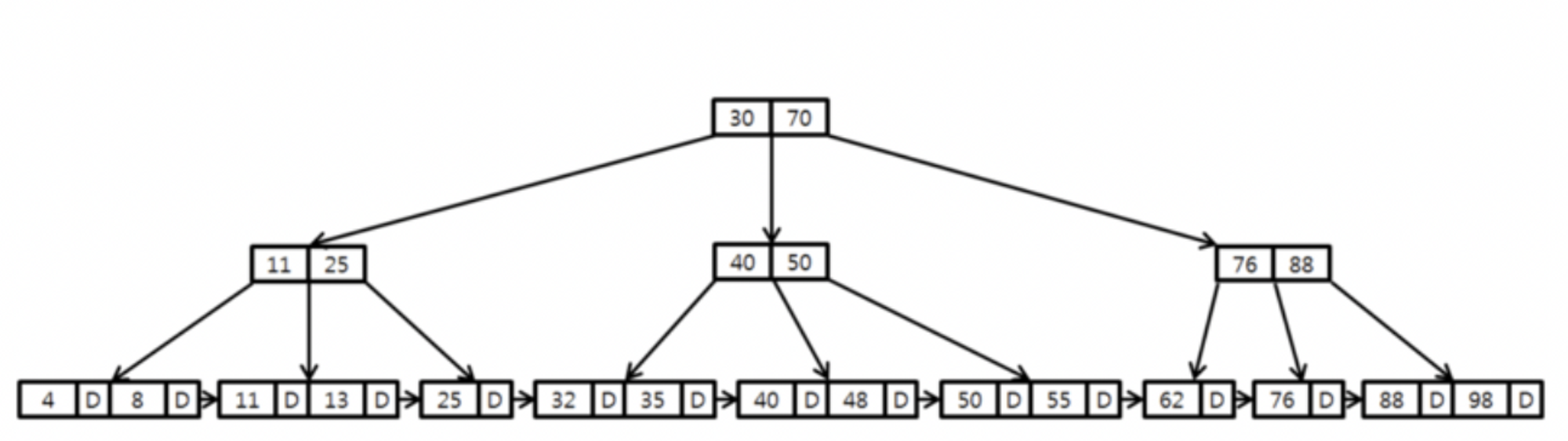
특징)
-
B-Tree를 개량한 트리구조
-
B-Tree처럼 모든 Leaf Node는 동일한 Depth를 갖습니다.
-
B-Tree와의 가장 큰 차이점은 Inner Node에는 Key만 저장이 되고 Leaf Node에 Key 와 Data를함께 저장한다는 점 입니다.
-
Inner Node는 Data가 없기 때문에 B-Tree의 Inner Node에 비해 용량이 작습니다.
→ 하나의 Disk Block에 더 많은 Inner Node를 배치할 수 있게 되어 Key 탐색시 B-Tree에 비하여 상대적으로 적은 Disk Block만 읽어도 됩니다. -
Leaf Node에만 Data가 저장되기 때문에 Leaf Node간의 Pointer를 연결하여 B-Tree에 비하여 쉬운 순회가 가능합니다.
-
위 그림은 4 Order B+ Tree를 나타내고 있습니다.
InnerNode는 최대 2개의 Key를 가질 수 있고, Leaf Node는 최대 3개의 Key/Value를 가질 수 있습니다.
참고
