고양이 vs 강아지 2
이번 시간에는 전처리한 이미지들을 바탕으로 실제 고양이와 강아지를 구분해주는 AI 모델을 제작해보겠다.
그럼 일단 저번 시간에 만들어준 폴더에 넣은 데이터셋의 구조와 값들이 올바르게 들어가 있는지 점검하겠다.
#for i, 정답 in train_ds.take(1):
#print(i)
#print(정답)
plt.imshow(i[0].numpy().astype('uint8'))
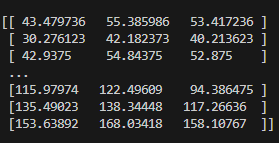
plt.show()train_ds.take(1)은 데이터셋에서 하나의 배치를 가져오는데, 출력된 하나의 배치 i 를 바탕으로 해당 이미지의 데이터가 정상적으로 나오고 있는지 알 수 있다.
이런 식으로 이미지의 데이터가 출력된다.
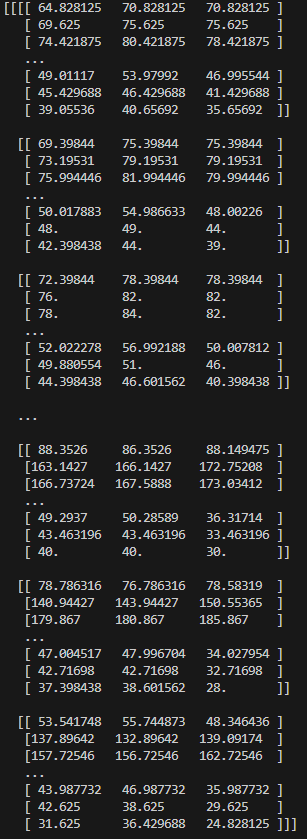
print(정답)의 경우, 
이런 식으로 출력이 되는데, 강아지 사진일 경우 1, 고양이 사진일 경우 0을 출력한다.
따라서 [0]을 출력해보면,
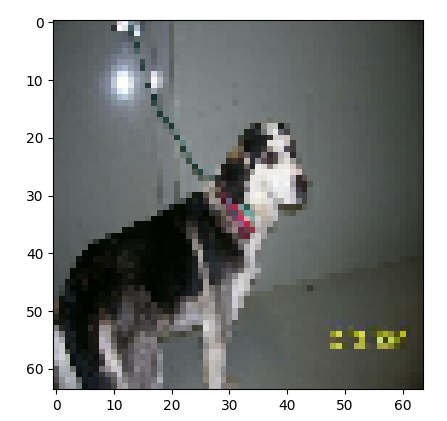
강아지 사진이 나오고,
[6]을 출력해보면,
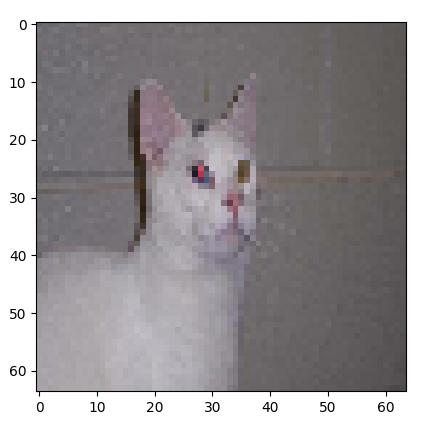
고양이 사진이 나온다.
이제 모델을 제작해 볼 건데, 전에 만들었었던 의류 이미지 구분 모델의 코드를 가져와서 이번 모델에 맞게 변형해보겠다.
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32,(3,3), padding="same", activation='relu', input_shape=(64,64,3)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64,(3,3), padding="same", activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(128,(3,3), padding="same", activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(1,activation="sigmoid"),
])일단 저번 모델에는 imput_shape를 (28,28,1) 로 지정했었는데, 이번 시간에는 (64,64,3) 으로 지정했다.
저번 시간에는 28X28 픽셀의 흑백 사진의 이미지로 모델을 학습시켰기에 28,28 그리고 단일 RGB 1이 들어갔지만, 이번 시간에는 64X64 픽셀에 색상 사진이므로 3을 넣어주었다.
또한 모델의 정확도를 향상시켜주기 위해서 컨볼루셔널 레이어와 풀링 레이어를 세 겹으로 넣어주었다.
이 때, 세 개의 컨볼루셔널 레이어와 풀링 레이어 사이의 있는
tf.keras.layers.Dropout(0.2)이 함수는, 저번 시간에 얘기했었던 overfitting을 완화해주는 장치이다. 이 함수는 일부 뉴런의 출력을 임의로 0으로 만드는데, 따라서 학습 데이터에 익숙해져 있던 모델을 과도하게 의존하지 않도록 재정비해준다.
다음으로, 마지막 레이어에 시그모이드 활성화 함수를 써줬는데, 이 모델은 강아지 or 고양이 하나의 분류만 하기에 시그모이드를 써주었다.
model.compile( loss= "binary_crossentropy", optimizer = "adam", metrics=['accuracy'])
model.summary()
model.fit(train_ds,validation_data=val_ds,epochs=5) 컴파일에서는 loss function을 binary_crossentropy를 써주었는데, 이는 이진 분류 모델에서 오차를 줄여주는 함수이다. 이 손실 함수는 출력층이 시그모이드 함수일 때만 사용한다.
이제 모델을 실행해보겠다.
먼저, dropout을 사용하지 않고 실행하면, 
이런식으로 77%의 정확도로 나오게 된다.
그럼 이제 dropout을 사용하고 실행해보자.

확실히 overfitting이 되지 않도록 처리했더니 정확도는 조금 내려간 모습이다.
하지만 정확도가 왜 이렇게 낮을까? - 그 이유는 전처리에 있다.
다음 시간에는 전처리 과정과 정확도를 향상시키는 방법에 대해 포스팅하겠다.
