고양이 vs 강아지 3
이번 시간에는 저번 시간에 정확도가 낮았던 이유와, 해결하는 방법에 대해 포스팅하겠다.
일단, 저번 시간에 정확도가 낮았던 이유는 전처리에 있다고 했다.
전처리를 완벽히 하지 않은 상태로 모델을 학습시켰을 때, 이미지 데이터 값인 0~255는 딥러닝 모델이 학습하기에 비교적으로 비대한 숫자라 불안정하게 학습이 된다. 또한, 기울기 소실이나 폭주 등의 문제가 생겨 학습이 비효율적이게 된다.
더해서, overfitting이 일어나기 더 쉬울 수 있다.
그러면 이미지 데이터를 어떻게 압축시킬 수 있을까?
그냥 255.0으로 나누어주면 된다.
먼저, 데이터를 255.0으로 나누어주는 메소드를 정의하겠다.
def 전처리함수(i, 정답):
i = tf.cast(i/255.0, tf.float32)
return i, 정답tf.cast()는 텐서의 자료형을 변환해주는데, 이 경우에는 i값을 255.0으로 나누고 float형태로 변환해준다.
이제 map()을 사용할건데, map()은 데이터셋에 함수를 적용해주는 메소드이다.
train_ds = train_ds.map(전처리함수)
val_ds = val_ds.map(전처리함수)이렇게 함수를 적용해주면 학습 데이터셋과 평가 데이터셋의 이미지 정보들이 0~1 사이로 압축된다.
이제 저번 시간에 했던 것처럼 데이터 값들을 출력해보면,
for i, 정답 in train_ds.take(1):
print(i)
print(정답)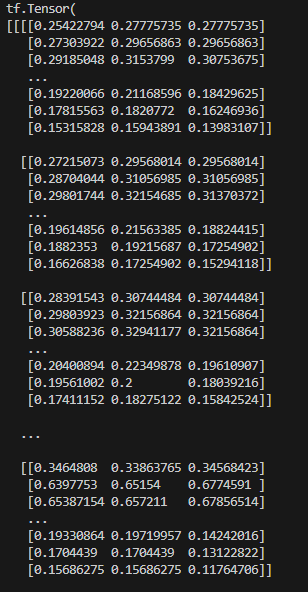
이미지 데이터들이 0과 1사이의 값으로 압축된다.
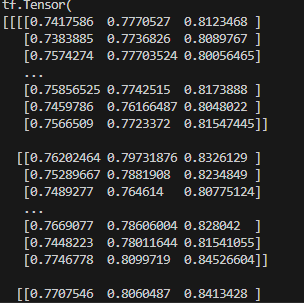
(압축된 평가 데이터셋)
이제 모델을 실행해보자.

일단 첫번째 epoch에서, 저번 시간에는 그냥 찍어서 맞히는 수준인 50%대가 나왔던 반면 72%로 많이 향상됐고, 5번째 epoch 또한 10%가량 향상된 걸 알 수 있다.
다음 시간에는 학습한 모델을 파일로 저장하는 법에 대해 공부해보겠다.
