Part-2 DNN
Neural Net
- 2겹 레이어 XOR 문제 해결
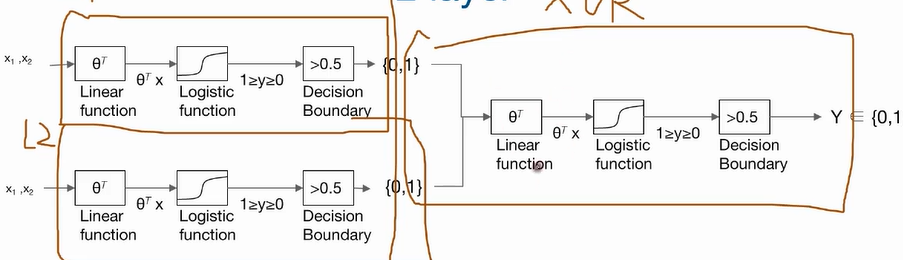
코드
def neural_net(features):
layer1 = tf.sigmoid(tf.matmul(features,W1 + b1) # W1=[2,1] b1=[1]
layer2 = tf.sigmoid(tf.matmul(features,W2 + b2) # W2=[2,1] b2=[1]
hypothesis = tf.sigmoid(tf.concat([layer1,layer2],-1),W3) +b3) #W3=[2,1] b3=[3]
return hypothesis- 2겹 레이어를 벡터화로 하나화
def neural_net(features):
layer = tf.sigmoid(tf.matmul(features,W1) + b1) # W1=[2,1] b1=[1]
hypothesis = tf.sigmoid(tf.concat(layer,W2)+b2) # W2=[2,1] b2=[1]
return hypothesis시그모이드 함수 문제점
input -> network -> output (ground_truth - output=loss)
(d(loss)=gradient)
여러 시그모이드 함수가 있는데, 매우 작은 gradient 값이 곱해지면서 gradient 가 소실 됨.
Relu
f(x)= max(0,x) # 0보다 작은 값은 0 (gradient가 아얘 전달되지 않음)

뫗팅