Azure 스토리지 서비스
개요
Azure 스토리지는 비정형, 반정형, 정형 데이터 유형의 저장소이자
빅데이터 분석에 필요한 최신 데이터 저장소 시나리오를 지원하는 솔루션이다.
Azure 스토리지가 지원하는 시나리오는 총 4가지로 분류할 수 있다.
- 가상 컴퓨터의 디스크와 공유 폴더용 스토리지
- 비정형 데이터(Blob 데이터)용 스토리지
- 정형 데이터(구조화된 데이터)용 스토리지
- 반정형 데이터(반 구조화된 데이터)용 스토리지
각 스토리지 서비스(컨테이너(Blob)와 파일 공유(Azure Files), 큐, 테이블 서비스)는 모두 HTTP/HTTPS 를 통해 어디서나 액세스 할 수 있다. 따라서, 각 서비스마다 고유한 엔드포인트(액세스 URL) 를 제공한다.
| 서비스 명 | 엔드포인트 |
|---|---|
| Blob 서비스 (컨테이너) | http://<스토리지 계정 이름>.blob.core.windows.net/ |
| 파일 서비스 | http://<스토리지 계정 이름>.file.core.windows.net/ |
| 큐 서비스 | http://<스토리지 계정 이름>.queue.core.windows.net/ |
| 테이블 서비스 | http://<스토리지 계정 이름>.table.core.windows.net/ |
Azure 스토리지 계정
Azure 스토리지 서비스는 스토리지 계정을 통해 관리한다.
즉, 스토리지 계정이 Azure 스토리지 서비스의 최상위 네임스페이스이며
하위의 스토리지 서비스들을 사용할 수 있도록 인증과 권한을 부여하는 기반이 된다.
액세스 키와 연결 문자열
스토리지 계정을 만들 때 스토리지 계정 액세스 키와 연결 문자열이 만들어진다.
-
액세스 키
저장소 계정의 루트 암호와도 같아서 저장소 전체에 강력한 권한을 가진다.
평문으로 저장하거나 코드 내 직접 포함하지 않아야 한다. -
연결 문자열
애플리케이션 실행 중에 스토리지 계정의 데이터를 액세스하는 데 필요한 인증 정보를 제공한다.
Azure Blob Storage (컨테이너 서비스)
Azure 스토리지 서비스 중 (컨테이너(Blob)와 파일 공유(Azure Files), 큐, 테이블 서비스), Azure Blob Storage (컨테이너 서비스) 에 대해 알아보자.
Azure Blob Storage 는 구조화되지 않은 대량의 비정형 데이터를 저장하기 위한 개체 스토리지 솔루션이다.
논리적인 컨테이너를 만들어 Blob 데이터를 저장하는 방식이다.
컨테이너(Blob) 서비스에서 폴더라는 개념은 없다. 폴더는 사용 편의를 위한 가상의 단위이기 때문에 파일이나 폴더 모두 평면적으로 동일한 수준이다.
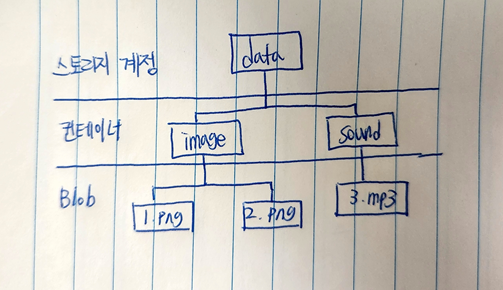
컨테이너
다수의 Blob을 그룹화 하는 논리적인 개념이다.
공용 액세스 수준
컨테이너를 생성할 때 '공용 액세스 수준'을 설정하게 된다. 이를 통해 컨테이너와 Blob에 대한 익명 공용 읽기 액세스를 지정하거나 익명 액세스를 차단할 수 있다.
여기서 주의할 점은 컨테이너 수준에서 공용 액세스를 지정하더라도 스토리지 계정에서 Blob 익명 액세스 허용이 '사용'으로 설정되어 있지 않으면 익명 액세스를 할 수 없다.
-
프라이빗(익명 액세스 없음) ~ 기본값
익명 액세스를 제공하지 않으므로 Blob을 요청할 때는 권한이 필요하다. -
Blob(Blob에 대한 익명 읽기 전용 액세스)
인증 절차없이 Blob 데이터를 읽을 수 있다.
하지만, 컨테이너의 Blob 목록을 나열할 수는 없다. -
컨테이너(컨테이너와 Blob에 대한 익명 읽기 액세스)
Blob 데이터와 컨테이너의 Blob 목록을 읽을 수 있다.
하지만, 컨테이너의 권한 설정과 컨테이너 메타데이터는 액세스 할 수 없다.
Blob 데이터 관리
Blob 은 3가지 유형(블록 Blob, 페이지 Blob, 추가 Blob) 이 있으며, 만들고 나면 변경할 수 없다. 그 중 블록 Blob 에 대한 세부 내용은 아래와 같다.
- 블록 Blob
- 텍스트나 이진 데이터 저장에 적합하다.
- 데이터 블록이 관리 단위이다.
- 블록 Blob 에 대해서만 핫, 쿨, 콜드, 아카이브 액세스 계층 중에서 선택할 수 있다.
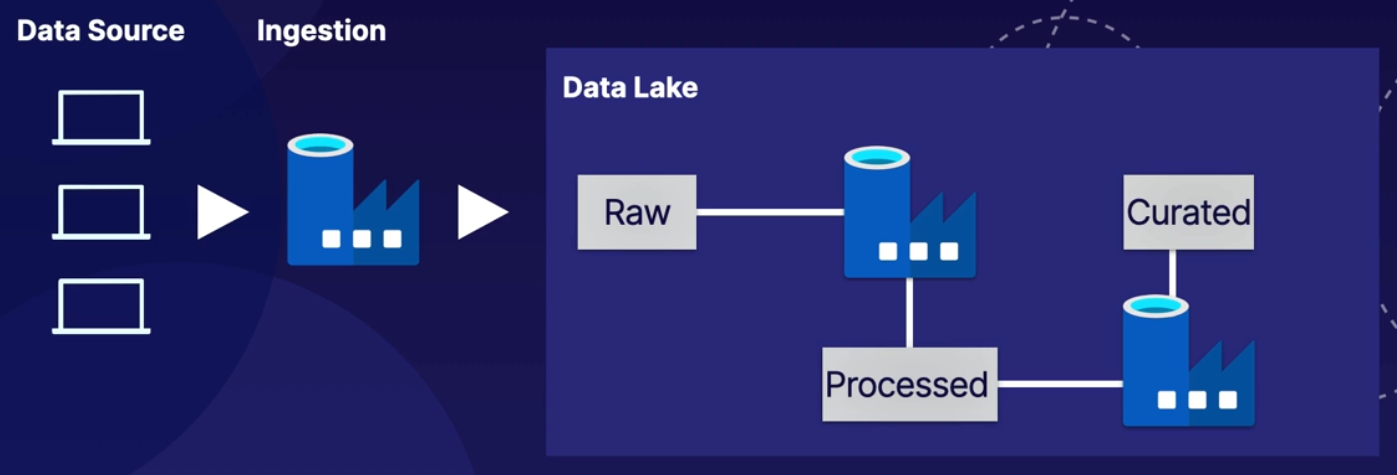
Azure Data Lake Storage Gen2
Data Lake Storage는 Azure Blob Storage를 기반으로 하는 빅 데이터 분석 전용 기능 세트이다.
Azure Data Lake Storage Gen2는 비정형 데이터 스토리지 및 처리를 위한 플랫폼으로, Azure Blob Storage에서 계층형 네임스페이스를 활성화하면 ADLS Gen2가 생성됩니다.
- Azure Data Lake Storage(ADLS) Gen2 combines the benefits of Azure Blob Storage and ADLS Gen1.
- ADLS Gen2 is a great choice for analytic workloads(분석 작업) or when a human-readable hierarchy(사람이 읽을 수 있는 계층) is needed.
- It is recommended that you turn on a firewall and only allow access from other Azure Services.

Azure Blob Storage 와 비교
-
데이터 레이크를 구분하는 주요한 요소는 '계층형 네임스페이스(hierarchical namespace)의 사용/활성화'이다.
-
Blob 스토리지를 생성할 때 '계층형 네임스페이스를 켜면' 데이터 레이크를 생성할 수 있다.
- 계층형 네임스페이스를 활성화하면 나중에 다시 비활성화 할 수 없다.
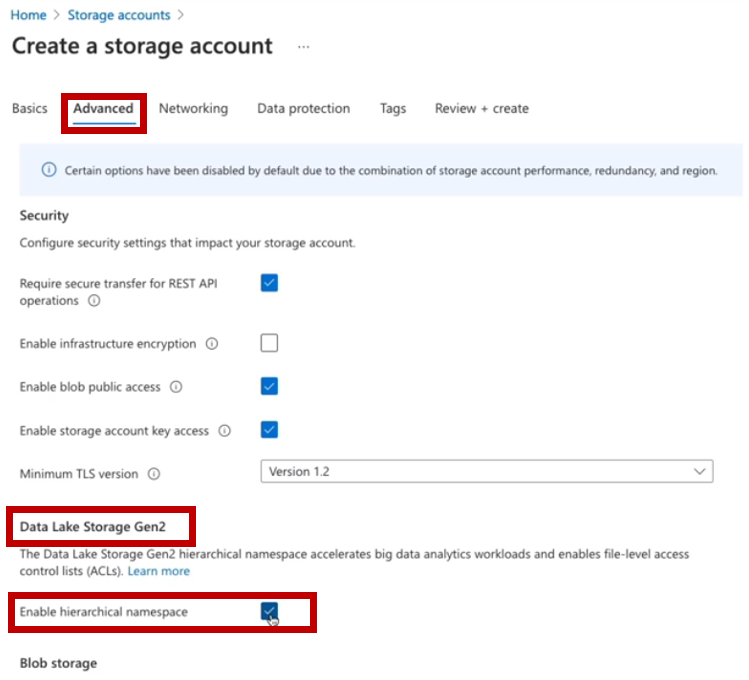
- 계층형 네임스페이스를 활성화하면 나중에 다시 비활성화 할 수 없다.
-
계층적 네임스페이스를 사용하는 이유 즉, 데이터 레이크를 사용/활성화하려는 주요한 이유는 다음과 같이 정리할 수 있다.
- 파일이 구조화되어 처리 시간을 줄일 수 있다.
- 파일 시스템은 친숙하고 쉽게 사용할 수 있다.
- 폴더별, 파일별로 액세스 제어(Access Control)와 ACL을 관리할 수 있다.
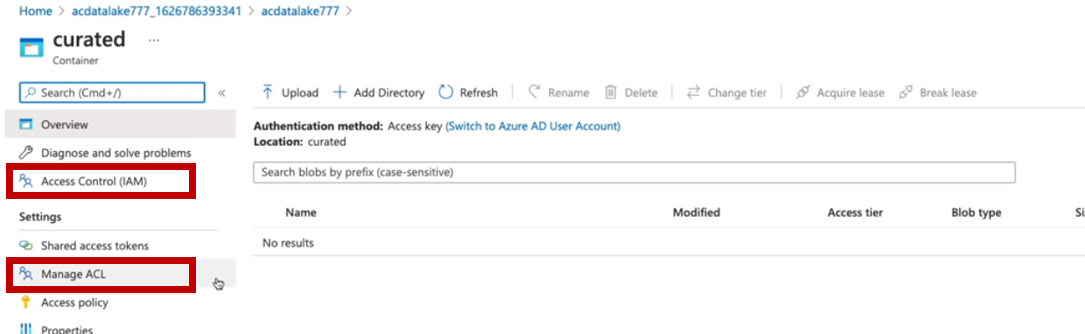
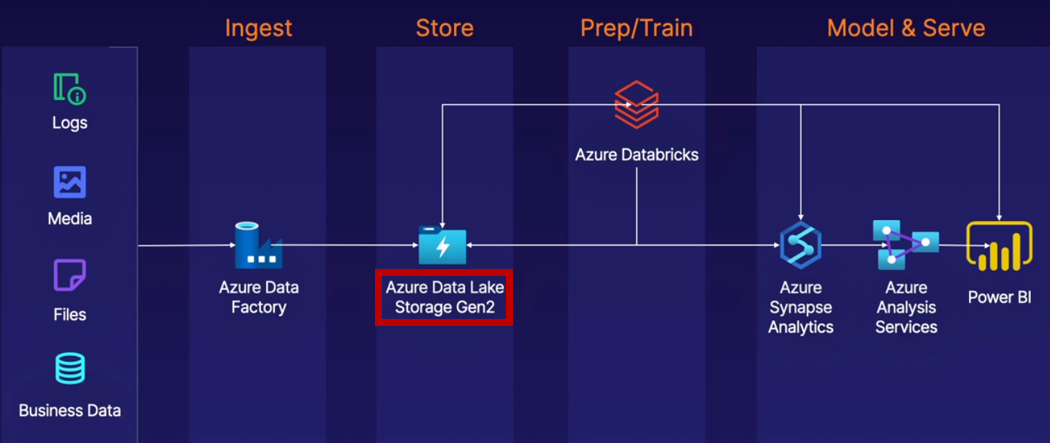
기본 아키텍처
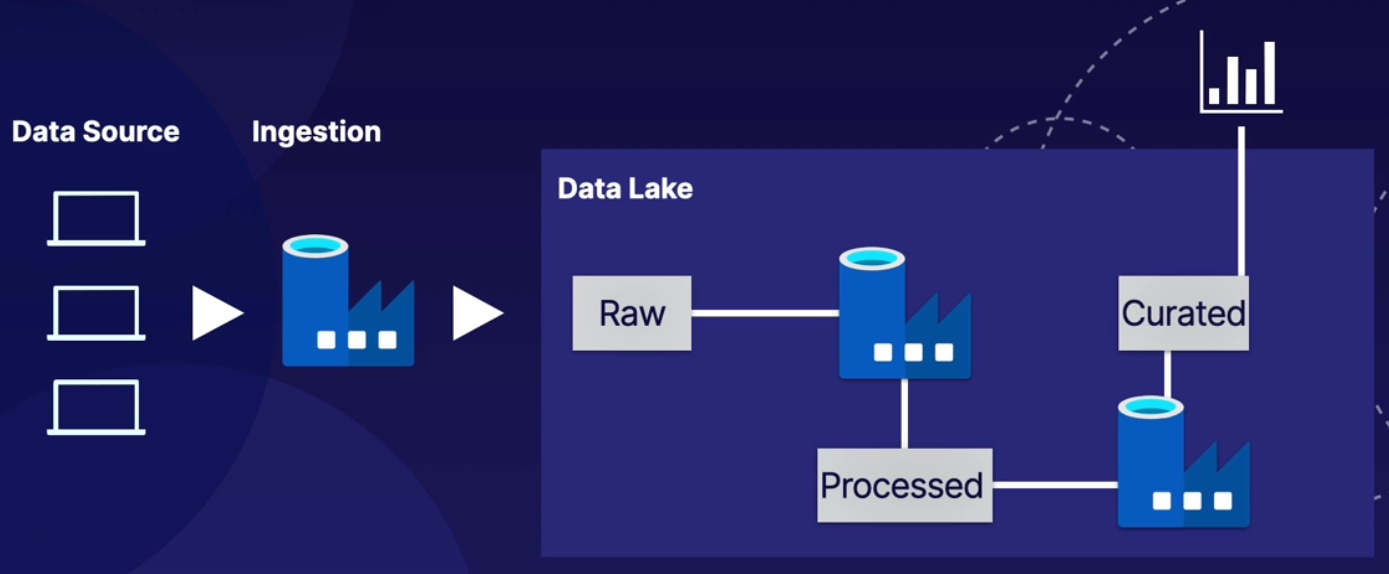
ADLS Gen2 and the Modern DW
ADLS Gen2에서 데이터를 추출하고 Databricks로 전송하여 준비하고 훈련시킬 수 있다. 그런 다음 Synapse로 보낼 수 있다. 또는 Synapse가 ADLS Gen2에서 직접 데이터를 추출할 수도 있다.
이처럼 어떤 서비스를 추가하더라도, 이 모든 것이 Azure Data Lake를 중심 허브로서 데이터에 연결되어 있다.