Azure
1.[DP-203] Data Engineering on Microsoft Azure

Azure Data Factory, Azure Blob & Azure Data Lake Storage Gen2, Azure Synapse Analytics & Azure Databricks & Azure Stream Analytics
2.[DP-203] Azure Blob Storage, ADLS Gen2 개요
Azure Blob Storage는 일반적인 목적의 객체 저장소이다. Azure Data Lake Storage는 Blob Storage의 일부이다. Blob Storage를 생성할 때 '계층형 네임스페이스를 켜면' ADLS를 생성할 수 있다.
3.[DP-203] Azure Data Factory 개요

Azure Data Factory는 orchestrate and automate data movement and transformation 을 할 수 있는 워크플로우를 클라우드에서 생성할 수 있게 해주는 서비스로 데이터를 연결하고 흐름을 제어하는 역할도 한다.
4.[DP-203] Azure Synapse Analytics 개요

Azure Synapse Analytics는 SQL Data Warehouse, Data Lake, Data Factory와 같은 서비스들을 가져와 처음부터 끝까지 전체 데이터 엔지니어링 경험을 실제로 수행할 수 있게 해주는 통합 서비스다.
5.[DP-203] Azure Stream Analytics 개요
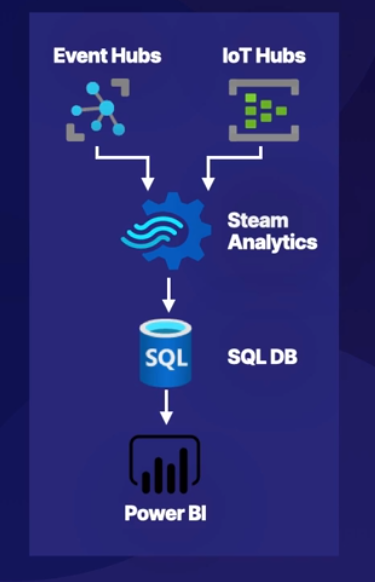
Azure Stream Analytics는 'Stream Process'로 주요 개념으로는 Input, Query, Output 이 있다. 'Stream Process'에서는 Windowing이 중요하다.
6.[DP-203] Azure Databricks 개요
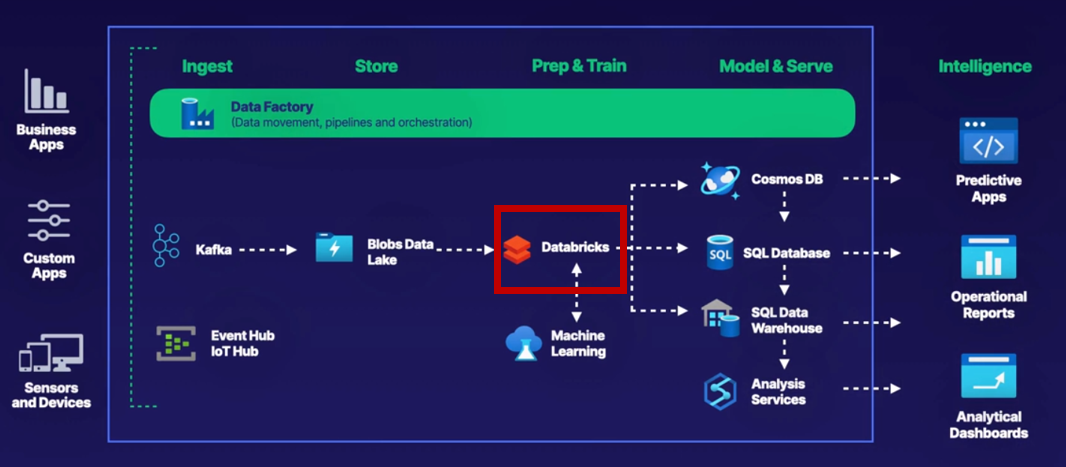
Azure Databricks 는 대규모 데이터를 정제하고 처리하기 위한 Transformation(변환) 계층으로서의 역할을 한다.
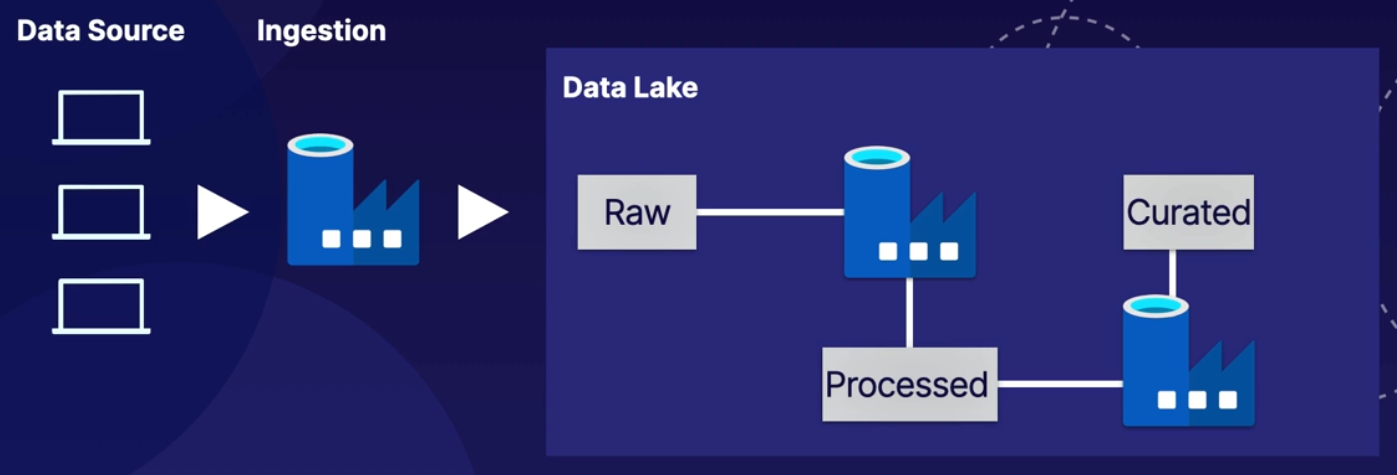
7.[DP-203] Data Storage : 기본 개념 (1)

데이터 웨어하우스, 데이터 레이크 그리고 데이터 마트의 차이점 / Data Lake Zone과 Folder Structure 전략 / 데이터 레이크에서 사용되는 주요 파일 포맷 (Avro, Parquet, ORC)
8.[DP-203] Data Storage : 기본 개념 (2) : Partitioning
하나의 테이블을 여러 물리적인 파티션으로 나눔으로써 파티션 단위로 데이터를 정리하여 데이터를 쓰거나 삭제할 수 있도록 하는 파티셔닝이 중요한 이유와 2가지 파티셔닝 옵션 (vertical, functional) 에 대해 알아보자.
9.[DP-203] Data Storage : Partitioning in Azure Data Lake
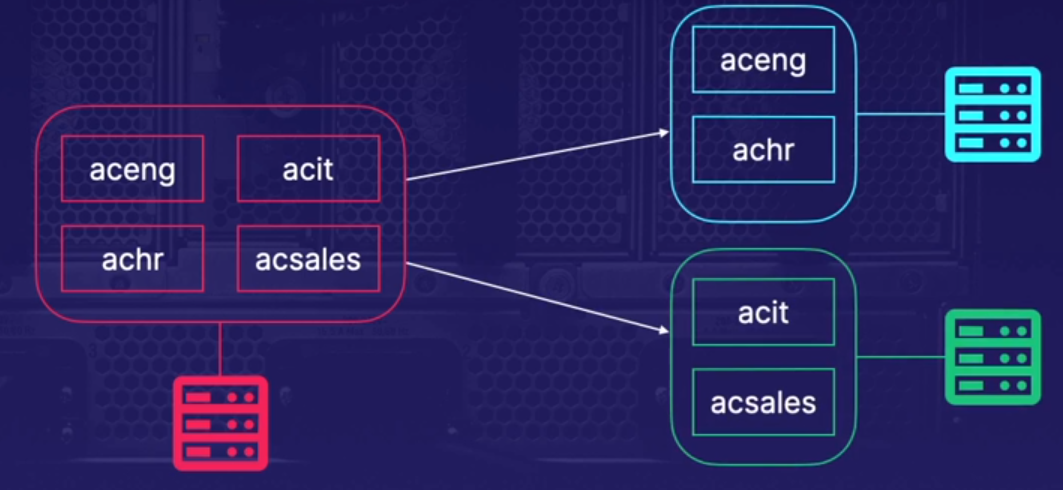
Azure Data Lake 에서 좋은 파티션을 구성하는 방법에 대해 알아보자. 파티션 키는 account, container, blob 의 이름을 포함한다. 그리고 데이터는 범위(range)로 분할되며 이는 storage system 전체에 로드 밸런싱된다.
10.[DP-203] Data Storage : Partitioning in Azure Synapse
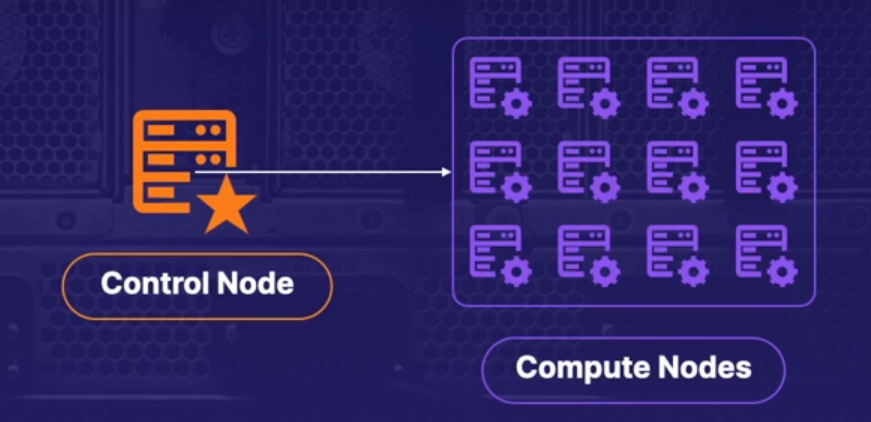
Azure Synapse 에서 좋은 파티션을 구성하는 방법에 대해 알아보자. Azure Synapse 는 대규모 병렬 처리 시스템으로 이미 60개의 Distributions이 포함되어 있다는 것을 고려하여 파티션을 설계해야 한다.
11.[DP-203] Data Storage : Data Distributions in Azure Synapse
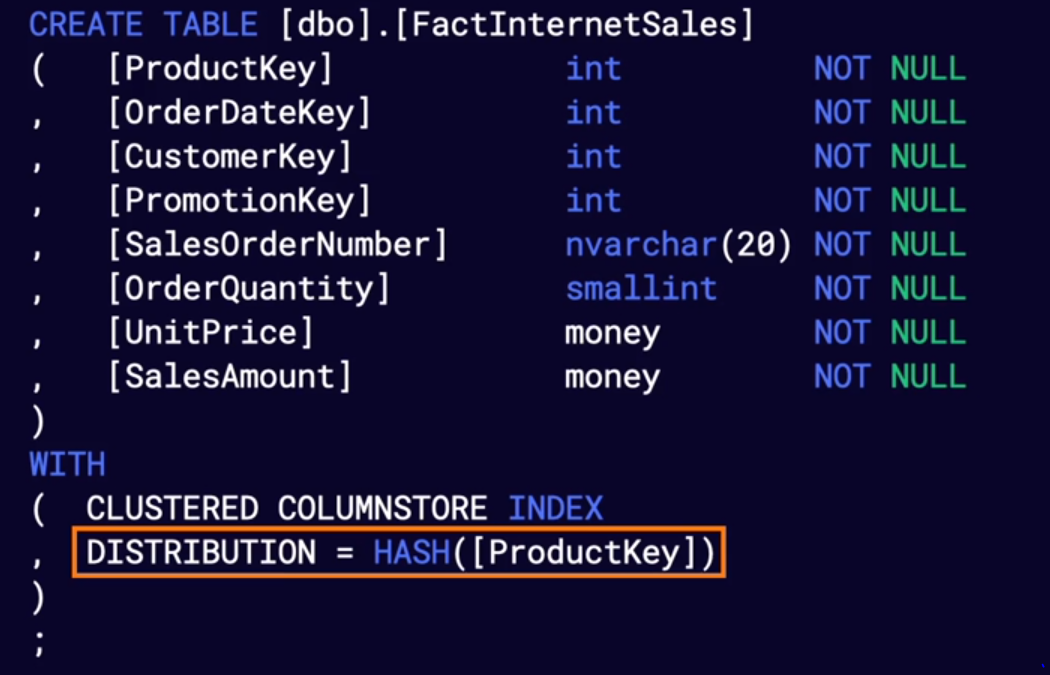
Distributions 는 하드웨어 저장 개념으로 더 많이 생각될 수 있다. Distributions 의 목표는 데이터 이동을 최소화하는 방식으로 데이터를 분배하는 것이다. 이러한 데이터 분배 유형으로는 Round Robin, Hash, Replicated 가 있다.
12.[DP-203] Data Storage : Archiving Data in Azure Blob Storage
Azure Blob Storage 에는 3가지의 Access Tier(HOT, COOL, ARCHIVE)가 있다. Account 레벨에서는 HOT과 COOL만, Blob 레벨에서 ARCHIVE 레벨을 선택할 수 있다.
13.[DP-203] Data Storage : Data Pruning in Delta Lake on Databricks

Data Pruning은 데이터를 검색하거나 쿼리할 때 불필요한 데이터를 효과적으로 건너뛰어 성능을 향상시키는 기술이다. Data skipping은 Data Pruning을 가능하게 하는 메커니즘 중 하나이다.
14.[DP-203] Data Storage : Compressing Data in Azure SQL Database

행 저장 객체와 열 저장 객체에 대한 압축 옵션에는 Row 압축, Page 압축, Columnstore 압축, Columnstore Archival 압축이 있다. 파티셔닝된 인덱스와 테이블의 경우, 각 파티션에 다른 압축 유형을 혼합하여 사용할 수 있다.
15.[DP-203] Data Storage : 기본 개념 (3) : Sharding
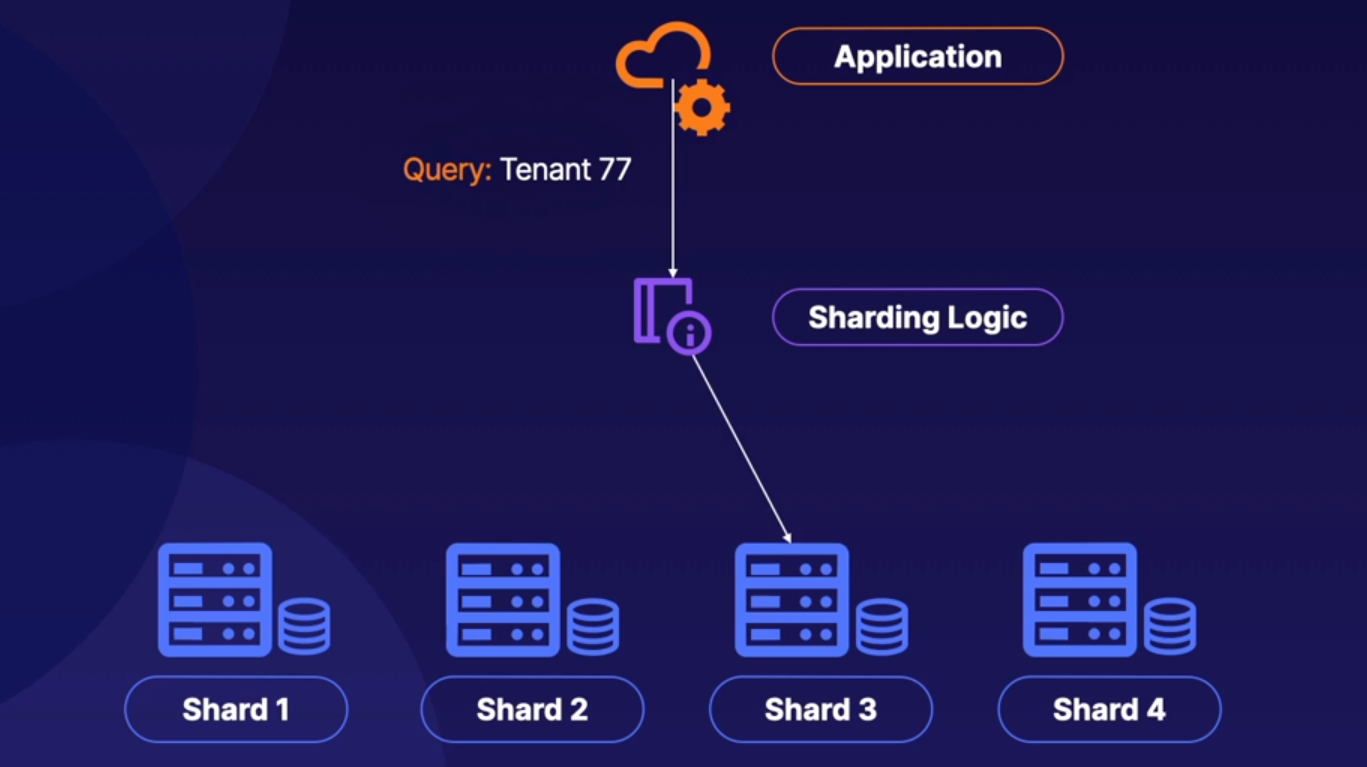
샤딩은 데이터를 여러 컴퓨터에 분산시키는 것이므로 파티셔닝과 다르다. 샤딩과 파티셔닝의 차이에 대해 알아보고 샤딩의 3가지 전략인 Lookup 전략, Range 전략, Hash 전략에 대해 알아보자!
16.Azure 가상 네트워크 연결 서비스
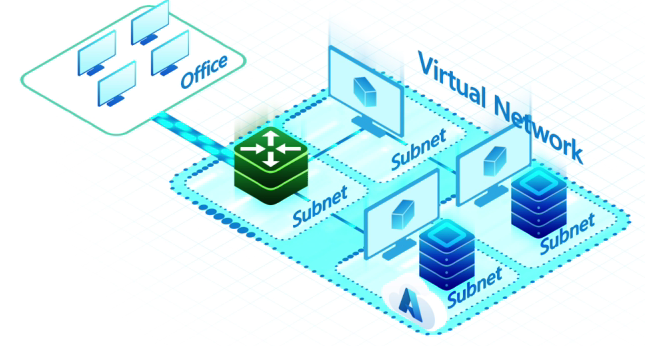
Azure 내에 구축한 소프트웨어들이 공용 인터넷을 거치지 않고 Azure 내에서만 통신하도록 가상 네트워크를 구현해야 한다. Azure는 여러 가지 가상 네트워크 연결 서비스를 제공하며, 그 중 가상 네트워크 피어링과 가상 네트워크 게이트웨이에 대해 알아보자.
17.[DP-203] Data Storage : Data Redundancy
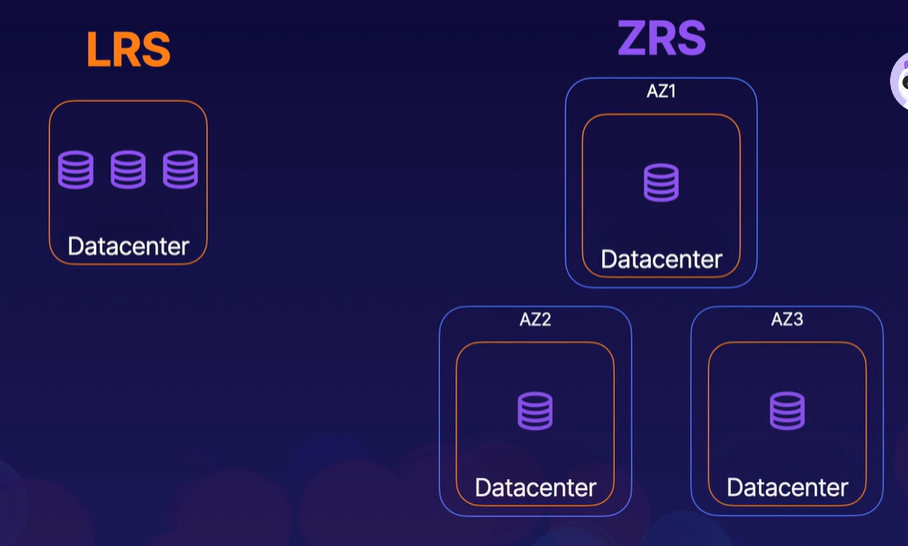
데이터 중복성(Data Redundancy)과 그 옵션에 대한 설명으로 데이터 엔지니어링을 다루는 부분뿐만 아니라 일반적으로 Azure Storage 에 내장되어 있다.
18.[DP-203] Data Storage : 전체 리뷰

Azure Data Lake Storage Gen2 allows scalable, flexiblem and highly available storage for a variety of data format. Distribution, partitioning, ...
19.[DP-203] Data Ingestion and Transformation : 목차

앞으로 정리할 Data Ingestion and Transformation 관련 서비스들 목록
20.[DP-203] Data Ingestion and Transformation : Azure Data Factory

Azure Data Factory, Azure Synapse Analytics, 그리고 Azure HDInsight / Azure Data Factory 주요 개념 / ADF 의 Data Movement 와 Transformation
21.[DP-203] Data Ingestion and Transformation : Transact-SQL

Microsoft SQL Server 에서 사용되는 SQL의 확장 버전이다. 이는 표준 SQL 명령어를 포함하면서, 프로그래밍적 요소를 추가해 DB 내에서 보다 복잡한 작업을 수행할 수 있게 한다. 예를 들어, T-SQL은 변수, 조건문(if/else), 반복문(whi
22.[DP-203] Data Ingestion and Transformation : Azure Synapse Analytics - Pipelines

Azure Synapse Analytics in Azure Portal / ADF 와 Azure Synapse Analytics 각 서비스에서 사용할 수 있는 기능
23.[DP-203] Data Ingestion and Transformation : Apache Spark
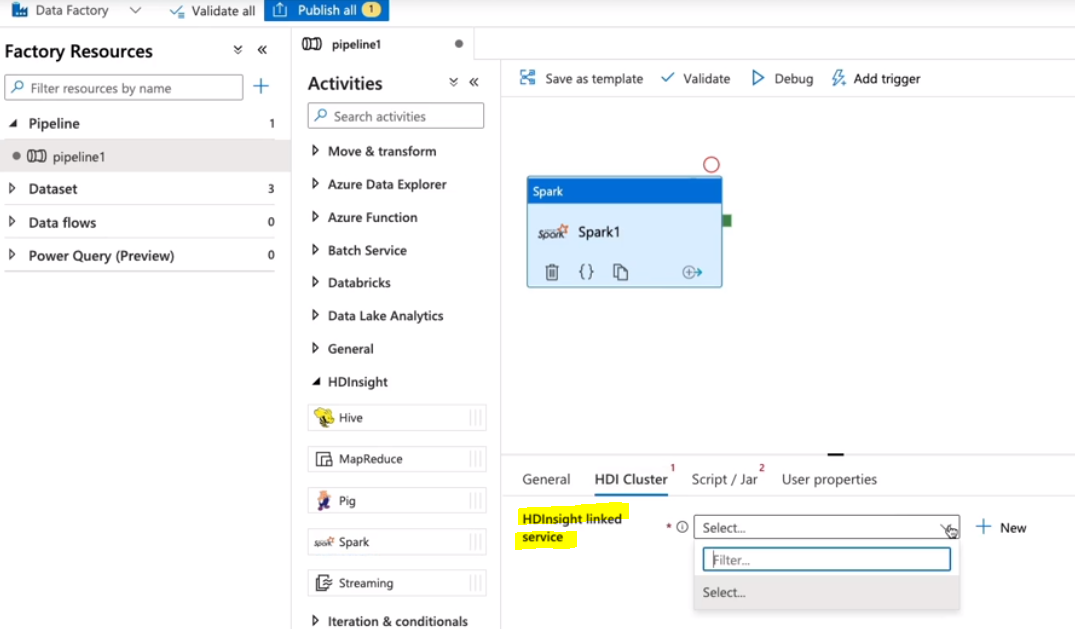
Spark는 빅데이터 처리 프레임워크로 대용량 데이터 처리에 적합한 오픈소스 분산 컴퓨팅 시스템이다. 스파크는 메모리 내 처리를 통해 빠른 데이터 처리 속도를 제공하고, 스칼라로 개발되었기 때문에 스칼라와의 호환성이 매우 뛰어나다.This activity execute
24.ADLS Gen2 및 Azure Synapse Analytics 소개
Azure 에서 데이터 엔지니어링 시작하기 : Azure Data Lake Storage Gen2 소개, Azure Synpase Analytics 소개
25.Azure Synapse Analytics의 서버리스 SQL 풀

Azure Synapse 서버리스 SQL 풀을 사용하여 데이터 레이트의 파일 쿼리/데이터 변환, Azure Synapse Analytics에서 레이크 데이터베이스 만들기, Azure Synapse 서버리스 SQL 풀에서 데이터 보안 및 사용자 관리
26.Azure Synapse Analytics에서 Apache Spark 사용하기
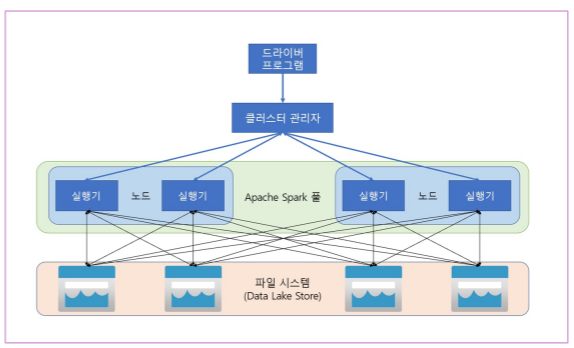
Spark는 분산 데이터 처리 프레임워크로 하둡과는 달리 메모리에서 작업이 이루어진다. Azure Synapse Analytics에서 Spark를 사용하여 여러 저장소의 데이터 작업이 가능하다.
27.Microsoft Graph API 개념과 기본 사용법
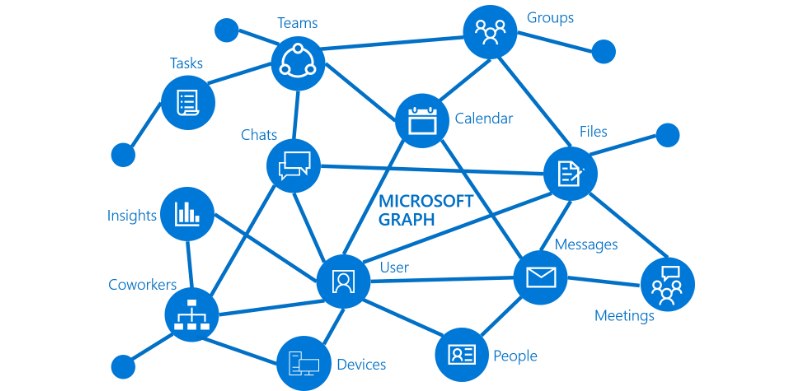
Microsoft Graph는 Microsoft 365 데이터에 액세스하는 데 사용되며, 그래프 데이터베이스 또는 GraphQL과 같은 다른 그래프 기술과는 관련이 없습니다.