Sharding, 샤딩
All for One and One for All
샤딩은 모두를 위한 노력이며, 동시에 각각을 위한 노력이다.
-
Multi-Computer Collaboration, 여러 컴퓨터가 협력하는 것
샤딩은 데이터를 여러 컴퓨터에 분산시키는 것이므로 파티셔닝과 다르다.모두 동일한 스키마를 가지고 있지만, 각각 고유 데이터 부분 집합 (own distinct subset of the data) 을 보유하고 있다.
-
반면, 파티셔닝은 단일 데이터베이스 인스턴스 내의 데이터 하위 집합을 그룹화한다.
파티셔닝 샤딩 적용 범위 단일 데이터베이스 여러 노드 또는 서버 간 목적 성능 최적화, 관리 용이성 시스템 확장성 향상 적용 대상 특정 테이블을 나누는 데 중점 여러 노드에 데이터를 분산하는 데 중점 샤딩과 파티셔닝 모두, 큰 데이터를 여러 서브셋으로 나누어 저장하는 기술을 말합니다.
하지만, 샤딩의 경우에는 각 서브셋을 여러 인스턴스에 저장하는 반면, 파티셔닝은 각 서브셋을 하나의 인스턴스의 여러 테이블에 나누어 저장하는 것을 말합니다.
출처: https://galid1.tistory.com/797 [배움이 즐거운 개발자:티스토리]
-
-
Horizontal Scaling
하나의 서버에 오직 일정량만 추가할 수 있기 때문에 수직적 확장만으로는 충분하지 않을 수 있다.
샤딩을 이용하면 노드나 샤드만을 추가하여 수평적 확장을 활용할 수 있다. -
고급스럽지만 비용이 낮다.
비싼 일체형 서버 대신, 일반 하드웨어를 사용할 수 있게 해준다. -
데이터를 가까이 두고(close) 사용할 수 있게(available) 해준다.
샤딩을 사용하면, 필요한 데이터를 사용자 또는 해당 데이터가 필요한 응용 프로그램에 가깝게 위치시킬 수 있다. 그리고 이를 여러 영역에 분산시켜 가용성을 높일 수 있다.
Sharding Strategies

1) Lookup Strategy (조회)
샤드 키를 기반으로 적절한 샤드로 요청을 라우팅하기 위해 맵(map) 을 사용한다.
쿼리를 올바른 샤드로 안내하기 위해 '맵' 을 사용한다.
- '맵'은 키와 값을 연결하는 데이터 구조로, 이 경우 샤드 키와 해당 샤드 키를 관리하는 샤드의 위치(예: 서버주소)를 매핑한다. 맵을 사용하면 특정 샤드 키에 대한 요청이 들어왔을 때, 맵에서 해당 샤드 키와 연결된 값을 조회하여 요청을 올바른 샤드로 라우팅 할 수 있다.
장점
Lookup Strategy 의 장점은 샤드가 어떻게 구성되고 접근되는지에 대해 더 많은 통제를 제공한다는 것이다.
예시 : 멀티 테넌트 애플리케이션 (multi-tenant application)
특정 테넌트의 모든 데이터를 하나의 샤드에 넣을 수 있다.
그런 다음 애플리케이션은 테넌트 ID 를 참조 (mapped by tenant ID) 하여 해당 샤드를 찾을 수 있다.
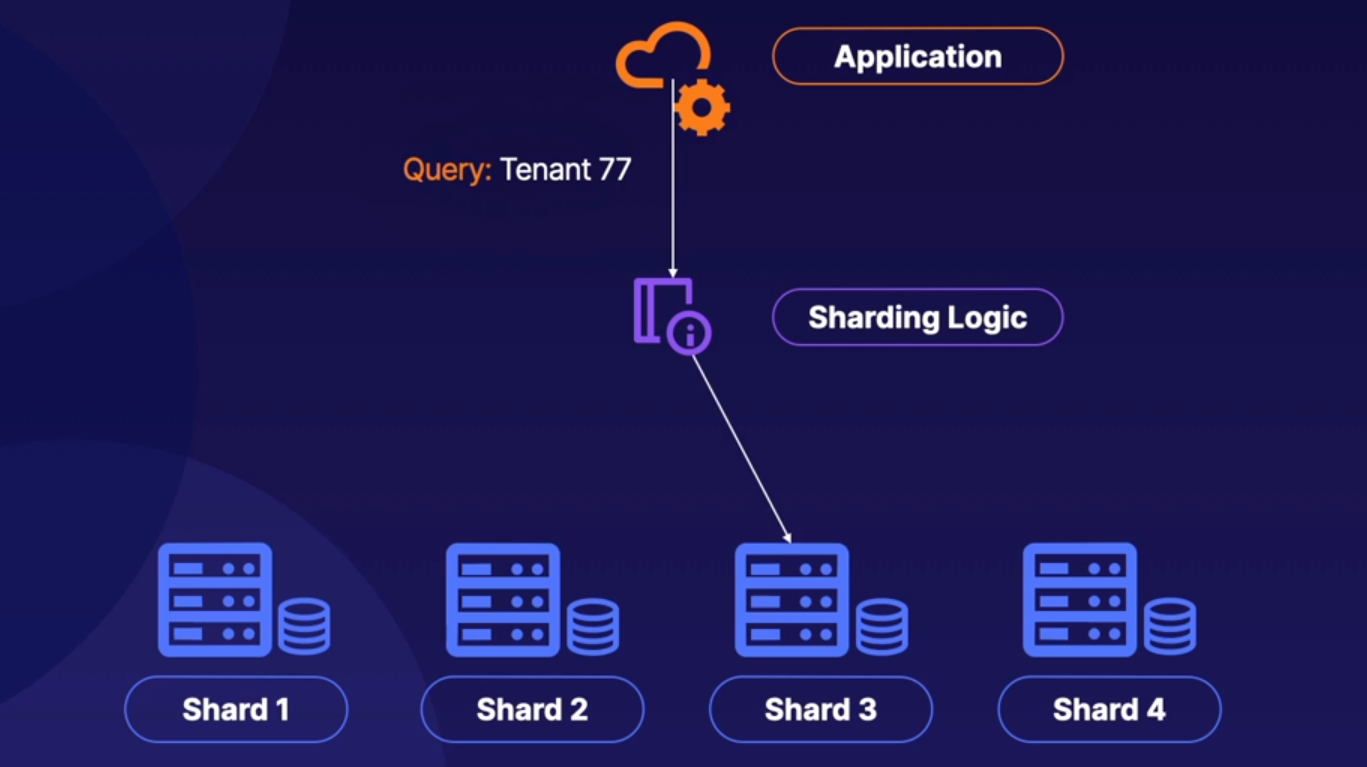
1) 4개의 샤드가 있다.
2) 애플리케이션은 '테넌트 77' 을 찾는 쿼리를 제출한다.
3) 샤딩 로직에는 '테넌트 77' 이 정확히 어느 샤드에 존재하는지 알려주는 맵이 있다.
2) Range Strategy (범위)
같은 샤드에 유사한 항목들을 모으고, 샤드 키에 따라 순차적으로 정렬한다.
관련 항목들을 샤드로 그룹화하고 샤드 키에 따라 순서를 매긴다.
장점
-
The Range Strategy 의 장점은 구현하고 관리하기 가장 쉽다는 것이다.
날짜 및 기타 범위로 데이터를 쉽게 나눌수 있기 때문에 범위가 사실상 스스로 생성된다는 것이다.
또한, 관리하고 작업하기가 더 쉽다. 예를 들어, 모든 사용자가 한 지역 즉, 동일한 샤드에 있을 경우 해당 지역의 시간대에 기반하여 쉽게 해당 샤드에 대한 유지보수를 예약할 수 있따.
-
범위 쿼리(range queries)와 잘 작동하며, 단일 샤드에서 여러 데이터 항목을 한 번의 작업으로 검색할 수 있습니다(can retrieve multiple data items from a single shard in a single operation).
예시 : 특정 달의 모든 주문을 빈번하게 가져오는 애플리케이션
모든 주문을 하나의 샤드에 함께 묶어 순차적으로 정렬해 두는 것이 유용하다. (all in one shard and ordered sequentially)
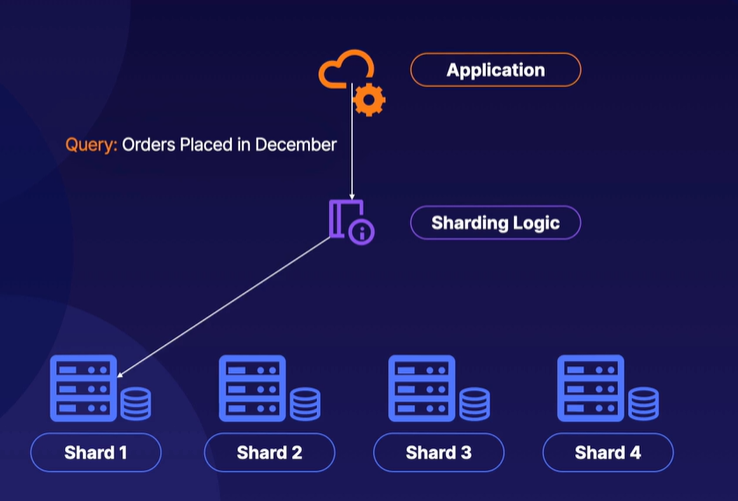
1) 애플리케이션이 12월 주문에 대한 쿼리를 제출
2) 샤딩 로직은 해당 범위의 주문을 포함하는 샤드를 알고 있으며, 직접 그곳을 가리킨다.
3) Hash Strategy (해시)
하나 이상의 속성(attributes) 이 해시 함수를 거쳐 항목이 배치될 샤드를 결정한다.
데이터의 하나 이상의 속성이 해싱 함수를 통해 아이템의 위치를 결정한다. 샤드의 크기와 각 샤드가 겪을 부하에 대해 모두 고려하여 샤드들 간에 균형을 이룰 수 있도록 데이터를 분산시키려고 시도한다.
장점
데이터와 부하(load)가 샤드 전체에 더 고르게 분배될 가능성이 높다.
예시 : 데이터를 테넌트 ID 별로 샤드들에 고르게 분산
노드 간의 크기와 부하 균형를 균형잡기 위해, 테넌트 ID의 해시를 사용하여 데이터를 고르게 분산
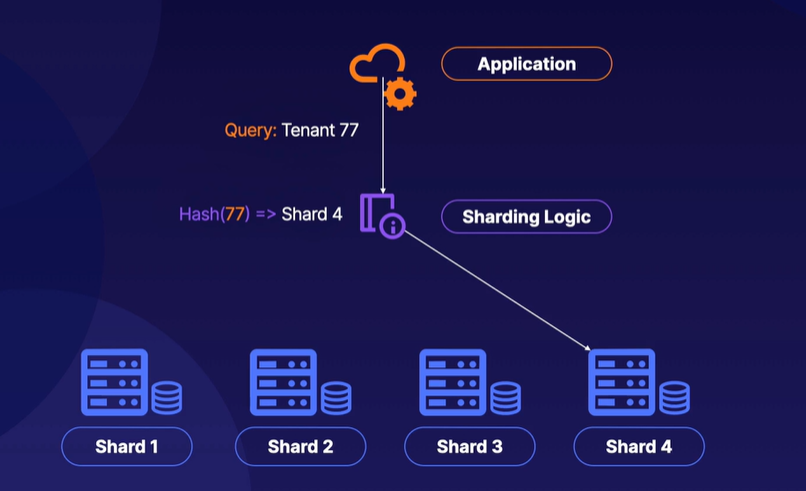
1) 애플리케이션이 테넌트 77에 대한 쿼리를 제출
2) 해싱 함수의 출력 값은 특정 샤드 (아래 이미지에서는 네번째 샤드)로 이동하도록 지시
고려사항
샤딩을 구현하기 위한 고려사항들은 아래와 같다.
-
Range 전략을 사용할 때, Range may not be the most balanced.
Range 전략을 사용할 때는 관계에 따라 그룹화하기 때문에 균등 분포가 아니므로 핫스팟을 생성하는 위험이 있다.
-
샤딩은 수직 및 기능적 파티셔닝과 같은 다른 형태의 데이터 분리를 보완한다.
-
안정적인 데이터를 샤드 키로 사용하는 것은 매우 중요하다.
-
어떤 샤드 키도 완벽하지 않다.
가장 빈번한 쿼리에서 가장 큰 이익을 얻으려고 노력해야 한다.
필요한 경우, 샤드 키의 일부가 아닌 속성에 기반한 기준을 사용하여 데이터를 검색하는 쿼리를 지원하기 위해 보조 인덱스 테이블을 만들어야 한다.
-
작은 샤드를 많이 가지는 것이 큰 샤드를 조금 가지는 것보다 종종 도움이 된다. 이를 통해 로드 밸런싱을 위한 기회가 증가한다.
-
일관성에 대한 기대를 적절히 조절해야 한다.
참조 무결성과 샤드 간 일관성을 유지하는 것은 정말 어렵다. 따라서, 실제 생활 범위 내에서 일관성에 대한 기대치를 계획하는 것이 중요하며, 여러 샤드에 영향을 미치는 작업을 최소화하려고 노력해야 한다.
Review
-
샤딩은 여러 컴퓨터에 걸쳐 데이터를 수평적으로 확장할 수 있게 해준다.
반면에 파티셔닝은 단일 데이터베이스 인스턴스 내의 데이터를 분리한다.
-
Lookup, Range, Hash 전략은 데이터를 샤딩하기 위한 옵션을 제공한다.
-
샤딩은 더 큰 성능(performance)뿐만 아니라 더 큰 가용성(availability)을 달성할 수 있게 해준다.
데이터를 여러 영역에 분산시키고, 애플리케이션과 사용자에게 더 가깝게 데이터를 위치시킬 수 있다.
