파티셔닝이란
대량의 데이터를 효율적으로 관리하고 쿼리 성능을 향상시키기 위한 데이터베이스 설계 기법 중 하나로 하나의 논리적인 테이블을 여러 개의 물리적인 테이블로 나누는 것이다.
대량의 데이터
데이터베이스가 많은 양의 데이터를 저장하고 있다면, 모든 인덱스를 한 번에 메모리에 로드하는 것은 많은 시간과 자원이 소요될 수 있다. 특히 메모리 크기가 제한적인 경우에는 전체 인덱스를 메모리에 유지하는 것이 어려울 수 있다.
파티셔닝의 역할
특정 기준에 따라 데이터를 파티션으로 나누면, 각 파티션은 작은 부분의 데이터를 관리하게 되어 효율적으로 메모리에 로드할 수 있다. 데이터가 파티션으로 나뉘면, 각 파티션에 해당하는 작은 인덱스 파일을 유지할 수 있다. 이로써 필요한 쿼리에 대해 필요한 파티션만을 메모리에 로드하여 작업을 수행할 수 있다.
쿼리 성능 향상
특정 쿼리가 특정 파티션에만 집중될 수 있기 때문에 필요한 데이터만을 메모리에 올려 쿼리 성능이 향상된다. 불필요한 데이터를 로드하지 않아도 되므로 I/O 비용이 감소하고 빠른 응답을 얻을 수 있다.
파티셔닝이 중요한 이유
Partitioning imporves scalability, performace, security, availability and cost savings.
Improve ...
-
Scalability, 확장성
데이터가 증가함에 따라, 데이터를 더 사용하기 쉬운 덩어리로 분할할 수 있고 빠르게 접근할 수 있다. 하지만, 샤딩을 통해 여러 컴퓨터에 분산되는 것과는 다르다는 점을 주의해야 한다.파티셔닝과 샤딩
- 파티셔닝은 하나의 데이터베이스 시스템 내에서 이루어지며, 주로 쿼리 최적화와 데이터 관리를 목적으로 합니다. 논리적인 데이터 관리에 초점을 두고 있습니다.
- 샤딩은 여러 데이터베이스 서버에 걸쳐 데이터를 분산시키는 것으로, 시스템의 확장성과 병렬 처리 능력을 향상시키기 위해 사용됩니다. 물리적인 데이터 분산에 초점을 두고 있습니다.
-
Performance, 성능
-
Security, 보안
서로 다른 보안 요구사항을 가진 데이터를 다른 파티션에 배치할 수 있다. -
Availability, 가용성
데이터를 분산시키면 *Single Point Of Failure를 피할 수 있다.*SPOF, Single Point Of Failure
특정 지점이나 구성 요소가 문제가 생기면 전체 시스템의 가용성이 크게 영향을 받을 수 있는 상황
-
Cost Savings, 비용절약
더 저렴한 저장소에 우선 순위가 낮은 데이터를 배치하여 비용을 줄일 수 있다.
파티셔닝 옵션
There are 2 strategies for partitioning : vertical and functional
이 2가지는 모두 단일 데이터베이스 인스턴스를 취하여 데이터를 여러 개의 작업 가능한 조각으로 분할하는 방법이다.
차이점은 vertical은 사용 패턴에 의해, functional은 bounded context에 의해 데이터 분할이 수행된다는 것이다.
Vertical Partitioning
Distribute the data according to its pattern of use.
데이터의 사용 패턴에 따라 데이터를 분배
-
Partitions hold a subset of the fields
Fields are divided according to their pattern of use
파티션은 필드의 부분 집합을 보유하고 있으며, 필드들은 그것들의 사용 패턴에 따라 분할되어 있다.아래 이미지에서 볼 수 있는 것처럼, 'ID, 이름, 주제' 와 같은 가장 자주 사용되는 필드를 한 파티션에 두고, 그 다음으로 덜 사용되는 '시청 시간' 열을 다른 파티션에 두고 'ID' 로 매칭할 수 있다.
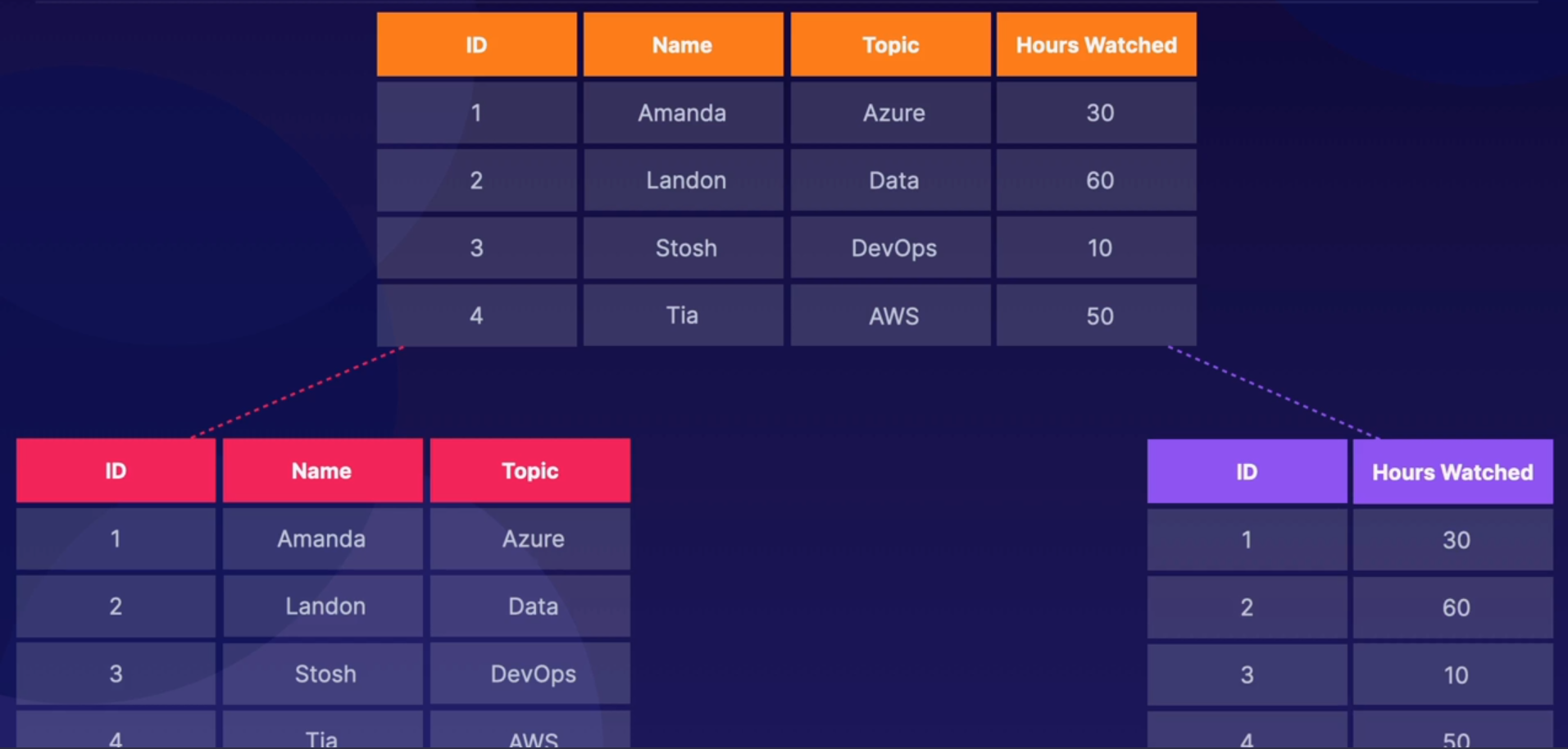
-
Seperate Static and Dynamic Data
Slow-moving data can be cached in memory by the application. -
Add Security to Data
Store sensitive data in a seperate partition with higer levels of security.
Functional Partitioning
Aggregate data by purpose within a bounded context.
경계가 정해진 맥락 내에서 목적에 따라 데이터를 집계
-
Aggregated by Use
Bounded contexts determine the partitions.아래 이미지에서 볼 수 있는 것처럼, 고객 정보 테이블과 이 고객들이 속한 회사 정보 테이블이 있다. 고객 정보 테이블을 하나의 파티션에 고객들이 속한 회사 정보 테이블을 다른 파티션에 두게 된다.
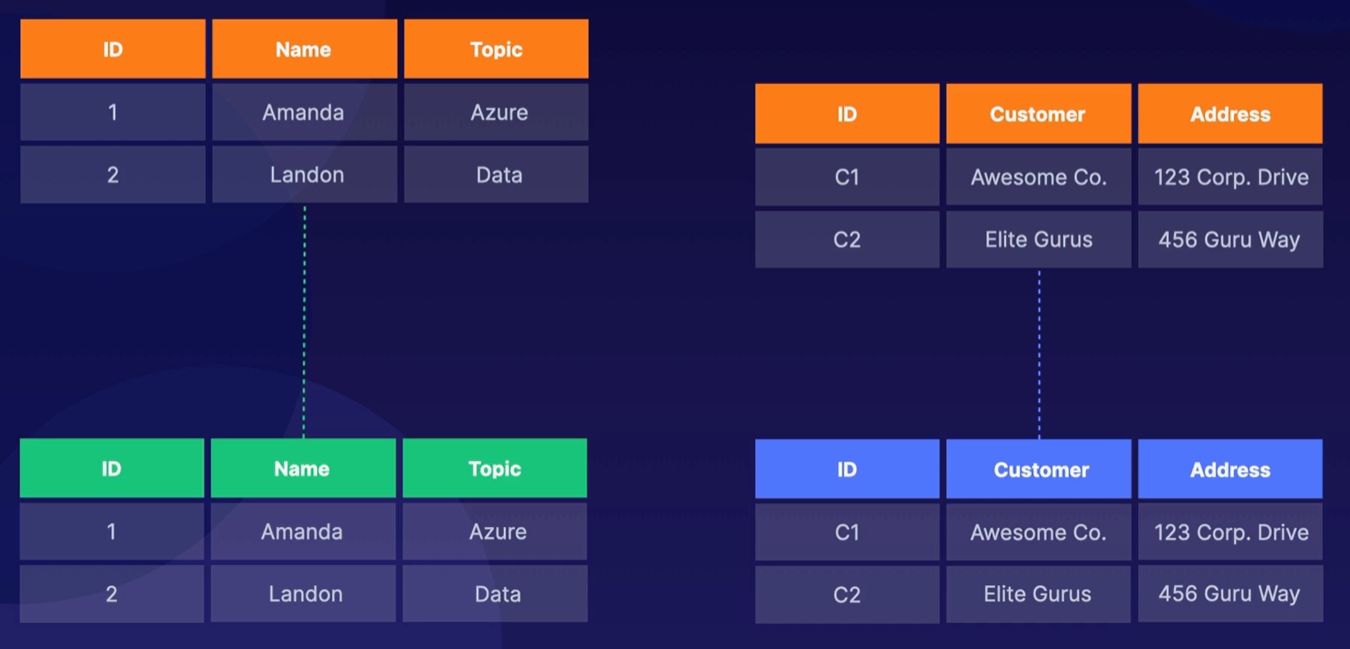
-
Seperate Workload Types
Read-only data can be placed in a serperate partition.
Partition decisions will depend on
the type of data you have, how you want to use it, and what the workload will be.
이것이 바로 어떤 파티션 전략이 가장 효과적인지 결정하는 요소이다.
