1. Apache Spark
1-1. Apache Spark
- 분산 데이터 처리 프레임워크
- 하둡과는 달리 메모리에서 작업이 이루어진다.
1-2. Azure Synapse Analytics에서 Spark
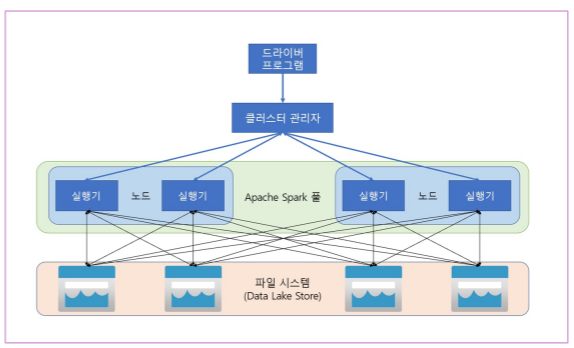
- Azure Synapse Analytics에서 Spark 를 사용하여 여러 저장소의 데이터 작업이 가능하다.
- 주 작업 영역 데이터 레이크
- 연결된 서비스 스토리지
- 전용 또는 서버리스 SQL 풀
- Azure SQL 또는 SQL Server 데이터베이스
- Azure Cosmos DB
- Azure Data Explorer Kusto 데이터베이스
- 외부 Hive 메타스토어
2. Spark와 Delta Lake
2-1. Spark를 이용한 데이터 변환
1) Load source data
Let's start by loading some historical sales order data into a dataframe.
order_details = spark.read.csv('/data/*.csv', header=True, inferSchema=True)
display(order_details.limit(5))2) Transform the data structure
The source data includes a CustomerName field, that contains the customer's first and last name. Let's modify the dataframe to separate this field into separate FirstName and LastName fields.
The code creates a new dataframe with the CustomerName field removed and two new FirstName and LastName fields.
# Use the full power of the Spark SQL library to transform the data
from pyspark.sql.functions import split, col
# Create new FirstName and LastName fields
transformed_df = order_details.withColumn(
"FirstName",
split(col("CustomerName"), " ").getItem(0)
).withColumn(
"LastName",
split(col("CustomerName"), " ").getItem(1)
)
# Remove the CustomerNmae field
transformed_df = transformed_df.drop("CustomerName")
display(transformed_df.limit(5))3) Save the transformed data
After making the required changes to the data, you can save the results in a supported file format.
Note :
ParquetformatCommonly,
Parquetformat is preferred for data files that you will use for further analysis or ingestion into an analytical store.Parquetis a very efficient format that is supported by most large scale data analytics systems. In fact, sometimes your data transformation requirement may simply be to convert data from another format (such as CSV) toParquet!
In the files tab, navigate to the root files container and verify that a new folder named transformed_data has been created, containing a file named orders.parquet. Then return to this notebook.
transformed_df.write.mode("overwrite").parquet('/transformed_data/orders.parquet')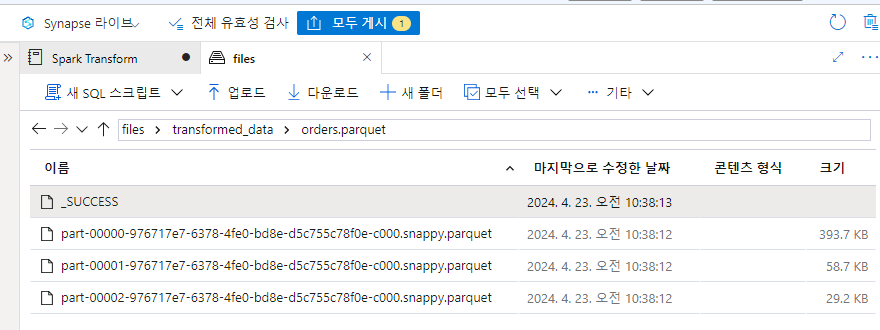
4) Partition data
A common way to optimize performance when dealing with large volumes of data is to partition the data files based on one or more field values. This can significant improve performance and make it easier to filter data.
Use the following cell to derive new Year and Month fields and then save the resulting data in Parquet format, partitioned by year and month.
from pyspark.sql.functions import year, monthm col
dated_df = transformed_df.withColumn(
"Year",
year(col("OrderDate"))
).withColumn(
"Month",
month(col("OrderDate"))
)
dated_df.write.partitionBy("Year","Month").mode("overwrite").parquet("/partitioned_data")In the files tab, navigate to the root files container and verify that a new folder named partitioned_data has been created, containing a hierachy of folders in the format Year=NNNN / Month=N, each containing a .parquet file for the orders placed in the corresponding year and month. Then return to this notebook.
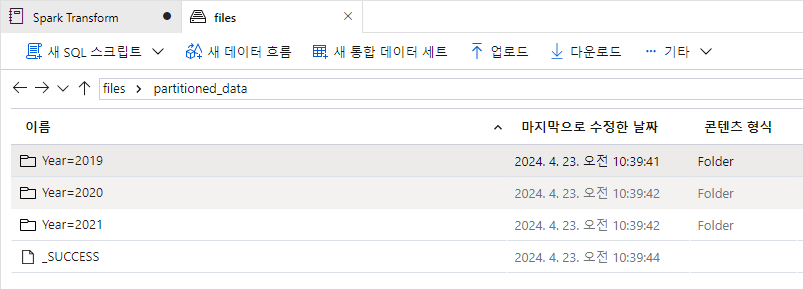

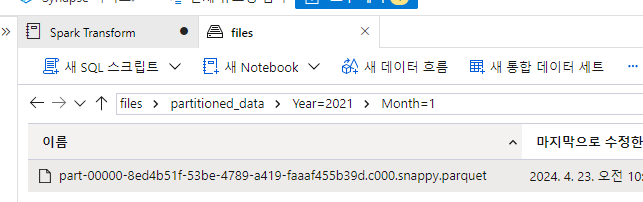
You can read this data into a dataframe from any folder in the hierarchy, using explicit values or wildcards for partitioning fields. For example, use the following code to get the sales orders placed in 2020 for all months.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020/Month=*')
display(orders_2020.limit(5))5) Use SQL in Spark to transform data
Spark is a very flexible platform, and the SQL library that provides the dataframe also enables you to work with data using SQL semantics. You can query and transform data in dataframes by using SQL queries, and persist the results as tables - which are metadata abstractions over files.
Save the original sales order data(loaded from CSV files).
order_details.write.saveAsTable('sales_orders', format='parquet', mode='overwrite', path='/sales_orders_table')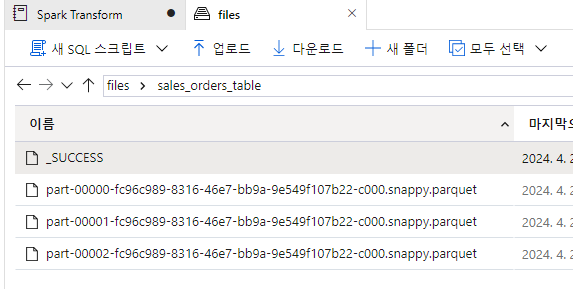
Technically, this is an external table because the path parameter is used to specify where the data files for the table are stored (an internal table is stored in the system storage for the Spark metastore and managed automatically).
In the files tab, navigate to the root files container and verify that a new folder named sales_orders_table has been created, containing parquet files for the table data.
Now that the table has been created, you can use SQL to transform it. For example, the following code derives new Year and Month columns and then saves the results as a partitioned external table.
sql_transform = spark.sql("SELECT *, YEAR(OrderDate) AS Year, MONTH(OrderDate) AS Month FROM sales_orders")
sql_transform.write.partitionBy("Year","Month").saveAsTable('transformed_orders', format='parquet', mode='overwrite', path='/transformed_orders_table')In the files tab, navigate to the root files container and verify that a new folder named transformed_orders_table has been created, containing a hierachy of folders in the format Year=NNNN / Month=N, each containing a .parquet file for the orders placed in the corresponding year and month.
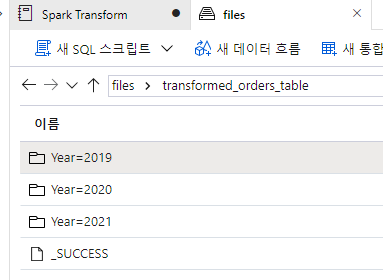
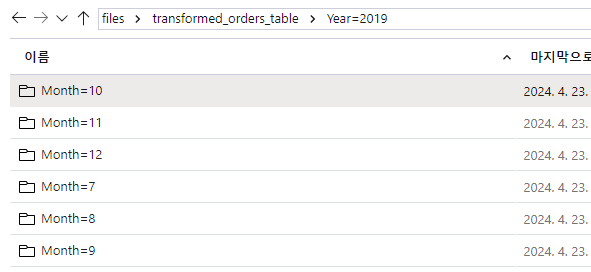
Essentially you've performed the same data transformation into partitioned parquet files as before, but by using SQL instead of native dataframe methods.
You can read this data into a dataframe from any folder in the hierarchy as before, but because the data files are also abstracted by a table in the metastore, you can query the data directly using SQL.
%%sql
SELECT * FROM transformed_orders
WHERE Year = 2021
AND Month = 1