이번에 가져온 논문은 정말 신기한 논문입니다.
기존 NLP TASK에서는 반드시 tokenization등의 과정이 필요했으나 이제는 해당 과정 없이도 좋은 성능을 낼 수 있습니다. 소개합니다! CANINE 입니다.
Abstract
"yet nearly all commonly-used models still require an explicit tokenization step.
In this paper, we present CANINE, a neural encoder that operates directly on character sequences --without explicit tokenization or vocabulary-- and a pre-training strategy that operates either directly on charcters or optionally uses subwords as a soft inductive bias."
아직까지 많은 모델은 별도의 토큰화 과정이 필요합니다. CANINE의 경우 해당 과정이 필요하지 않습니다.
이는 문자열을 바로 입력에 넣을 수 있는 encoder이자 character나 subword를 soft inductive bias(약한 귀납 편향)로 사용하는 사전훈련 전략입니다.
이 모델의 성능은 mBERT 보다 우세합니다.
1. Introduction
기존 방법은 선 토큰화, 후 임베딩이였습니다.
이는 문자 데이터를 어디를 기준으로 split할지 (토큰화를 수행하기 때문에), 이후 이들의 문맥적 의미를 얼마나 정확히 학습할지가 문제였습니다.
언어 현상의 전체 범위를 정확히 포착하기 위해 필요한 정교성의 정도는, 모든 언어와 도메인에 걸쳐 이러한 작업을 수작업으로 하는 것이 불가능함을 시사하였습니다.
즉, 토큰화의 한계가 LLM에서 명확하다는 것입니다.
이에 대비하여, 날것의 문자열을 바로 연산에 사용하는 end-to-end 모델은 해당 문제점을 해결할 수 있습니다.
그러나 이러한 변화는 다음의 문제점을 야기합니다.
- transformer의 연산량이 입력값의 길이에 대해 제곱배로 증가합니다.
- 문자 어휘로의 단순 전환은 실험적으로 좋지 않은 결과를 가져옵니다. 즉, 문제를 해결할 수는 있으나 이에 대한 성능은 좋지 않다는 것이죠.
그러나! CANINE은 이 문제점을 해결합니다.
CANINE은 코어에 deep transformer stack이 있는 LLE(large language encoder)입니다.
입력은 Unicode 문자열입니다. 이에 대해 우리는 Hash Embedding을 적용합니다.
seq length가 증가함에 따른 속도저하를 피하기 위해 CANINE은 transformer stak 이전에 strided conv를 사용해 입력 sequence의 길이가 줄어들도록 downsampling을 수행합니다.
CANINE은 Masked Language Model에서 Next Sentence Prediction Task를 통해 pre-training합니다.
MLM task에 대해서 CANINE은 2가지 옵션이 있습니다.
1. 마스크된 영역에서 문자를 자동으로 예측하는 fully character-level loss
2. 마스크된 subword token의 신원을 자동으로 예측하는 vocabulary-level loss
이때, 2번이 tokenization은 pre-training loss에서만 사용됩니다. 절대 입력값에서 사용되지 않습니다. (이 부분은 후에 더 다뤄봅니다.)
본 논문은 다음을 기여합니다.
• 첫 번째 사전 훈련된 토큰화 없는 딥 인코더;
• 바닐라 BERT와 유사한 속도로 긴 문자 시퀀스를 직접 인코딩하는 효율적인 모델 아키텍처;
• 입력에 대한 토큰화를 수행하지 않고, 대부분의 전처리와 관련된 정보의 손실이 발생하는 병목 현상을 피하는 모델.
2. Motivation
2.1 Linguistic pitfalls of tokenization
Subword Tokenization은 사실상 modern NLP의 표준입니다.
이는 단순한 word-splitting operations에만 제한되어 있습니다.
해당 operation는 영어와 같은 improverished morphology(단순 형태론적)언어에서는 적절하나
agglutinative morphology(융착 형태론적), nonconcatenative morphology(비엽전 형태론적), consonant mutation (자음 변화), vowel harmony(모음 조화) 언어에서는 그다지 적절하지 않습니다.
때문에 모든 언어에서 subword tokenization이 효율적인 것이 아닙니다.
영어처럼 resource가 풍부한 corpus에서도 subword 토큰화는 informal text 등 어려운 문제들에 여전히 직면해 있습니다. (BERT도 해당 문제에 직면)
subword 토큰화는 언어마다 구조, 특징, 문법이 다르기에 보편적으로 적용 가능한 메소드가 아닙니다.
끝으로, 사전훈련 과정에서 고정된 어휘를 사용하는 것은 downstream task에서 complications를 만들어냅니다.
2.2 Enabling better generalization
과학적 탐구 관점에서, 우리는 적절한 경우에 단어를 구성하는 방법을 학습하고, 필요한 경우에는 기억하는 모델을 구축할 수 있는지 알고 싶어합니다.
언어는 본질적으로 기억과 구성의 측면을 모두 요구합니다. 실제로, 매우 빈번하지 않은 약간의 철자 변형을 갖는 어휘 요소들의 경우에는 일반화가 방해됩니다.
가설적으로, 모델은 흔한 어휘 요소 "kitten"에 대한 매우 좋은 임베딩을 추정할 수 있지만, 모델이 그들이 관련되어 있다는 사전 지식이 없기 때문에 드문 어휘 요소 "kittens"에 대한 부정확한 임베딩을 추정할 수 있습니다.
2.3 Reducing engineering effort
완전한 tokenizaer는 종종 이메일 주소, URL, unkown words 등 특별한 경우에 대한 몇년에 걸친 hand-engineered rules를 가지고 있다.
Modern pre-trained model 또한 그들의 lifecycle 전반에 대해 많은 requirements를 가지고 있다.
3. CANINE
본 모델은 다음과 같은 세 가지의 주요 구성요소를 가지고 있습니다.
1. 텍스트를 임베딩하는 데 사용되는 어휘 무관 기술;
2. 다운샘플링 및 업샘플링을 통해 효율적인 문자 수준 모델;
3. 문자 수준 모델에서 마스크된 언어 모델링을 수행하는 효과적인 방법.
3.1 Model
CANINE은 deep transformer stack based model끼리 쉽게 implement가 가능하다.
가장 간단한 implementation은 subword들의 각 위치에 character를 넣어주는 것이다.
그러나 이 방법은 동일한 입력 텍스트를 사용할 때 시퀸스 위치가 훨씬 더 많아져, 순방향 레이어 (Feed Forward Layer)에서는 선형적으로 더 많은 계산이 발생하고, self-Attention layer에서는 제곱배나 더 많은 계산이 발생할 것으로 예상된다.
CANINE 모델의 각 구조는 downsampling function DOWN, primary encoder ENCODE, upsampling function UP으로 구성되어있다.
길이가 n이고 차원이 d인 문자 임베딩 e ∈ R^(n×d)의 입력 시퀀스가 주어졌다고 가정한다.
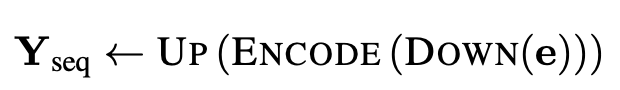
위는 CANINE의 구조를 수식화한 것이다.
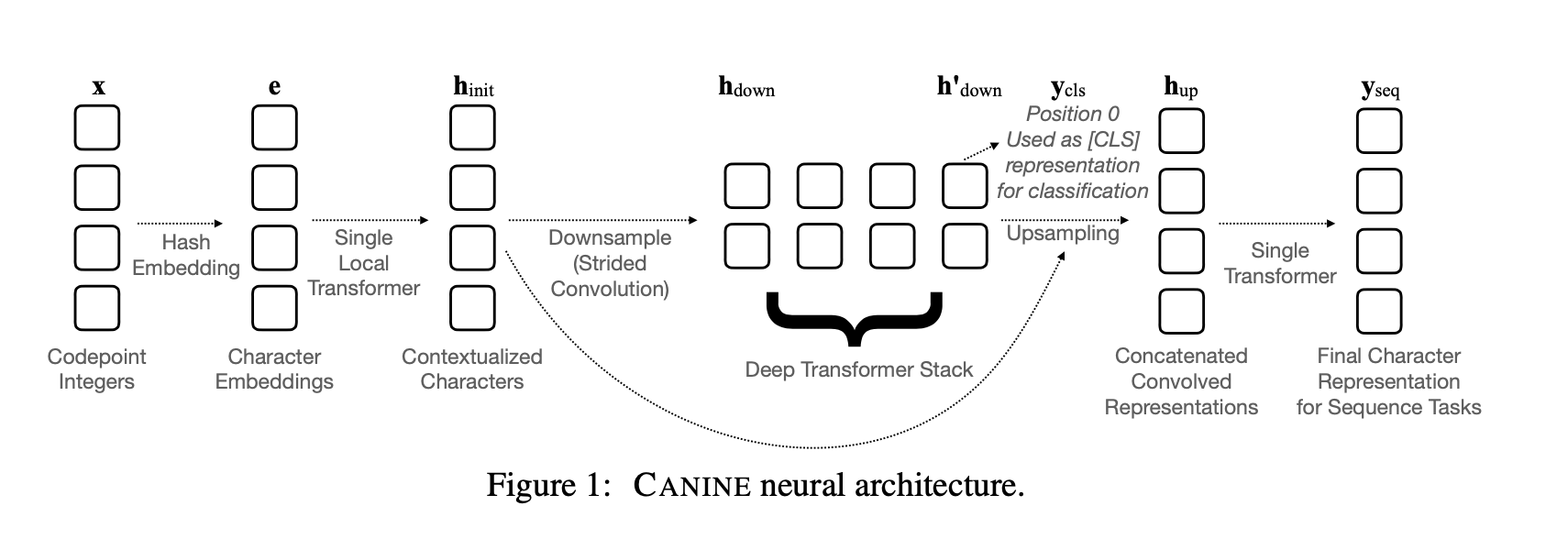
위 그림은 신경망 구조로 CANINE을 설명하였다.
Y_seq는 sequence prediction task의 최종 representation이다.
유사하게 classification task에 대해, 모델은 단순히 primary encoder의 0번째 요소를 사용한다.
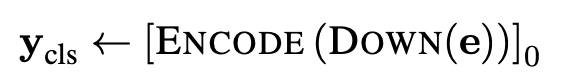
Preprocessing
CANINE의 입력은 정수열로 표현된다.
이는 raw text data를 Unicode로 변환한 것이다.
Unicode의 표준화와 정의가 매우 잘 되어있기에 엄청난 양의 Text도 단순한 순회 replacement로 빠르게 변환을 수행할 수 있다.
Character Hash Embeddings
CANINE은 Hash Embedding을 통해 유니코드 전처리를 수행한다.
하지만, 서로 다른 코드 포인트가 정확히 동일한 표현을 공유할 가능성을 줄이기 위해,
우리는 각 코드 포인트에 대해 여러 해시함수를 적용하고 여러 해시값과 관련된 표현을 연결하는
"표준 해싱 접근 방법의 일반화"를 정의한다.
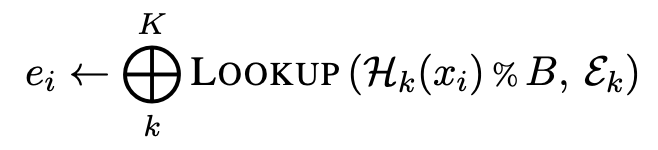
H_k : hash function ( N -> N )
e_k : embedding matrix
e_k ∈ R^(Bxd') .. yeilding k embeddings of size d' = d/k
⨁ : vector concatenation
(논문에서는 d = 768, k = 8, B = 16k)
이때, Hash collision 확률은 매우 적기에 고려하지 않아도 좋다.
Optional vocabulary-free n-grams
각 n-gram 순서가 합쳐진 임베딩에 동등하게 기여하도록 고정 어휘 없이 문자 n-gram을 포함하여 위의 임베딩 e_i를 재정의할 수도 있습니다.
(n-gram : n-gram은 텍스트에서 연속적으로 등장하는 문자나 단어의 시퀀스를 나타냅니다. 여기서 n은 각각의 문자나 단어의 길이를 나타내는 숫자입니다.)
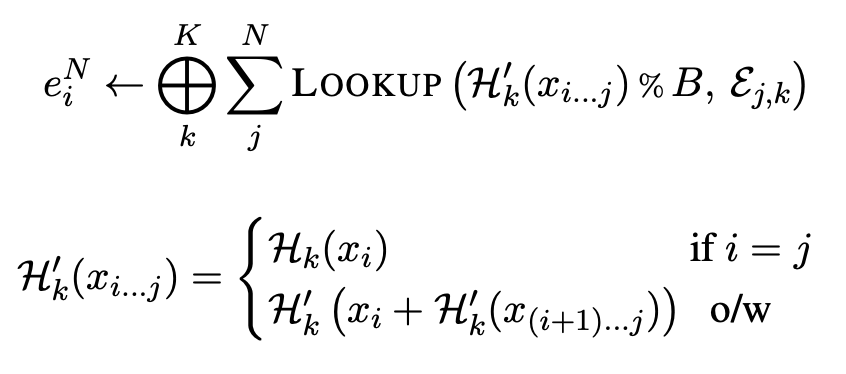
이 공식은 여전히 토큰화 없는 모델링을 허용하지만, 약간 더 많은 메모리를 소모합니다.
이는 계산비용이 적은 매개변수 추가를 통해 이루어집니다.
Downsampling
먼저, single-layer block-wise local attention transformer로 문자를 인코딩합니다.
이후, strided convolution을 사용하여 시퀀스 위치의 수를 단어 조각 모델과 유사하게 줄입니다.

h_down ∈ R^(mxd), m = n/r
r : stride
(논문에서는 r = 4, n = 2048, m = 512) 이다.
Deep transformer stack
downsampling 이후 마치 BERT와 derivative model의 핵심부분처럼 L개의 transformer stack을 연결합니다.
이 부분의 구성요소는 성능에 따라 다른 seq-to-seq model (Performer, Big Bird) 등으로 쉽게 대체될 수 있다.
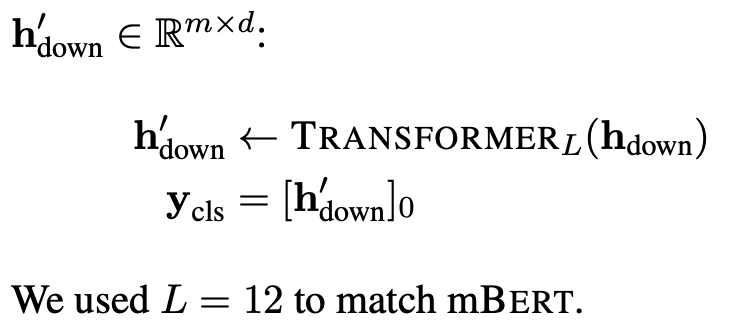
h_down : downsampling 결과값
Upsampling
지금까지의 구조도 classification task를 수행하기에 충분하다.
그러나 Sequence prediction task는 model이 input seq의 length와 같은 length의 결과를 도출하기 원한다.
그렇기에 우리는 원래의 문자 트랜스포머의 출력을 downsampling 된 representation과 연결하여 문자별 output representation을 재구성한다.
명심해라!
각 다운샘플링된 위치는 다운샘플링 비율 r에 따라 정확히 r개의 문자와 관련이 있으므로, 다운샘플링된 표현의 각 위치는 연결되기 전에 r번 복제됩니다.
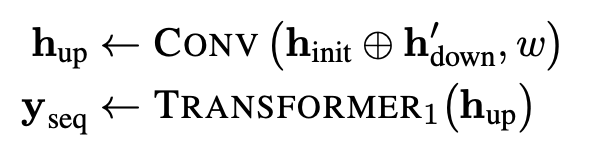
⨁ : vector concatenation (i.e., not seq)
w : number of characters for window (w = 4 in paper)
transformer layer -> standard, not local
여기서 "standard"는 transformer 모델의 일반적인 형태 및 동작을 의미하며,
"not local"은 해당 계층이 입력 시퀀스의 특정 부분에만 집중하는 것이 아니라 전체 입력 시퀀스를 고려한다는 것을 나타냅니다.
Residual Connections
inital character encoder (downsampling 이전), final character encoder (downsampling 이후) 모두 character position을 representing 한다.
그러나! 그들은 네트워크에서 굉장히 다른 목적을 가지고 있다.
직관적으로
initial character encoder는 더 word-like한 representation을 생성하기 위해 character를 compose한다.
final character encoder는 각 위치에서의 문맥의 의미를 예측하는 것에 연관되어 있는 in-context representation을 추출한다.
CANINE은 upsampling 중에 추가적인 모호성을 처리할 수 있어야 한다.
왜냐하면, 단일 downsampling 된 위치가 하나 이상의 개념적 단어에 걸칠 수 있기 때문이다.
이러한 유도된 특성들의 역할이 다르기 때문에 h_init에서 h_up으로 residual connectin을 사용하지 않는다.
가령, "큰 갈색 개"라는 문장에서 "큰 갈색"이 하나의 개념적 단어로 인식된다고 가정하자.
만일 downsampling 된 위치가 "큰 갈색"과 "개" 사이에 위차한다면, 이 위치는 두 개의 개념적 단어를 포함하고 있는 것이다.
따라서 CANINE은 이러한 추가적인 모호성을 다루는데 많은 노력을 기울여야 한다.
(애초에 토큰화가 없으니까 모델이 이런 작업을 잘 수행해야지!!!!)
3.2 Pre-training
최근 pre-trained 모델들은 span corruption으로도 불리는 masked language model (MLM) task의 변형을 unsupervised pre-training loss function으로 사용한다.
이는 실제 작업에서 파생되지 않은 합성 예제를 생성하는 수단으로, 모델이 미래의 훈련단계 (즉, fine-tuning)에서 실제 task를 학습하기 위한 준비를 하게 한다.
(자 이제 loss 쪽을 집중해서 봅니다.)
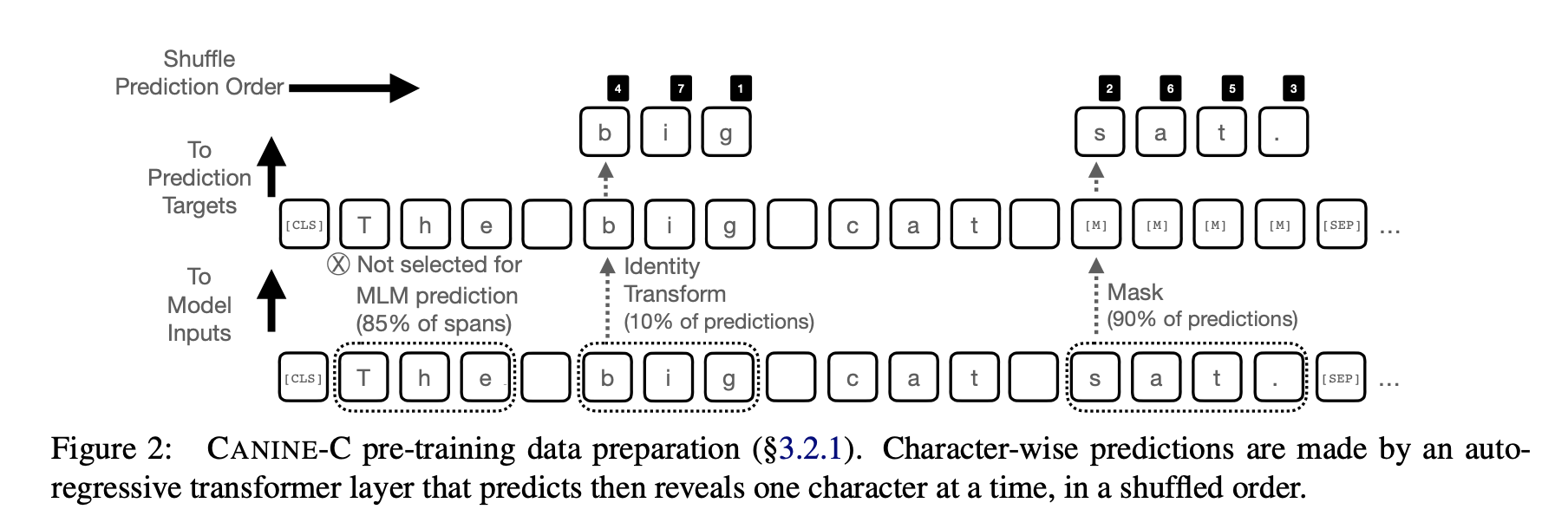
3.2.1 Autoregressive Character loss
Span-wise making
"CANINE-C"는 autogressive character loss이다.
이는 주어진 시퀀스 내에서 문자들을 간격으로 나누며, 각각의 구간은 공백 경계에 기반하여 선택된다.
(구두점 분할이나 다른 휴리스틱은 사용되지 않습니다.)
mask된 모든 character 들은 special mask codepoint로 대체된다.
subword vocabulary가 없기에 random subword replacement도 없다.
(여기서 span은 sequence에서 선택된 character를 의미한다.)
Span Prediction
"CANINE-C"는 masked character를 자동으로 예측하기도 한다.
마스크된 위치의 순서가 섞여있어 마스크된 Context가 반드시 왼쪽에서 오른쪽으로 공개되는 것이 아니라, 한번에 한 문자씩 공개되도록 섞인다.
앞서 3.2 pre-training 소제목 직전에 첨부한 이미지를 잘 살펴보면 이를 알 수 있다.
masked input : x
output of CANINE : y_seq
embeddings "e_g" of the gold characters g. (i.e., the character positions selected for MLM prediction)
(gold character는 MLM task의 정답 label이다.)

y hat은 각 문자를 예측하도록 한다.
큰 output weight matrix와 softmax에서 시간을 낭비하지 않기 위해, 골드 티켓 클래스 t는 bucket codepoint ID로 분류된다. (이때, t_i = g_i % B)
(bucket codepoint ID는 Unicode point를 그룹화하는데 사용되는 식별자이다.)
문자들 간 가끔 발생하는 충돌은 이 모델이 인코더만으로 구성되어 있고, 임베딩이 여전히 문자를 올바르게 예측하기 위해 문맥 정보를 유지해야 한다는 사실 때문에 덜 문제가 된다. 우리는 입력의 비교적 작은 일부 (논문의 실험에서는 15%)만 예측하고 있기 때문에, 이 레이어의 비용은 작다.
3.2.2 Subword Loss
"CANINE-S"는 subword based loss function이다.
이는 토큰 인식 pre-training loss가 토큰화된 모델과 함께 사용되어 토큰화 및 어휘를 사전 훈련 후 폐기할 수 있음을 보여줍니다.
Span-wise making
CANINE-S에서 각 span은 single subword에 해당합니다. 자기 회귀 손실과 마찬가지로, 마스크된 범위 내의 모든 문자는 특수한 "마스크" 코드 포인트로 대체됩니다.
Random replacement는 같은 길이의 subword 어휘끼리, 전체 문장 길이를 훼손하지 않는 선에서 진행된다.
공식으로 이를 표현하면..
선택된 subword : x
Vocabulary of subword : V
이때, replace 조건은 다음과 같다.
v ∈ V where Len(v) = Len(x) (v: 대체 subword)
Span Prediction
masked character span 내에서, CANINE-S는 masked prediction이 할 character position을 랜덤으로 정한다.
"softmax"를 통해서 masked subword의 identity를 식별한다.
관련 subword embedding은 pre-train 이후 폐기된다.
3.2.3 Targeted Upsampling
각 최종 character representation (upsampling 후)는 initial character encoder의 출력 (downsampling 전)과 deep transformer stack의 출력에 의해 결정된다.
Upsampling 된 sequence 간에는 위치간 종속성이 없다.
이는 Upsampler가 position-wise feed-forward projection과 single transformer layer를 사용하기 때문이다.
MLM task p에서 쓰일 sequence position만 upsampling하는 것으로 pre-training 중 속도를 개선한다.
다음은 그 공시이다.
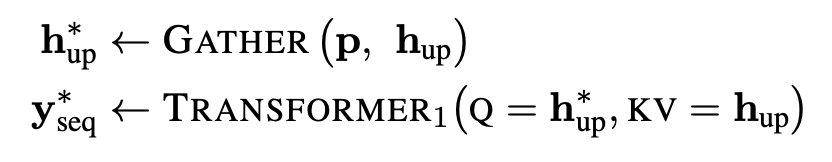
3.2.4 Modularity
CANINE은 이전 모델과 달리 pre-trained model에서 vocabulary 및 tokenization algorithm을 제거한다.
이는 모델이 fine-tuning 및 예측 중에 토큰화된 데이터를 처리하는 방법에 대한 지식을 필요로 하지 않도록 한다.
따라서, CANINE은 vocabulary나 토큰화 알고리즘에 의존하지 않고, 다양한 데이터를 자연스럽게 처리할 수 있는 모델이다.
4. Experiments
4.1.1 Information-Seeking QA Data
TYDI QA: Primary Tasks
11개 언어로 구성된 정보탐색 질의 데이터셋이다. 질의문은 응답문 전에 쓰여지며 이는 위키피디아에서 추출된 질문과 답변 간의 어휘 및 형태적 중첩이 줄어들게 됩니다.
우리는 주요 작업들을 평가합니다.
Passage Selection Task (SELECT P)
위키피디아 문서의 단락 목록이 주어졌을 때, 질문에 대한 답변이 있는 단락의 인덱스를 반환하거나, 만약 문서에 적절한 답변이 없는 경우에는 NULL을 반환합니다.
Minimal Answer Span Task (MINSPAN)
완전한 위키피디아 문서가 주어졌을 때, 질문에 완전히 답하는 최소한의 범위의 시작과 끝 바이트 인덱스를 반환합니다. 또는 시스템은 문서에 답변이 포함되어 있지 않음을 나타낼 수 있으며, 예/아니오 형식의 질문에 대해 YES 또는 NO를 반환할 수도 있습니다.
4.1.2 Named Entity Recognition Data
우리는 명명된 개체 인식(NER) 작업도 고려합니다. 이 작업은 모델이 문장의 어느 부분이 개체에 해당하는지 식별하고 개체 유형을 라벨링해야 합니다. 모든 실험에서 우리는 이 작업을 시퀀스 라벨링으로 프레임화했습니다. 즉, BIO 인코딩된 스팬 라벨을 예측하는 것입니다.
CoNLL NER
우리는 새스팬 도메인의 CoNLL 2002 NER 작업에서 스페인어와 네덜란드어 데이터를 사용하고 (Tjong Kim Sang, 2002), 뉴스 와이어 도메인의 CoNLL 2003 NER 작업에서 영어와 독일어 데이터를 사용합니다 (Tjong Kim Sang and De Meulder, 2003).
MasakhaNER
우리의 실험 범위를 유럽어 이외의 언어로 확장하기 위해, 우리는 MasakhaNER (Adelani 등, 2021)를 포함시켰습니다. 이는 아프리카 언어인 아머어, 하우사어, 이그보어, 키냐르완다어, 루간다어, 루오어, 나이지리아 피진, 스와힐리어, 울로프어, 요루바어를 포함하며 현지 뉴스 텍스트에 대한 인간 주석이 포함되어 있습니다.
4.1.3 Model Configuration
Direct comparison with mBERT
- CANINE은 효율적이고 고성능의 문자 수준 언어 모델로, 다양한 언어와 문제에 대해 유용합니다.
- CANINE은 기존의 BERT와 mBERT와 비교하여 품질이 우수하며, 사전 훈련 아키텍처의 효율성을 증명합니다.
- CANINE은 다운스트림 예측 작업에 대한 사전 훈련 모델로 사용되며, 이를 통해 다양한 언어 및 작업에서 높은 성능을 보입니다.
Setup
우리는 mBERT의 다국어 위키피디아 데이터를 사용하여 사전 훈련을 진행했습니다.
이 데이터는 104개 언어를 포함하고 있습니다. 마찬가지로, mBERT의 지수 평활 기술을 재사용하여 사전 훈련 샘플 내의 언어를 가중치로 설정했습니다. 우리는 배치 크기를 4096으로 설정하여 124k 단계 동안 훈련을 진행했습니다.
이는 데이터의 2.5회 반복을 의미합니다. 우리는 LAMB optimizer를 사용하였고, 선형 감소 학습률을 적용하여 0.018로 설정했습니다. 학습의 2.5%는 워밍 업에 사용되었습니다. mBERT의 경우 시퀀스 길이를 512로, CANINE의 경우 2048로 설정하여 사전 훈련을 진행했습니다. 이로 인해 CANINE의 핵심 딥 트랜스포머 스택에는 512개의 다운샘플링 위치가 생성되었습니다.
약 1일 동안 약 64개의 Cloud TPU v328에서 사전 훈련을 진행했습니다. mBERT와 CANINE-S(CANINE의 서브워드 손실 버전) 모두에서 MLM 손실을 위해 서브워드의 15%를 선택하고 최대 80개의 출력 위치까지 예측합니다. 입력에서 80%는 마스크가 되고, 10%는 무작위로 대체되고, 10%는 수정되지 않습니다.
CANINE-C(CANINE의 자기 회귀 문자 손실 버전)의 경우, 연속된 스팬의 15%를 MLM 손실을 위해 선택하고 최대 320개의 출력 문자를 예측합니다. 무작위 대체는 수행되지 않습니다. TYDI QA의 경우, 최대 답변 길이를 100자로 설정하였습니다. 이는 대략 99번째 백분위수의 답변 길이에 해당합니다. 최대 시퀀스 길이보다 긴 시퀀스는 BERT에 따라 제로 패딩됩니다.
4.2 TYDI QA Results
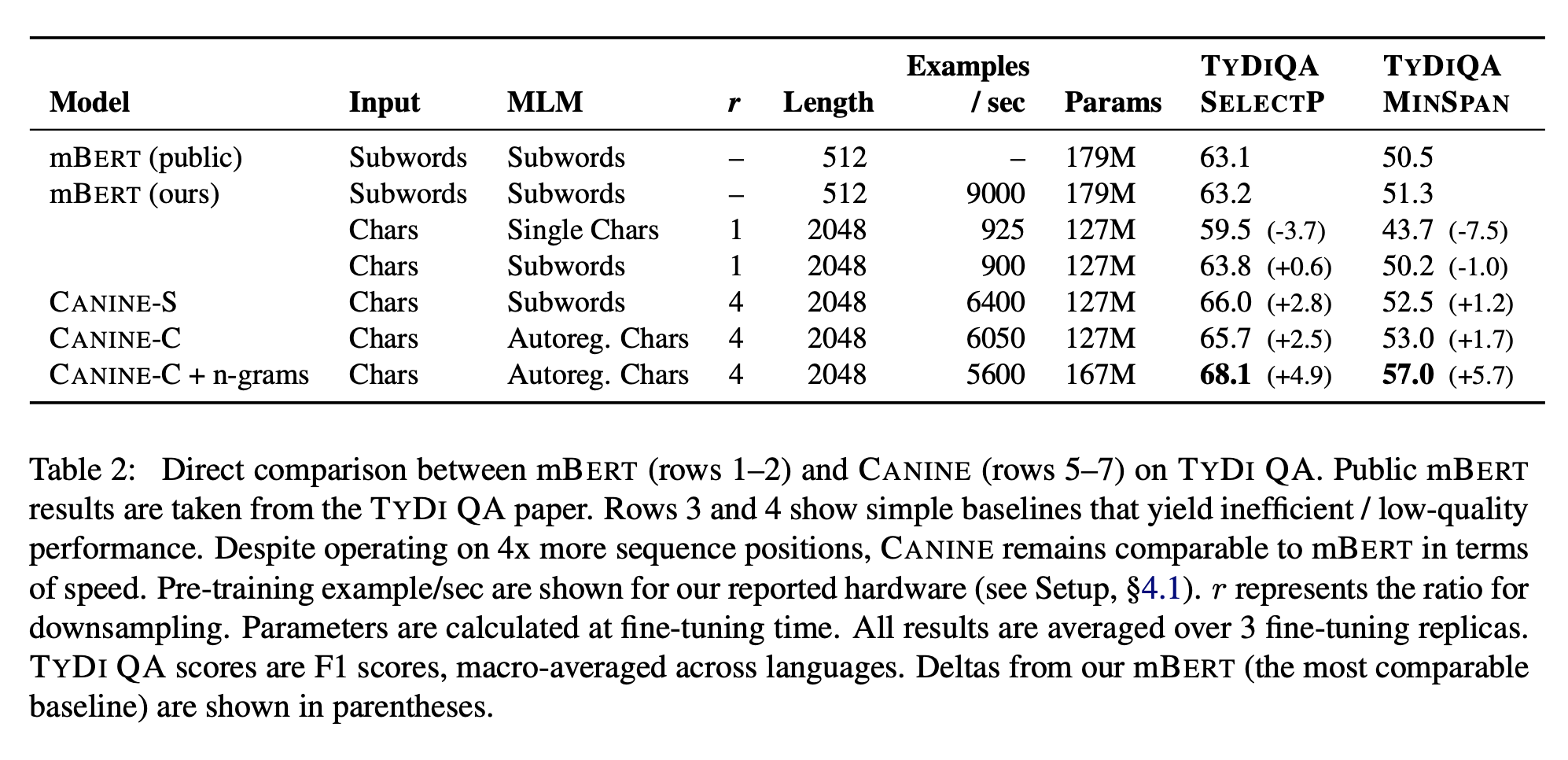
주요 결과는 위에 첨부한 표에 나와 있습니다. 서브워드 손실을 사용하는 CANINE-S는 TYDI QA SELECTP 작업에서 mBERT 대비 2.8 F1을 개선하였으며, 매개변수의 약 30%가량을 더 적게 사용합니다. 마찬가지로, 자기 회귀 문자 손실을 사용하는 CANINE-C는 mBERT 대비 2.5 F1을 개선하였습니다. 어휘 무관 문자 n-그램을 추가하면 mBERT 대비 추가적인 이득이 나타나며 (+3.8 F1), MINSPAN 작업에서 더 큰 이득을 얻을 수 있습니다 (+6.9 F1). 부록의 표 7에서 언어별로 세부 내용을 확인할 수 있습니다.
위 표의 3-4행에는 몇 가지 축소 모델의 결과도 추가로 제시됩니다. 3행에서는 BERT의 서브워드 어휘를 순수한 문자 어휘로 대체하여, 문자를 입력의 단위로 사용하고 MLM 작업에서 마스킹 및 예측의 단위로 사용합니다. 이 모델은 서브워드 기반 BERT보다 10배 느리며, 품질도 크게 저하됨을 관찰할 수 있습니다. 4행에서는 입력 단위로 문자를 유지하면서 마스킹 및 MLM 예측을 위해 서브워드를 사용하도록 이 모델을 수정하고, 사전 훈련이 여전히 극도로 느립니다. 마지막으로, 전체 CANINE 모델과 비교하여 5행에서는 다운샘플링 전략을 추가함으로써 속도가 700% 개선되었으며, 품질도 약간 향상되었습니다. 이는 모델에 딥 트랜스포머 스택 내에서 더 단어와 유사한 단위를 얻게 해줌으로써 추가적인 품질 향상이 이루어졌을 것으로 추정됩니다.
Analysis

CANINE은 Kiswahili와 같은 형태론적으로 풍부한 언어에서 특히 잘 수행됩니다. 표 3은 TYDI QA SELECTP 작업에서 CANINE이 mBERT를 능가하는 예제를 보여줍니다.
특히, Kiswahili의 풍부한 형태론이 CANINE의 일치 과정을 방해하지 않는 예제를 관찰할 수 있습니다.
