아주 미친 논문을 들고왔다.
최근 BitNet이 1-bit LLMs의 새로운 시대를 열고 있다.
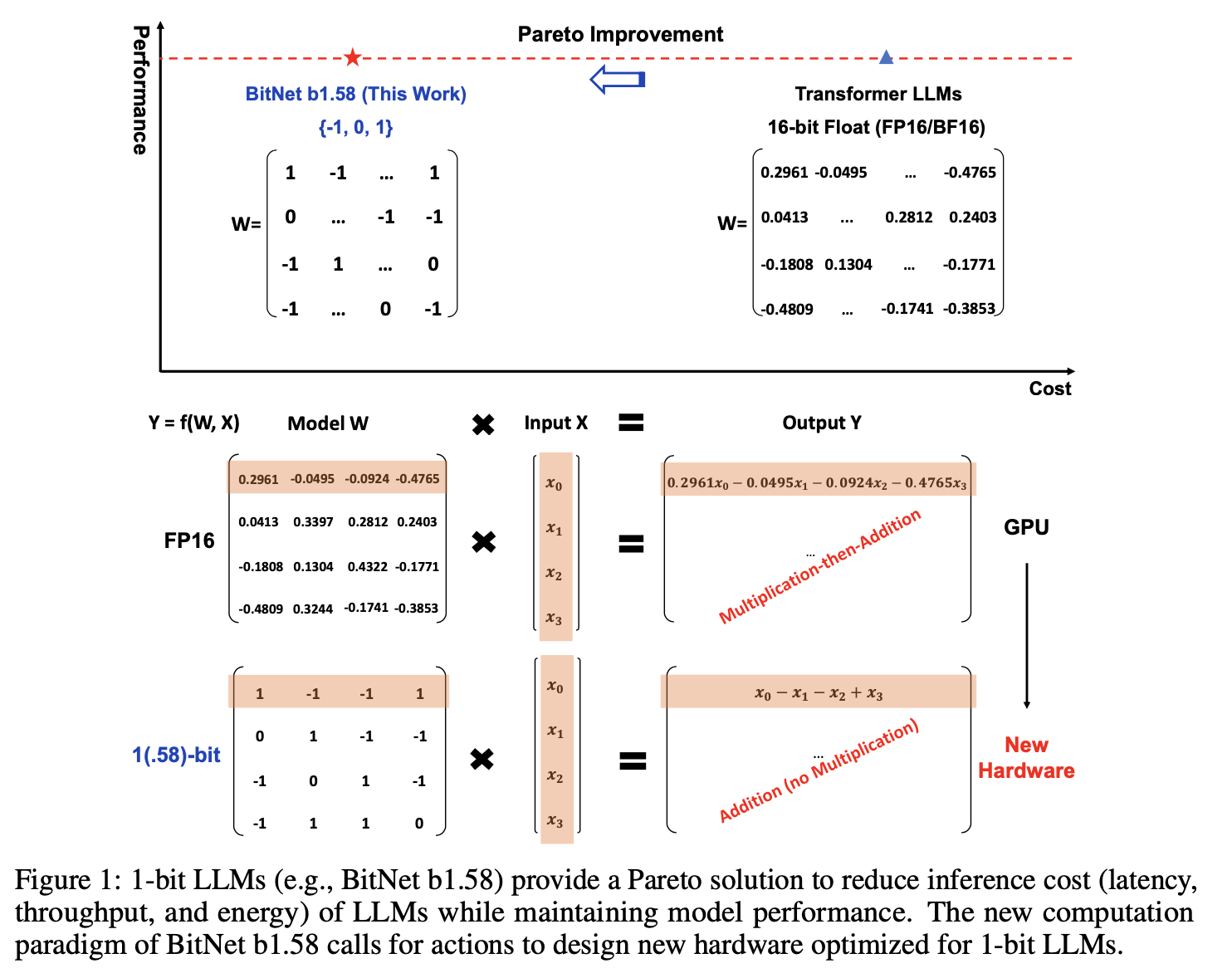
본 논문은 모든 개별 매개변수가 {-1, 0, 1}로 이루어진 BitNet b1.58이라는 1-bit LLM의 변형을 소개한다.
해당 모델은 full-Precision Transformer LLM과 견줄법한 성능을 자랑한다. 그럼에도 불구하고! Cost에서 압도적인 효율을 자랑한다.
심층적으로, 1.58-bit LLM은 새로운 Scaling 방식, 레시피를 제시한다. (그런데 이제 매우 고성능과 고효율인 것이다!)
또한 1-bit LLM 대상의 새 Hardware를 위한 Computational Paradigm을 제시한다.
1. The Era of 1-bit LLMs
최근 몇년간 AI는 급성장을 이루었다.
그 결과 경제적, 환경적으로 소모되는 에너지와 비용이 증가하였고 이에 대해 양자화된 low-bit model에 대한 개발 수요가 증가하였다. (이를 post-training quantization 이라고 한다.)
그러나 post-training quantization이 발전함에도 성능면에서는 sub-optimal하였다. (16bit에서 4bit 모델까지 지속적으로 발전하였다.)
BitNet 같은 최근에 개발된 1-bit model architecture는 성능은 유지하면서도 비용 효율성이 증가하였다.
Q. 왜 비용 효율성이 증가하였는가?
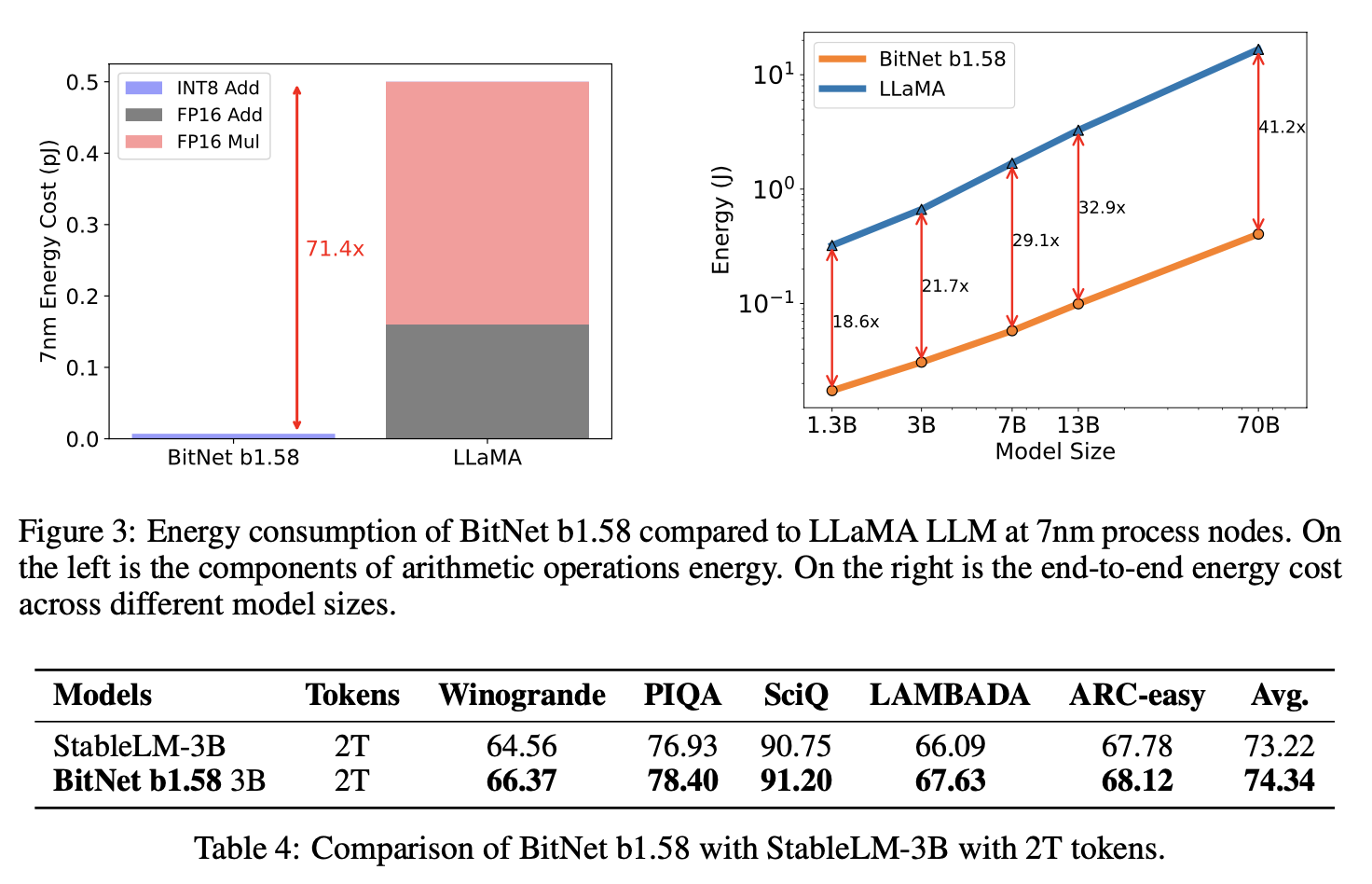
기존 LLM은 floating-point addition, multiplication operation에서 대부분의 비용이 발생한다. 이 비용은 가히 압도적이다. 그러나 BitNet은 이러한 연산 없이 integer addition만 matrix multiplication에 포함된다. 이 때문에 비용이 획기적으로 줄어들고 "Faster Computation" 즉, 더 빠른 연산이 가능해진다.
Computation에 더하여 DRAM에서 Memory로 model parameter를 전송하는 속도도 빨라졌다. (추론 과정에서 비용이 비싸질 수 있음.)
1-bit LLM은 이러한 점에서도 Cost를 크게 줄인다.
(참고로 SRAM은 DRAM보다 느려 쓰지 않는다.)
<BitNet 1.58>
BitNet 1.58은 모든 매개변수의 값이 {-1, 0, 1}로 고정된다.
해당 모델은 1-bit BitNet의 모든 장점들을 그대로 가져오면서 matrix multiplication 연산을 거의 수행하지 않는다. (또한 굉장한 최적화가 진행됨.)
1-bit BitNet과 같은 양의 에너지를 소모하면서도 Memory 소모 면에서는 더 효율적이다.
이를 제외하고도 2가지 장점이 더 있는데
1. 0을 모델 가중치에 포함하여 기능 필터링을 명시적으로 제공하므로 1 bit LLM의 성능을 크게 향상시킬 수 있다.
2. perplexity, end-task performance 모두 완전 정밀도 (즉, FP16) 기준에 준한다.
(Perplexity: text 생성 모델의 예측 불확실성을 나타내는 지표)
(End-task Performance: 모델이 주어진 최종작업 (기계번역, 텍스트 분류 등)에서 얼마나 잘 수행되는지를 측정하는 지표)
2. BitNet b1.58
nn.linear를 BitLinear로 대체하는 Transformer인 BitNet architecture에 기반하고 있으며 1.58-bit 가중치와 8-bit activation으로 훈련되었다.
다음은 기존 1-bit BitNet과의 차이점이다.
Quantization Function
Absmean Quantization Function(절대 양자화 함수)을 적용하여 가중치를 {-1, 0, 1}로 제한한다.
다음은 Absmean Quantization Function의 진행과정이다.
- weight matrix (가중치 행렬)을 그것의 average absolute value (평균 절대값)으로 scaling한다.
- 각 value를 {-1, 0, 1} 중 가장 가까운 값으로 반올림한다.
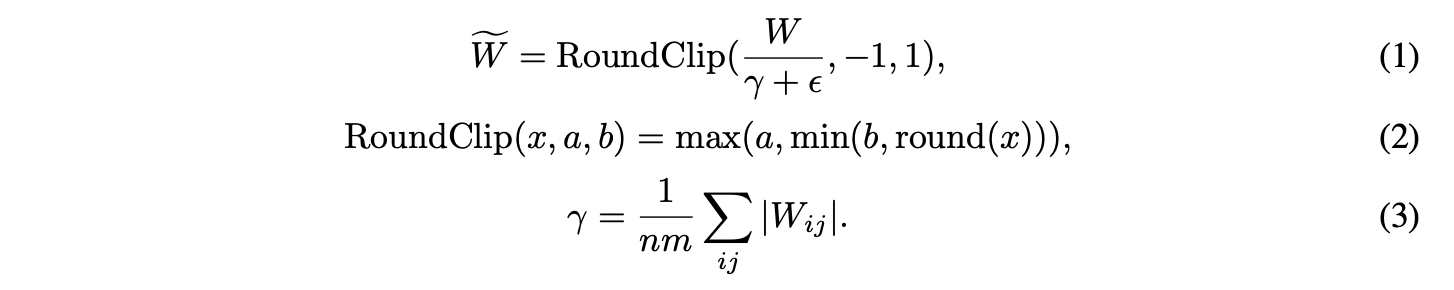
Activation Function에 대한 양자화 함수는 BitNet과 동일한 구현을 따르지만,
activation을 비선형함수 이전에 범위 [0, Q_b]로 스케일링하지 않는다.
대신, activation은 모두 토큰 당 [-Q_b, Q_b]로 스케일링 되어 제로 포인트 양자화를 제거한다.
(제로 포인트 양자화: 양자화된 값이 범위에서 제로포인트를 기준으로 하는 방법. ex, [a, b] -> [a, 0, b]
LLaMa-alike Components
LLaMA는 오픈소스로 공개되어 LLM 모델에 많은 기여를 했다.
본 논문의 BitNet b1.58은 LLaMA-alike component들을 채택하였다.
특히, RMSNorm, SwiGLU, rotary embedding을 사용, 모든 bias를 제거했다.
3. Results
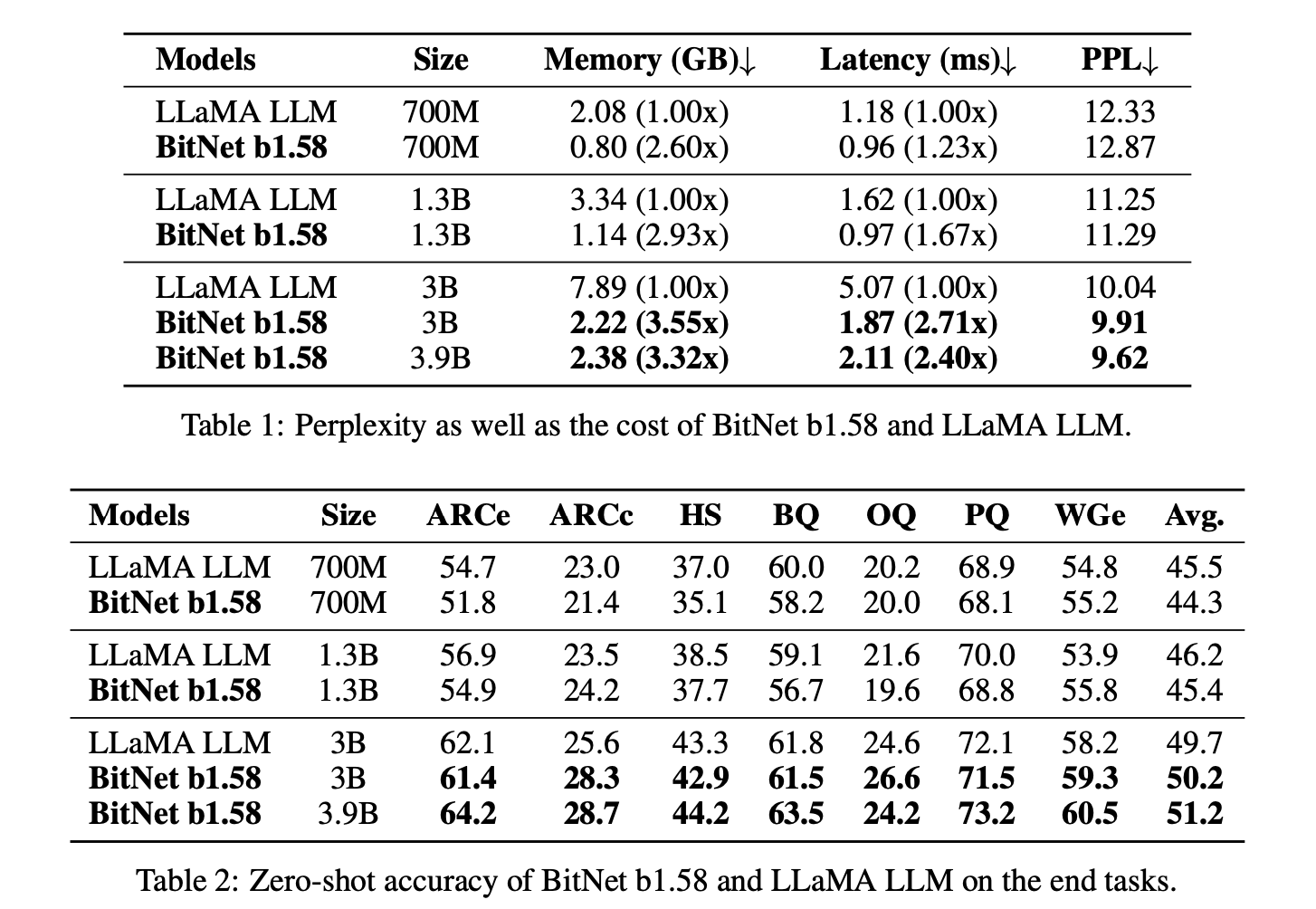
Dataset: RedPajama dataset for 100 billion tokens
Evaluated ZeroShot Performance on a range of language task
(* ZeroShot Performace: 모델이 추가 학습 없이 새로운 작업을 수행하는 능력)
BitNet b1.58과 LLaMA LLM 사이의 성능 차이는 모델의 크기가 증가함에 따라 줄어든다.
BitNet b.158과 LLaMA LLM 사이의 속도 차이 또한 줄어든다. 왜냐하면 모델의 크기가 증가함에 따라 nn.Linear의 time cost가 증가하기 때문이다. 이는 memory gap에서도 마찬가지이다.
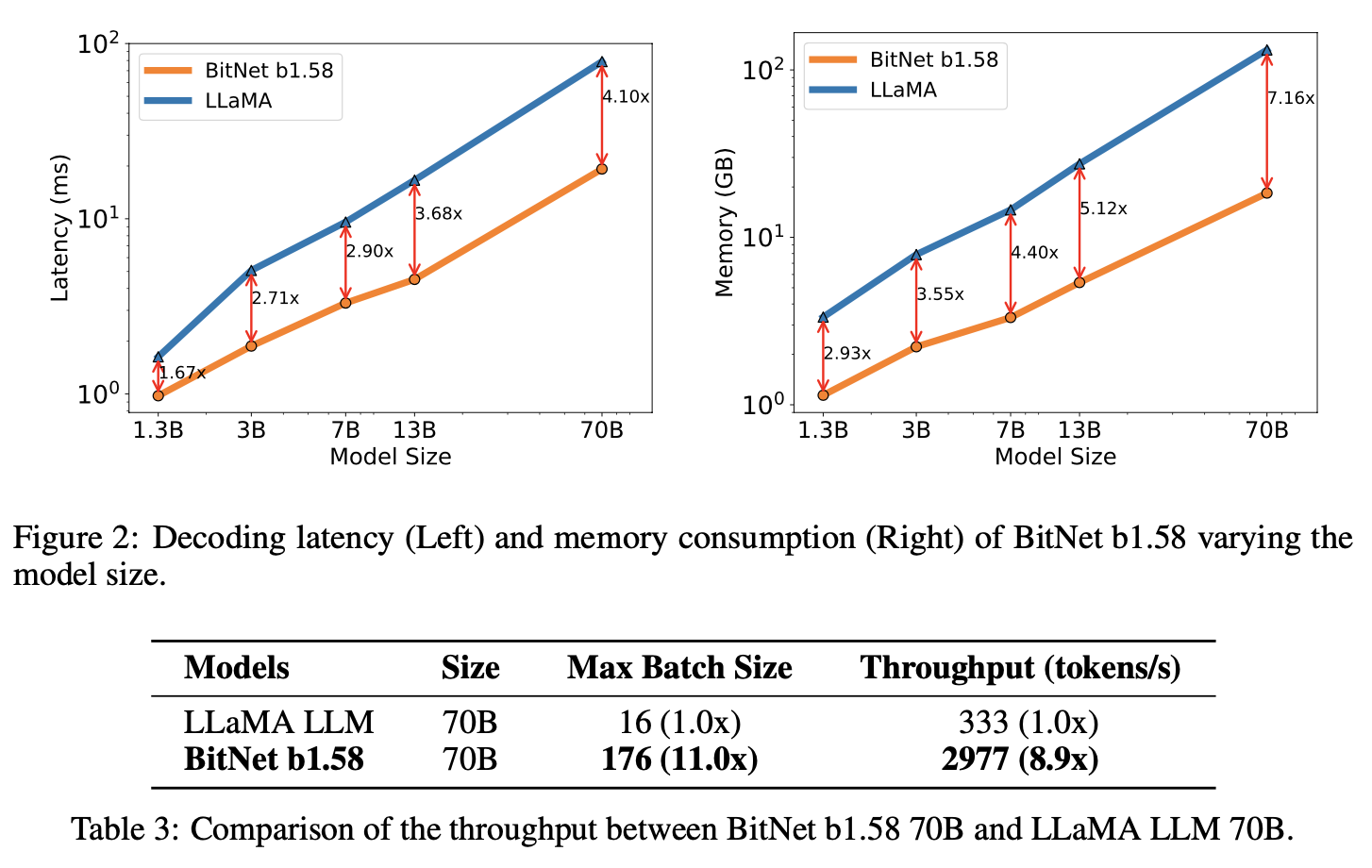
Decoding Latency와 memory consumption 모두 BitNet b1.58이 압도적이다.
Throughput 또한 마찬가지이다.
(Thoughput: 모델이 시간당 처리할 수 있는 작업의 양.)
BitNet b1.58과 StableLM-3B의 성능 비교이다. 같은 토큰양에 대해 BitNet b1.58이 근소한 우세를 보인다.
4. Discussion and Future Work
1-bit Mixture-of-Experts (MoE) LLMs
Mixture-of-Experts (MoE) -> LLM의 cost를 효과적으로 다루는 방법이다.
Computational FLOPs를 기하급수적으로 줄이는 대신, high memory consumption과 inter-chip communication 때문에 상용화하기는 어렵다.
그러나 1.58-bit LLM으로 해당 문제를 해결할 수 있다.
- 줄어든 memory footprint가 MoE 모델 배포를 더 쉽게 만들어준다.
- 네트워크간 활성화 전송이 오버헤드를 크게 줄여준다.
- 전체 모델을 단일칩에 배치하여 오버헤드 자체를 없애버린다.
Native Support of Long Sequence in LLMs
long seq를 처리하는 것은 LLM의 중요과제이다.
Seq가 길수록 memory 소모가 크기 때문이다.
1.58-bit LLM이 memory 소모가 작기에 이를 해결할 수 있다.
LLMs on Edge and Mobile
edge와 mobile device에서의 LLM 사용에 크게 기여한다. (작은 장치에서도 고성능의 LLM 사용이 가능해짐)
또한 1.58bit-LLM이 CPU 친화적이기에 이런 장점이 더욱 강조된다.
New Hardware for 1-bit
LLM 특화 Hardware 또한 개발되었다.
1-bit Model에 특화된 Hardware도 기대할 수 있을 것이다.
