크롤링 환경 세팅

먼저 작업하려고 하는 디렉토리 안에 작업 디렉토리를 만들었습니다.

작업 디렉토리에서 작업할 가상환경을 생성합니다.
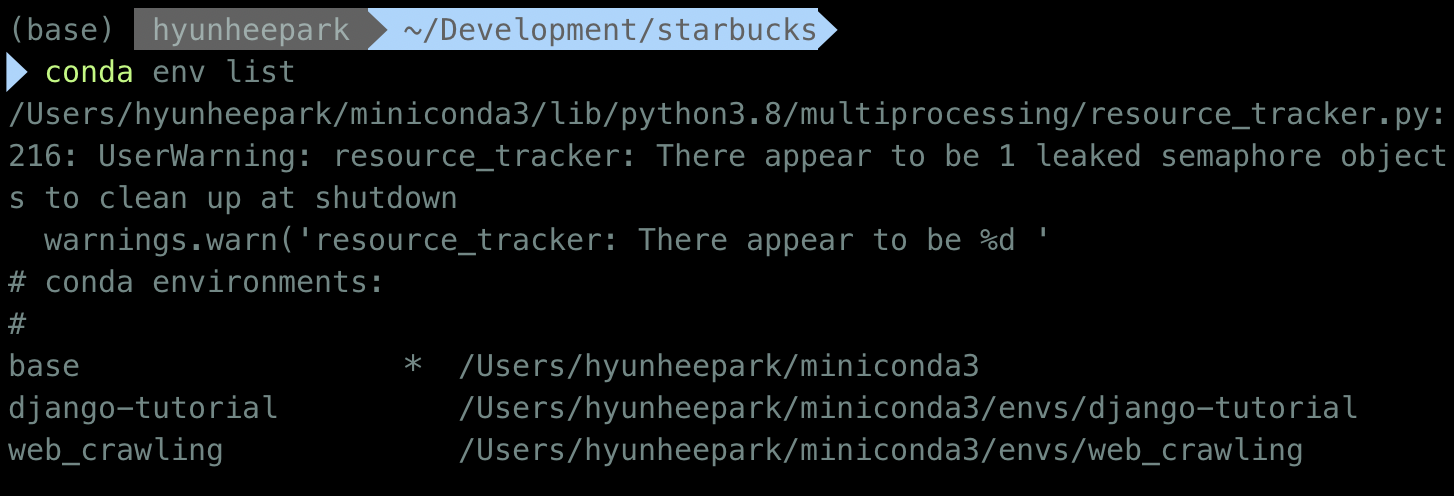
새로 생성된 가상환경을 확인합니다.

생성한 가상환경을 실행시킵니다.




크롤링에 필요한 라이브러리들을 설치합니다.
모듈 import

작업을 위핸 파이썬 파일을 만들어줍니다.

모듈을 import 해줍니다.
csv 파일 작업

csv 파일에 저장하기 위해 미리 셋팅을 했습니다.
witer를 사용하면 writerow() 메서드를 통해 list 데이터를 한 줄씩(row) 입력 가능하여 좋습니다.
페이지 접속과 파싱
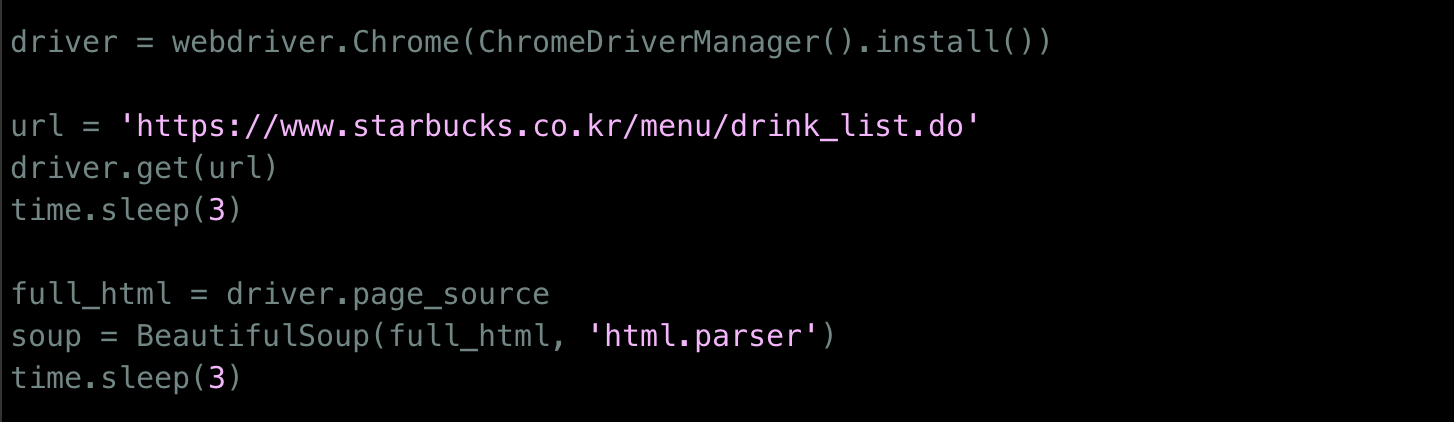
셀레니엄의 webdriver를 통해 페이지에 접속하고
beautifulsoup으로 페이지의 HTML 코드를 파싱합니다.
데이터 추출
우선 필요한 데이터는 음료의 이름과 음료 이미지입니다.
스타벅스 페이지에서 그에 맞는 태그를 살펴보겠습니다.

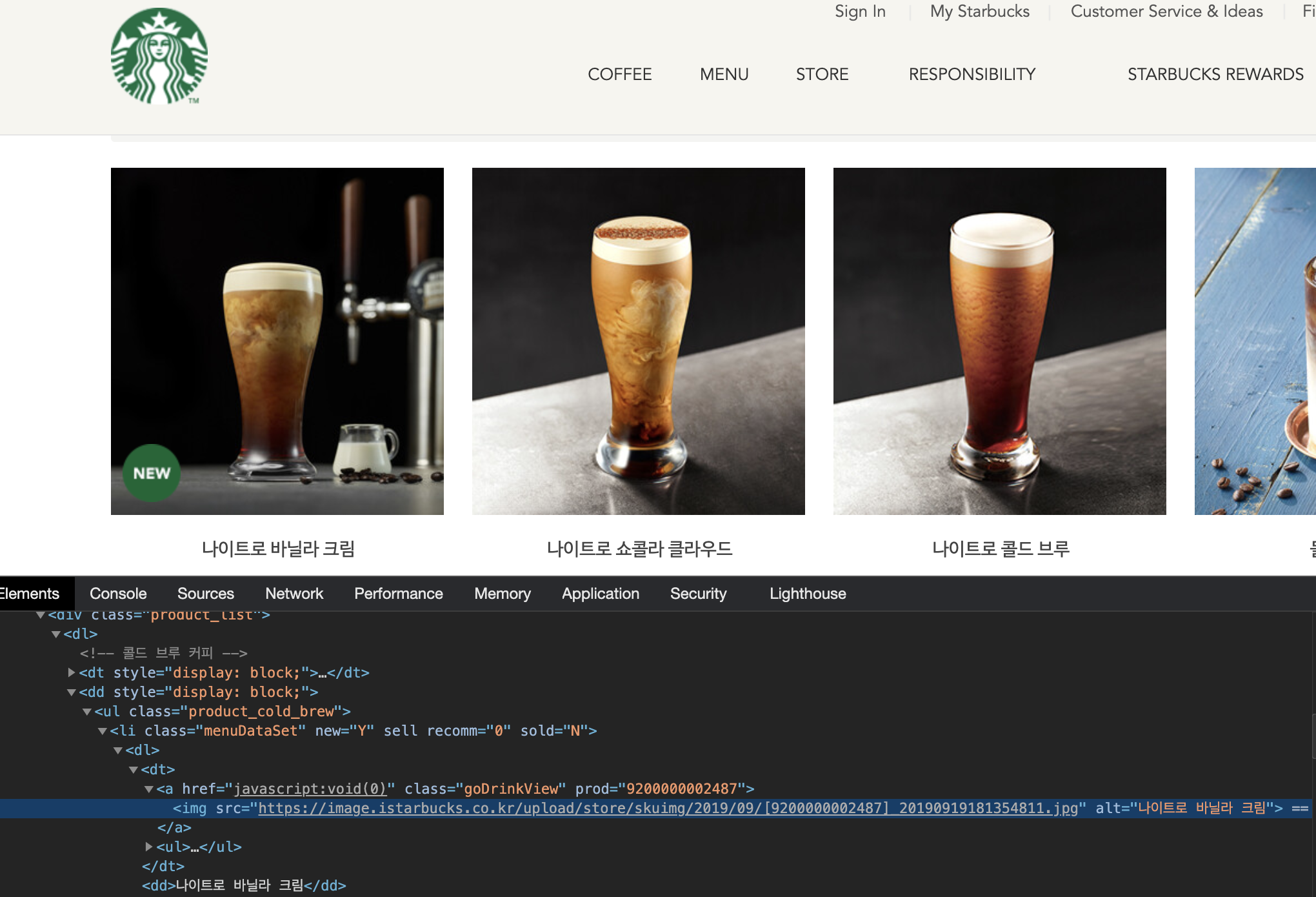
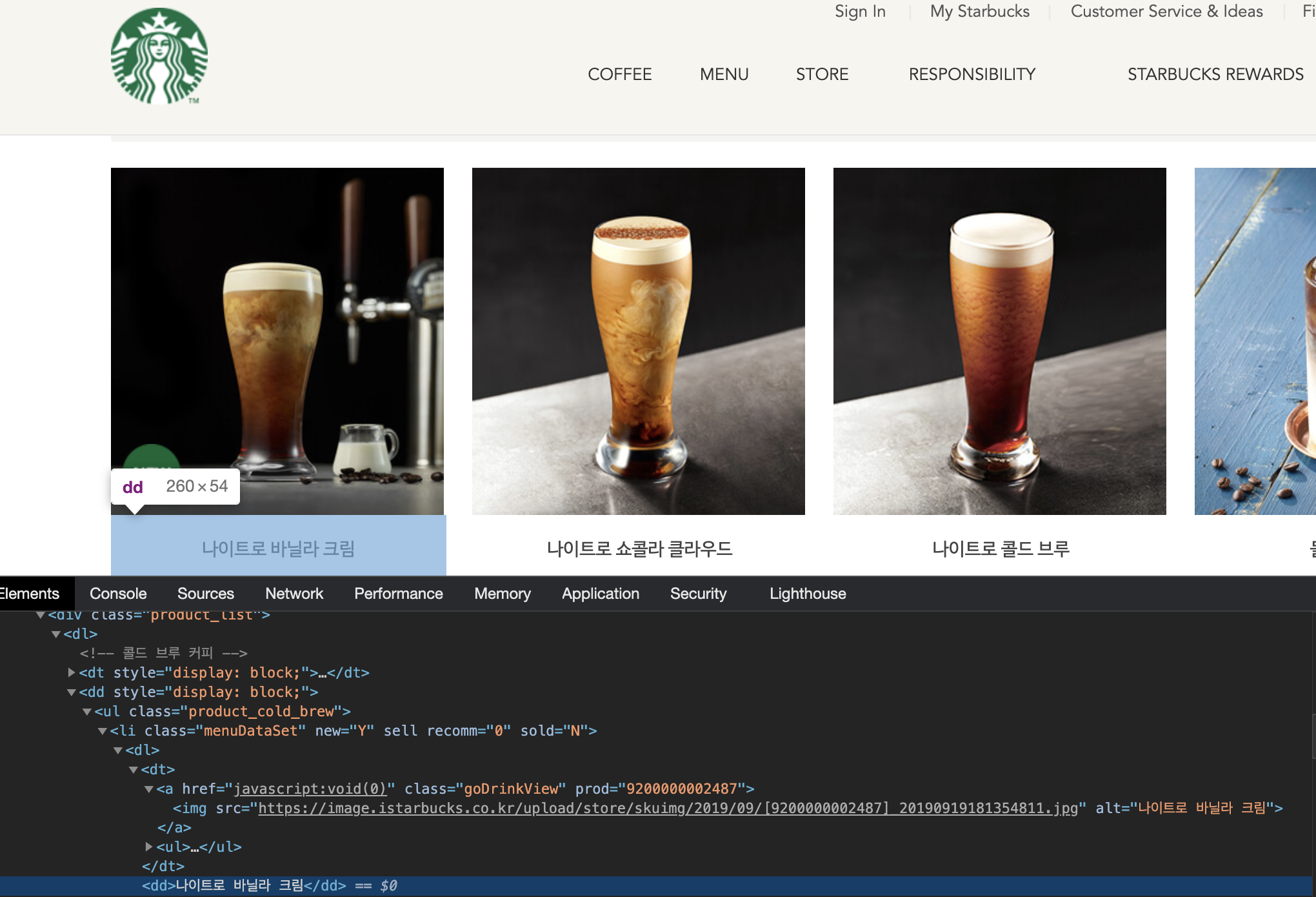
음료 이미지는 menuDataSet class를 가진 li 태그 > dl > dt > a > img 루트를 가집니다.
음료 이름은 menuDataSet class를 가진 li 태그 > dl > dd 루트를 가집니다.
저는 이런 경우에는 selector를 이용하는게 편하다고 생각해서 그걸 이용했습니다.
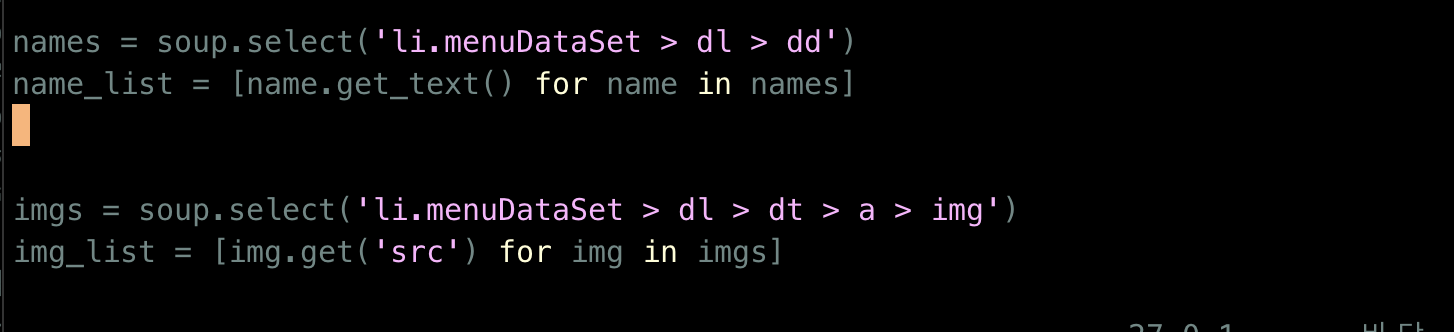
csv 파일 작성
위에서 추출한 데이터를 csv에 작성하기 위해 for loop와 writerow를 사용하였습니다.

결과물

디렉토리 안에 starbucks_crawling.csv 파일이 생성된걸 확인할 수 있습니다.
파일을 열어 확인하니
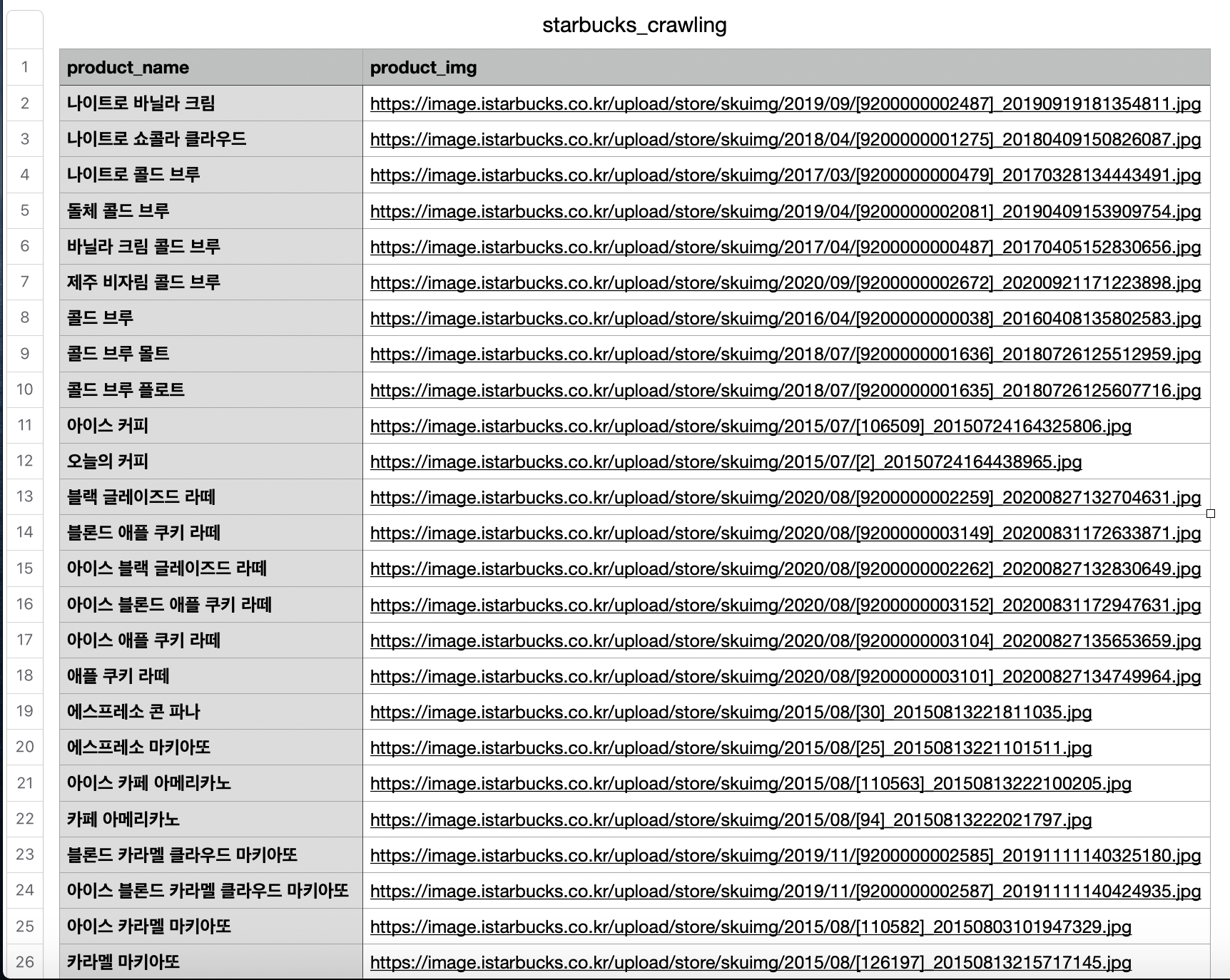
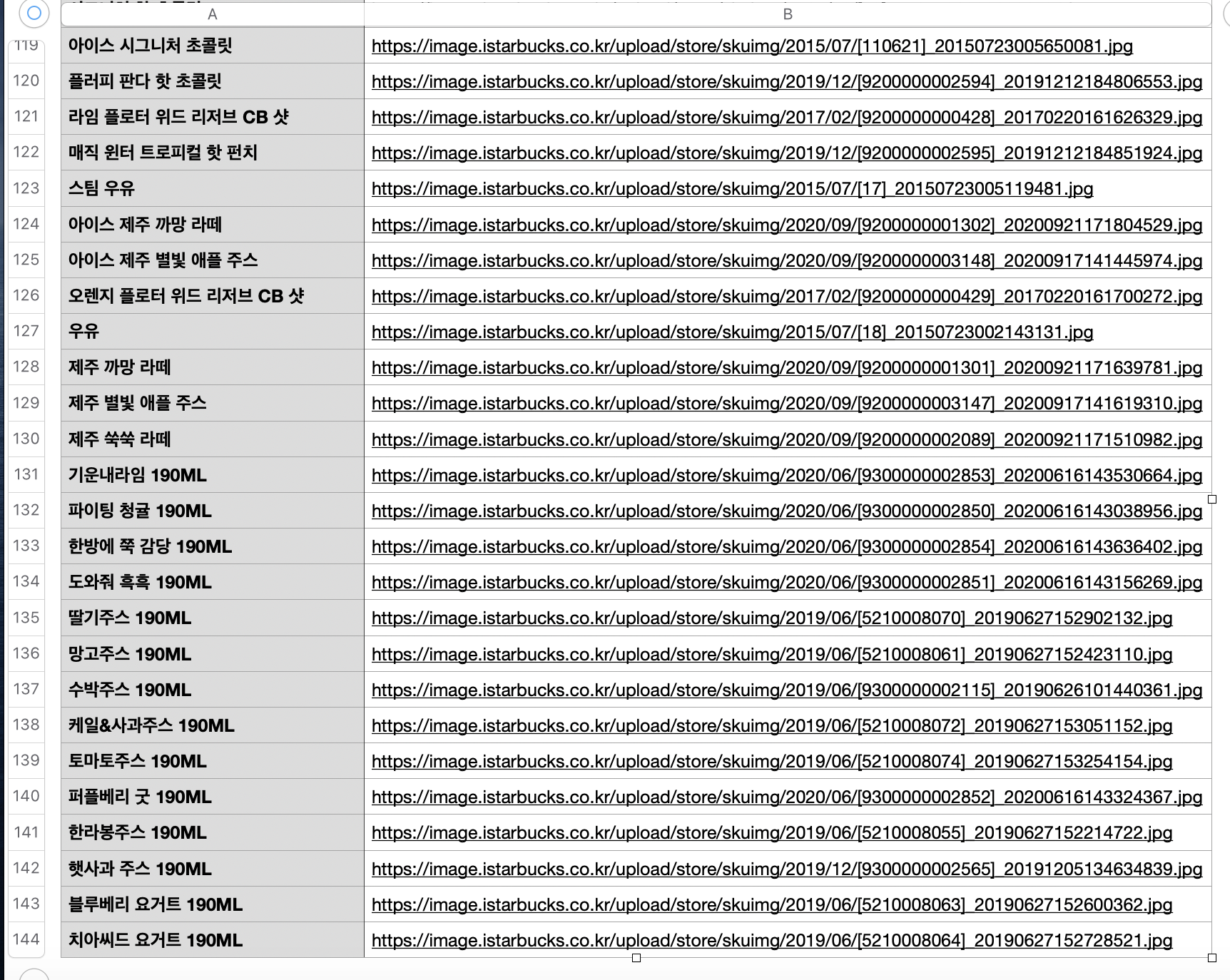
총 143개 음료의 정보가 들어온 것을 볼 수 있습니다.
