Latent Variable Models
강력하게 추천드리는 이유 : Adam Optimizer를 만든분이 만든 모델
Autoencoder
Variational Auto-encoder
-
posterior distribution 을 찾는것이 목표다.
-
variational distribution
- 학습하는 분포를 말함.
무언가를 잘 최적화 하겠다.
KL 다이버전스를 활용한다.
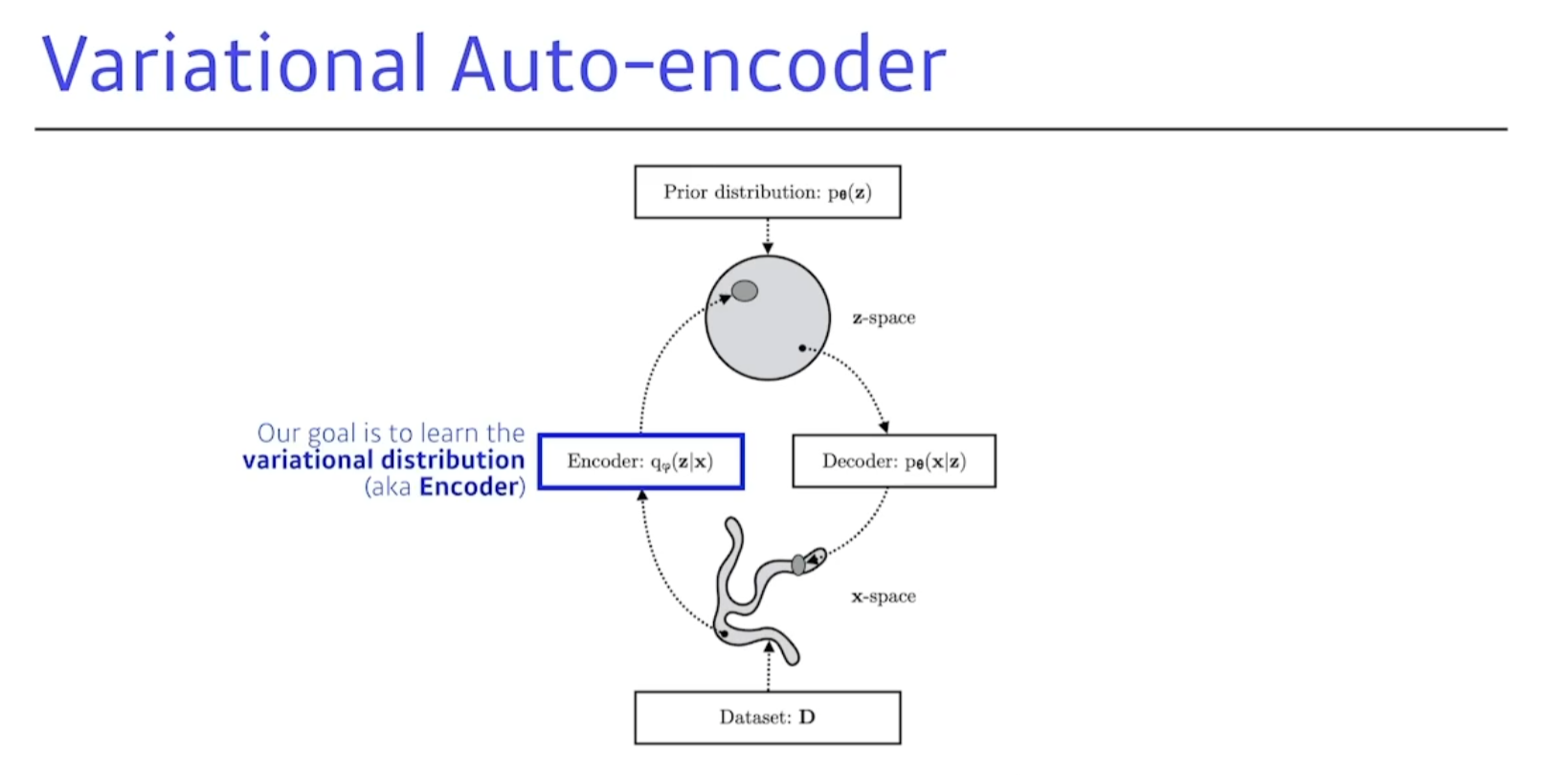
뭔지도 모르는 variational distribution을 어떻게 찾냐?
그것이 바로 variational auto-encoder를 사용한다.
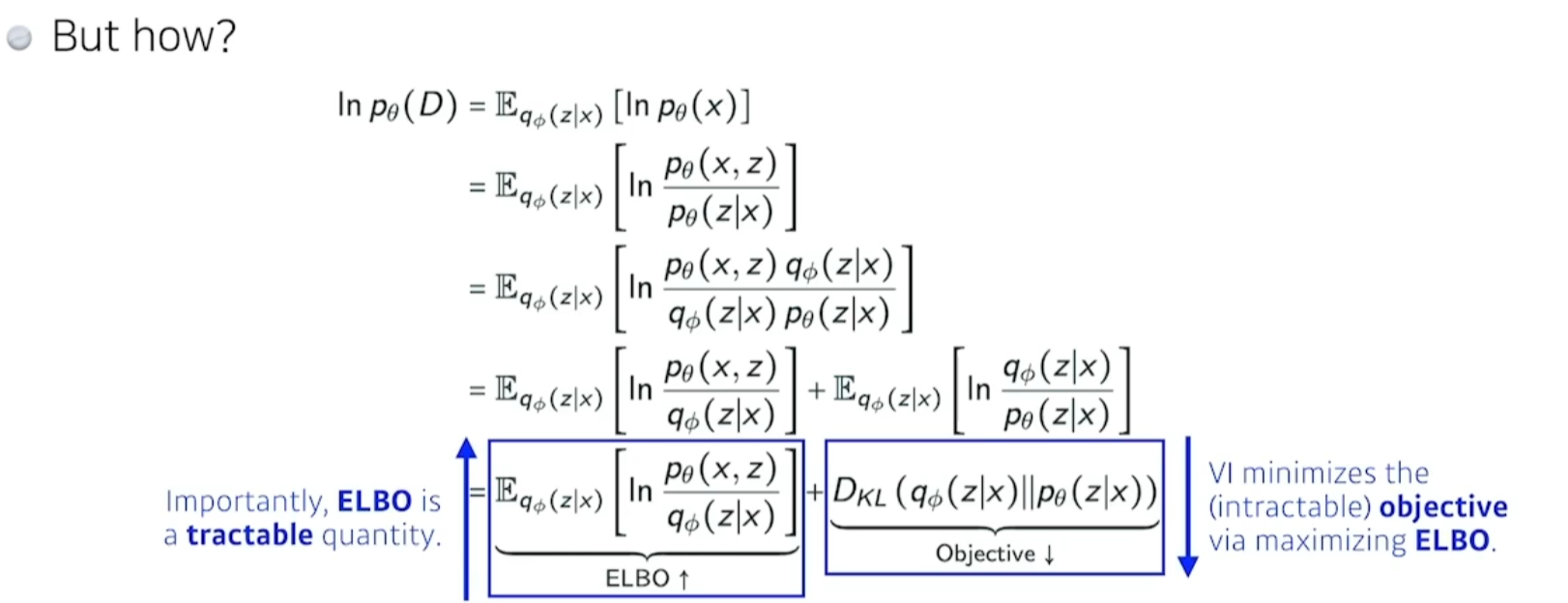
뭔지도 모르고 계산할수도 없는걸 ELBO를 맥시마이즈 하면서 찾아낼 수 있는것이다.
- ELBO : 에비젼스 롤 바운드는 나눠볼 수 있다.
- X라는 입력이 있고, Z라는 레이턴시 스페이스를 찾고싶다. 우린 encoder로 얘를 근사하고싶다.
- 이 ELBO
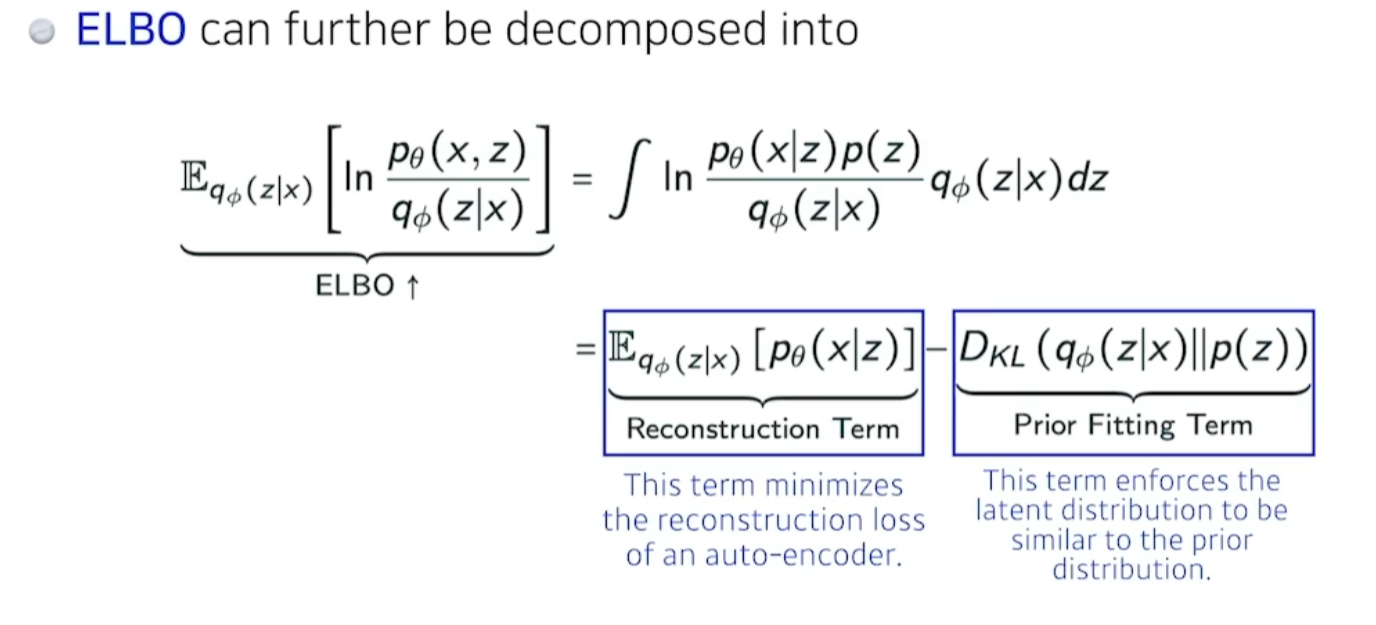
에비던스 롤 바운드를 맥시마이즈 하는것이 posterior,varitional distribution의 두개의 거리를 줄여주는것과 같은 역할을 하더라. - 이 ELBO는 잘뜯어보면 두가지로 나뉜다.
- Reconstruction term : x란입력을 레이턴시로 보냇다가 다시 x로돌아오는 레이턴시를 줄인다.
- Prior fitting term : x란 이미지를 잔뜩 z로 보낸다. 이 점들의 분포가 내가가정하는 레이턴시의 사전분포와 비슷하게 만들어주는 이 두가지업데이트를 동시에 만족하는 것과 같다.
Key limitation

- 얘가 제너레이트 모델이 되기위해서 디코더를 태워서 나온 값들을 generative model이라고 본다. 엄밀히 말하면, generative 모델이 아니다.
- intractable model - 얼마나 likelihood
어떤 상황이 발생할 확률한지 알기 힘들다. - prior fitting term이 미분 가능해야한다.
- 대부분 케이스는 우린 isotropic gaussian을 사용한다.

Adversarial Auto-encoder (AAE)
- 앞에서 봣던 variatial 오토인코더의 단점은 인코더를 활용할때 프라이어 피팅텀이 k다이어버리를 활용한다는것이다. 그래서 가우시아닝 아닐때는 활용할수없다.
- GEN을 사용해서 latent distributions 을 맞춘다.
- 그럼 많은경우는 가우시안을 활용하고싶지않다. 그럴때는 adversarial auto-encoder를 사용한다.
- 샘플링이 가능한 어떤 분포만 있어도 이것과 맞출 수 있다.
- 주로 adversarial auto-encoder를 많이 활용하고있다.
- 성능도 varitial보다 훨씬 좋을 때가 많다.(항상은 아니고)
Genereative Adversarial Network (GAN)
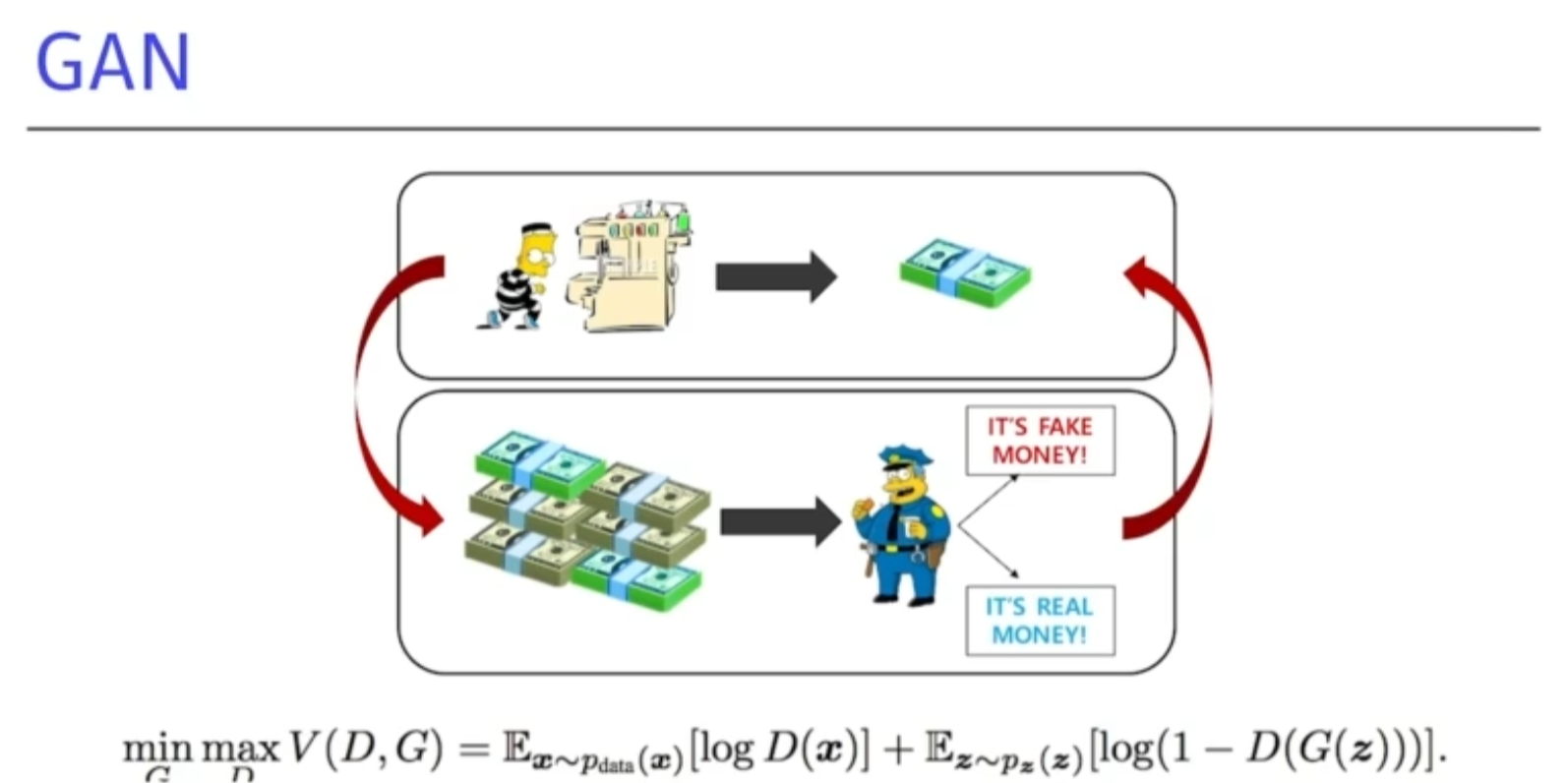
- 겐이라는 방법론은 재밋는 아이디어를 가지고 있다.
-
도둑이 위조지폐를 만들고싶다.
-
위조지폐를 잘 분별할수있는 경찰이 있다.
-
경찰이 이걸 분별하고 분별한걸 바탕으로 도둑은 경찰을 속이려고 한다.
-
이런식으로 계속 더 잘 구분할 수 있게 학습을 한다.
-
위 과정을 반복함으로써 generative 성능을 높이는것이 목표이다.
장점 : 좋은 generater가 우리가 원하는 것이다. 내가 학습에 결과로 나오는 discriminator가 점차점차 좋아진다는게 제일 큰 장점이다.
- 임플리싯 모델이다.
GAN vs VAE(variational autoencoder)
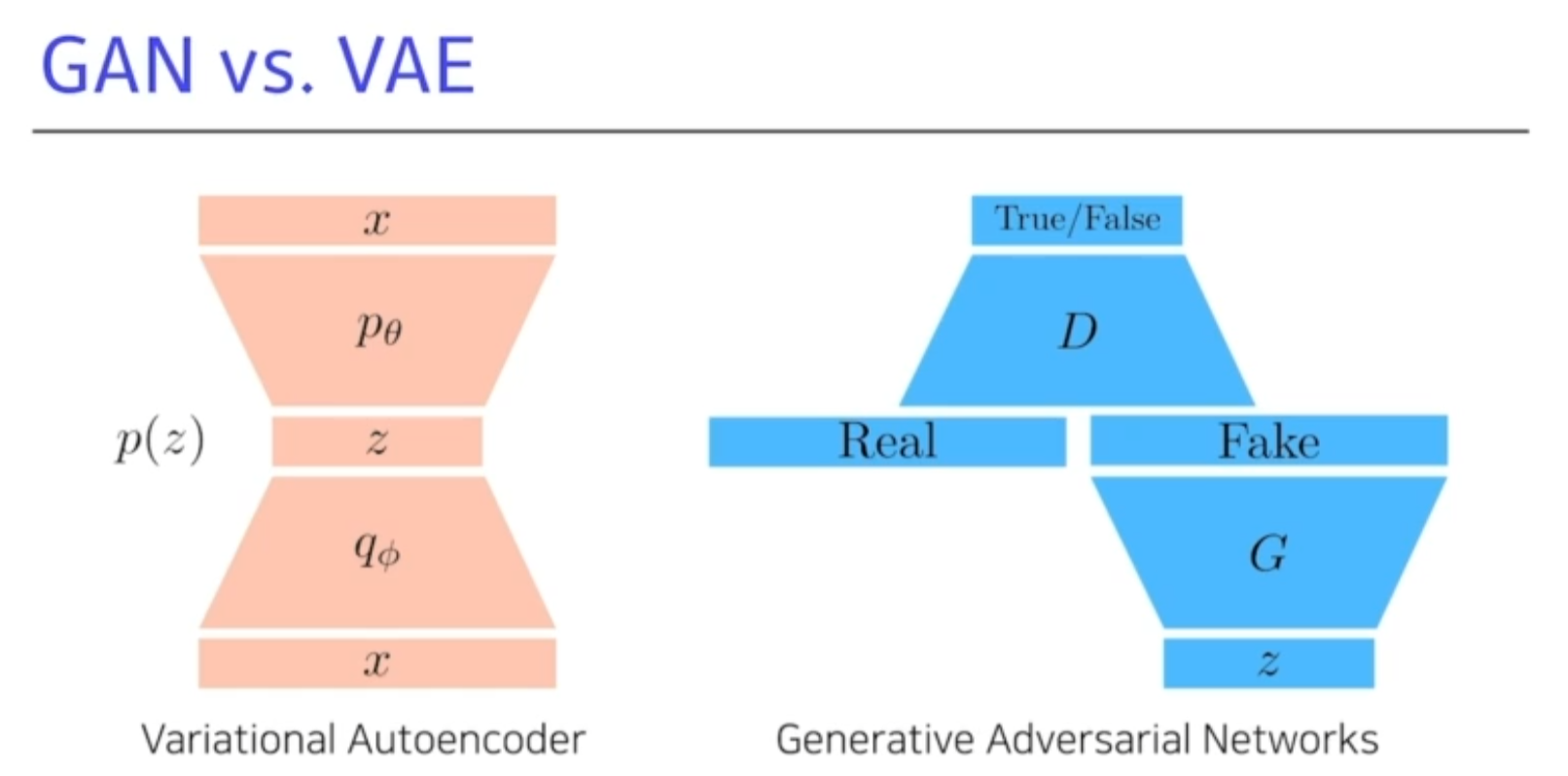
-
x -> q -> z -> p-> x 를 거치는게 일반적인 VA방식.(Variational Autoencoder)
-
G를통해서 Fake가 나오고 이 Fake이미지를 구분하는 분류기를 학습하고, 그렇게 학습된 분류엥서 True가 나오도록 학습을 계속 진행한다.
-
이 D와 G를 계속 학습한다.
GAN Objective
-
2플레이어 미니맥스 게임이라고 본다.
-
Generator 와 discriminator.

-
generator가 fix가 돼있을때 얘를 항상 최적으로 갈라주는것은 D*G(x)로 나온다.
-
그러면 얘를 다시 generator에 집어넣게 되면, Jenson-shannon Divergence가 나온다.

우리의 실제 만든 데이터 distribution과 내가 학습한 generator과의 jenson-shannon divergence를 최적화하는 것이다 라고 말한다.
실제로 봤을때 discriminator를 수정하기 보장하기도 힘들고, 제너레이터가 이렇게 안나올 수도 있다. 이론적으로는 맞지만.
현실적으로는 좀의아 한 적이있다.
어떤사람 : GEN objective는 true generator distribution과 내가 학습하고 자 하는 generator와의 jenson-shannon Divergence를 최적화 하는거야.
라고 설명 할 수 있다.
DCGAN
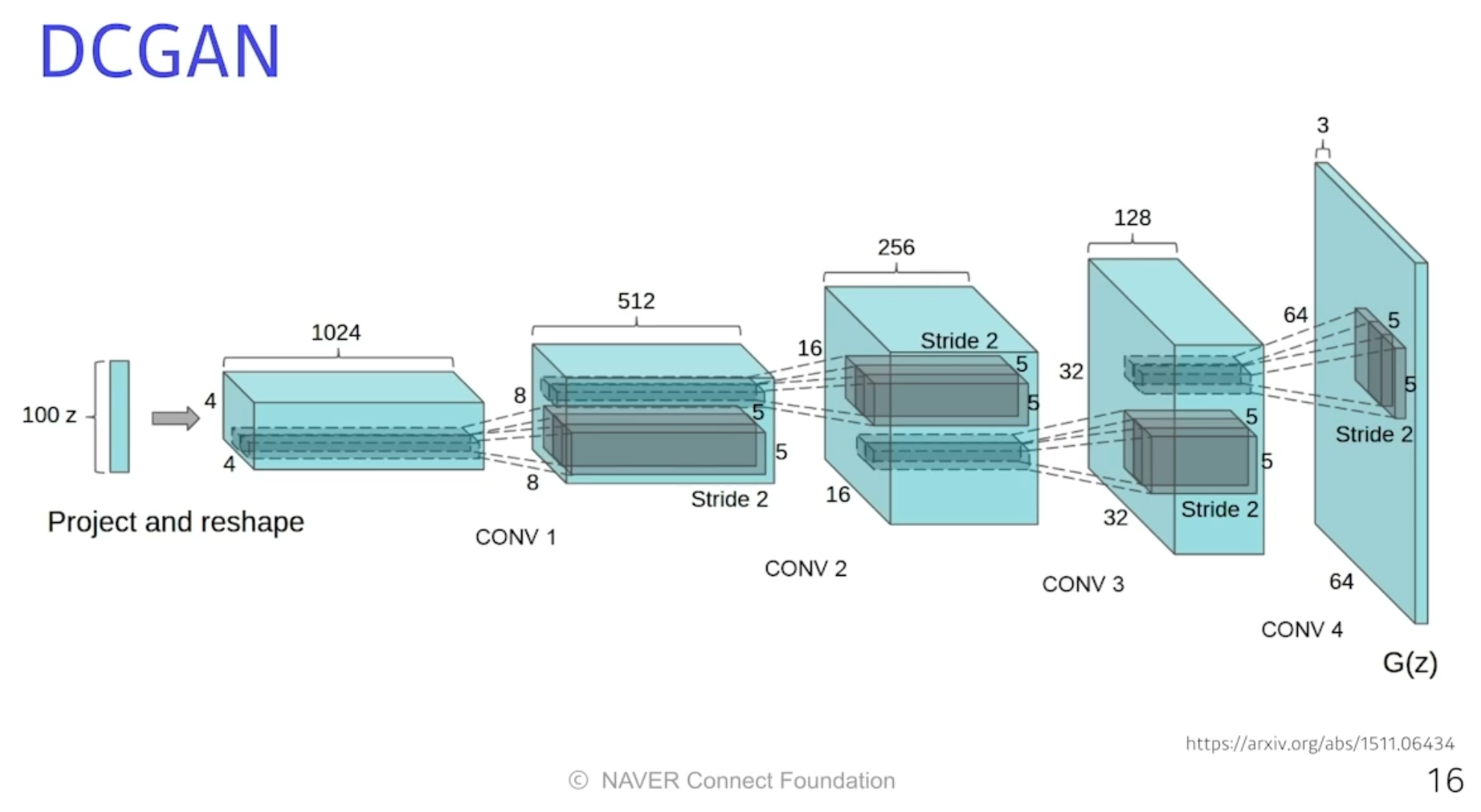
- 이미지 도메인을 사용해 활용했다.
info-GAN
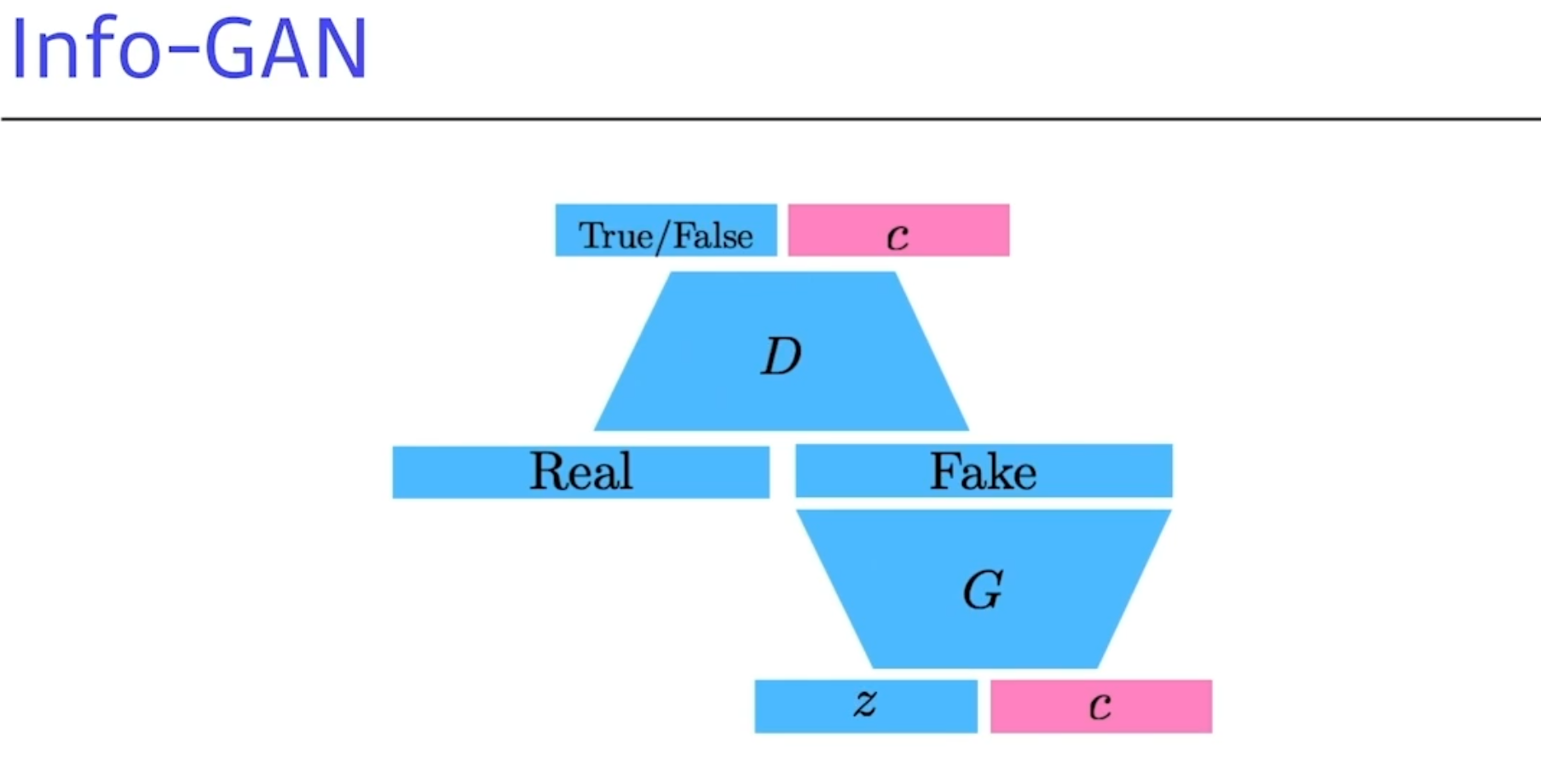
- Z라는걸 통해 이미지를 만드는게 아니라 C라고하는 Class를 랜덤하게 집어넣는다.
- generation을 할때 GAN이 특정 모드에 집중할 수있게 해준다.(C라고 하는 컨디션 배포)
Text2Image

- 문장이 주어지면 이미지를 만드는 것. 이 연구로 시작된 (OpenAI의 DALL-E 와 같음)
Puzzle-GAN
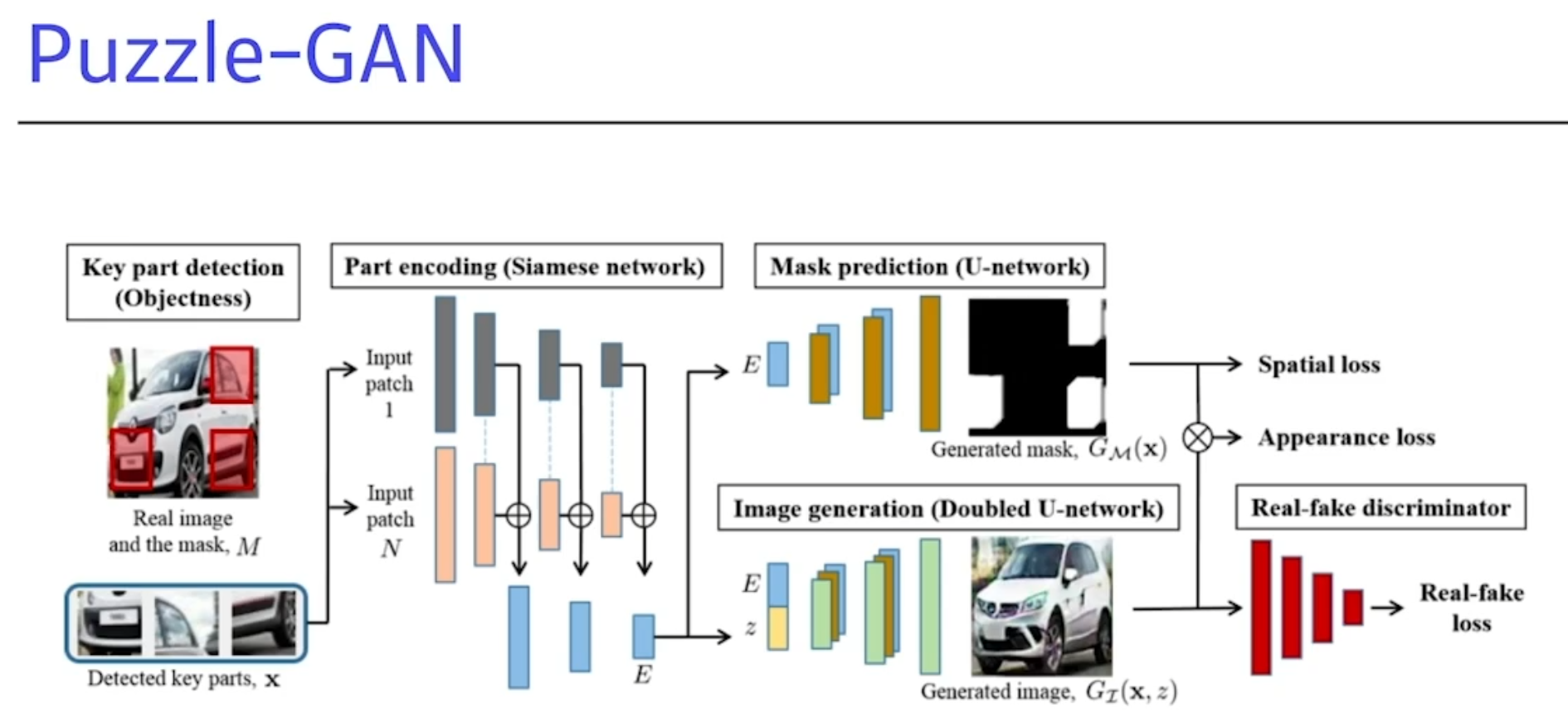
- 자동차의 sub-patch의 원래이미지를 복원하는걸 GAN을 통해서 구현하는것.
CycleGAN

- 이미지 사이의 도메인을 바꿀 수 있는것.
- 굉장히 중요하다.
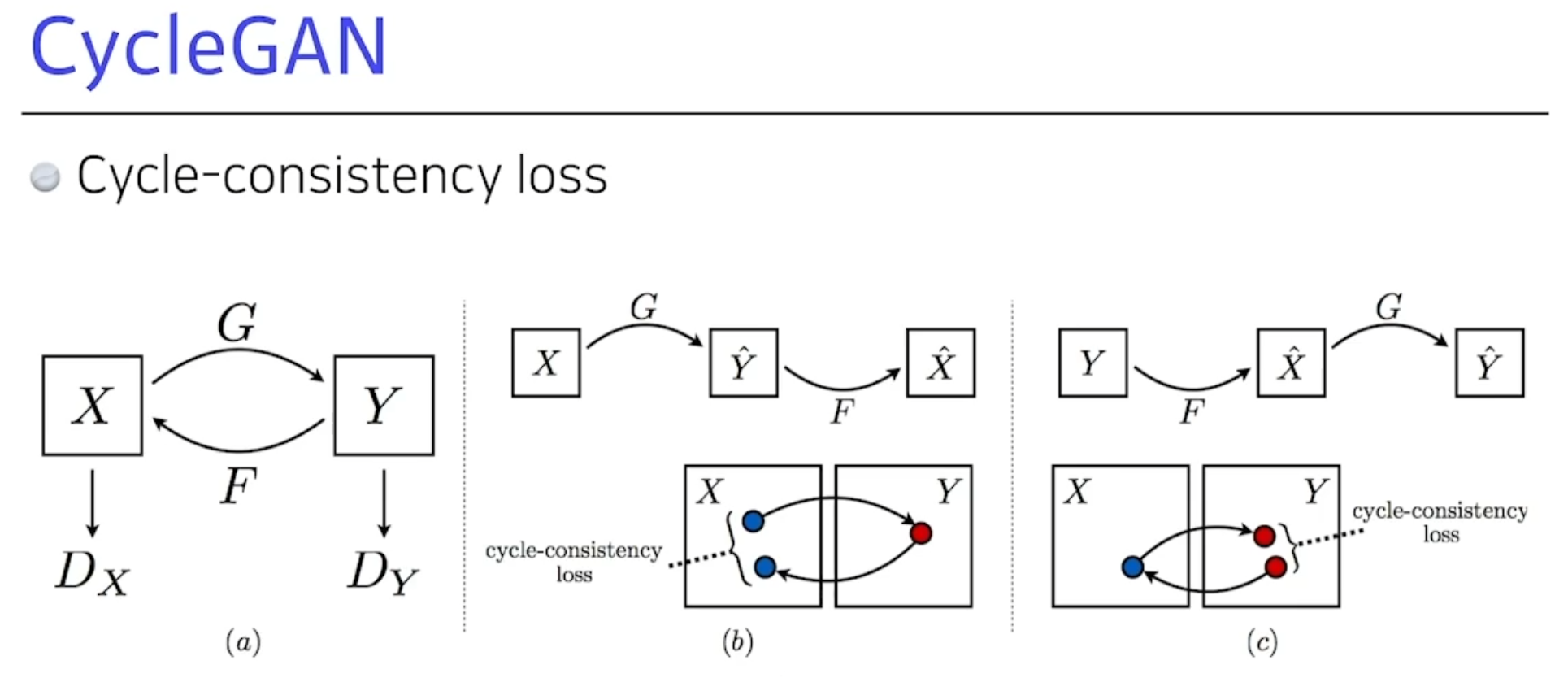
이녀석의 가장큰 장점:
- 말을 얼룩말로 바꾸려면 일반적으로 두 사진이 필요하는데
- 알아서 임의의 말을 얼룩말의 이미지로 바꿔준다.
Star-GAN

- 내가 도메인을 컨트롤할 수 있게 만들어준다.
GAN은 굉장한 고차원의 이미지를 만들어 낼 수 있다.
Progressive-GAN
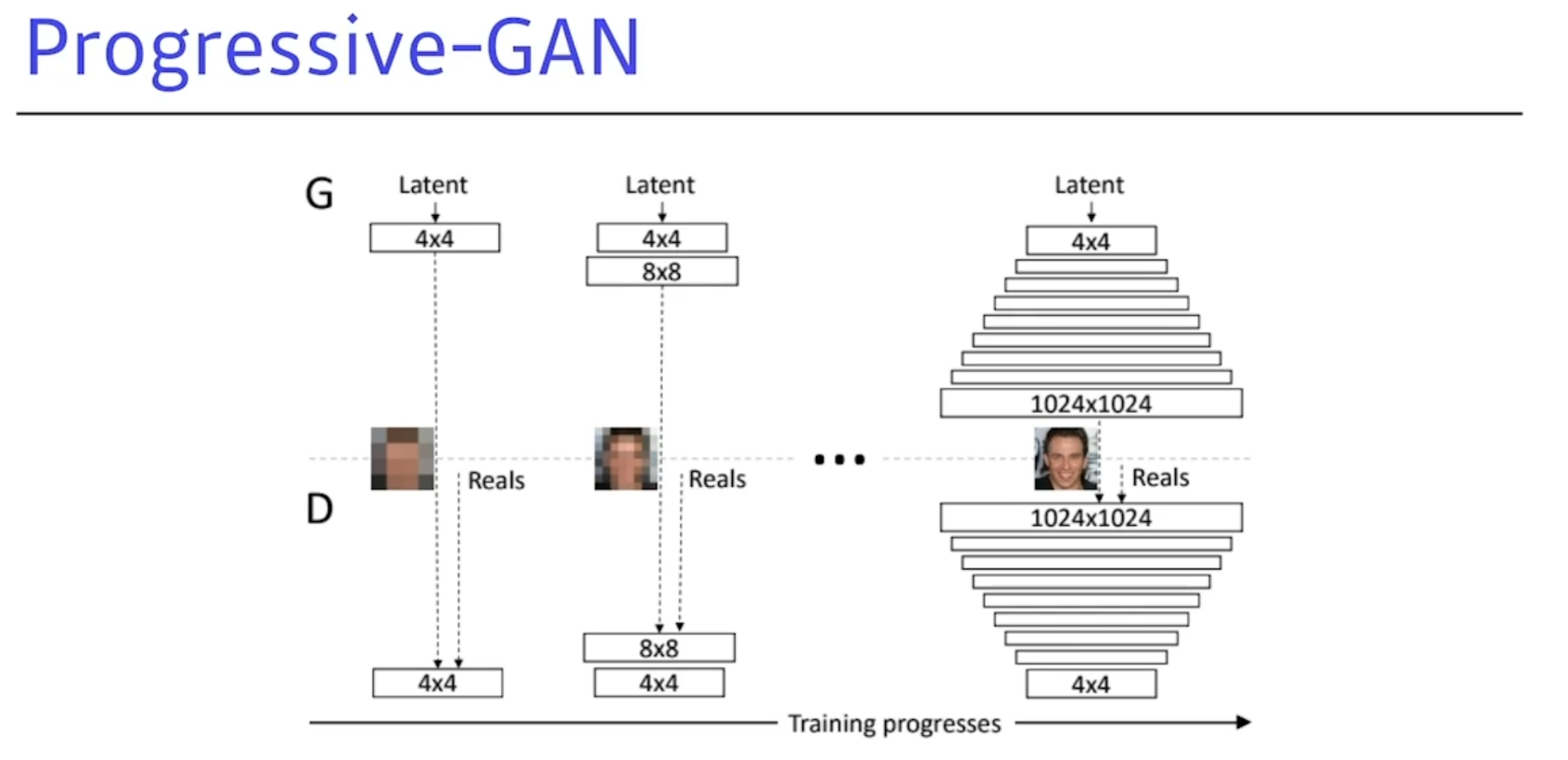
저차원부터 고차원까지 점점 늘려나가면서 학습을 시키는 트레이닝 방식이다.
굉장히 좋은성능의 하이 피델리티 이미지를 만들어 낼 수 있었다.
WAY MORE
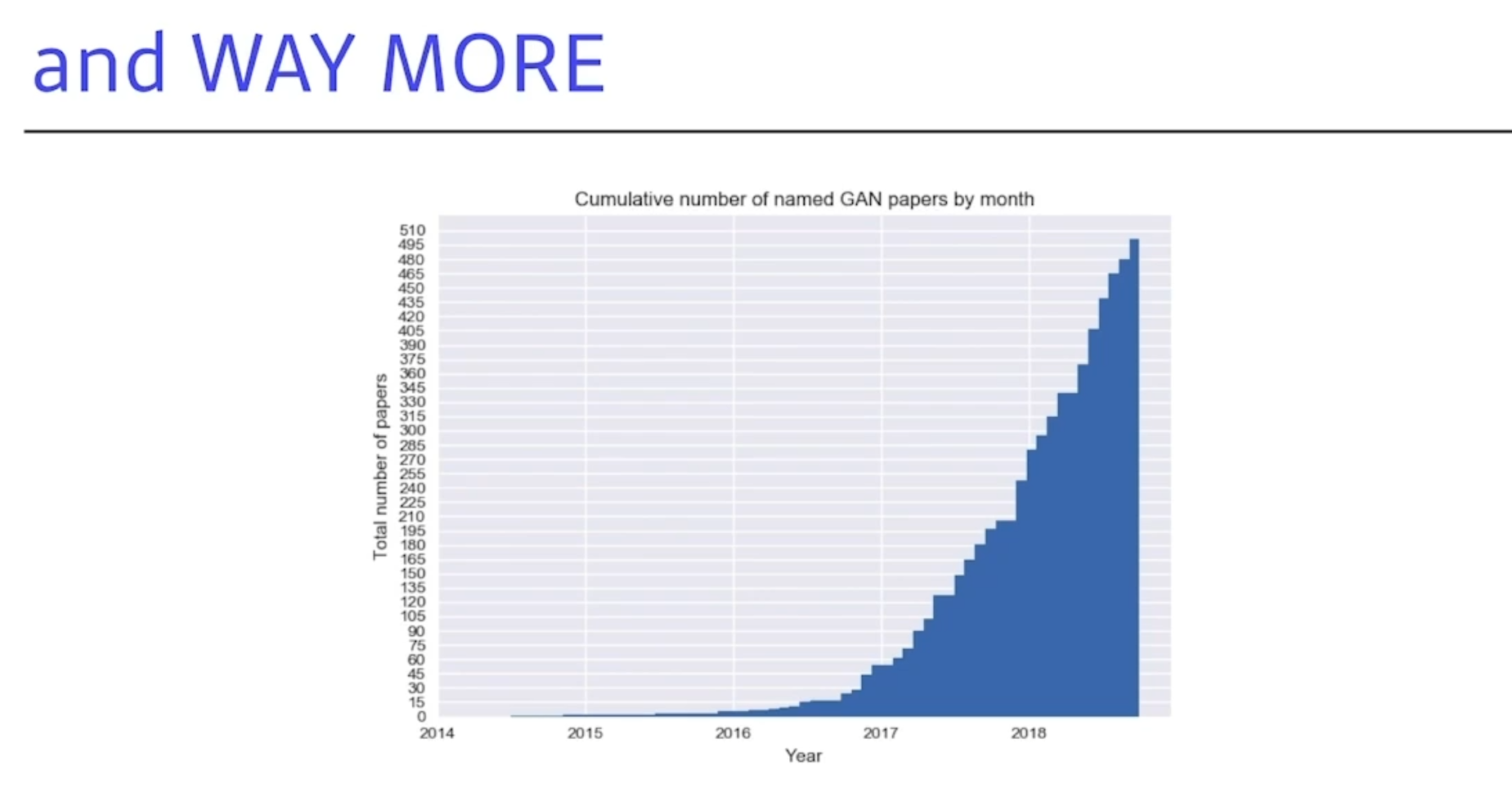
GAN의 논문들은 엄청나게 늘어나고있다.
다 이해하는것은 불가능하지만,OpenAI의 DALL-E 의 Transform을 쓰는게 어쩌면더 좋을 것 같다! 라고 생각하신다.(교수님왈)