AI 엔지니어 기초다지기
1.[네이버 커넥트재단] 2024년 상반기 AI 엔지니어 기초 다지기 합격

링크 : https://m.post.naver.com/viewer/postView.naver?volumeNo=37010051&memberNo=34635212&navigationType=push기간 : 24.1.15~24.2.27 (6주)목적 : AI엔지니어 실
2.AI 엔지니어 기초 다지기 - 1주차

pandas numpy 주피터 구글코랩 (많이편함) 현재 문제 주피터에 설치된걸 원활하게 적용못하겠다. 특히 특히나 불러올때 파일이름을 제대로 입력해주자. csv 불러올때 abc.csv 로 읽어오려고햇는데 실제 파일은 a b c.csv 였다. 2차시 > EDA는
3.구글 colab에서 구글드라이브 연동 경로
을 써주면된다 ! 해당 경로를 처음부터 /content로 시작하게 하는게 중요.
4.LightGBM에서 verbose_eval가 없다는 에러?
LightGBM 을 3.x.. 버전말고 4.x.. 를 사용하면 verbose_eval 대신에 num_boost_round로 사용한다고 나와있다.출처 : lightgbm.train — LightGBM 4.2.0.99 documentation
5.AI 엔지니어 기초 다지기 - 2주차
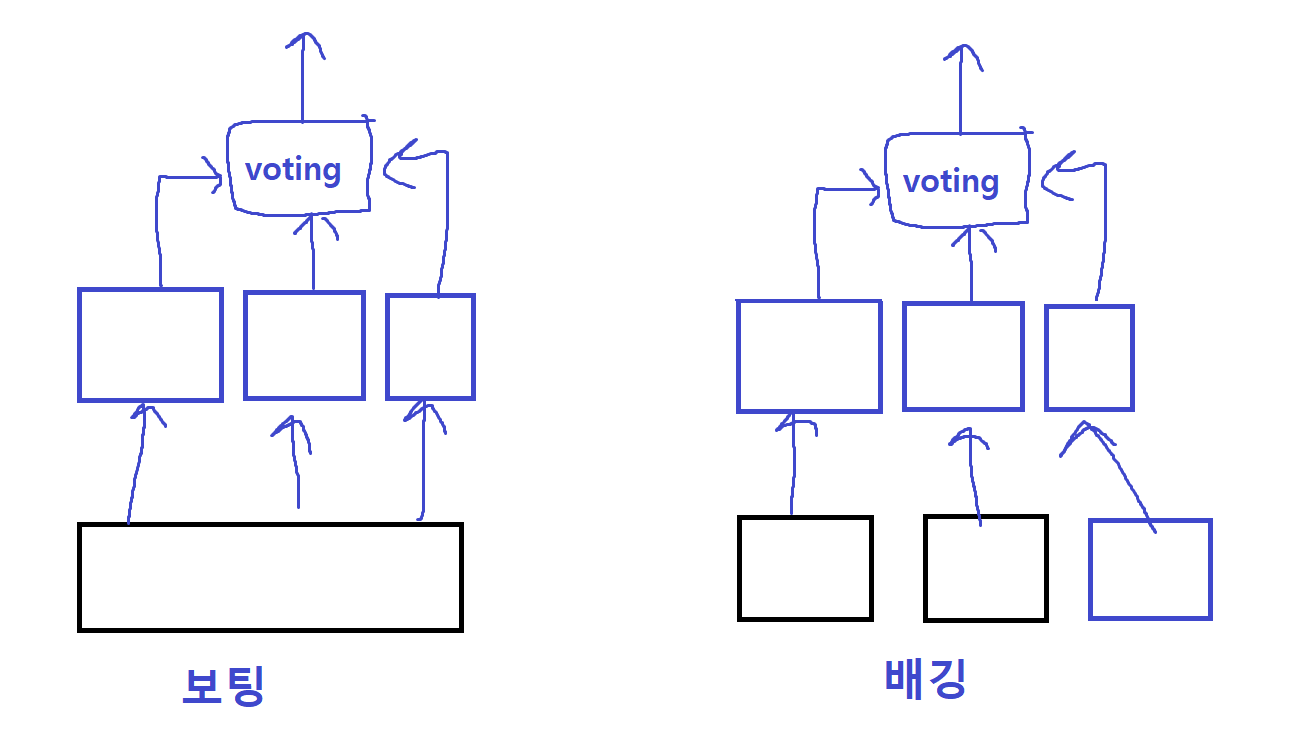
지금부터 조금 어려운 개념들이 나와서 조금씩 써보면서 공부해보려고한다. > 피처 엔지니어링 : 원본 데이터로부터 도메인 지식(특정주제나 전문 분야)등을 바탕으로 문제를 해결하는데 도움이 되는 를 생성, 변환하고 이를 머신러닝 모델에 적합한 형식으로 변환하는 작업
6.AI 엔지니어 기초 다지기 - 3주차 - 벡터
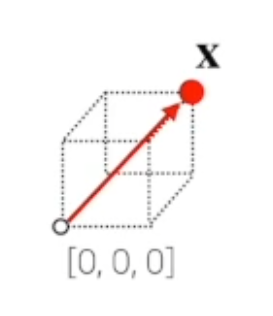
벡터는 숫자로 원소로 가지는 리스트 또는 배열 입니다. 벡터는 공간에서 한 점을 나타냅니다.벡터는 원점으로부터 상대적 위치를 표현합니다.원점 좌표에서 어떤 한점을 표현하는 화살표를 그림으로 표시하면!이런 개념으로 이루어져 있다. 어떠한 벡터에 스칼라(크기)를 곱하면 각
7.AI 엔지니어 기초 다지기 - 3주차 - 행렬

행렬은 벡터를 원소로 가지는 2차원 배열이다. 3개의 행벡터를 하나의 array 벡터에서 표현. 열벡터가 아니라 행벡터를 원소로 가진다고 생각하자.이후 행렬의 곱셈에서 더 이해하기 쉬워진다. 코딩테스트를 했으면 그대로 이해하면 될듯.행벡터와 열벡터를 부르는 방법을 익
8.AI 엔지니어 기초 다지기 - 3주차 - 경사하강법
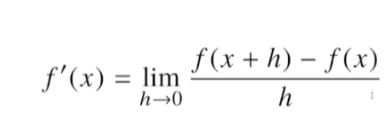
미분은 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구고등학교때 배웠던 극한의 개념.요즘엔 컴퓨터로 미분이 가능한 시대라 손으로 할 필요는 없다. 미분은 함수의 주어진 점(x,f(x))에서의 접선의 기울기를 구한다. 이 미분값의 양,음수에 따라 증가하고있나 감
9.AI 엔지니어 기초 다지기 - 3주차 - 딥러닝 학습방법
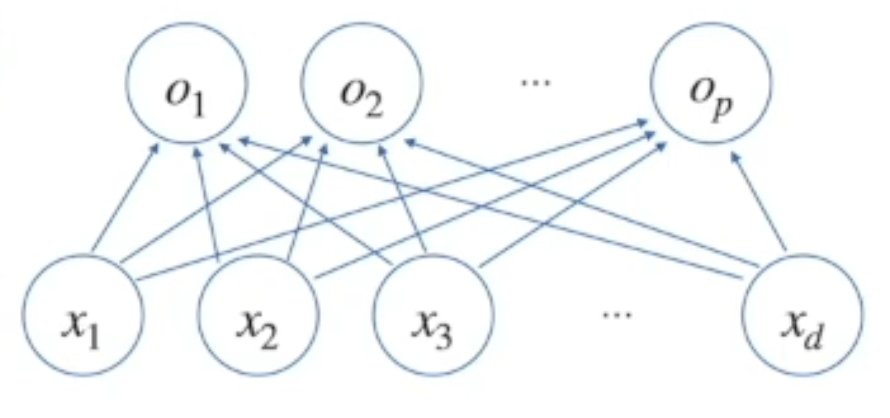
목적 : 신경망을 수식으로 분해해 보자. 지금까지는 선형모델을 사용했지만, 분류나 복잡한 패턴문제를 풀때는 선형문제만으로는 높은 예측을 하기는 어렵다. \-> 신경망 모델을 고려한다. (비선형 모델)각 행벡터 o, 데이터 x, 가중치 행렬 w, 절편 b벡터의 합으로 표
10.AI 엔지니어 기초 다지기 - 4주차 - 확률론 맛보기
확률론을 배워야하는이유 ? > - 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고있다. 기계학습에서 사용되는 손실함수 ( loss function)들의 작동원리는 데이터 공간을 통계적으로 해석해서 유도하게 된다. 회귀 분석에서 손실함수로 사용되는 L2노름은 예측오차
11.AI 엔지니어 기초 다지기 - 4주차 - 통계학 맛보기
헷갈리는 용어 정리 로그가능도 : > - 모수 : > - 최대가능도 : > - 정규분포 : > - 독립적인 표본 : > - 가중치 :
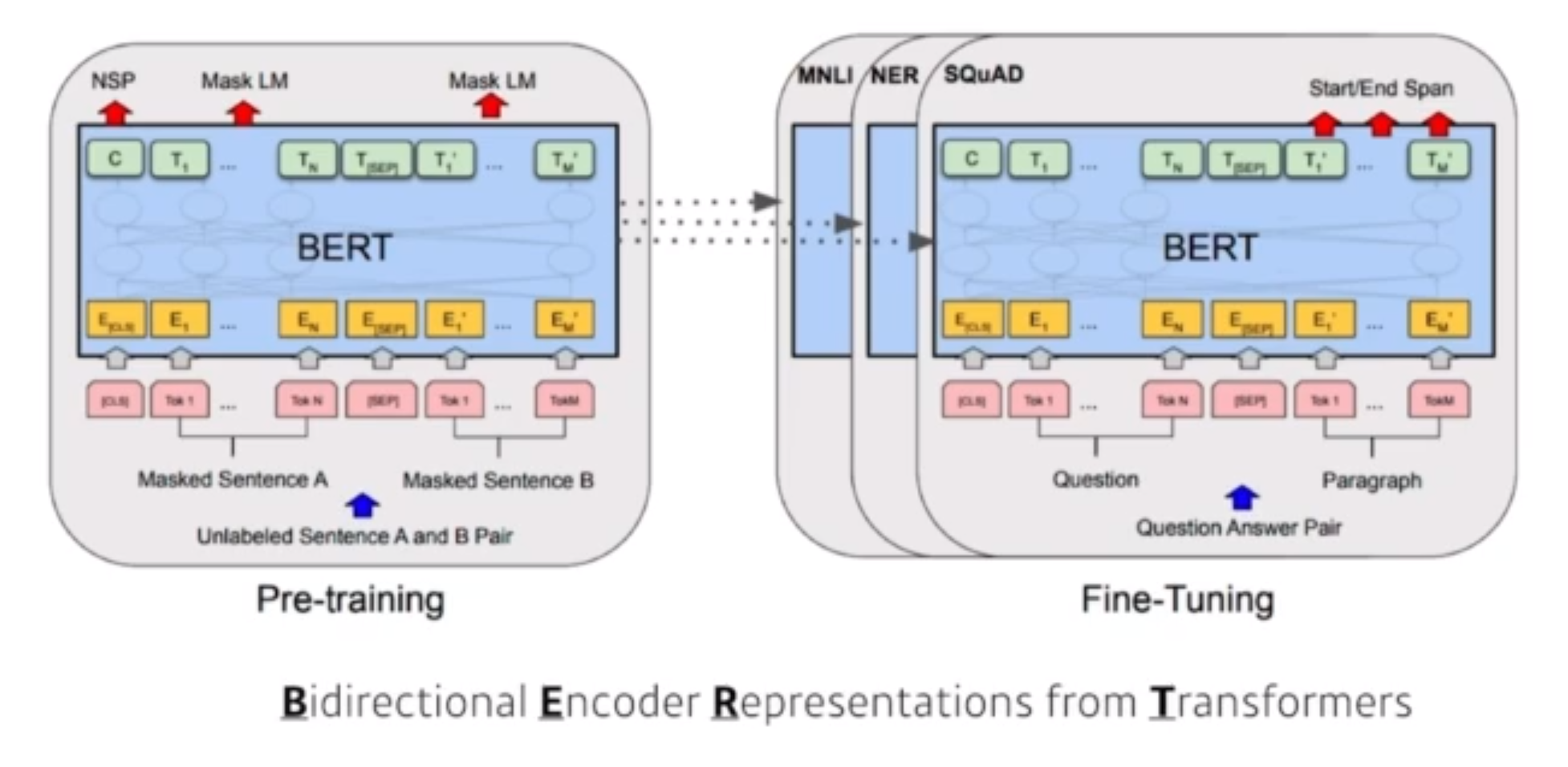
12.AI 엔지니어 기초 다지기 - 4주차 - 딥러닝 기본 용어 설명

딥러닝 이란?여러가지 분야가 존재하기에 일반적으로 3가지로 정의한다.구현실력Implementation Skills (예: Tensorflow, pytorch )수학적 실력Math Skills(Linear Algebra, Probability)최신논문 지식 Knowing
13.AI 엔지니어 기초 다지기 - 5주차 - Historical Review
딥러닝이란게 어떻게 지금의 위상을 가지게 됐나 알게되는 시간.Denny Britz 가 작성한 Historical Review 를 기반으로 설명한다.컨볼루전 네트워크 224x224의 이미지를 분류하기 위해 사용한다.이 알렉스넷 다음부터 deeplearning 블랙 매직?
14.AI 엔지니어 기초 다지기 - 5주차 - 뉴럴 네트워크 - MLP
뉴럴 네트워크란건 어떤건지?뉴럴 네트워크중에서 가장 간단한 구조인 Multi-Layer Perceptron이 어떤건지?딥러닝을 학습할때 학습이 어떤걸 가지는지? 알아보자.뇌신경망포유류의 신경망을 모방하고자 하는 시스템.사람의 지능을 모방하는 방법론이라고 굳이 설명할 필
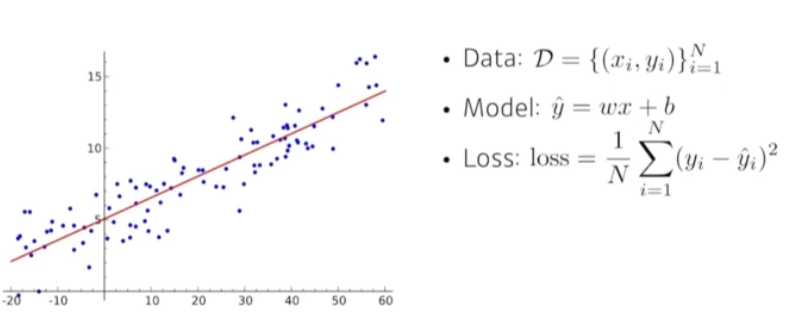
15.AI 엔지니어 기초 다지기 - 5주차 - 최적화의 주요 용어 이해하기
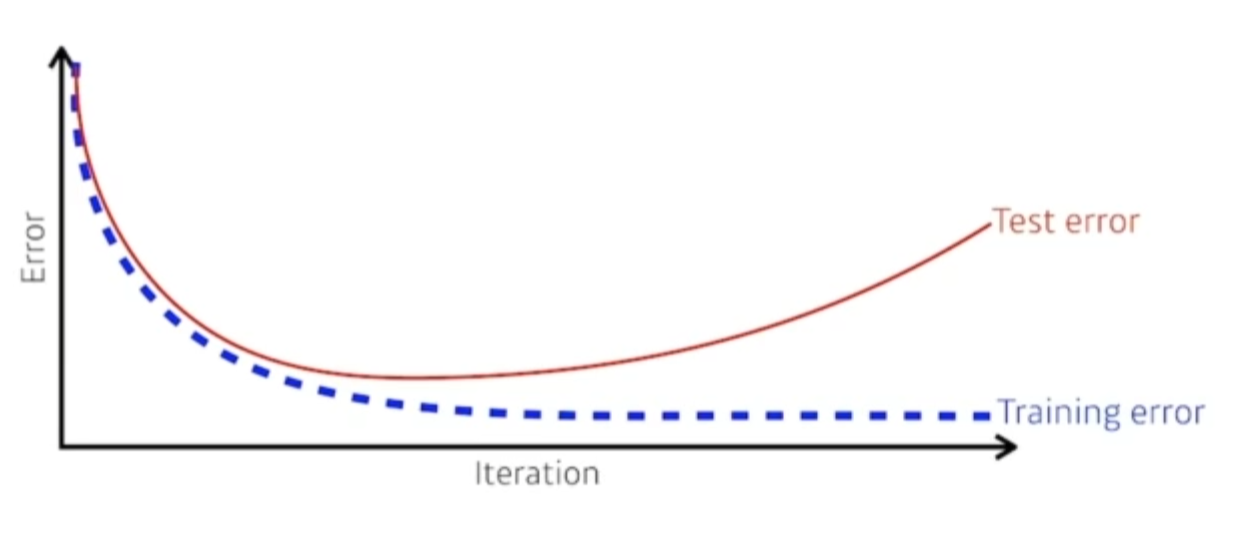
언어란 오해의 시작이다.반복적으로 최적화, 첫번째 미분을 계속 진행해서 최소값을 찾으러 간다.최적화에 대한 용어를 먼저 정리하겠다.일반화 성능많은 경우 일반화 성능을 높이는게 목적이다.그렇다면 일반화 성능이 뭘까?일반적으로 우린 학습을 시키면 학습데이터에 대한 트레이닝
16.AI 엔지니어 기초 다지기 - 5주차 - Gradient Descent Methods
Stochastic gradient descent10만개의 데이터가있으면 1번에 1번의 보개로 gradient를 구하고 업데이트 한다. Mini-batch gradient descent10만개를 다쓰거나 1개만 쓰는게 아니다. 일반적인 batch사이즈로 128개, 25
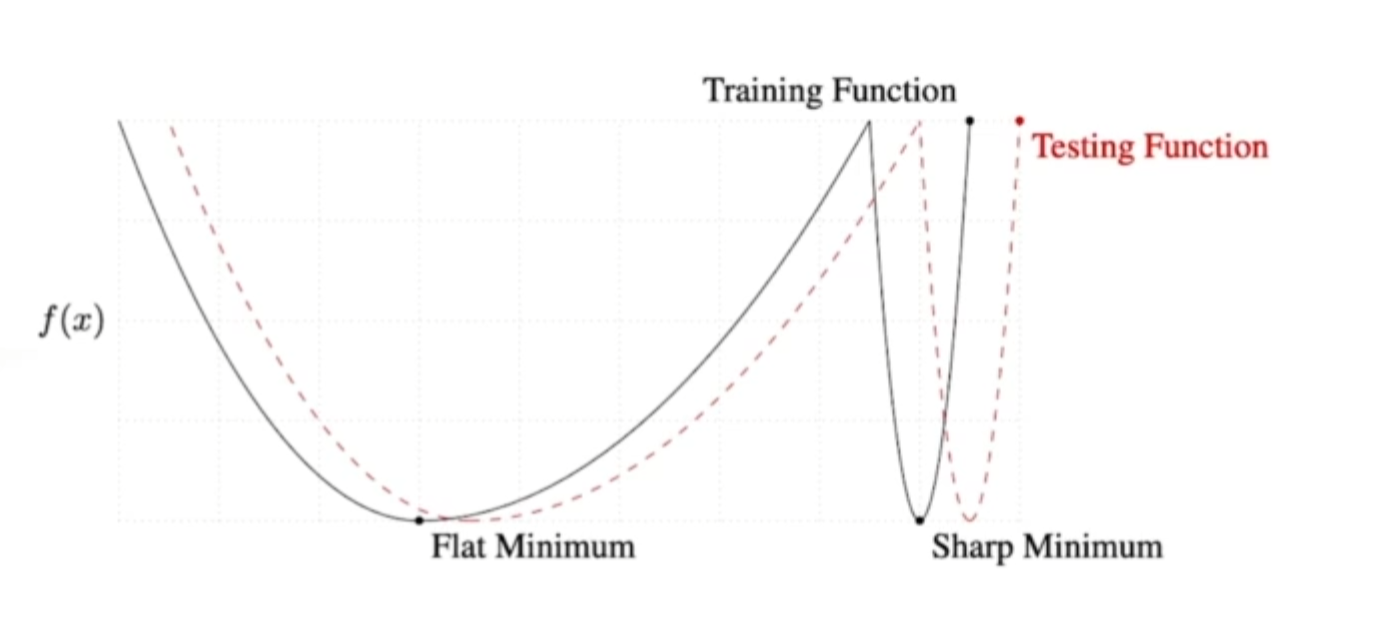
17.AI 엔지니어 기초 다지기 - 5주차 - Regularization
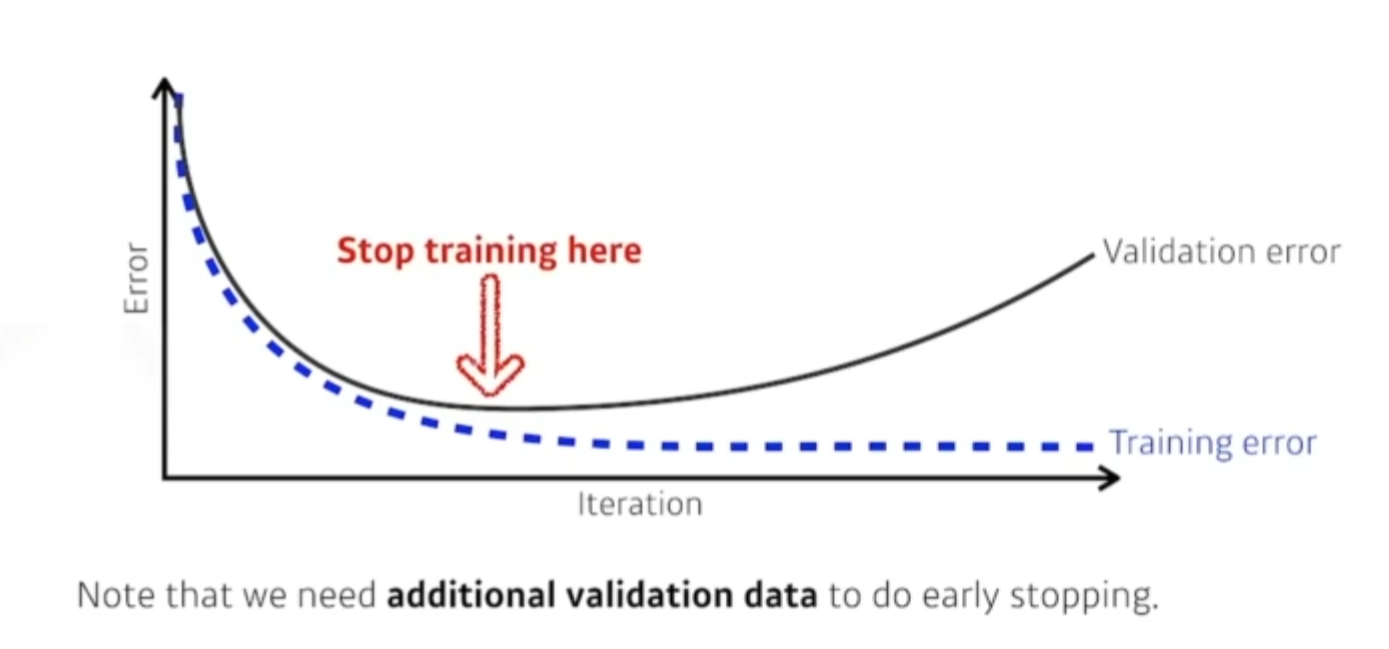
규제를 건다학습을 방해하는게 목적이다.학습데이터 뿐만아니라, 테스트 데이터에도 잘 동작 할수 있도록 만드는것.잘되고 있을때 멈추는 것. 너무 반복해서 Loss가 커지기전에. 뉴럴네트워크 파라미터가 너무 커지지 않게 하는것.네트워크 파라미터들을 다 제곱해서 더하면 큰숫자
18.AI 엔지니어 기초 다지기 - 6주차 - CNN - Convolution은 무엇인가?
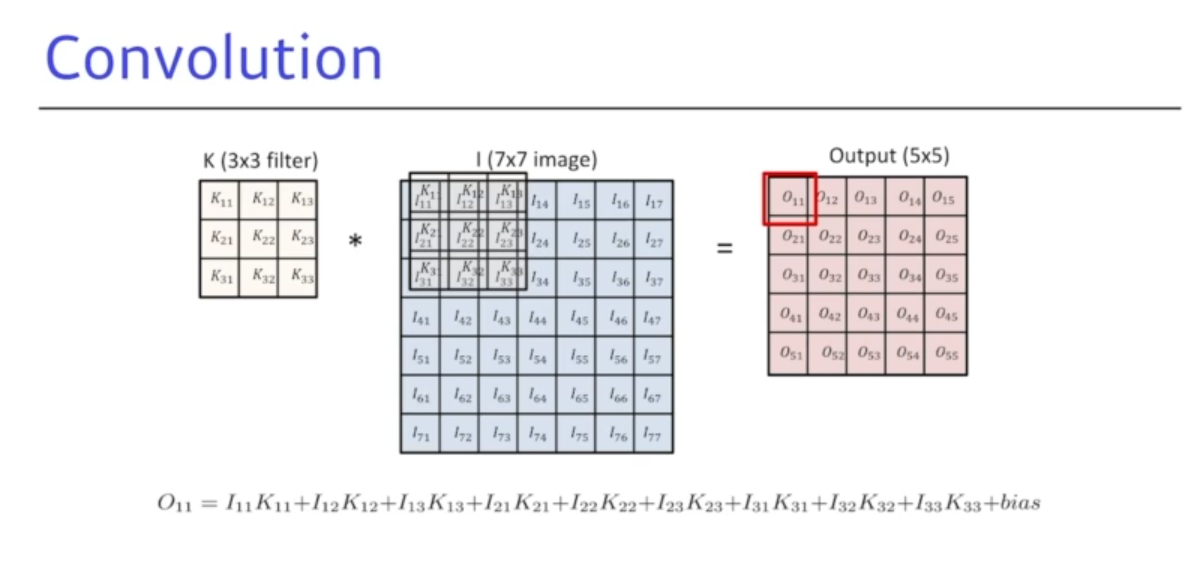
Convolution 이란?signal processing에서 두개의 함수가 있을때 f,g라는 함수를 잘 섞어주는 방법으로 정의한다. Discrete convolution2D image convolution일반적으로 가장 기본적인 컨볼루션을 사용하면 도장을찍는다, 찍는
19.AI 엔지니어 기초 다지기 - 6주차 - Modern CNN - 1x1 convolution의 중요성

모던 컨볼루션 뉴럴 네트워크모던이란 말은 좀 어폐가 있다.2018년도까지이기 때문에 상대적으로 가장 기본적인 CNN보단 모던하지만,완전 모던한 것은 아니다.우리는 총 5개의 네트워크를 볼 것이다. 해마다 1등을 했던 네트워크 ! 각각 네트워크의 파라미터 숫자, dept
20.AI 엔지니어 기초 다지기 - 6주차 - Computer Vision Applications
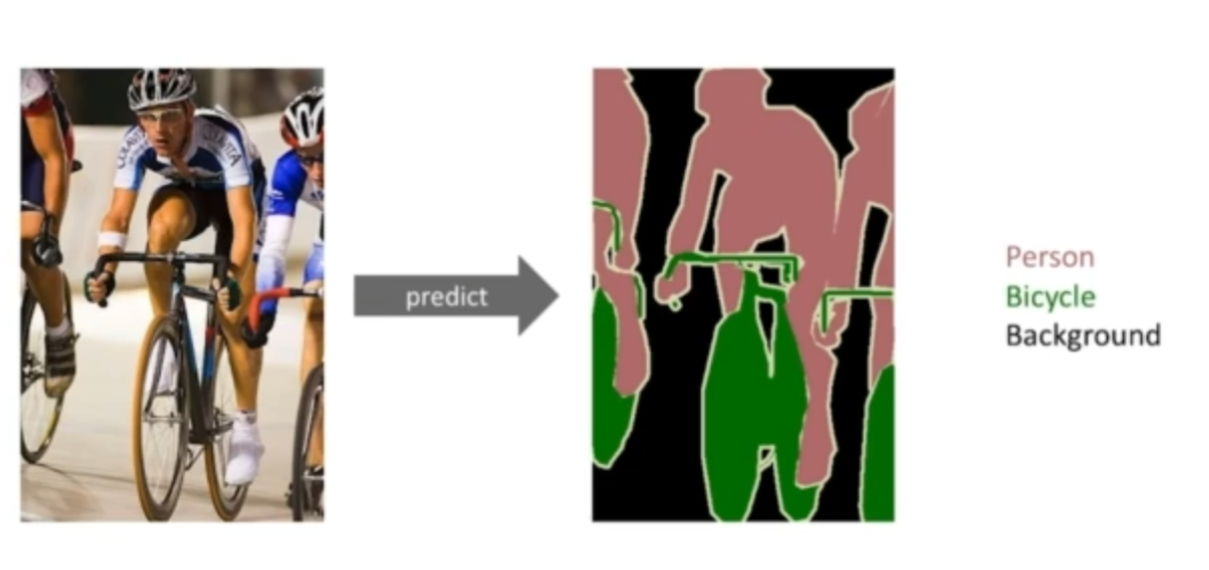
Semantic Segmentation(시멘틱 세그멘테이션)은 직역하자면 '의미론적인 분할'어떤 이미지가 있을때 각 이미지를 픽셀별로 사물을 분류해 내는것.이미지의 모든 픽셀이 어떤 라벨에 속하는지 보고싶다. 자율주행 문제에 많이 활용된다. 라이다와같은 센서를 활용하지
21.AI 엔지니어 기초 다지기 - 6주차 - Sequential Models - RNN
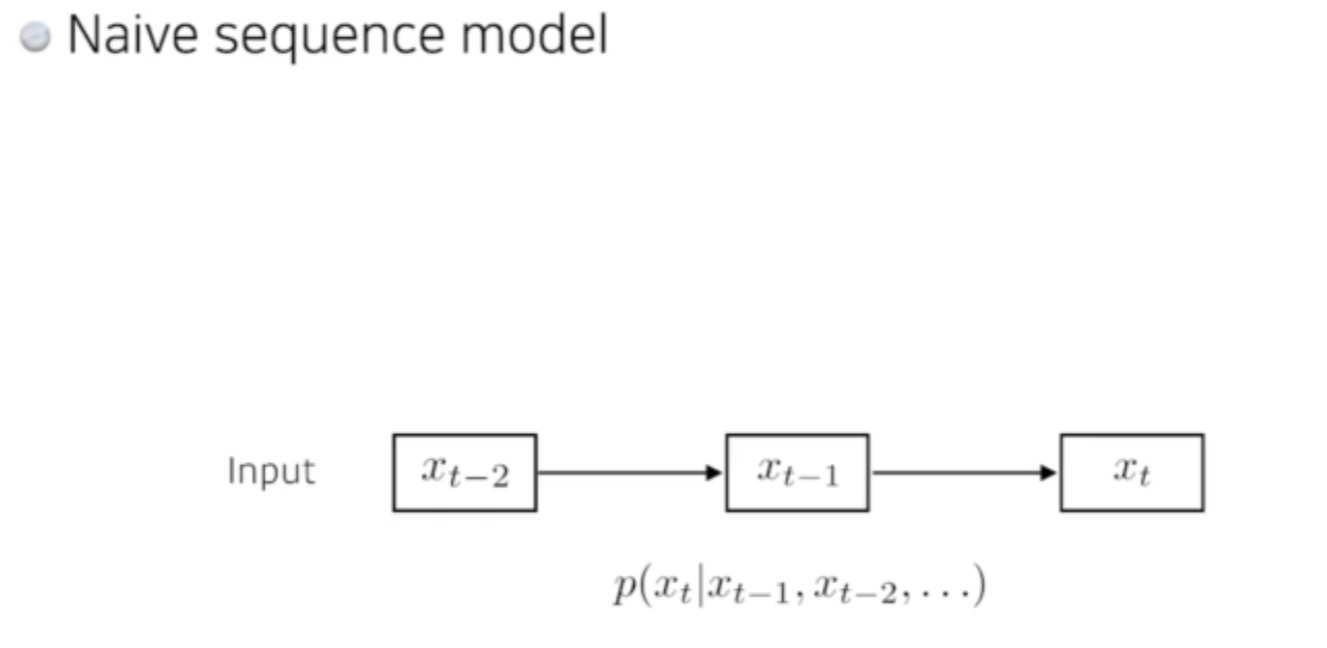
RNN은? 주어지는 입력이 시퀀셜 입력이다.(연속입력)Naive Sequence model일상생활하며 접하는 대부분의 데이터는 연속된 데이터이다. 연속된 데이터가 들어오기 때문에 FNC 를 사용할 수없는것임.몇개의 데이터가 들어오는지 모르기 때문.그래서 입력이 들어왔을
22.AI 엔지니어 기초 다지기 - 6주차 - Sequential Models - Transformer
연속적인 데이터를 다루는 모델이다. 이전 시간에서 배운 RNN의 lSTM 과는 살짝 다르다. 말로 문장을 말한다고 하면, 중간에 단어가 빠질수도있고, 중간 어순이 달라질 수도 있고 완벽한 대응구조가 아닐 수도 있다.트랜스포머는 RNN의 재귀적인 반복과는 달리, atte
23.AI 엔지니어 기초 다지기 - 6주차 - Generative Models 1

생성 모델이라고 하면 GEN 이 가장 유명하다! 수업에서 다룰 내용은 GEN방법론 보다는 머신러닝에서 Generative model이라고 하면 어떤걸 이야기 하는지, 어떤 trans 와 방법론이 있는지 이야기를 할 예정이다.
24.AI 엔지니어 기초 다지기 - 6주차 - Generative Models 2 - 마지막 수업

Latent Variable Models > 강력하게 추천드리는 이유 : Adam Optimizer를 만든분이 만든 모델 Autoencoder Variational Auto-encoder posterior distribution 을 찾는것이 목표다. variation
25. [AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정] 인공지능모델링 수료 !

수료후기: AI 를 처음 접하고 적용해보기에는 가장 부담없는 교육. 퀄리티 좋은 강의 및 과제.너무 어려운 수준의 코드 작성 요청을 요구하지 않아서 교육 난이도가 맘에 들었다.코치님들에게 질문할 수 있는게 좋았다. 하지만 답장이 빠르지 않아서 살짝 불만이였다. 아마 인