🧘♂️ CRDT의 데이터 구조를 정하자
📑 블럭CRDT, 텍스트CRDT?
앞서 우리 글래스모팀은 블럭형태, 텍스트형태로 CRDT를 나눠 LinkedList를 활용하기로 결정했다고 말씀드렸습니다.
이렇게 결정한 이유는
- 텍스트 CRDT 를 관리하는 LinkedList 구조
- 블럭 CRDT 를 관리하는 LinkedList 구조
위 두 구조를 병합하는 과정에서 CRDT에서 확장한 버전으로 관리하면, 더 효율적으로 마크다운 문법과 블럭 관리를 할 수 있을 것으로 생각하였습니다.
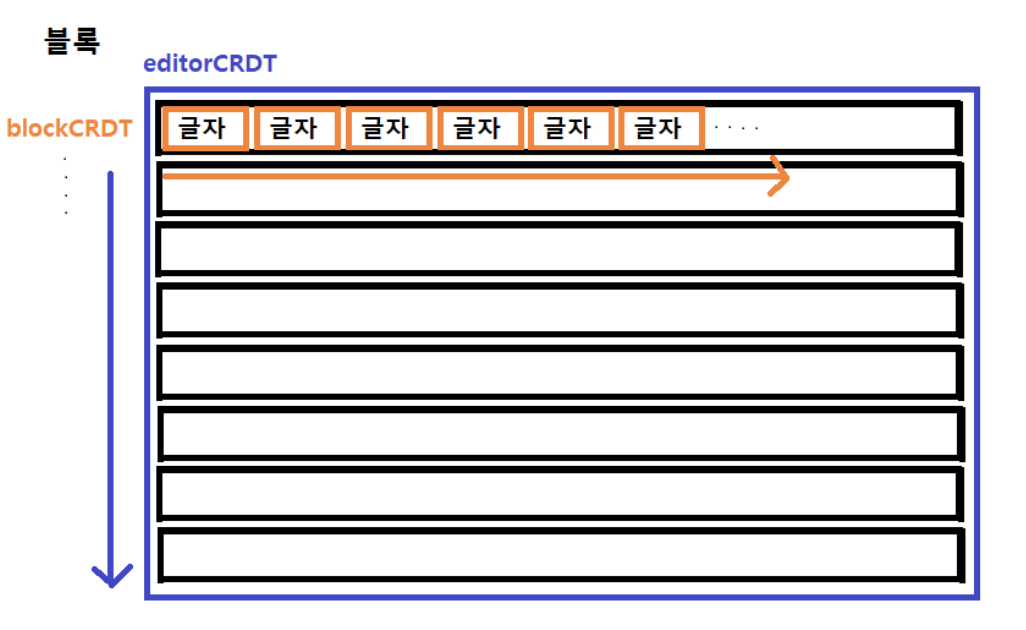
간단하게 보면 위 사진과 같습니다.
글자와 글자 사이에 들어가는 인덱스와 블록의 연결관계가 동일한 상태관리 유지에 매우큰 영향을 미칩니다.
우리팀은 각 텍스트마다 가지는 indext를 최대 3개만 가지게 설정했는데요. 3개 보다 큰경우는 일반적으로 사용하지 않을 것이라고 제한 하였습니다.
하지만 기존에 indent를 구현했던 방식에 확장이 어려운 문제가 발견됐습니다.
기존 블록의 구조
export interface EditorNode {
id: string;
type: ElementType;
content: string;
attributes?: Record<string, any>;
// 수평 연결 (같은 레벨의 노드들 간 연결)
prevNode: EditorNode | null;
nextNode: EditorNode | null;
// 수직 연결 (부모-자식 관계)
parentNode: EditorNode | null;
firstChild: EditorNode | null; // 배열 대신 첫 번째 자식만 참조
// 형제 노드 간 연결 (같은 부모를 가진 노드들 간 연결)
prevSibling: EditorNode | null;
nextSibling: EditorNode | null;
depth: number;
order: number;
listProperties?: ListProperties;
}- 위에 보면 그다음 형제 노드를 따로 매개변수로 저장하고 있었습니다.
- 만약 부모블럭을
drag&drop으로 옮긴다면, 자식요소들도 같이 따라가 줘야합니다. - 이때
while을 통해 형제 노드들을 탐색해서 찾아줘야 했는데요. - 이 과정에서 수직연결 parentNode와 firstChild 노드를 전부 끊어주고 다시 붙여줘야하며, 이 과정에서 코딩 구현의 번거로움이 컸습니다.
- 그래서 더 효율적인 방법으로 인덱스를 관리하고, 마크다운 에디터에 필요한 체크박스, 순서리스트, 일반리스트 등을 표현할 방법을 찾게 되었습니다.
블럭의 구조를 변경
기존에는
- 리스트를
<ul>
<li>로 변경하며 html을 조작하는 과정이 필요했습니다.
그리고 <ul> 들 끼리 연결도 시켜줘야했죠.
하지만 좀더 쉽게 개선하기 위해서
<Block indent=1 type="list" icon="list"/>- 의 형태로 전환하기로 했습니다.
이방식으로 블럭을 구현하면 추후 다양하게 확장할 수 있을 것으로 보였습니다. 특히 선택을 한 Block 을 기준으로 indent 탐색을 진행하면 되고, 블록의 복잡한 연결관계를 다시 맞춰줄 필요가 없이 단순히 순서만 지정해주면 되었습니다.
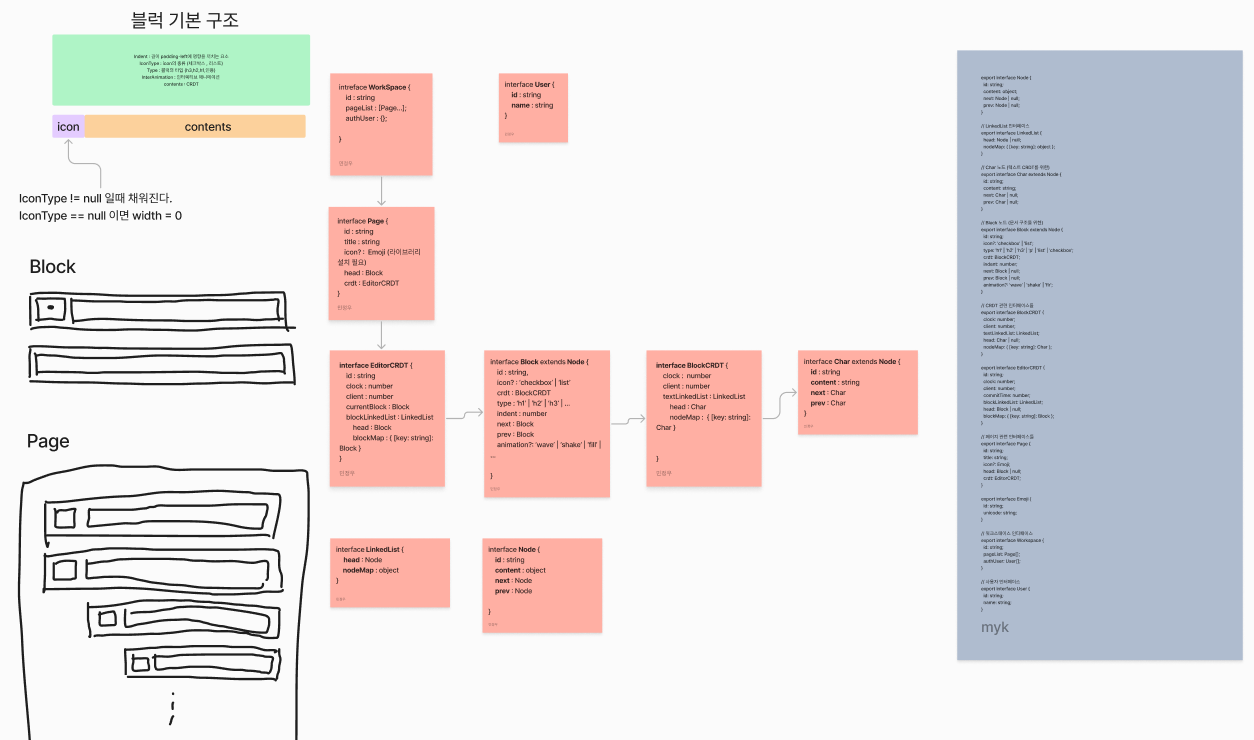
그래서 우리 글래스모 팀은 위 블럭구조의 이해관계를 맞추고 figjam 에서 필요한 자료구조와 이해상황을 통일한 뒤, 이를 기반으로 interface 구조를 작성했습니다.
위 두사항들이 반영된 동작화면은 아래와 같습니다.

이제 좀더 자세하게 CRDT의 데이터 구조에 대해 정해보겠습니다.
👩💻 CRDT 데이터 구조
CRDT 데이터 구조 명명
CRDT는 다중 중첩 링크드리스트 형태를 가지고 있습니다.
이를 JSON객체로 표현할 수 있는데요
아래는 노션의 토글을 이용해 JSON객체처럼 나타내 본 모습입니다.
- CRDT (블럭)
- Clock: 10
- Client: 1
- LinkedList
- Head:
{ clock: 1, client: 1 } - NodeMap
- 1-1
id:{ clock: 1, client: 1 }value: "H"next:{ clock: 2, client: 1 }prev:null
- 1-1
- Head:
- CRDT (노드)
- id: { clock: number, client: number}
- value: string
- next: Node
- prev: Node
- indent: number
또한 우리는 명명을 할때 맨 앞에 접두사를 붙이기로 결정했습니다.
그이유는 CrdtBlock, CrdtText 또는 CRDTBlock, CRDTText의 경우 대문자가 중첩되거나 crdt가 먼저 눈에 들어와서 요소의 주체를 먼저 알기 어렵다고 판단했습니다.
{접두사}+ CRDT
접두사 : CRDT를 활용하는 주체
예 :
- EditorCRDT = 에디터에 있는 CRDT로
Block을 관리 - BlockCRDT = 블럭에 있는 CRDT로
Text를 관리
실제 CRDT 데이터 구조
간단하게 @noctaCRDT 에 사용하는 데이터 구조를 확인할 수 있습니다.
- Editor CRDT (페이지 안의 블럭들을 관리하는 CRDT)
- Clock: 10
- Client: 1
- CurrentBlock: BlockId
- BlockLinkedList
- Head: NodeId
- NodeMap
- 1-1
id:{ clock: 1, client: 1 }type: ElementTypevalue: Block CRDTnext:{ clock: 2, client: 1 }prev:nullindent:0
- 1-1
- Block CRDT (블럭 안의 텍스트를 관리하는 CRDT)
- TextLinkedList
- Head:
{ clock: 1, client: 1 } - NodeMap
- 1-1
id:{ clock: 1, client: 1 }value: Textnext:{ clock: 2, client: 1 }prev:nullindent:0
- 1-1
- Head:
- currentCaret
- TextLinkedList
- Page
export class Page { id: string; title: string; icon: PageIconType; crdt: EditorCRDT; - Block
export class Block extends Node<BlockId> { type: ElementType; indent: number; animation: AnimationType; style: string[]; icon: string; crdt: BlockCRDT; listIndex?: number; isChecked?: boolean;
내부 메소드
처음 설계했던 당시에 insertById 나 spread 와 같은 자주 사용될 메소드들이 필요할 것이라고 지레 짐작을 햇었습니다.
하지만 실제 사용해보니 생각보다 많은 메소드들이 필요했습니다.
그중 꽤많은 시간이 걸렸던게 바로
직렬화, 역직렬화 입니다.
직렬화, 역직렬화
글래스모팀은 마치 redis 역할을 하는 것처럼 clinet와 server 내부에 @noctaCRDT에서 만들어진 클래스들의 상태를 일치시키며 상태를 동기화 하고 있습니다.
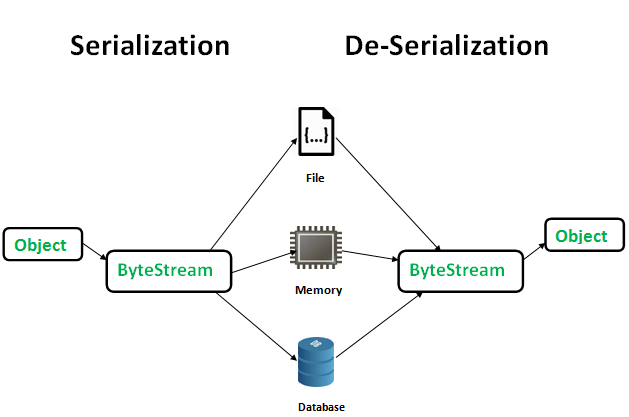
이때 client → server 로 데이터를 보낼때 클래스요소를 그대로 담아 보낼수 없습니다.
그래서 클래스 내부에 있는 값들을 JSON 형태로 변경하여 객체로 전달해야 했습니다.
이과정을 직렬화(serialization)로 부르며 반대로 JSON 데이터를 다시 클래스에 사용할 수 있게 하는 것을
역직렬화(deserialization) 이라고 부릅니다.
이 직렬화와 역직렬화 과정에서 데이터 에러가 많이 발생했습니다.
특히나 caret을 관리하기가 많이 까다로워 졌습니다.
useEffect(() => {
if (!editorCRDT || !editorCRDT.current.currentBlock) return;
const { activeElement } = document;
if (activeElement?.tagName.toLowerCase() === "input") {
return; // input에 포커스가 있으면 캐럿 위치 변경하지 않음
}
if (isLocalChange.current || isSameLocalChange.current) {
**setCaretPosition({
blockId: editorCRDT.current.currentBlock!.id,
linkedList: editorCRDT.current.LinkedList,
position: editorCRDT.current.currentBlock?.crdt.currentCaret,
pageId,
});**
isLocalChange.current = false;
isSameLocalChange.current = false;
return;
}
}, [editorCRDT.current.currentBlock?.id.serialize()]);특이점 : 우리 Nocta는 server에 캐럿을 저장하지 않는다.
우리팀은 Caret을 각 클라이언트 마다 관리를 하고 있습니다.
그 이유는
- 캐럿의 위치 주고받을 경우 서버의 부하 예상
- 낙관적 업데이트로 인해 캐럿위치 선반영
특히 1번이 가장 컸고 2번의 경우 이미 2번을 반영해서 개발을 진행해 오고 있었습니다.
우리는 추후에 동일한 블럭에서 caret위치 초기화 문제 라는 아주 큰 문제를 겪으며 caret을 서버에 저장해보기위해 시도하지만, 결국 6주안에 해결하지 못하는 원인이 됩니다.
이 문제를 바로 해결하지 못한 원인도 이 직렬화, 역직렬화 과정에서 caret위치를 자동으로 계산해 판단하는 알고리즘이 너무 많이 들어가 있었기 때문입니다.
하지만
연산만 주고 받는다면서.. 역직렬화 이런게 왜 필요하죠?
라고 하실 수도 있습니다. 하지만 server ↔ MongoDB를 저장하기 위해선 server의 상태를 JSON 화 하여 객체로 저장해 주어야 합니다.
그리고 연산을 주고받는 것 뿐만이 아니라 page를 새롭게 킬때 page의 상태를 서버로부터 받아와야 하기 때문에 역직렬화가 필요한 부분도 있었습니다.
간단한 역직렬화 스토리보드를 살펴볼까요?
- 클라이언트가 page를
open합니다. - 서버로부터 새로운 page 인스턴스 상태를 전달 받습니다.
- 인스턴스 상태를 역직렬화 하여 클라이언트의 상태에 반영합니다.
이 과정에서 클래스 내부에 currentCaret이라는 값을 가지고있는데요.
이 값들 역시 remoteInsert 등을 통해 1번 클라이언트의 caret 값을 갱신시키며 관리해 오고 있습니다.
하지만 caret 이 클라이언트 유저에 의해 빈번하게 바뀌거나 아직 클라이언트에 반영되지 않은 입력값이 들어오면 캐럿이 0으로 초기화 되는 문제가 발생했습니다.
0으로 초기화 시키지 않으면 node가 없다는 error가 발생했습니다.
자세한 트러블 슈팅은 아래를 참고해주세요..!
🏋️♀️ 느낀 점
이처럼 CRDT 데이터 구조를 만들며 많은 것들을 알게 되었습니다.
직렬화, 역직렬화, 효율적인 구조, 현재까지 개발한 데이터 구조를 최대한 해하지 않고 동작하도록 고려하는 것, 기술 원리에 대한 근본적인 의구심..
결국 이 모든것은 유저의 사용성을 최대로 끌어올리기 위해 필요한 것이고, 개발자는 추후 확장 가능성을 염두한 개발이 매우 중요하구나를 알게 되었습니다.
좋은 점
- 우리가 설계한 대로 서비스가 동작하는걸 보며 팀원들도 많은 동기부여와 사기를 얻었습니다.
- 최대한 완성도를 높이기 위해 20개가 넘는 예외처리를 진행했습니다.
- 팀원들과 CRDT에 관한 이해상태를 페어프로그래밍을 진행하며 많이 맞추었습니다.
아쉬운 점
- 매우 잦은 CRDT의 데이터 구조를 거치며 초기설계의 중요성을 많이 느끼게 되었습니다.
- 급하게 예외처리를 진행하며 코드의 가독성이 많이 떨어지게 되었습니다.
- 근본적인 원인 문제를 파악하지 못한점이 아쉬웠습니다. (node가 없다고 error가 뜨는 건 crdt에서 일어날 수 없다)
- 너무 많이 수정을 해야할 것 같아 기술부채를 남긴점
다음은 CRDT의 완성도를 위한 개선 작업과 트러블 슈팅을 정리하며 마무리 해보겠습니다.