4.5.1 인덱스의 필요성
- 인덱스 : 데이터를 빠르게 찾을 수 있는 하나의 장치
- 인덱스 구성 파일
- 데이터 파일 : 실제 레코드를 저장하고 있는 파일
- 인덱스 파일 : 레코드들에 대한 포인터를 가지고 있는 파일
4.5.2 B-트리
- 인덱스는 보통 B-트리라는 자료 구조로 이루어져 있다
루트 노드,리프 노드, 루트 노드와 리프 노드 사이브랜치 노드로 나뉜다.- 특정 노드의 왼쪽 서브 트리는 특정 노드의 key 보다 작은 값들로, 오른쪽 서브 트리는 큰 값들로 구성
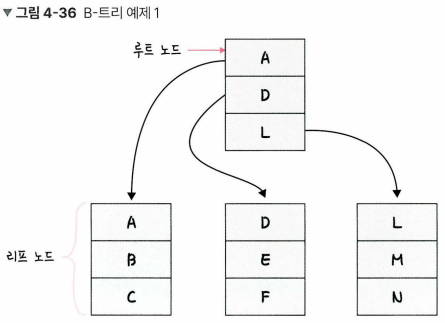
- E를 찾는다고 하면, 전체 테이블 탐색이 아니라 E가 있을 법한 리프 노드로 들어가 E를 참색
- 이 자료구조 없이 E를 탐색하고자 하면 A, B, C, D, E 다섯 번 탐색해야 하지만 이렇게 노드들로 나누면 두 번만에 리프 노드에서 찾을 수 있음
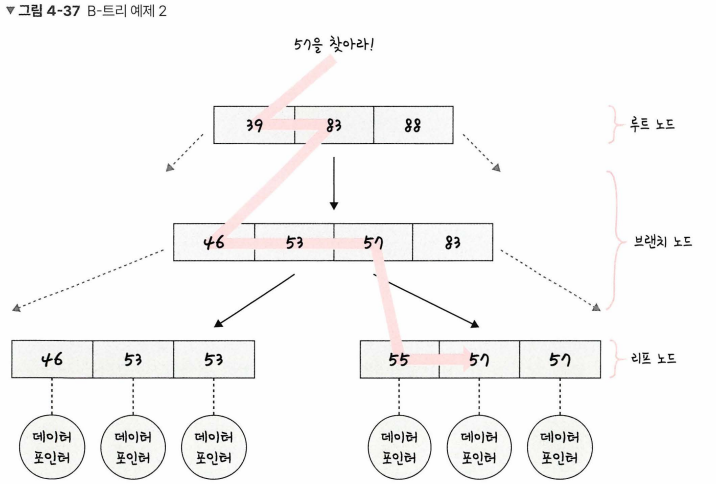
- 57을 찾는다고 할 때, 트리 탐색은 맨 위 루트 노드부터 탐색이 일어나며 브랜치 노드를 거쳐 리프 노드까지 내려온다.
인덱스가 효율적인 이유와 대수확장성
- 인덱스가 효율적인 이유 : 효율적인 단계를 거쳐 모든 요소에 접근할 수 있는 균형 잡힌 트리 구조와 트리 깊이의 대수확장성 때문
- 대수확장성 : 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것. 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가한다.
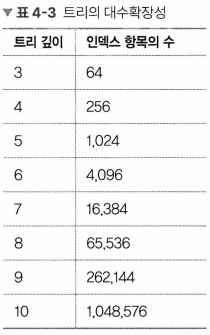
- 앞의 표처럼 트리 깊이는 10개짜리로, 100만개의 레코드를 검색할 수 있다.
- 참고로 실제 인덱스는 이것보다 훨씬 더 효율적이며, 그렇기 때문에 인덱스가 효율적이다.
4.5.3 인덱스 만드는 방법
- MySQL, MonggoDB 기준 설명
MySQL
- 클러스터형 인덱스와 세컨더리 인덱스(보조 인덱스)가 있음
클러스터형 인덱스 : 레코드들의 물리적인 저장 순서가 인덱스 순서와 동일하게 되도록 구성된 인덱스
- 인덱스의 리프 노드가 곧 데이터 레코드.
- 인덱스 자체에 데이터가 포함됨
- 사전과 유사
- 보조 인덱스보다 검색 속도 빠름
- 동일하거나 인접한 키 값 가진 레코드들은 물리적으로도 인접하게 저장되어 성능 향상
- 데이터의 입력/수정/삭제는 더 느림
- 테이블당 하나 설정 가능
- 테이블 생성 시 기본키에 대해 클러스터 인덱스를 자동으로 생성
- 기본키를 지정하지 않으면 먼저 나오는 UNIQUE 속성에 대해 클러스터 인덱스 생성

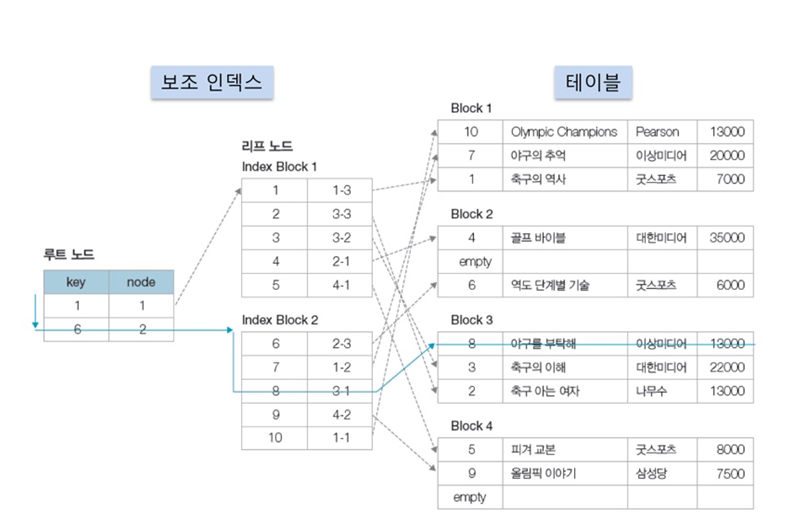
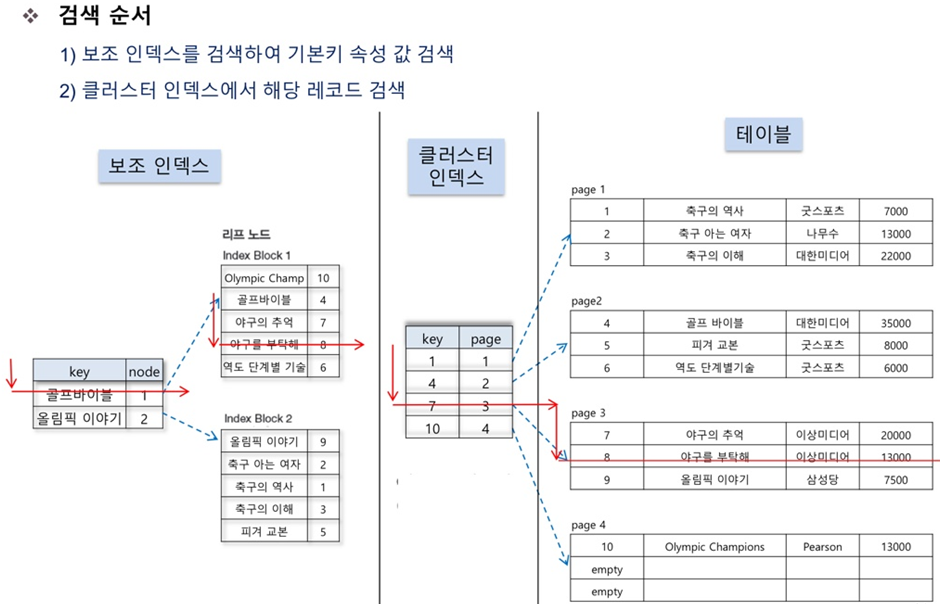
세컨더리 인덱스(보조 인덱스)
- 클러스터 인덱스가 아닌 모든 인덱스
- 보조 인덱스 생성시 별도의 페이지에 인덱스 구성
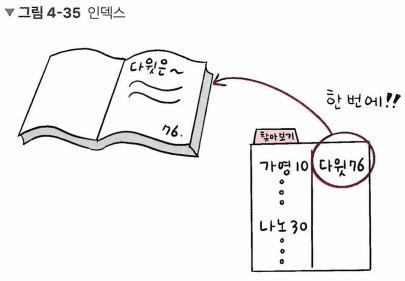
- 책 뒤 <찾아보기>와 유사
- 클러스터형보다 검색 느림
- 데이터 입력/수정/삭제는 덜 느림
- 테이블당 여러 개 생성 가능
- create index... 명령어 사용
- 하나의 인덱스만 생성할 것이라면 클러스터형 인덱스를 만드는 것이 세컨더리 인덱스 만드는 것보다 성능 좋음
- 예) age라는 하나의 필드만드로 쿼리 보내면 클러스터형 인덱스만 필요 . age, name, email 등 다양한 필드를 기반으로 쿼리 보낼 땐 세컨더리 인덱스 사용
클러스터 인덱스와 보조 인덱스 동시 사용
MongoDB
- 도큐먼트를 만들면 자동으로 ObjectID가 형성
- 해당 키가 기본키로 설정
- 세컨더리키도 부가적으로 설정해서 기본키와 세컨더리키를 같이 쓰는 복합 인덱스 설정할 수 있음
4.5.4 인덱스 최적화 기법
- MongoDB 기반 설명
- 이를 기반으로 다른 DB에 웬만하면 적용 가능
1. 인덱스는 비용이다
- 인덱스는 두 번 탐색하도록 강요
- 인덱스 리스트, 그 다음 컬렉션 순으로 탐색 -> 관련 읽기 비용 듦
- 또한, 컬렉션이 수정되었을 때 인덱스도 수정되어야 함.
- 이때 B-트리의 높이를 균형 있게 조절하는 비용 듦
- 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 듦
- 따라서 쿼리에 있는 필드에 인덱스를 무작정 다 설정하는 것이 답이 아님.
- 또한 컬렉션에서 가져와야 하는 양이 많을수록 인덱스를 사용하는 것은 비효율적
2. 항상 테스팅하라
- 서비스에서 사용하는 객체의 깊이, 테이블의 양이 다르기 때문에 인덱스 최적화 기법은 서비스 특징에 따라 달라진다.
- 때문에 항상 테스팅하는 것이 중요
- explain() 함수를 통해 인덱스를 만들고 쿼리를 보낸 이후 테스팅을 하며 걸리는 시간을 최소화 해야함
3. 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다
- 보통 여러 필드를 기반으로 조회를 할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다
- 같음, 정렬, 다중 값, 카디널리티 순으로 생성해야 한다.
- 어떠한 값과 같음을 비교하는 ==이나 equal이라는 쿼리가 있다면 제일 먼저 인덱스로 설정
- 정렬에 쓰는 필드라면 그다음 인덱스로 설정
- 다중 값을 출력해야 하는 필드, 즉 쿼리 자체가 >이거나 < 등 많은 값을 출력해야 하는 쿼리에 쓰는 필드라면 나중에 인덱스 설정
- 유니크한 값의 정도 : 카디널리티. 이 카디널리티가 높은 순서를 기반으로 인덱스를 생성해야 한다. 예를 들어 age와 email이 있을 때, email이 더 높다. 즉 email이라는 필드에 대한 인덱스를 먼저 생성해야 한다.
Reference
주홍철 작가님의 '면접을 위한 CS 전공지식 노트'를 기반으로 작성되었습니다.
