Overview
- 논문명: ModernTCN: A Modern Temporal Convolutional Network for Time Series Forecasting
- 학회(출판연도): ICLR(2024)
- 연구분야: 머신러닝, 시계열 예측, 시퀀스 모델 아키텍쳐 설계
Abstract
최근 Transformer 또는 MLP 기반 모델이 시계열 분석에 주도권을 가지고 있으나, 전통적인 TCN을 현대화함으로써 더 나은 효율성과 성능을 증명
✓ 설명을 덧붙이자면
- 2018년~2022년동안 시계열 분야는 LSTM → Transformer → 더 복잡한 Transformer 변형과 같이 발전
- 하지만 Transformer가 NLP에서 성공했을지라도 시계열은 NLP와 분명히 다르기 때문에 Transformer가 항상 최적은 아닐 수 있다.
[참고]
<NLP의 경우> ① 데이터가 많고 ② 문맥이 복잡하며 ③ 문장 길이가 제한되어 있다
↔ <시계열>은 ① 데이터가 적고 ② 패턴이 반복적이며 ③ 수 천~수 만 길이 가능
1. Introduction
시계열 예측
✓ 시계열 예측이란?
- 과거 데이터를 기반으로 미래 값을 예측하는 문제
X{t-L:t} → X{t+1:t+H}- 시계열 예측은 시간 순서가 절대적이고, 패턴이 고정되어 있지 않으며, 계절성 및 추세, 잡음이 많기 때문에 쉽지 않음
✓ TCN은 무엇인가?
- TCN은 시계열 데이터를 처리하기 위해 설계된 1차원 합성곱(1D Conv)기반 시퀀스 모델
즉, 단순 CNN이 아님!- RNN → LSTM/GRU → Transformer → (다시) Convolution
- RNN의 경우 병렬화의 어려움과 기울기 소실 문제가 있고,
- Transformer의 경우에는 메모리를 많이 사용하고 작은 데이터셋에서는 과적합 등의 문제로 인해 다시 Convolution으로 흐름이 변하고 있는 추세
✓ TCN의 3가지 핵심구조
- 인과적 합성곱(Causal Convolution)
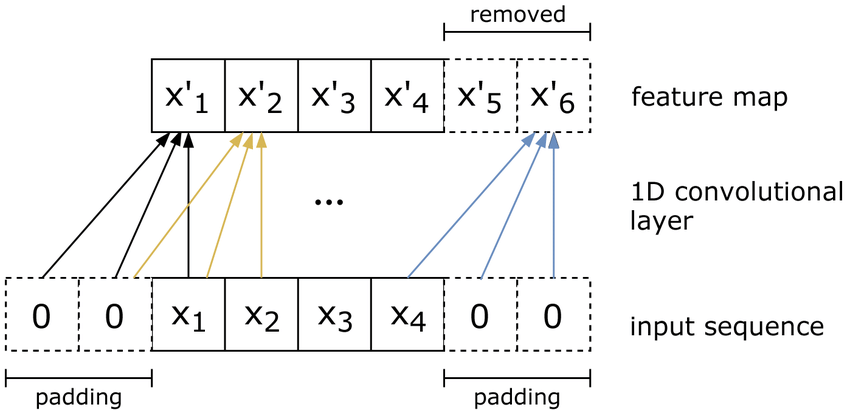
- 출력 y_t는 현재와 과거만 연결, 미래는 연결X (시계열 예측에서는 미래 정보를 보면 안되기 때문
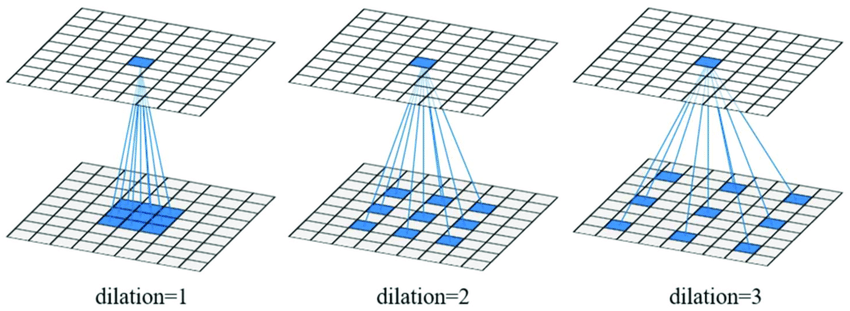
- 확장 합성곱(Dilated Convolution)
- 커널 사이에 dilation(간격)을 둬서 긴 과거 정보(long-range dependecy)를 적은 층으로 커버
- dilation을 1,2,4,8식으로 늘리는데 커널 간격을 띄어서 과거를 샘플링하는 방식
- 레이어 수는 줄이고 계산량은 거의 유지할 수 있다는 장점
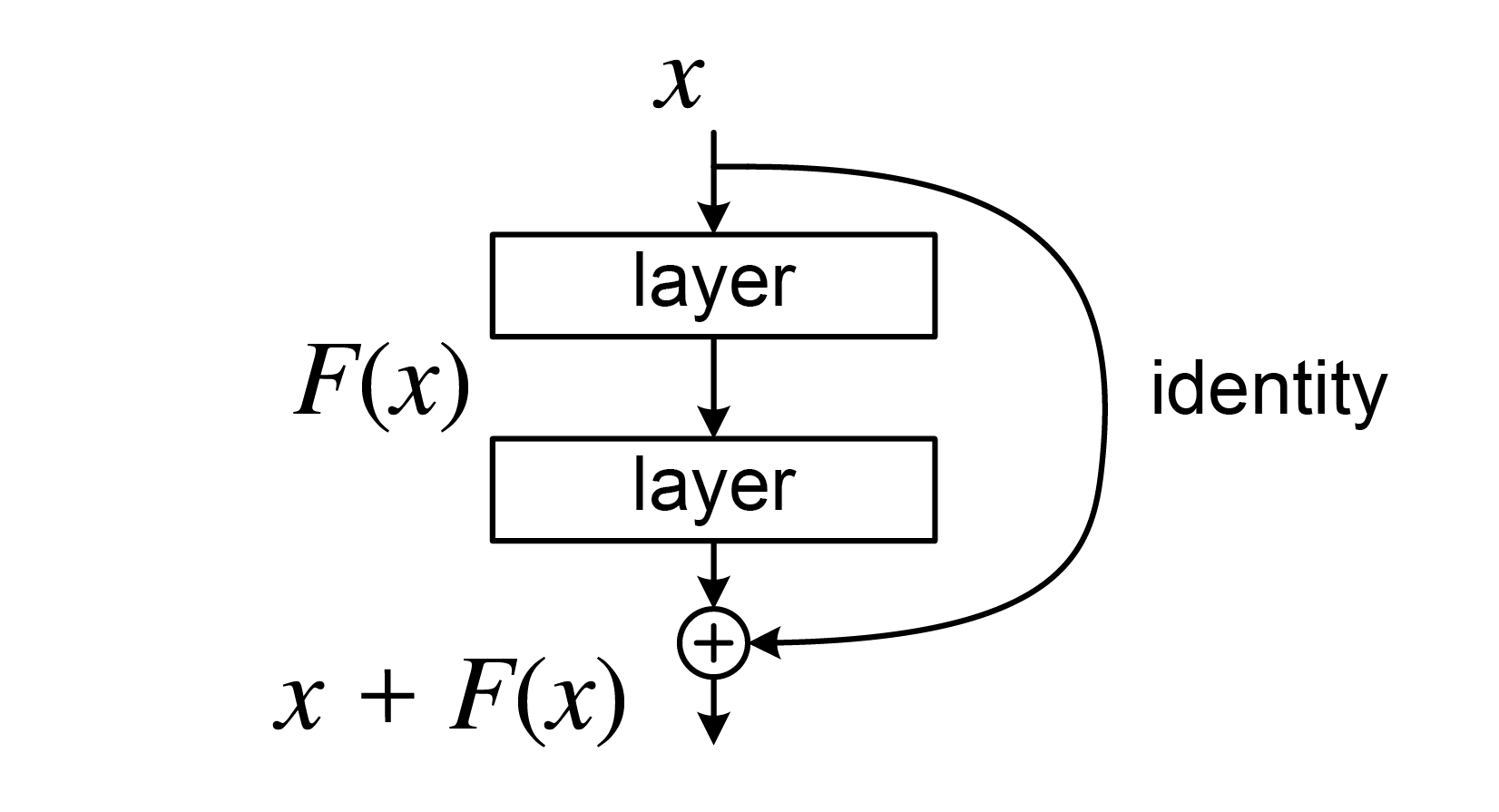
- Residual Connection
- 깊어질수록 gradient 소실 문제 발생
- Resnet스타일의 구조를 활용하여 깊은 네트워크에서도 학습 안정성 확보
- y=x+TCNBlock(x)
- 결측치 예측, 행동 예측, 이상치 탐지 등 많은 활동이 가능함
- Transformer기반 방법, MLP기반 모델이 특히 두드러짐
- 2010년대: TCN과 그 변형들이 많이 사용됨
- 2020년대: Transformer기반, TCN기반 모델들이 몇 년 사이에 등장해서 안정적인 성능 가능
ERF문제
✓ ERF란?
- 모델의 출력 하나가 실제로 얼마나 넓은 입력 범위의 정보에 영향을 받는지
- 실제로는 학습과 추론에서 의미이쎅 기여하는 범위를 의미
- 입력시계열의 더 넓은 범위의 데이터를 사용하여 각 출력 지점의 정보 계산
- 전통적 TCN의 경우
: 이론상 reception field는 커질 수 있지만, 실제 ERF는 중앙에 집중되고 멀어질수록 영향이 급격히 줄어드는 경우가 많음 - Transformer/MLP기반 모델의 경우
: 전역적인 ERF를 가짐으로써 먼 시점의 정보도 출력에 실질적인 영향을 줌
⇒ 제한된 ERF로 합성곱 기반 모델이 약세
Modorn TCN의 등장
- Transformer 블록과 유사한 구조
- ERF를 효과적으로 증가시킬 수 있는 대형 커널 주로 사용
- 현재 기준에서 성능이 그다지 높지 않지만, 합성곱이 변수간 의존성도 포착 가능
- 장단기예측, 결측값 보간, 분류, 이상탐지를 포함한 5가지 주요 시계열 분석 과제로 평가
→ 우수한 성능

 ✓ 색이 진할수록 해당 시점 출력에 더 큰 영향을 미친다는 의미
✓ 색이 진할수록 해당 시점 출력에 더 큰 영향을 미친다는 의미
⇒ 깊게 쌓기, 복잡한 구조, 멀티 브랜치가 아닌 큰 커널을 사용한 현대적 conv를 사용하자!
⇒ 합성곱이 시계열에서 밀린 이유는 구조가 낡았기 때문이지 합성곱 자체가 약해서가 아니다
2. Related work
2.1 Convolution In Time Series Analysis
1. MICN
- 인과적 합성곱뿐만 아니라 다중 스케일 합성곱 구조 제안
- 시계열에서 국소적 특징과 전역적 상관관계를 결합하기 위함
2. SCINet
- 재귀적인 다운 샘플 - 합성곱 - 상호작용 구조 도입
[한계]
제한된 ERF로 인해 장기 의존성을 모델링하는데에 어려움
3. TimesNet
- 1차원 합성곱을 사용하는 다른 모델과 달리
1차원 시계열을 2차원 변형으로 변환한 뒤, CV에서 사용되는 2D 합성곱 백본을 활용해서 정보성 높은 표현을 얻음

⇒ Transformer가 강한 이유는 attention이 아닌 블록설계에 있다.
때문에, Modern TCN은 ① Transformer block 구조 차용, ② attention 제거, ③ 큰 커널의 Conv로 ERF를 확보하고, ConvFFN으로 변수간 의존성 처리
2.2 Modern Convolution in Computer Vision
1. ConvNeXt
: ConvNet → ViT → Modern Conv(ConvNeXt)
- 20년대에 들어오면서 ViT가 제안되며 ConvNet을 능가
- 이를 따라 잡기 위해 Modern Conv가 도입되었고, ConvNeXt는 합성곱 블록을 Transformer 블록과 유사하게 설계
2. RepLNet
- 구조적 재파라미터화 기법으로 커널 크기를 31x31로 확장
- Transformer의 전역 ERF에 더 가까워지기 위함
3. SLak
- 큰 커널을 2개의 직사각형 병렬 커널로 분해
+ 동적 희소성 사용
→ 커널 크기 51x51로 확장
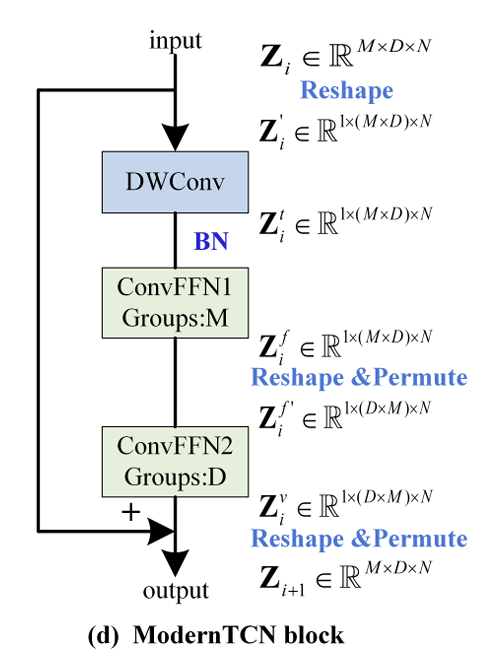
3. Modern TCN
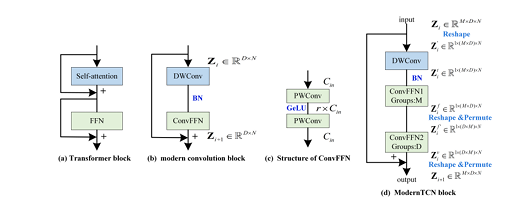
3.1 Modernize The 1D Conv Block
[1D 합성곱 블록의 재설계]
-
DWConv
- 각 feature별로 토큰들 사이의 시간적 정보 학습
- Transformer의 self-attention 모듈과 동일한 역할
-
ConvFFN
-
Transformer의 FFN 모듈과 유사
-
2개의 PWConv로 구성
-
ConvFFN블록의 hidden 채널수가 입력 채널보다 r배 더 큰 inverted bottleneck 구조 채택
✓ inverted bottleneck (역병목 구조)
: 입력과 출력 차원을 중간층(Hidden layer)의 차원을 훨씬 크게(r배) 가져가는 구조
즉, 채널을 먼저 확장하고 연산한 후 다시 줄이는 구조
↔ [병목구조]: 중간채널을 줄였다가 다시 늘리는 구조 → 더 적은 파라미터로도 효율적으로 깊은 특징을 학습할 수 있음
→ 더 적은 파라미터로도 효율적으로 깊은 특징을 학습할 수 있음[참고]
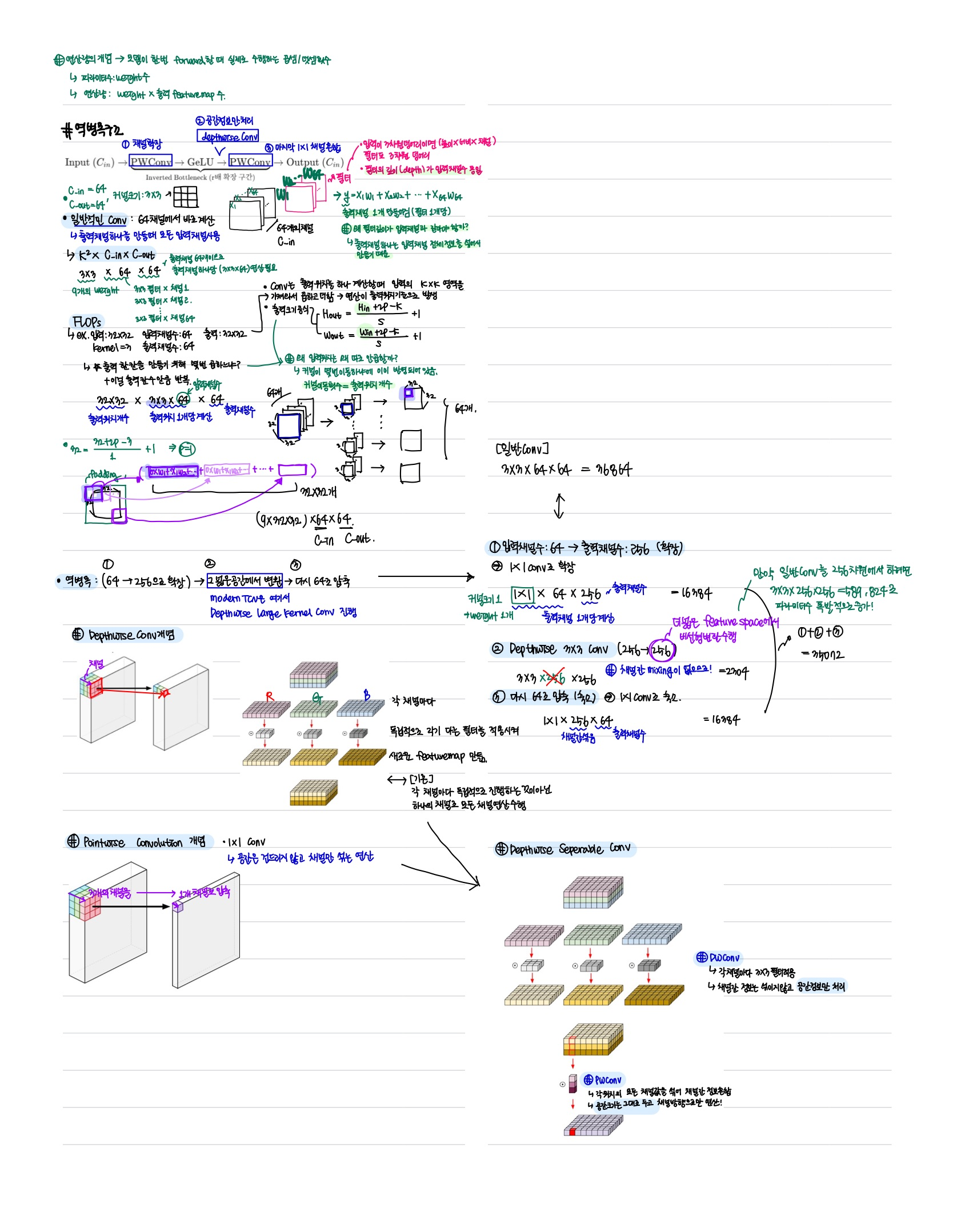
-
⇒ 이러한 설계는 시간정보와 feature 정보의 혼합을 분리함
⇒ 즉, DWConv와 ConvFFN은 각각 시간 차원 또는 feature 차원 중 하나에서만 정보를 혼합하고, 이는 두 차원을 동시에 섞는 전통적인 합성곱과 다름!
[한계]
- 시계열의 특성을 고려하지 못함
- 시계열은 feature, 시간 차원 이외에도 변수 차원이 존재
- 하지만 그림2(b)와 같이 설계된 합성곱 블록을 쌓은 백본은 변수 차원을 제대로 처리하지 못함
3.2 Time Series related modifications
[CV]
- 백본 이전에 각 픽셀의 3채널(RGB) 특징을 embedding layer을 통해 D차원 벡터로 임베딩하여 RGB채널 정보를 혼합
[한계]
- 유사한 변수 혼합(각 시점에서 m개의 변수를 단순히 d차원 벡터로 임베딩하는 방식)은 시계여에는 적합하지 않음
- 시계열의 변수들 간의 차이는 RGB 채널간 차이보다 훨씬 크기 때문
- 단순한 임베딩 레이어만으로 변수간 복잡한 의존성을 학습할 수 없고,
서로 다른 행동 특성을 고려하지 못해서 변수의 독립적인 특성마저 잃게 될 수 있음
- 단순한 임베딩 레이어만으로 변수간 복잡한 의존성을 학습할 수 없고,
- 이러한 임베딩 설계는 변수 차원을 제거하게 되어 이후 변수간 의존성을 연구할 수 없음
1. Patchify Variable-independent Embedding (패치화 변수 독립 임베딩)
- 입력: 길이 L을 갖는 M개의 변수의 입력 시계열
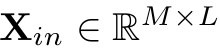
-
적절한 패딩 후 이를 patch 크기P의 N개의 패치로 나눔
- 패칭 과정의 stride = S (연속된 두 패치의 비중첩 길이)
- 즉 시간 축을 길이가 P짜리 덩어리로 나눈다.
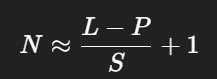
-
이후 패치들은 D차원 임베딩 벡터로 변환
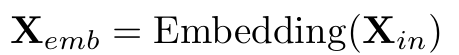
-
입력 임베딩
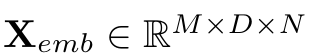
- m: 변수 개수(채널, 센서수)
- d: 임베딩 차원(feature 차원)
- n: 패치 개수(시간 토큰 수)
-
L이 아니라 N으로 Patchify
✓ 왜 M x D x N 이어야 하는가?
- M이 가장 먼저 있는 이유
: 변수는 처음부터 섞으면 안된다.
→ 각 변수는 독립적으로 patchify 및 embedding - D가 있어야 하는 이유
: 이 패치를 어떠한 관점으로 볼 것인가?
상승하강, 주기성, 변화량 등을 담는 표현 공간임 - 마지막에 N인 이유
: 시간축으로 Conv해야함
즉, N이 새로운 time axis
- M이 가장 먼저 있는 이유
-
-
구현을 단순화하기 위해 본 논문에서는
-
Patchify embedding을 완전 합성곱 방식 채택
- X in shape를 M x 1 x L로 확장한 뒤,
커널 크기 P, Stride를 S를 갖는 1D Conv layer에 입력 - 이 Stem layer는 입력 1채널을 D개의 출력 채널로 매핑 (시간축만 압축)
- 단 M개의 단변량 시계열은 서로 독립적으로 임베딩
→ 변수 차원 유지 가능
- X in shape를 M x 1 x L로 확장한 뒤,
-
2. DWConv (시간)
- 채널A, 채널 B가 서로 정보를 주고 받지 않고, 채널 A 내부에서만 과거 시점들을 컨볼루션으로 시간적으로 혼합한다는 뜻
- 원래 시간 정보를 학습하도록 설계됨
- DWConv만으로 시간 간, 변수 간 의존성을 동시에 학습하는 것은 어렵기 때문에, DWConv가 변수 차원 정보 혼합까지 담당하도록 하는 것은 부적절
- 기존의 feature 독립 DWConv를 feature와 변수 모두에 대해 독립적인 형태로 수정
⇒ 각 단변량이 사간적 의존성을 독립적으로 학습하도록! - DWConv에 큰 커널을 사용
- ERF 확장 및 시간 모델링 능력 향상
3. ConvFFN (특징)
- 각 토큰의 새로운 특징 표현을 학습
- DWConv가 feature 및 변수가 독립적이므로 이를 보완하기 위해 feature 및 변수를 혼합해야함!
- 단일 ConvFFN으로 feature과 변수간의 의존성을 학습하는데에는 무리
⇒ PWConv를 grouped PWConv로 대체해서 서로 다른 group수를 설정 - 즉 단일 ConvFFN을 ConvFFN1, ConvFFN2로 추가 분리
- ConvFFN1: 변수별 새로운 feature 표현학습
- ConvFFN2: feature별 변수 간 의존성 포착
위 3개의 수정을 거쳐 최종 Modern TCN 블록 완성
3.3 Overall Structure
4. Experiments
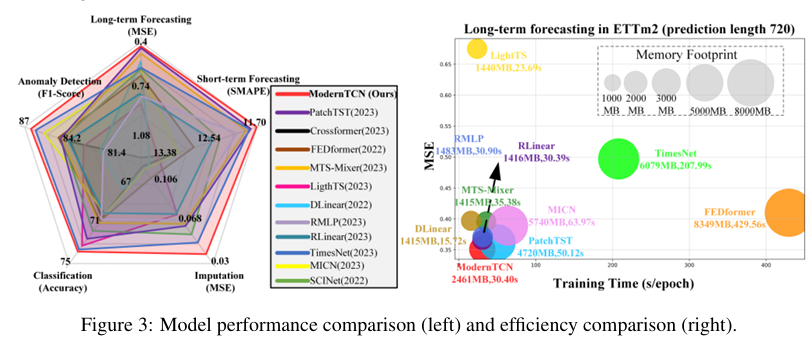 Modern TCN 좋다~
Modern TCN 좋다~
5. Model Analysis
커널 크기 늘리는 것이 ERF 에 좋았다~
6. Conclusion And Future Work
시계열 분석에 있어서 컨볼루션 기반도 좋다~
향후 더 긴 시퀀스, 다양한 도메인에서의 일반화 및 모델 경량화, 추론 최적화같은 방향 확장이 과제
