TCP와 UDP?
전송(transport) 계층에서 데이터 전송을 위해 사용하는 2가지 프로토콜입니다.
TCP 프로토콜
신뢰성 있는 바이트 스트림 서비스를 제공합니다. 신뢰성이 있다는 것은 데이터가 손실 없이 제시간에 도착하며, 도착하지 않았을 경우 대처할 방안이 있다는 것을 의미합니다. 하나의 데이터를 TCP 세그먼트라고 불리는 작은 데이터 조각으로 나누어 전송하고, 정확하게 도착했는지 확인하는 역할을 담당합니다.
연결 지향형
서버와 클라이언트를 연결시켜 놓고 데이터를 주고 받습니다. 연결이 끝나기 전에는 몇 번이든 데이터를 주고 받을 수 있습니다.
그러나, 각 연결이 독립적이기 때문에 연결이 끊어지고 나면 전 연결에 대한 정보가 사라진다는 단점이 있습니다. 예를 들어, 이메일을 전송하고 나서 연결이 끊기고 나면, 전 이메일에 대한 정보를 얻기 위해서 다시 연결을 해야 합니다. 최근에는 지속 HTTP 연결을 사용하기 때문에 이러한 문제점이 없어졌다고 할 수 있습니다.
만약, 데이터의 양이 적어 연결을 하고 끊는 시간보다 전송 시간이 적다면, 비효율적인 연결이 되게 됩니다.
TCP의 디멀티플렉싱
받은 데이터의 헤더 정보(IP 주소, 포트 번호 등)를 분석하여 해당 프로세스에 디멀티플렉싱하게 됩니다.
연결이 되어 있기 때문에, IP 주소와 포트 번호를 안 붙여도 될 것 같습니다. 그러나, 헤더 정보에 포함하는 이유가 있습니다. 같은 포트 번호를 가진 다른 센더가 보내는 경우 IP 주소가 없다면 식별할 수 없습니다. 같은 식으로 같은 센더의 다른 프로세스가 보내는 경우 포트 번호가 없다면 프로세스를 식별할 수 없습니다.
신뢰성
TCP 프로토콜을 사용하게 된다면, 애플리케이션 계층에서는 신뢰성에 대해 상관할 필요가 없게 됩니다. 네트워크 계층에서 패킷 드롭 등으로 인해 데이터가 손실된다하여도 재전송을 요청하게 됩니다.
신뢰성을 위한 2-way, 3-way, 4-way handshaking
handshaking은 프로세스 간 신뢰성을 보장하며 데이터를 주고 받기 위한 TCP의 세션 연결 방식입니다. 데이터를 주고 받기 전에 서버와 클라이언트 간에 연결을 하고 잘 되었는지 확인하는 것입니다.
2-way handshaking
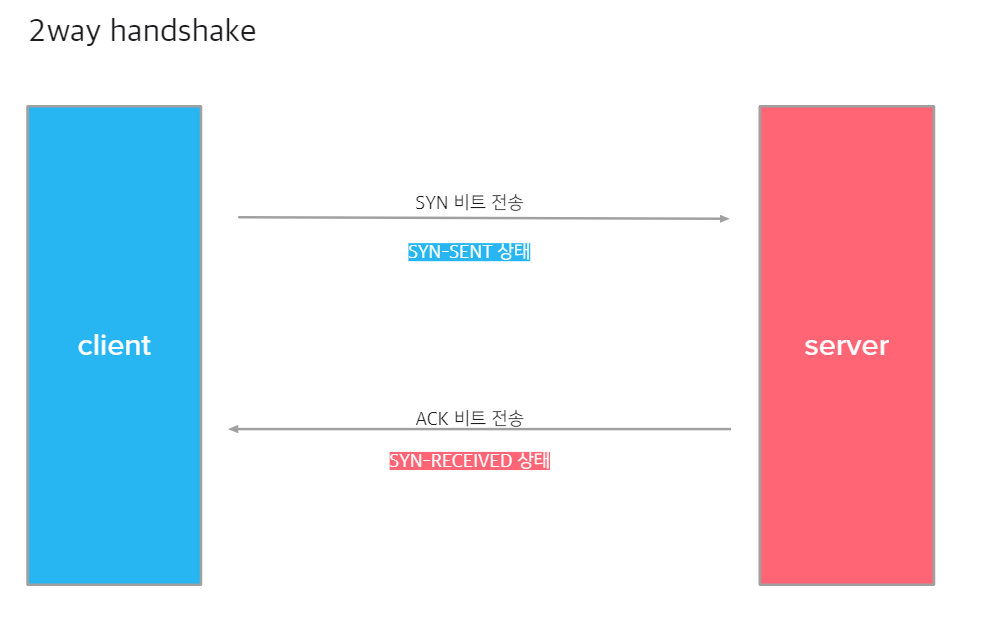
- 클라이언트가 서버에 SYN 비트를 전송합니다.
- SYN 비트를 받은 서버가 클라이언트에 ACK 비트를 전송합니다. 1(서버 쪽 연결 확립)
- 클라이언트가 ACK 비트를 받습니다. 2(클라이언트 쪽 연결 확립)
얼핏 보기에 문제가 없어 보이지만, 2-way handshaking은 서버와 클라이언트가 서로의 상황을 모른다는 점에서 문제가 존재합니다. 다음 시나리오는 문제가 존재합니다.
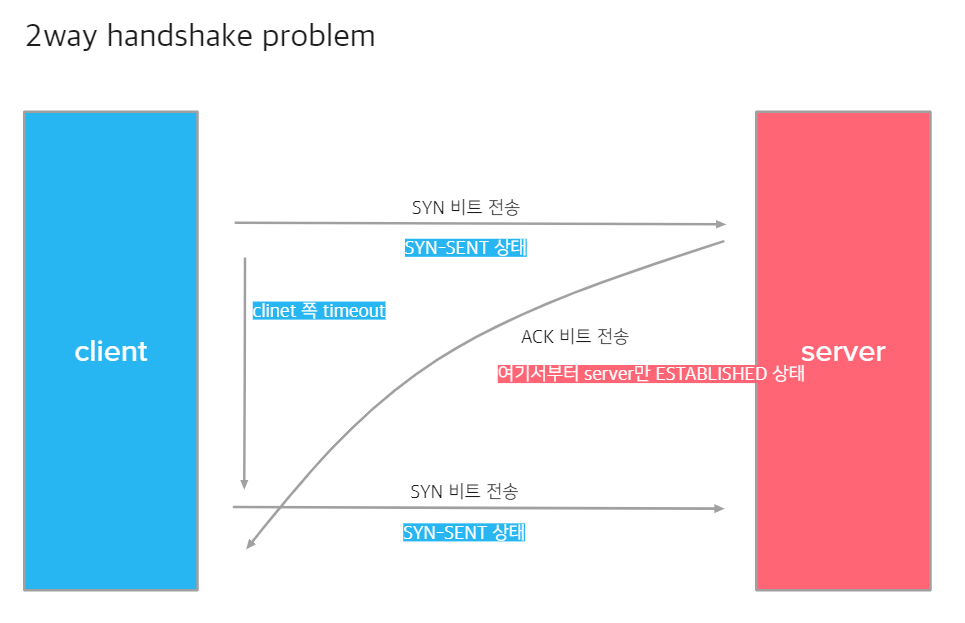
-
클라이언트가 서버에 SYN 비트를 전송합니다.
-
SYN 비트를 받은 서버가 클라이언트에 ACK 비트를 전송합니다. (서버 쪽 연결 확립)
-
클라이언트 쪽에서 timeout이 발생하여, SYN 비트를 재전송합니다.
-
서버가 보낸 ACK 비트가 클라이언트에 도착합니다.
서버가 ACK 비트를 보내기 전에 클라이언트 쪽에서 timeout이 발생해 SYN 비트를 재전송하게 되고, 그 다음 서버의 ACK 비트가 도착하게 되는 시나리오는 서버만이 클라이언트와 연결된 지 아는, 클라이언트가 존재하지 않는 반만 연결된 세션이 열리게 됩니다.
3-way handshaking
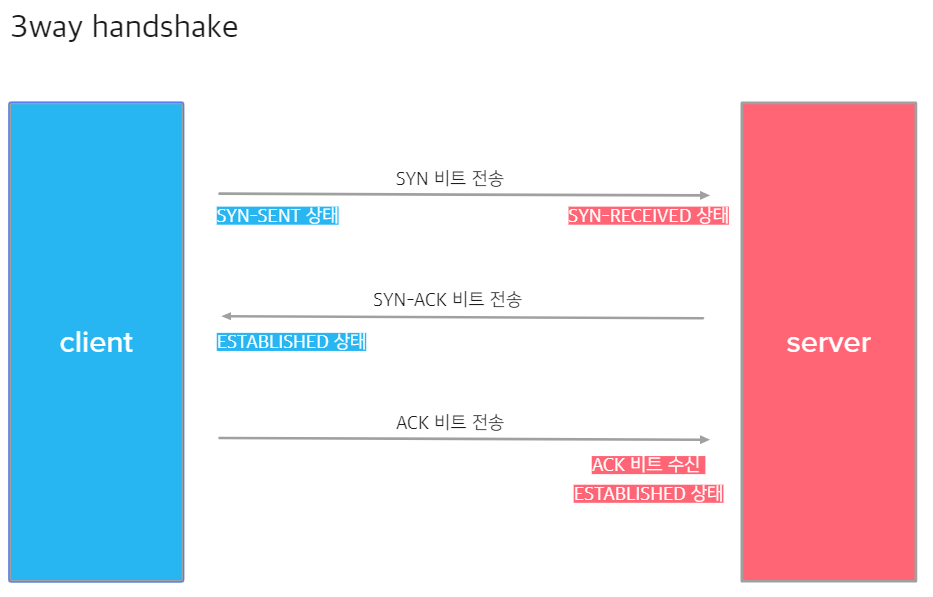
이에 비해, 서로가 데이터를 보낼 때 연결된 것을 보장하고 서로 인지하고 있는 방식이 3-way handshaking입니다. 앞의 클라이언트가 연결이 확립되었는지 서버가 모르는 것을 방지하기 위해 클라이언트가 연결이 확립되었다는 것을 서버에게 알려주는 단계가 하나 추가됩니다.
- 클라이언트가 서버에 SYN 비트를 보내고 SYN-SENT 상태가 됩니다.(1)
- 서버가 SYN 비트를 받아 SYN-ACK 비트를 보내고 SYN-RECEIVED 상태가 됩니다.(2)
- 클라이언트가 SYN-ACK 비트를 받고 ESTABLISHED 상태가 되어 ACK 비트를 보냅니다.(3)
- 서버가 ACK 비트를 받고 ESTABLISHED 상태가 됩니다.
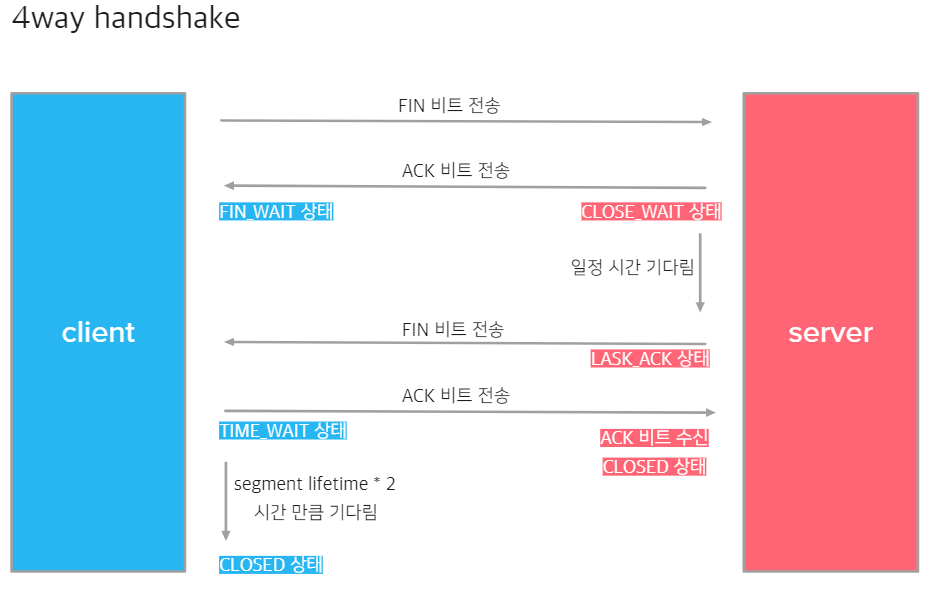
4-way handshaking
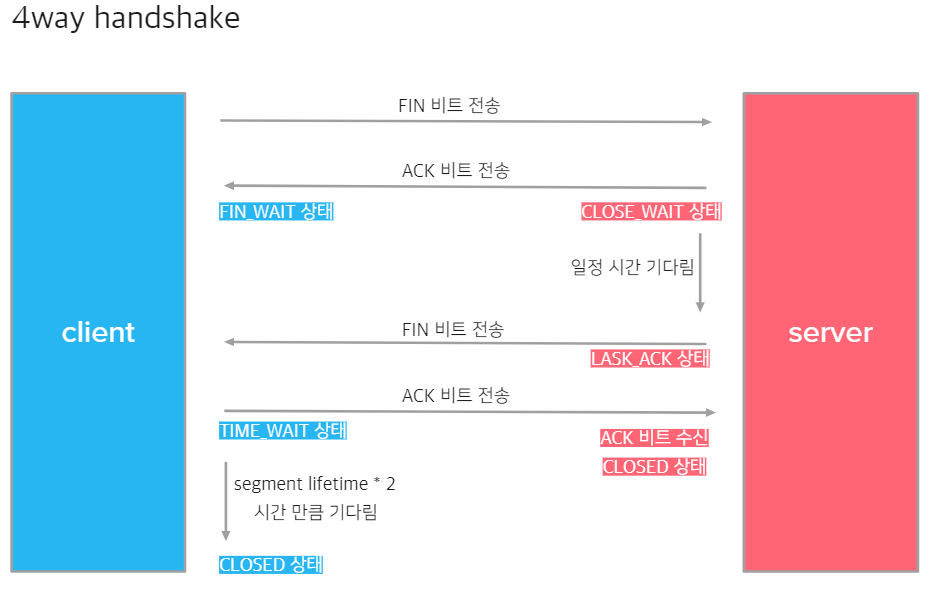
4-way handshaking은 데이터 송수신 전 세션 연결 단계가 아닌 세션 종료를 위한 방식입니다.
-
클라이언트가 서버에 FIN 비트를 보냅니다.(1)
-
FIN 비트를 받은 서버가 클라이언트에 ACK 비트를 보내고 CLOSE_WAIT 상태가 됩니다.(2)
-
ACK 비트를 받은 클라이언트는 FIN_WAIT 상태가 됩니다.
-
일정 시간 후 서버는 클라이언트에 FIN 비트를 보내고 LAST_ACK 상태가 됩니다.(3)
-
FIN 비트를 받은 클라이언트는 ACK 비트를 보내고 TIME_WAIT 상태가 됩니다.(4)
-
ACK 비트를 받은 서버는 연결을 종료하고 CLOSED 상태가 됩니다.
4단계에서 클라이언트는 TIME_WAIT 상태로 세그먼트의 lifetime*2 (디폴트는 240초) 시간 동안 대기하게 되는데, 이는 서버가 보낸 FIN 비트가 FIN 비트 전의 데이터보다 빨리 도착하게 되는 경우에 늦게 도착하는 데이터를 기다리게 하는 과정입니다.
흐름 제어
센더와 리시버의 데이터 처리 속도 차이를 해결하기 위한 방법입니다.
리시버 측이 센더 측 보다 처리 속도가 느리다면, 패킷 드롭이 발생하게 되고 불필요한 데이터 송수신을 하게 됩니다. 따라서, 리시버 측에 버퍼를 두고, 버퍼의 상태를 센더에게 알려주게 됩니다.
센더 측의 데이터 처리 속도가 느리다면, 애플리케이션 계층은 계속 데이터를 보내고 있기 때문에, 센더의 트랜스포트 계층에서 데이터 드롭이 일어날 수 있습니다. 따라서 센더 측에도 버퍼를 두어 관리하게 합니다.
1. Stop and Wait 방식
센더 측이 데이터를 하나 보내고, 받았다는 응답이 오면 다음 데이터를 보내는 방식입니다.
2. Sliding Window 방식
센더가 리시버의 버퍼(윈도우)에 맞춰 데이터를 보내는 방식입니다. 센더는 윈도우만큼의 데이터를 보내고, 리시버가 어디까지 받았다고 신호를 하면 받은 만큼 윈도우를 옮겨 보내는 방식입니다.
혼잡도 제어
회선을 많이 사용하는 특정 회선의 요청을 제한하거나 모든 회선의 요청을 제한하여, 회선 혼잡도를 제어합니다.
1. 끝점간 제어
호스트 사이의 라우터들이 혼잡도를 제어하는 것이 아닌, 네트워크 사정에 따라 호스트들이 제어하는 것을 말합니다. AIMD (Additive Increase / Multicative Decrease) 방식은 1부터 시작하여 window 크기를 1씩 증가시키며 보내고, 패킷 전송이 실패하게 되면 window 크기를 반으로 줄입니다.
또 다른 방식은 1부터 시작하여 곱으로 올리고, 3개의 중복된 ACK가 도착하면 TCP Reno는 window 크기를 반으로 줄이고, TCP Tahoe는 window 크기를 1로 줄입니다. 이 밖에도 많은 방식이 있습니다.
2. 네트워크 지원 제어
일반적인 제어 방식이 아닙니다. 라우터들이 호스트들에게 네트워크 상황을 제공합니다.
순차 전송
UDP와 달리 데이터를 순차적으로 전송합니다.
UDP 프로토콜
TCP와 달리 비연결형 프로토콜으로, 속도가 빠르지만 데이터의 신뢰성을 보장하지 않는 프로토콜입니다.
데이터의 순서를 보장하는 TCP와 달리 데이터의 순서를 보장하지 않습니다. 데이터가 유실된다해도 재전송을 요청하지 않고, handshaking을 하지 않습니다.
최소한의 오류를 검출하기 위해 checksum 방식을 사용합니다.
UDP의 checksum
전송 과정의 최소한의 오류를 검출하기 위한 방식으로 보내는 쪽에서 정해진 방식에 따라 checksum을 각 독립적인 세그먼트의 헤더에 넣습니다. 받는 쪽에서는 checksum이 맞는지 확인하여 틀리면 버립니다.
그러나, checksum이 맞다고 하여 데이터 안쪽이 손상된 확률도 있기 때문에 데이터의 신뢰성을 보장하고 싶다면 TCP방식을 사용하거나 응용 계층에서 구현하여 추가하여야 합니다.
