들어가기 전에
Hash와Set구별 잘하고 각각 가능한 메서드 잘 구별하자
- add :
Set에 요소를 추가할 때 사용되며, 중복된 요소는 추가X- put :
Map에 키와 값을 추가하거나 업데이트 할 때 사용
컬렉션 프레임워크 - Map, Stack, Queue
1. 컬렉션 프레임워크 - Map 소개1
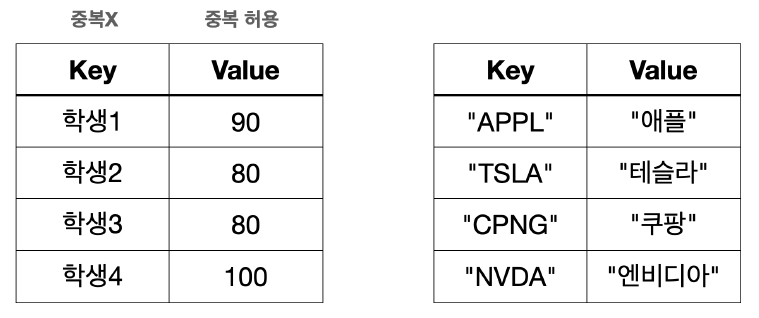
Map은 키-값의 쌍을 저장하는 자료 구조이다.
- 키는 맵 내에서 유일해야 한다. 그리고 키를 통해 빠르게 검색할 수 있다.
- 키는 중복될 수 없지만, 값은 중복될 수 있다.
Map은 순서를 유지하지 않는다.
- 자바는
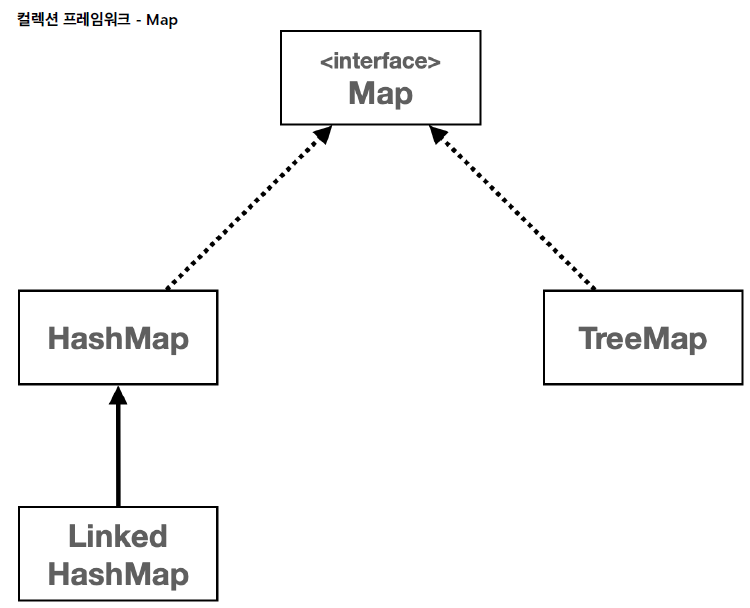
HashMap,LinkedHashMap,TreeMap등 다양한Map구현체를 제공한다. 이들은Map인터페이싀 메서드를 구현하며, 각기 다른 특성과 성능 특징을 가지고 있다.
이 중 HashMap 사용법을 코드로 알아보자.
public class MapMain1 { public static void main(String[] args) { Map<String, Integer> studentMap = new HashMap<>(); // 학생 성적 데이터 추가 studentMap.put("studentA", 90); studentMap.put("studentB", 80); studentMap.put("studentC", 80); studentMap.put("studentD", 100); System.out.println(studentMap); // 특정 학생의 값 조회 Integer result = studentMap.get("studentD"); System.out.println("result = " + result); System.out.println("keySet 활용"); Set<String> keySet = studentMap.keySet(); for (String key : keySet) { Integer value = studentMap.get(key); System.out.println("key=" + key + ", value=" + value); } System.out.println("entrySet 활용"); Set<Map.Entry<String, Integer>> entries = studentMap.entrySet(); for (Map.Entry<String, Integer> entry : entries) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println("key=" + key + ", value=" + value); } System.out.println("values 활용"); Collection<Integer> values = studentMap.values(); for (Integer value : values) { System.out.println("value = " + value); } } }
키 목록 조회
Set<String> keySet = studentMap.ketSet()
Map의 키는 중복을 허용하지 않는다.- 따라서,
Map의 모든 키 목록을 조회하는ketSet()을 호출하면, 중복을 허용하지 않는 자료 구조인Set을 반환한다.
키와 값 목록 조회
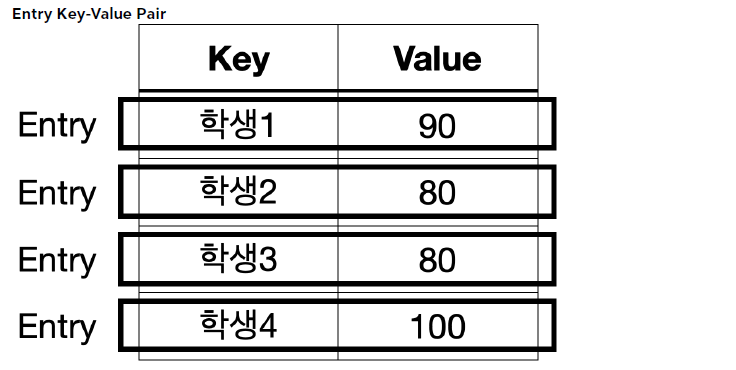
Map은 키와 값을 보관하는 자료 구조이다. 따라서 키와 값을 하나로 묶을 수 있는 방법이 필요하다. 이때Entry를 사용한다.Entry는 키-값의 쌍으로 이루어진 간단한 객체이다.Entiry는Map내부에서 키와 값을 함께 묶어서 저장할 때 사용한다.- 쉽게 이야기해서 우리가
Map에 키와 값으로 데이터를 저장하면Map은 내부에서 키와 값을 하나로 묶는Entry객체를 만들어서 보관한다. 참고로 하나의Map에 여러Entry가 저장될 수 있다.- 참고로
Entry는Map내부에 있는 인터페이스이다. 우리는 구현체보다는 이 인터페이스를 사용하면 된다.
값 목록 조회
Collection<Integer> values = studentMap.values()
Map의 값 목록 중복을 허용한다.- 따라서, 중복을 허용하지 않는
Set으로 반환할 수는 없다.- 그리고 입력 순서를 보장하지 않기 때문에 순서를 보장하는
List로 반환하기도 애매하다.- 따라서, 단순히 값의 모음이라는 의미의 상위 인터페이스인
Collection으로 반환한다
2. 컬렉션 프레임워크 - Map 소개2
Map 의 기능을 더 알아보자.
같은 키로 다른 데이터를 저장하면 어떻게 될까?
public class MapMain2 { public static void main(String[] args) { Map<String, Integer> studentMap = new HashMap<>(); // 학생 성적 데이터 추가 studentMap.put("studentA", 90); System.out.println(studentMap); studentMap.put("studentA", 100); //같은 키에 저장시 기존 값 교체 System.out.println(studentMap); boolean containsKey = studentMap.containsKey("studentA"); System.out.println("containsKey = " + containsKey); // 특정 학생의 값 삭제 studentMap.remove("studentA"); System.out.println(studentMap); } }
Map에 값을 저장할 때 같은 키에 다른 값을 저장하면 기존 값을 교체한다.studentA = 90에서studentA=100으로 변경된 것을 확인할 수 있다.
만약 같은 학생이 Map 에 없는 경우에만 데이터를 저장하려면 어떻게 해야할까?
public class MapMain3 { public static void main(String[] args) { Map<String, Integer> studentMap = new HashMap<>(); // 학생 성적 데이터 추가 studentMap.put("studentA", 50); System.out.println(studentMap); // 학생이 없는 경우에만 추가1 if (!studentMap.containsKey("studentA")) { studentMap.put("studentA", 100); } System.out.println(studentMap); // 학생이 없는 경우에만 추가2 studentMap.putIfAbsent("studentA", 100); studentMap.putIfAbsent("studentB", 100); System.out.println(studentMap); } }
putIfAbsent()는 영어 그대로 없는 경우에만 입력하라는 뜻이다.- 이 메서드를 사용하면 키가 없는 경우에만 데이터를 저장하고 싶을 때 코드 한줄로 편리하게 처리할 수 있다.
3. 컬렉션 프레임워크 - Map 구현체
- 자바의
Map인터페이스는 키-값 쌍을 저장하는 자료구조이다.Map은 인터페이스이기 때문에, 직접 인스턴스를 생성할 수는 없고, 대신Map인터페이스를 구현한 여러 클래스를 통해 사용할 수 있다.- 대표적으로
HashMap,TreeMap,LinnkedHashMap이 있다.
Map vs Set
Map과Set은 거의 같다.
- 단지 옆에
Value를 가지고 있는가 없는가의 차이가 있을 뿐이다.
Map의 키가 바로Set과 같은 구조이다.
- 그리고
Map은 모든 것이Key를 중심으로 동작한다.
Value는 단순히Key옆에 따라 붙은 것 뿐이다.
Key옆에Value만 하나 추가해주면Map이 되는 것이다.
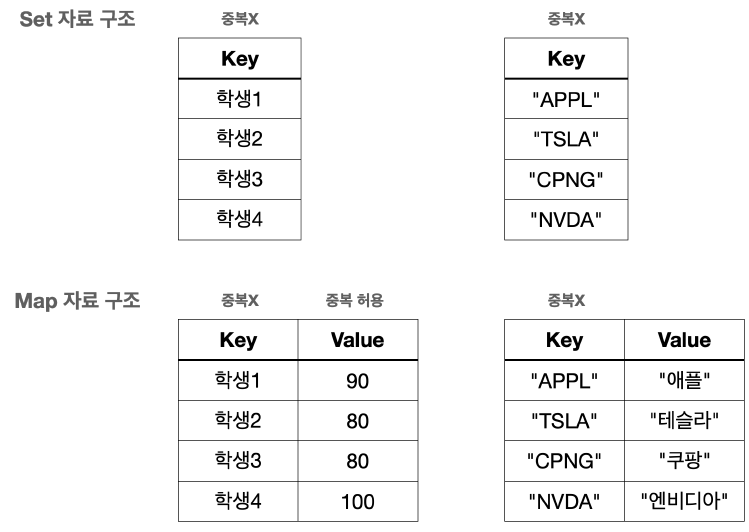
이런 이유로 Set 과 Map 의 구현체는 거의 같다.
HashSet -> HashMap(순서 보장 X)LinkedHashSet -> LinkedHashMap(입력 순서 보장)TreeSet -> TreeMap(키는 정렬된 순서로 저장)1. HashMap:
- 구조:
HashMap은 해시를 사용해서 요소를 저장한다.
- 키(
Key) 값은 해시 함수를 통해 해시 코드로 변환되고, 이 해시 코드는 데이터를 저장하고 검색하는 데 사용된다.- 특징: 삽입, 삭제, 검색 작업은 해시 자료 구조를 사용하므로 일반적으로 상수 시간(
O(1))의 복잡도를 가진다.- 순서: 순서를 보장하지 않는다.
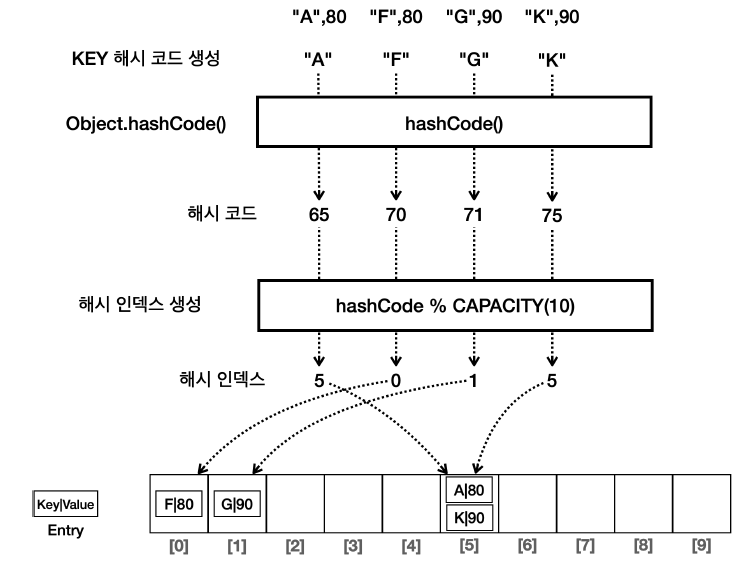
자바 HashMap 작동 원리
자바의
HashMap은HashSet과 작동 원리가 같다.
Set과 비교하면 다음과 같은 차이가 있다.
Key를 사용해서 해시 코드를 생성한다.Key뿐만 아니라 값(Value)을 추가로 저장해야 하기 때문에Entry를 사용해서Key,Value를 하나로 묶어서 저장한다.
- 이렇게 해시를 사용해서 키와 값을 저장하는 자료 구조를 일반적으로 해시 테이블이라 한다.
- 앞서 학습한
HashSet은 해시 테이블의 주요 원리를 사용하지만, 키-값 저장 방식 대신 키만 저장하는 특수한 형태의 해시 테이블로 이해하면 된다.- 주의 :
Map의Key로 사용되는 객체는hashCode(),equals()를 반드시 구현해야 한다.
2. LinkedHashMap:
- 구조:
LinkedHashMap은HashMap과 유사하지만, 연결 리스트를 사용하여 삽입 순서 또는 최근 접근 순서에 따라 요소를 유지한다.- 특징: 입력 순서에 따라 순회가 가능하다.
HashMap과 같지만 입력 순서를 링크로 유지해야 하므로 조금 더 무겁다.- 성능:
HashMap과 유사하게 대부분의 작업은O(1)의 시간 복잡도를 가진다.- 순서: 입력 순서를 보장한다.
3. TreeMap:
- 구조:
TreeMap은 레드-블랙 트리를 기반으로 한 구현이다.- 특징: 모든 키는 자연 순서 또는 생성자에 제공된
Comparator에 의해 정렬된다.- 성능:
get,put,remove와 같은 주요 작업들은O(log n)의 시간 복잡도를 가진다.- 순서: 키는 정렬된 순서로 저장된다.
4. 스택 자료 구조
Stack 클래스는 사용하지 말자
자바의 Stack 클래스는 내부에서 Vector 라는 자료 구조를 사용한다. 이 자료 구조는 자바 1.0에 개발되었는데, 지금은 사용되지 않고 하위 호환을 위해 존재한다. 지금은 더 빠른 좋은 자료 구조가 많다. 따라서 Vector 를 사용하는 Stack 도 사용하지 않는 것을 권장한다. 대신에 이후에 설명할 Deque 를 사용하는 것이 좋다.
5. 큐 자료 구조
Queue인터페이스는List,Set과 같이Collection의 자식이다.Queue의 대표적인 구현체는ArrayDeque,LinkedList가 있다.
- 전통적으로 큐에 값을 넣는 것을
offer라 하고, 큐에서 값을 꺼내는 것을poll이라 한다.
public class QueueMain { public static void main(String[] args) { Queue<Integer> queue = new ArrayDeque<>(); //Queue<Integer> queue = new LinkedList<>(); // 데이터 추가 queue.offer(1); queue.offer(2); queue.offer(3); System.out.println(queue); // 다음 꺼낼 데이터 확인 System.out.println("queue.peek() = " + queue.peek()); //데이터 꺼내기 System.out.println("poll = " + queue.poll()); System.out.println("poll = " + queue.poll()); System.out.println("poll = " + queue.poll()); System.out.println(queue); } }
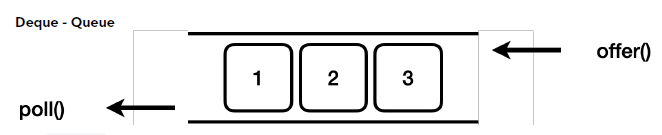
6. Deque 자료 구조
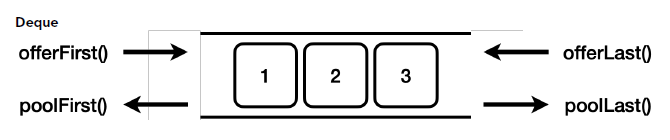
- "Deque"는 "Double Ended Queue"의 약자로, 이름에서 알 수 있듯이, Deque는 양쪽 끝에서 요소를 추가하거나 제거할 수 있다.
- Deque는 일반적인 큐와 스택의 기능을 모두 포함하고 있어, 매우 유연한 자료 구조이다.
offerFirst(): 앞에 추가한다.offerLast(): 뒤에 추가한다.pollFirst(): 앞에서 꺼낸다.pollLast(): 뒤에서 꺼낸다.

Deque 의 대표적인 구현체는 ArrayDeque , LinkedList 가 있다.
public class DequeMain { public static void main(String[] args) { Deque<Integer> deque = new ArrayDeque<>(); // Deque<Integer> deque = new LinkedList<>(); // 데이터 추가 deque.offerFirst(1); System.out.println(deque); deque.offerFirst(2); System.out.println(deque); deque.offerLast(3); System.out.println(deque); deque.offerLast(4); System.out.println(deque); // 다음 꺼낼 데이터 확인(꺼내지 않고 단순 조회만) System.out.println("deque.peekFirst() = " + deque.peekFirst()); System.out.println("deque.peekLast() = " + deque.peekLast()); // 데이터 꺼내기 System.out.println("pollFirst = " + deque.pollFirst()); System.out.println("pollFirst = " + deque.pollFirst()); System.out.println("pollLast = " + deque.pollLast()); System.out.println("pollLast = " + deque.pollLast()); System.out.println(deque); } }입력 순서는 다음과 같다.
- 앞으로 1을 추가한다. [1]
- 앞으로 2를 추가한다. [2, 1]
(앞으로 2를 추가했으므로 기존에 있던 1이 뒤로 밀려난다)- 뒤로 3을 추가한다. [2, 1, 3]
- 뒤로 4를 추가한다. [2, 1, 3, 4]
앞에서 2번 꺼내면 2, 1이 꺼내진다. 다음으로 뒤에서 2번 꺼내면 4, 3이 꺼내진다.
Deque 구현체와 성능 테스트
Deque의 대표적인 구현체는 ArrayDeque ,LinkedList가 있다. 이 둘 중에 ArrayDeque가 모든 면에서 더 빠르다.
100만 건 입력(앞, 뒤 평균)
ArrayDeque: 110ms
LinkedList: 480ms
100만 건 조회(앞, 뒤 평균)
ArrayDeque: 9ms
LinkedList: 20ms
- 둘의 차이는
ArrayListvsLinkedList의 차이와 비슷한데, 작동 원리가 하나는 배열을 하나는 동적 노드 링크를 사용하기 때문이다.ArrayDeque는 추가로 특별한 원형 큐 자료 구조를 사용하는데, 덕분에 앞, 뒤 모두O(1)의 성능을 제공한다. 물론LinkedList도 앞 뒤 모두O(1)의 성능을 제공한다.- 이론적으로
LinkedList가 삽입 삭제가 자주 발생할 때 더 효율적일 수 있지만, 현대 컴퓨터 시스템의 메모리 접근 패턴, CPU 캐시 최적화 등을 고려할 때 배열을 사용하는ArrayDeque가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많다.
7. Deque와 Stack, Queue
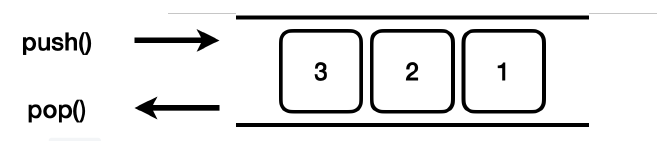
Deque는 양쪽으로 데이터를 입력하고 출력할 수 있으므로, 스택과 큐의 역할을 모두 수행할 수 있다.Deque를Stack과Queue로 사용하기 위한 메서드 이름까지 제공한다.
push()를 호출하면 앞에서 입력한다.pop()을 호출하면 앞에서 꺼낸다.

offer()를 호출하면 뒤에서 입력한다.poll()을 호출하면 앞에서 꺼낸다.