1. 개요
주제: Pandas
내용 : Pandas에 대해 강의 기반 내가 헷갈렸던 부분 위주로 정리를 해보려고 한다.
2. 데이터프레임
(1) 데이터프레임 이해
1) 데이터프레임이란 : 일반적으로 접하게 되는 테이블 형태, 엑셀 형태
2) 데이터프레임 형태 : 데이터프레임은 인덱스(=행 이름) 이 있고 없고에 따라 다른 형태를 갖습니다.
① 인덱스와 열 이름이 없는 형태
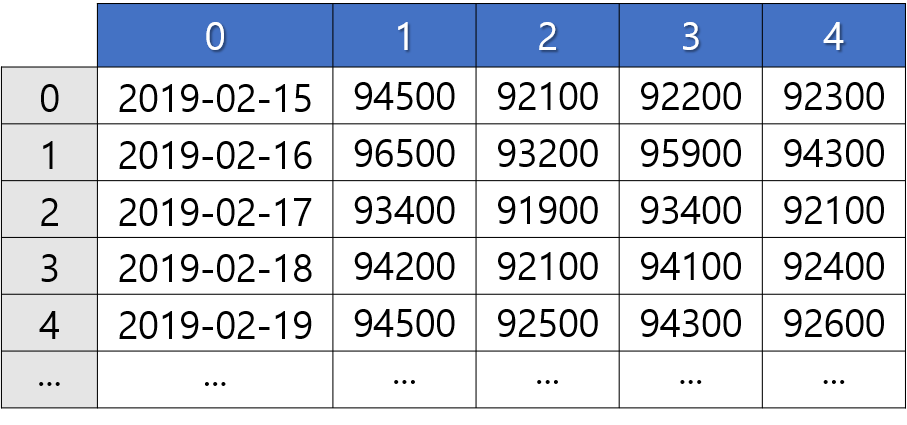
② 열 이름을 지정한 형태
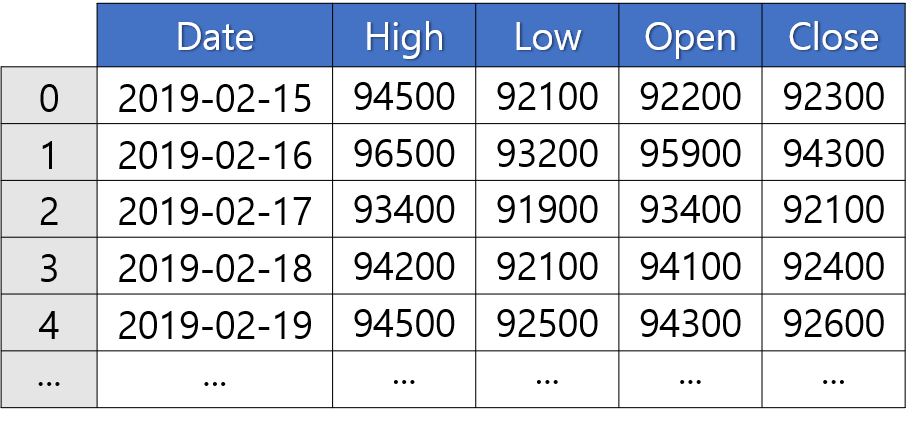
③ 인덱스와 열 이름을 지정한 형태
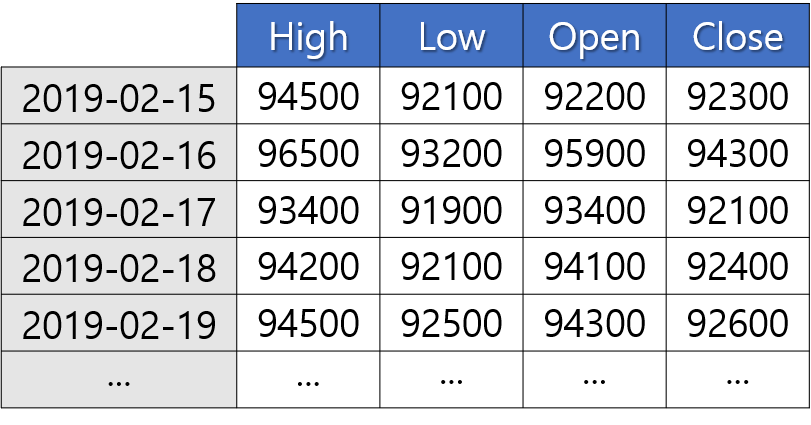
(2) 데이터프레임 직접 만들기
1) 라이브러리 불러오기
✍ 입력
import pandas as pd2) 딕셔너리로 만들기
✍ 입력
# 딕셔너리 만들기
dict1 = {'Name': ['Gildong', 'Sarang', 'Jiemae', 'Yeoin'],
'Level': ['Gold', 'Bronze', 'Silver', 'Gold'],
'Score': [56000, 23000, 44000, 52000]}
# 확인
print(dict1)✍ 입력
#### 데이터프레임 만들기
df = pd.DataFrame(dict1)
#### 확인
print(df.head())✍ 출력
Name Level Score
0 Gildong Gold 56000
1 Sarang Bronze 23000
2 Jiemae Silver 44000
3 Yeoin Gold 52000(3) CSV파일 읽어오기
✍ 입력
# 데이터 읽어오기
path='https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv'
data = pd.read_csv(path)
# 상위 10행만 확인
data.head(10)
# 하위 10행만 확인
data.tail(10)3. 데이터프레임 탐색
(1) 상위, 하위, 일부 데이터, 크기 확인
✍ 입력
# 상위 10개 행 데이터
data.head(10)
# 하위 3개 행 데이터
data.tail(3)
# 행 수와 열 수 확인
data.shape(2) 열, 행 정보 보기
1) 열 확인
✍ 입력
# 열 확인
print(data.columns)
print(data.columns.values) # np array 형태✍ 출력
Index(['Attrition', 'Age', 'DistanceFromHome', 'EmployeeNumber', 'Gender',
'JobSatisfaction', 'MaritalStatus', 'MonthlyIncome', 'OverTime',
'PercentSalaryHike', 'TotalWorkingYears'],
dtype='object')
['Attrition' 'Age' 'DistanceFromHome' 'EmployeeNumber' 'Gender'
'JobSatisfaction' 'MaritalStatus' 'MonthlyIncome' 'OverTime'
'PercentSalaryHike' 'TotalWorkingYears']✍ 입력
# 데이터프레임을 리스트 함수에 넣으면 열 이름이 리스트로 반환됨.
list(data)✍ 출력
['Attrition',
'Age',
'DistanceFromHome',
'EmployeeNumber',
'Gender',
'JobSatisfaction',
'MaritalStatus',
'MonthlyIncome',
'OverTime',
'PercentSalaryHike',
'TotalWorkingYears']2) 자료형 확인
✍ 입력
# 열 자료형 확인
data.dtypes✍ 출력
Attrition int64
Age int64
DistanceFromHome int64
EmployeeNumber int64
Gender object
JobSatisfaction int64
MaritalStatus object
MonthlyIncome int64
OverTime object
PercentSalaryHike int64
TotalWorkingYears int64
dtype: object✍ 입력
# 열 자료형, 값 개수 확인
data.info()✍ 출력
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1196 entries, 0 to 1195
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Attrition 1196 non-null int64
1 Age 1196 non-null int64
2 DistanceFromHome 1196 non-null int64
3 EmployeeNumber 1196 non-null int64
4 Gender 1196 non-null object
5 JobSatisfaction 1196 non-null int64
6 MaritalStatus 1196 non-null object
7 MonthlyIncome 1196 non-null int64
8 OverTime 1196 non-null object
9 PercentSalaryHike 1196 non-null int64
10 TotalWorkingYears 1196 non-null int64
dtypes: int64(8), object(3)
memory usage: 102.9+ KB(3) 정렬해서 보기
인덱스를 기준으로 정렬하는 방법과 특정 열을 기준으로 정렬하는 방법이 있습니다.
sort_values() 메소드로 특정 열을 기준으로 정렬합니다.
ascending 옵션을 설정해 오름차순, 내림차순을 설정할 수 있습니다.
ascending=True: 오름차순 정렬(기본값)
ascending=False: 내림차순 정렬
✍ 입력: 단일 열 정렬
data.sort_values(by='MonthlyIncome', ascending=False)✍ 입력: 복합 열 정렬
data.sort_values(by=['JobSatisfaction', 'MonthlyIncome'], ascending=[True, False])✍ 입력: 복합 열 정렬 별도로 저장하고, 인덱스 reset
temp = data.sort_values(by=['JobSatisfaction', 'MonthlyIncome'], ascending=[True, False])
temp.reset_index(drop = True)(4) 기본 집계
- 데이터를 좀더 이해하기 위해 고유값, 합, 평균, 최댓값, 최솟값 등을 확인합니다.
1) 고유값 확인
- 범주형 열(열이 가진 값이 일정한 값인 경우, 성별, 등급 등)인지 확인할 때 사용합니다.
- 열 고유값은 여러열이 아니라 한개 씩 사용해야한다
✍ 입력
# MaritalStatus 열 고유값 확인
print(data['MaritalStatus'].unique())✍ 출력
['Married' 'Single' 'Divorced']2) 기본 집계 메소드 사용
데이터를 1차 집계 한 후 분석을 진행하는 경우가 많으므로 필히 알아두어야 할 내용입니다.
이후에 배우는 Groupby 기능에서 같이 사용됩니다.
✍ 입력 : MonthlyIncome 열 합계 조회
print(data['MonthlyIncome'].sum())✍ 출력
7798045✍ 입력 : 'Age', 'MonthlyIncome' 열 중앙값 확인
print(data[['Age', 'MonthlyIncome']].median())✍ 출력
Age 36.0
MonthlyIncome 4973.5
dtype: float64
안녕하세요. wony입니다.