1. 개요
주제: Pandas
내용 : Pandas에 대해 조회 및 집계를 정리하려고 한다.
2. 데이터프레임 조회
(1) 들아가기 전에
- 시리즈(Series)와 데이터프레임(DataFrame)
- 데이터프레임 : 2차원 구조
- 시리즈 : 1차원 구조
- 데이터프레임에서 열 하나를 띄어 내면 시리즈!

(2) 특정 열 조회
- df.loc[ : , [열 이름1, 열 이름2,...]] 형태로 조회할 열 이름을 리스트로 지정합니다.
- 2차원 배열은 대괄호 안에 또 대괄호로 읽지 마시고, 대괄호 안에 리스트!!!
- 열 부분은 생략할 수 있었지만, 행 부분을 생략할 수는 없습니다.
✍ 입력
# Attrition 열 조회 : 시리즈로 조회
data['Attrition']✍ 출력
0 0
1 0
2 0
3 0
4 1
..
1191 0
1192 0
1193 0
1194 0
1195 0
Name: Attrition, Length: 1196, dtype: int64✍ 입력
# Attrition, Age 열 조회 : 데이터프레임으로 조회
# 대괄호 안에 또 대괄호로 읽지 마시고, 대괄호 안에 리스트!!!
data[['Attrition', 'Age' ]]✍ 출력
Attrition Age
0 0 33
1 0 35
2 0 42
3 0 46
4 1 22
... ... ...
1191 0 32
1192 0 27
1193 0 29
1194 0 29
1195 0 43
1196 rows × 2 columns✍ 입력 : Pandas 보충문제
# Age, DistanceFromHome, Gender열만 DistanceFromHome 열 기준으로 내림차순 정렬
data[['Age', 'DistanceFromHome', 'Gender']].sort_values(by=['Age', 'DistanceFromHome', 'Gender'], ascending=False)(3) 조건으로 조회: .loc
- df.loc[조건] 형태로 조건을 지정해 조건에 만족하는 데이터만 조회할 수 있습니다.
- 우선 조건이 제대로 판단이 되는지 확인한 후 그 조건을 대 괄호 안에 넣으면 됩니다.
1) 단일 조건 조회
✍ 입력
data['DistanceFromHome'] > 102) 여러 조건 조회
- [ ]안에 조건을 여러개 연결할 때 and와 or 대신에 &와 |를 사용해야 합니다.
- 그리고 각 조건들은 (조건1) & (조건2) 형태로 괄호로 묶어야 합니다.
✍ 입력
data.loc[(data['DistanceFromHome'] > 10) & (data['JobSatisfaction'] == 4)]3) isin(), between()
- isin([값1, 값2,..., 값n]): 값1 또는 값2 또는...값n인 데이터만 조회합니다.
- 주의 isin(리스트) 값들을 리스트 형태로 입력해야 합니다.
✍ 입력 : 값 나열
data.loc[data['JobSatisfaction'].isin([1,4])]✍ 입력 : 범위 지정
data.loc[data['Age'].between(25, 30)]3. 데이터프레임 집계
- sum(), mean(), max(), min(), count() 메소드를 사용해 지정한 열 또는 열들을 기준으로 집계합니다.
- 평균을 구하는 메소드가 avg()가 아닌 mean() 임을 주의하기 바랍니다.
(1) 열 하나 집계
- 우선 특정 열의 값 합은 다음과 같이 구할 수 있습니다.
✍ 입력
# MonthlyIncome 합계
data['MonthlyIncome'].sum()✍ 출력
7798045✍ 입력
# MonthlyIncome, TotalWorkingYears 각각의 평균
data[['MonthlyIncome', 'TotalWorkingYears']].mean()✍ 출력
MonthlyIncome 6520.104515
TotalWorkingYears 11.330268
dtype: float641) 집계하기
- 만일 day 별로 합을 구하고자 한다면 다음과 같이 합니다.
- 아래 결과 값 네 개를 더하면 전체 합이 됩니다.
- as_index=True를 설정(기본값)하면 집계 기준이 되는 열이 인덱스 열이 됩니다. - 집계 결과가 data 열만 가지니 시리즈가 됩니다.
✍ 입력
# MaritalStatus 별 Age 평균 --> 시리즈
data.groupby('MaritalStatus', as_index=True)['Age'].mean()✍ 출력
MaritalStatus
Divorced 37.522727
Married 37.704380
Single 35.460938
Name: Age, dtype: float64✍ 입력 : MaritalStatus 별 Age 평균 --> 데이터프레임
data.groupby('MaritalStatus', as_index=True)[['Age']].mean()✍ 출력
Age
MaritalStatus
Divorced 37.522727
Married 37.704380
Single 35.460938- as_index=False를 설정하면 행 번호를 기반으로 한 정수 값이 인덱스로 설정됩니다.
✍ 입력
# MaritalStatus 별 Age 평균 --> 데이터프레임
data.groupby('MaritalStatus', as_index=False)[['Age']].mean()✍ 출력
MaritalStatus Age
0 Divorced 37.522727
1 Married 37.704380
2 Single 35.4609382) 데이터프레임으로 선언
- 집계 결과를 새로운 데이터프레임으로 선언하여 사용하는 경우가 많습니다.
- 집계된 결과를 반복해서 사용하거나, 분석 대상이 되는 경우 데이터프레임으로 선언함이 유익합니다.
✍ 입력
data.groupby('MaritalStatus', as_index=False)[['Age','MonthlyIncome']].mean()✍ 출력
MaritalStatus Age MonthlyIncome
0 Divorced 37.522727 6707.018939
1 Married 37.704380 6880.144161
2 Single 35.460938 5877.794271- sum() 메소드 앞에 아무 열도 지정하지 않으면 기준열 이외의 모든 열에 대한 집계가 수행됩니다.
✍ 입력
data.groupby('MaritalStatus', as_index=False).sum()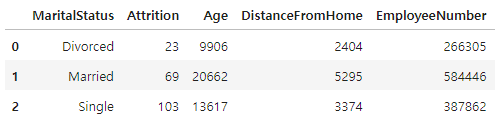
- by=['feature1', 'feature2'] 과 같이 집계 기준 열을 여럿 설정할 수도 있습니다.
✍ 입력
# 'MaritalStatus', 'Gender'별 나머지 열들 평균 조회
data_sum = data.groupby(['MaritalStatus', 'Gender'], as_index=False)[['Age','MonthlyIncome']].mean()
# 확인
data_sum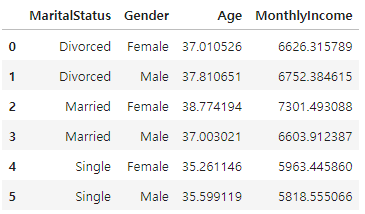
(3) 여러 함수로 한꺼번에 집계 .agg
df.groupby( ).agg(['함수1','함수2', ...])
✍ 입력
data_agg = data.groupby('MaritalStatus', as_index=False)[['MonthlyIncome']].agg(['min','max','mean'])
# 확인
data_agg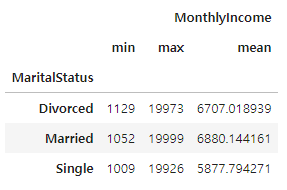

안녕하세요. wony입니다.