1. 개요
주제: Pandas
내용 : Pandas의 데이터프레임 변경을 정리하려고 한다.
2. 데이터프레임 변경
(1) 열 이름 변경
- 기존 데이터프레임의 열 이름을 적절히 변경해야 할 경우가 있습니다.
- 또는 집계 결과를 가진 열 이름을 이해하기 쉽게 변경해야 할 경우도 있습니다.
1) 일부 열 이름 변경
- rename() 메소드를 사용해 변경 전후의 열 이름을 딕셔너리 형태로 나열하는 방법으로 변경합니다.
- inplace=True 옵션을 설정해야 변경 사항이 실제 반영이 됩니다.
✍ 입력
# rename() 함수로 열 이름 변경
data.rename(columns={'DistanceFromHome' : 'Distance',
'EmployeeNumber' : 'EmpNo',
'JobSatisfaction' : 'JobSat',
'MonthlyIncome' : 'M_Income',
'PercentSalaryHike' : 'PctSalHike',
'TotalWorkingYears' : 'TotWY'}, inplace=True)
# 확인
data.head()2) 모든 열 이름 변경¶
- 모든 열 이름을 변경할 때는 columns 속성을 변경합니다.
- 변경이 필요없는 열은 기존 이름을 부여해 변경합니다.
✍ 입력
# 모든 열 이름 변경
data.columns = ['Attr','Age','Dist','EmpNo','Gen','JobSat','Marital','M_Income', 'OT', 'PctSalHike', 'TotWY']
# 확인
data.head()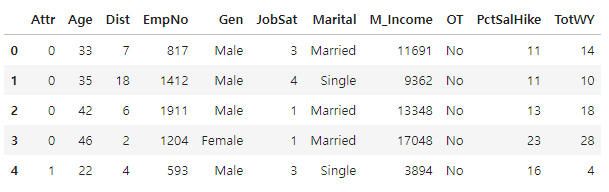
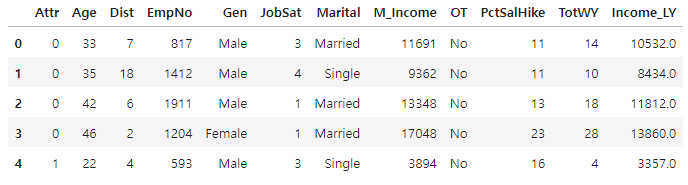
(2) 열 추가
- 새로운 열을 추가하여 기존 데이터에서 계산된 결괏값을 저장해야할 경우가 있습니다.
(3) 열 삭제
- 뭔가를 삭제할 때는 항상 조심x100 해야 합니다.
- 잘못 되었을 때 되돌리기 위한 준비가 필요합니다.
✍ 입력
# data를 복사합니다.
data2 = data.copy()1) 열 하나 삭제
- drop() 메소드를 사용해 열을 삭제합니다.
- axis=0: 행 삭제(기본 값)
- axis=1: 열 삭제
- inplace = True 옵션을 지정해야 실제로 반영이 됩니다.
✍ 입력
# 열 하나 삭제
data2.drop('Income_LY', axis=1, inplace=True)
# 확인
data2.head()2) 여러 열 삭제
- 삭제할 열을 리스트 형태로 전달해 한 번에 여러 열을 제거할 수 있습니다.
✍ 입력
# 열 두 개 삭제
data2.drop(['JobSat2','Diff_Income'], axis=1, inplace=True)
# 확인
data2.head()(4) 값 변경1
1) 열 전체 값 변경
✍ 입력
# Income_LY의 값을 모두 0로 변경해 봅시다.
data2['Income_LY'] = 0
data2.head()2) 조건에 의한 값 변경1
✍ 입력
# Diff_Income 의 값이 1000보다 작은 경우, 0로 변경해 봅시다.
data2.loc[data2['Diff_Income'] < 1000, 'Diff_Income' ] = 0
data2.head()3) 조건에 의한 값 변경2(np.where)
✍ 입력
# Age가 40보다 많으면 1, 아니면 0으로 바꿔 봅시다.
data2['Age'] = np.where(data2['Age'] > 40, 1, 0)
data2.head()(5) 값 변경2(map, cut)
1) map() 메소드
주로 범주형 값을 다른 값으로 변경
다음 구문은 Gen 변수의 Male, Female을 각각 숫자 1, 0으로 변경합니다.
✍ 입력
# Male -> 1, Female -> 0
data['Gen'] = data['Gen'].map({'Male': 1, 'Female': 0})
# 확인
data.head()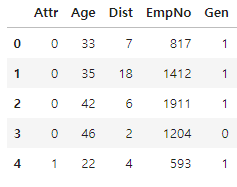
2) cut()
pd.cut() 함수를 이용하여, 숫자형 변수를 범주형 변수로 변환할 수 있습니다.
사례 : 나이 >> 나이대, 고객 구매액 >> 고객 등급
다음 구문은 나이를 나이대로 변경하는 구문입니다.
- 전체 범위 균등 분할하기
값의 범위를 균등 분할하는 것이지, 값의 개수를 균등하게 맞추는 것은 아님!
- 3 등분으로 분할후 a,b,c로 이름 붙이기기
✍ 입력
age_group = pd.cut(data2['Age'], 3, labels = ['a','b','c'])
age_group.value_counts()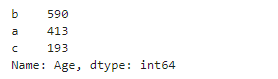
- 내가 원하는 구간으로 자르기 : bins = [ ]
✍ 입력
# 나이를 다음 구간으로 분할합니다.
# 'young' : =< 40
# 'junior' : 40 < =< 50
# 'senior' : 50 <
age_group = pd.cut(data2['Age'], bins =[0, 40, 50, 100] , labels = ['young','junior','senior'])
age_group.value_counts()
안녕하세요. wony입니다.