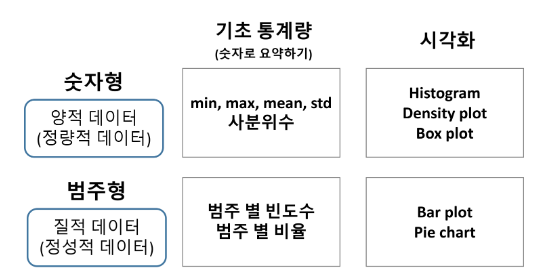
1. 개요
주제 : 단변량분석_숫자형, 범주형 변수
목표 : 숫자형 변수와 범주형 변수를 공부하면서 완벽하게 구분해 낼 수 있다.
2. 숫자형 변수
(1) 수치화 : 대표값
1) 평균, 중앙값, 최빈값, 4분위수
✍ 입력
# 평균
titanic['Fare'].mean()
# 중앙값
titanic['Fare'].median()
# 최빈값
titanic['Fare'].mode()
# 4분위수
titanic['Fare'].describe()(2) 수치화 : 기초통계량
1) 시리즈.describe()
✍ 입력
titanic['Fare'].describe()
2) 데이터프레임.describe()
✍ 입력
titanic.head()
(3) 시각화
1) 히스토그램
✍ 입력 : plt.histplot
# bins가 x축의 구간을 나누어 준다.
plt.hist(titanic.Fare, bins = 5, edgecolor = 'gray')
plt.show()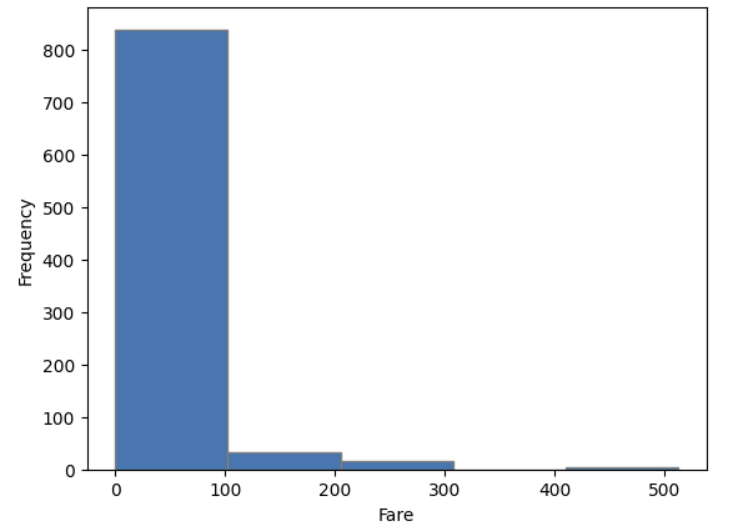
✍ 입력 : sns.histplot
sns.histplot(x= 'Fare', data = titanic, bins = 20)
plt.show()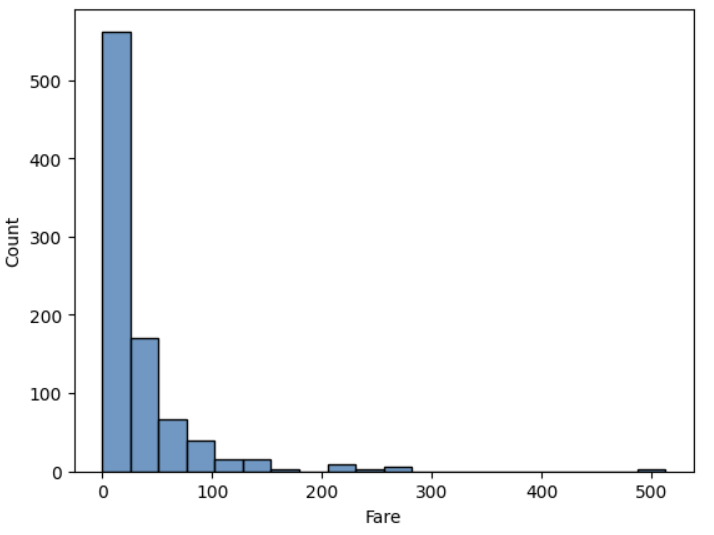
2) 밀도함수 그래프(kde plot)
- 히스토그램의 단점 : 구간의 너비를 어떻게 잡는지에 따라 전혀 다른 모형
- 밀도함수 그래프 : 막대의 너비를 가정하지 않고 모든 점에서 데이터의 밀도를 추정하는 커널 밀도 추정 방식을 사용하여 이러한 단점을 해결
- 밀도함수 그래프 그리그
✍ 입력
sns.kdeplot(titanic['Fare'])
plt.show()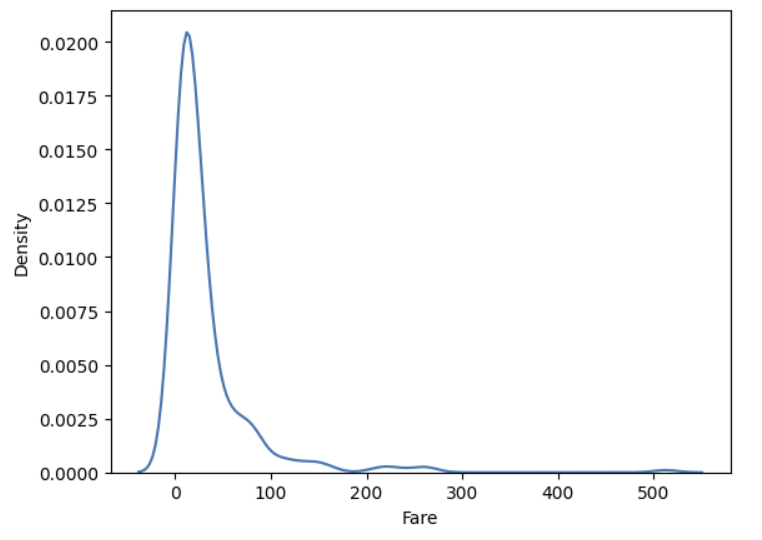
3) boxplot
주의사항 : 값에 NaN이 있으면 그래프가 그려지지 않습니다.
✍ 입력 : plt.boxplot
# titanic['Age']에는 NaN이 있습니다. 이를 제외한 데이터
temp = titanic.loc[titanic['Age'].notnull()]
plt.boxplot(temp['Age'])
plt.grid()
plt.show()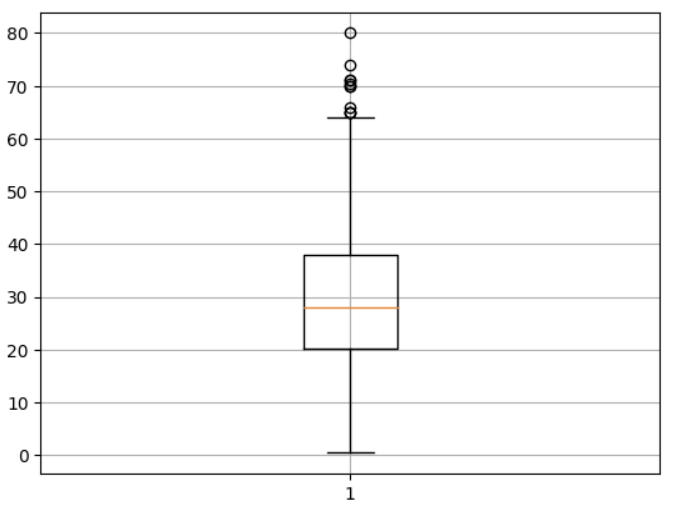
✍ 입력 : sns.boxplot
seaborn 패키지 함수들은 NaN을 알아서 빼줍니다.
sns.boxplot(x = titanic['Age'])
plt.grid()
plt.show()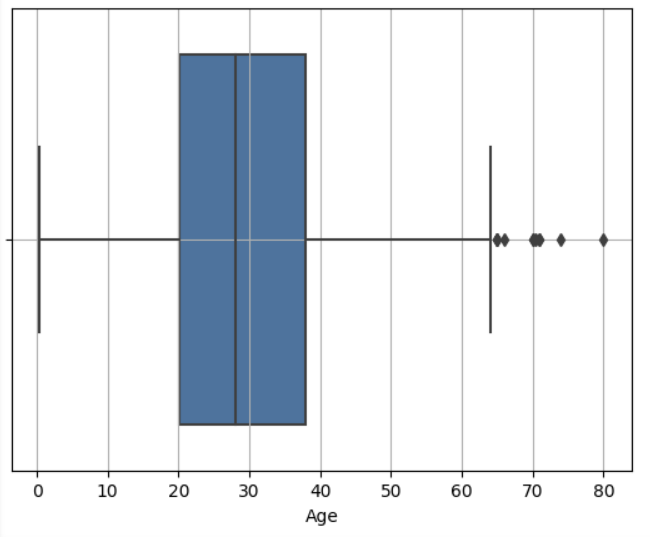
4) 시계열 데이터 시각화
- 시계열 데이터는 보통 시간 축(x축)에 맞게 값들을 라인차트로 표현합니다.
✍ 입력 :
air['Date'] = pd.to_datetime(air['Date']) # 날짜 형식으로 변환
plt.plot('Date', 'Ozone', 'g-', data = air, label = 'Ozone')
plt.plot('Date', 'Temp', 'r-', data = air, label = 'Temp')
plt.xlabel('Date')
plt.legend()
plt.show()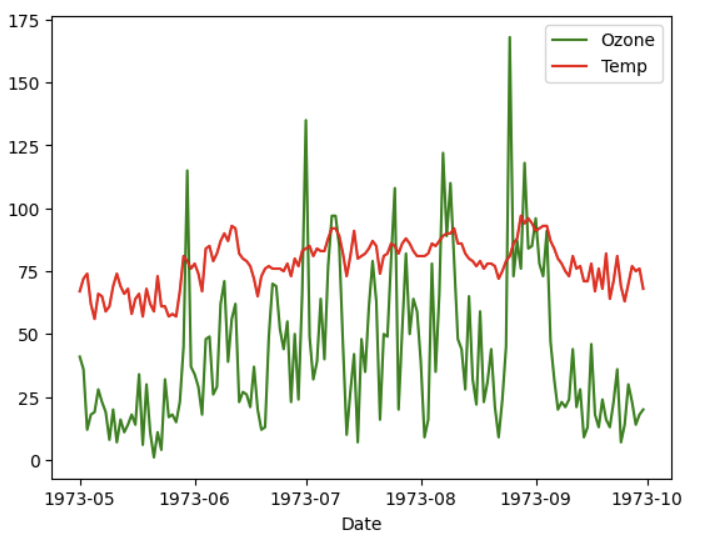
3. 단변량분석_범주형변수
(1) 수치화 : 기초통계량
1) 범주별 빈도수
titanic['Embarked'].value_counts()
2) 범주별 비율
titanic['Embarked'].value_counts(normalize = True)
[문1] titanic의 Pclass에 대한 기초 통계량을 구하시오
✍ 입력
var = 'Pclass'
t1 = titanic[var].value_counts()
t2 = titanic[var].value_counts(normalize = True)
t3 = pd.concat([t1, t2], axis = 1)
t3.columns = ['count','ratio']
t3
(2) 시각화
1) bar chart
✍ 입력
sns.countplot(x = 'Pclass', data = titanic)
plt.grid()
plt.show()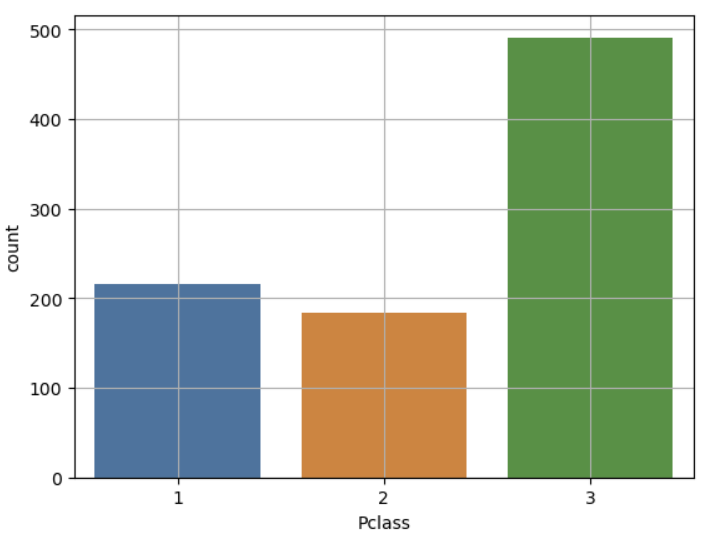

안녕하세요. wony입니다.